







阅读一个关于预测深度图和相机姿态的一篇论文《DRO: Deep Recurrent Optimizer for Structure-from-Motion》用于SFM的深度循环优化器。
通过机器学习的方法研究SFM问题越来越多了,早期的风法是直接从图像中得到一个深度图和相机姿态,现在出现很多通过在网络中嵌入优化器用多视角提高精度。这个论文展示了一个基于循环网络的优化方法来进一步探索SFM网络中的潜力。优化器通过迭代来最小化feature-metric cost来更新深度和相机位姿。该方法作为一个零次优化器,避免了高昂的体积或梯度的计算。作者说他的效果和速度又高又快。代码开源地址:https://github.com/aliyun/dro-sfm
1 介绍
给定一组图像序列,SFM方法优化深度图和相机pose来恢复场景的3D结构,传统方法主要解决Bundle-Adjustment 问题,最小化重投影误差,前期的深度学习的方法主要是直接预测结果,并没有利用到多视角的一些领域知识(domain knowledge),现在的方法主要设设计一个基于几何的优化器,作为一个可微层嵌入到网络中。
下图为作者提出的gated recurrent network,网络会不断更新depth和pose来最小化feature-metric cost,循环迭代使得,最后重投影误差最小。(其实这个NN优化器实际上就是根据输入的pose预测pose偏移量,直到最优)
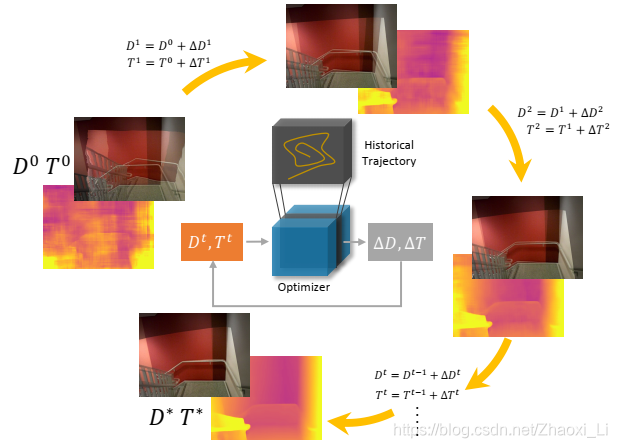
一些方法通过建立cost-volume来预测稠密depth map。cost-volume在计算机视觉中特指计算机视觉中的立体匹配stereo matching问题中的一种左右视差搜索空间。cost volume 对每个像素的多种不同深度值误差进行编码,尽管证明了在计算深度图是有效的,但是时间和空间都耗损巨大。作者提出的优化器是零次的而且在整个迭代利用了时间信息。
论文的展示效果:


2 深度循环优化器
目前网络分析是跟着论文来的,可能代码与论文有差异,后续代码读通了再补充细节
网络结构如下图所示,网络需要输入一个参考图像 I 0 I_0 I0和 N N N个相邻图像 I i I_i Ii,这个 N N N可以理解为深度学习的batch,整个网络的输入是两张图,最后会有一个cost,而N张图实际上就是每一对cost的平均。
所以以下图为例,假设输入图像
I
0
I_0
I0和
I
i
I_i
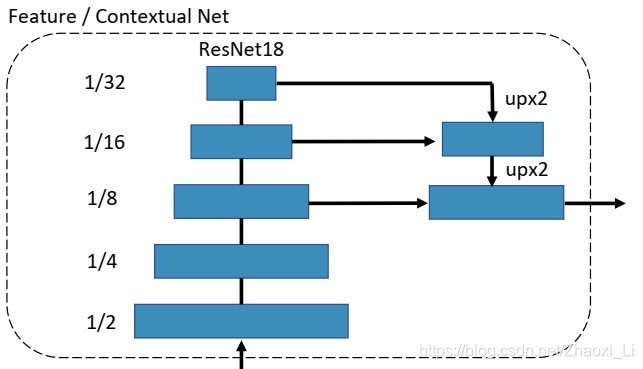
Ii,首先需要提取特征Feature Net,这个网络就是ResNet18,输出特征图的尺寸是原图的
1
/
8
1/8
1/8,定义为
F
0
,
F
i
F_0, F_i
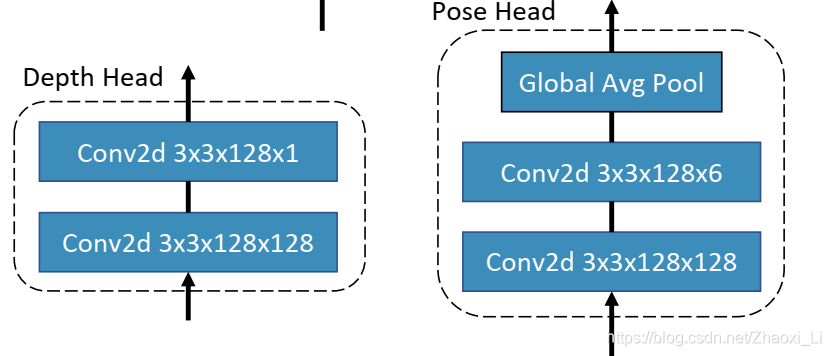
F0,Fi,共享同一个参数。Depth Head由两个CNN构成,输出depth map
D
D
D,而Pose Head在两个CNN的基础上又来一个平均池化层,输出pose参数
T
i
T_i
Ti。
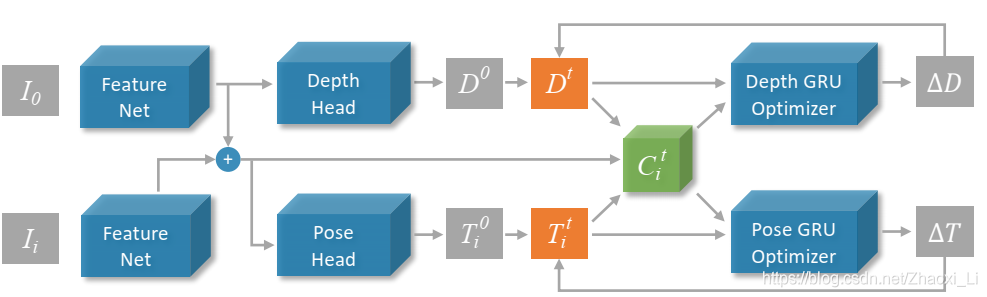
一对图像进来,先得到特征
F
0
,
F
i
F_0, F_i
F0,Fi,进而估算位姿,然后另一种网络用来计算上下文特征图
F
0
c
,
F
i
c
F^c_0, F^c_i
F0c,Fic用于输入后面的优化器中。

网络细节如下所示,实际上输出特征图维度都是输入的1/8。
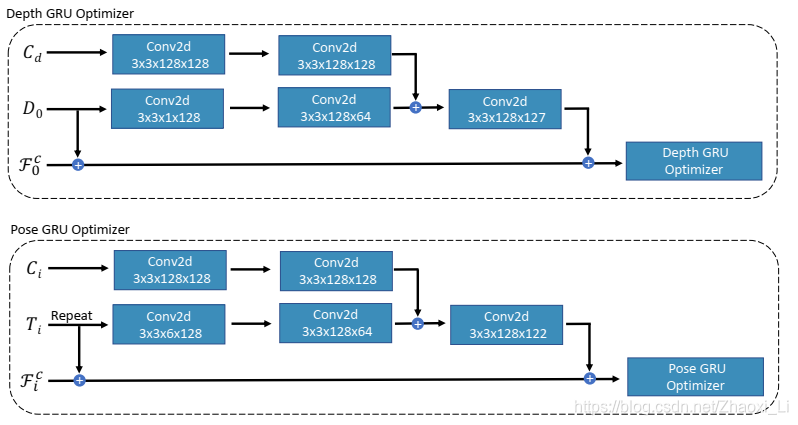
无论是前面说的pose head 还是depth head 其网络结构如下所示,depth最后输入的特征图维度为1,pose输出的维度为6
给定 F 0 , F i , D , T i F_0, F_i, D, T_i F0,Fi,D,Ti即可算出一个cost map C i C_i Ci,作者认为第 i i i张特征图的一个点,在参考图上的投影之后的位置处的特征值相等,基于这个就构建出了一个cost计算方法,对于参考图像特征图 F 0 F_0 F0上的一个点x,cost计算如下所示, D ( x ) ⋅ π − 1 ( x ) D(x)\cdot\pi^{-1}(x) D(x)⋅π−1(x)表示参考图像的3d点, π ( T i , D ( x ) ⋅ π − 1 ( x ) ) ) \pi(T_i, D(x)\cdot\pi^{-1}(x))) π(Ti,D(x)⋅π−1(x)))表示这个3d点在第i张特征上的位置。
C i ( x ) = ∣ ∣ F i ( π ( T i , D ( x ) ⋅ π − 1 ( x ) ) ) − F 0 ( x ) ∣ ∣ 2 C_i(x) = ||F_i(\pi(T_i, D(x)\cdot\pi^{-1}(x))) - F_0(x)||_2 Ci(x)=∣∣Fi(π(Ti,D(x)⋅π−1(x)))−F0(x)∣∣2
遍历所有像素,即可得到一个Cost Map C i C_i Ci,对于多张相邻图,整体的loss就是 C i C_i Ci的平均数。
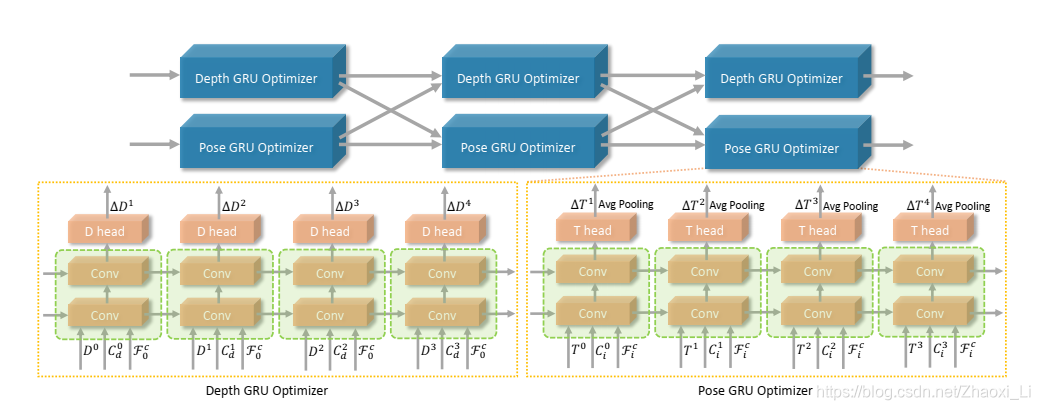
上图为作者提出的GRU方法,这个就是循环神经网络,想看懂RNN的图可以参考这个链接:一文搞懂RNN(循环神经网络)基础篇。如果不懂也没关系,咱们就记着,输入的是cost map
C
t
−
1
C_{t-1}
Ct−1和当前预测值
V
t
−
1
V_{t-1}
Vt−1,这个预测值就是前面的深度图或位姿信息。网络的输出就是
Δ
V
\Delta V
ΔV,这样新的值就可以被更新了:
V
t
=
V
t
−
1
+
Δ
V
V_{t} = V_{t-1}+\Delta V
Vt=Vt−1+ΔV,上图4个循环叫做一个stage,位姿修正和深度修正之后,重新计算cost map,再循环几个stage就作为输出。所以再调参时候,可以控制
m
m
m stages
n
n
n times。
GRU输入网络之前需要对三种数据进行处理,具体操作如下所示。
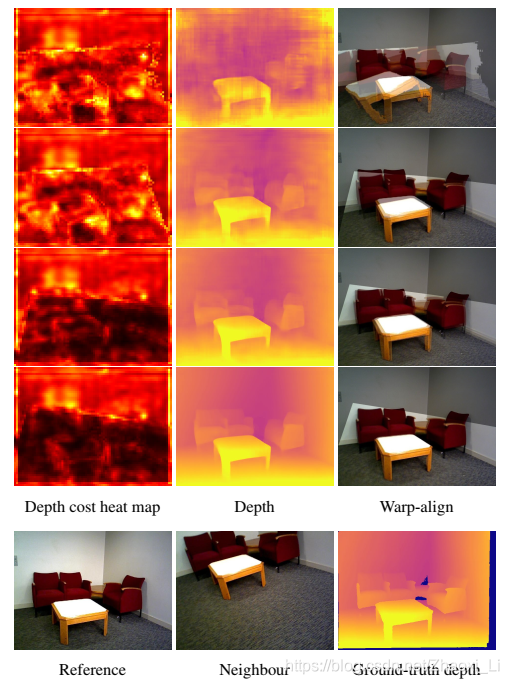
下图是每个stage的结果,深度图越来越精确,图像也对的越来越齐
3 训练Loss
3.1 有监督情况
有监督指的是有深度图真值和相机变换之间的真值
深度的loss计算方法如下所示,在优化过程中,每个stage都会输出一个深度图, γ \gamma γ是一个滞后因子,说明越早得到的深度图对应的权重越小,最后以最终的输出深度图为主。
L d e p t h = ∑ s = 1 m γ m − s ∣ ∣ D s − D ∣ ∣ 1 L_{depth} = \sum^{m}_{s=1}\gamma^{m-s}||D^s-D||_1 Ldepth=s=1∑mγm−s∣∣Ds−D∣∣1
关于位姿的loss,思路简单,就是利用深度图真值 D D D ,用预测变换出来的和真值变幻出来的深度图做差。
L p o s e = ∑ s = 1 m ∑ x γ m − s ∣ ∣ π ( T i s , D ( x ) ⋅ π − 1 ( x ) ) − π ( T i , D ( x ) ⋅ π − 1 ( x ) ) ∣ ∣ 1 L_{pose} = \sum^{m}_{s=1}\sum_x\gamma^{m-s}||\pi(T_i^s, D(x)\cdot \pi^{-1}(x)) - \pi(T_i, D(x)\cdot \pi^{-1}(x)) ||_1 Lpose=s=1∑mx∑γm−s∣∣π(Tis,D(x)⋅π−1(x))−π(Ti,D(x)⋅π−1(x))∣∣1
最后将这两个loss加在一起就是最后真值。
3.2 自监督情况
用了两种loss,光度损失 photometric loss 和平滑度损失smoothness loss。
关于photometric loss,利用预测出的深度图和pose,可以将相邻图像 I i I_i Ii变换到参考图像下 I i ′ I'_i Ii′,原理上两个图像的差应该特别小。作者又引入了一个结构相似度的概念,SSIM,评价两个图像的相似度的,这样这个loss可以定义为:
L p h o t o = α 1 − S S I M ( I i ′ , I 0 ) 2 + ( 1 − α ) ∣ ∣ I i ′ − I 0 ∣ ∣ 1 L_{photo} = \alpha \dfrac{1-SSIM(I'_i,I_0)}{2} + (1-\alpha)||I'_i-I_0||_1 Lphoto=α21−SSIM(Ii′,I0)+(1−α)∣∣Ii′−I0∣∣1
关于smoothness loss,基于相邻的像素应该具有相似的深度这个性质,特别是颜色相似的时候,这样就构建处一个loss
l S M O O T H = ∣ ∂ x D ∣ e − ∣ ∂ x I 0 ∣ + ∣ ∂ y D ∣ e − ∣ ∂ y I 0 ∣ l_{SMOOTH}=|\partial_xD|e^{-|\partial_xI_0|} + |\partial_yD|e^{-|\partial_yI_0|} lSMOOTH=∣∂xD∣e−∣∂xI0∣+∣∂yD∣e−∣∂yI0∣
图像的颜色越相似, ∣ ∂ x I 0 ∣ |\partial_xI_0| ∣∂xI0∣越小,则该深度误差给的权重越大。
最后自监督的总体误差为: L s e l f = L p h o t o + λ L s m o o t h L_{self}=L_{photo}+\lambda L_{smooth} Lself=Lphoto+λLsmooth
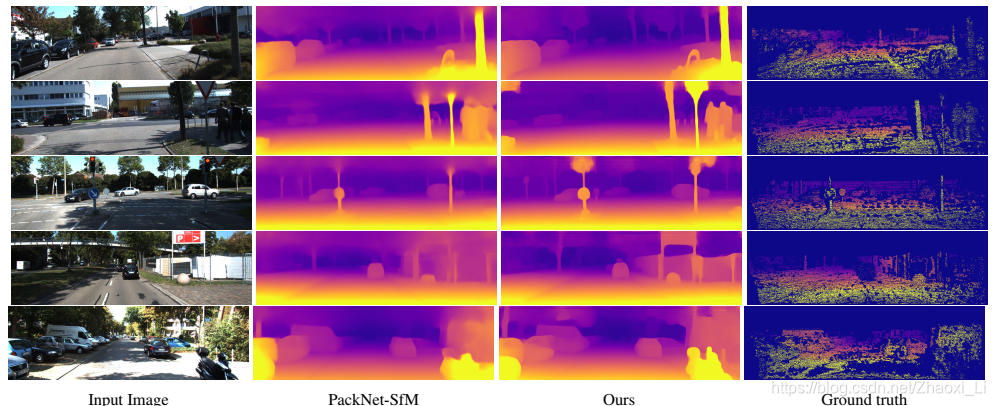
4 实验结果

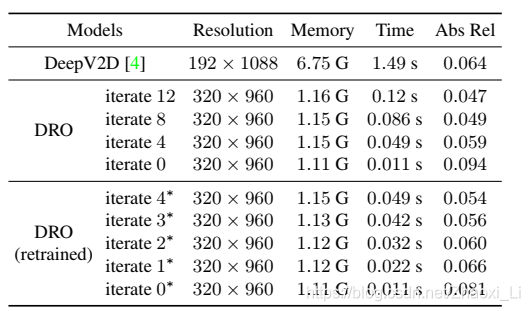
时间和内存占用情况。

总结
从结果来看重建效果非常好,但是从他的对比算法结果来看,深度图提升效果不明显,但是旋转平移矩阵这个提升还是很明显的,所以后续要研究的话也要搞清楚为什么depth不足够好。














 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









