







今天看一篇论文《SUNet: Symmetric Undistortion Network for Rolling Shutter Correction》用于卷帘快门的对称不失真网络SUNet。
现在的消费级相机采用的卷帘快门机制,当相机快速移动的时候,采集到的图像是有扭曲的。这个论文就提出了一个网络使用一对连续帧解决这个问题。网络用于预测这两帧中间时刻的图像。这个对别的现有方法是比较困难的,因为这些算法需要两个姿态差异比较大的图像。
1 介绍
全局快门(GS)相机是一次性曝光所有像素得到图像,而卷帘快门(RS)实在CMOS上一行一行曝光的,因此在运动过程中会出现RS效应,使得像素出现便宜,扭曲,模糊等等,导致一些基于序列的应用比如重建等出现偏移,缺失等误差。因此作者的工作就是针对RS的问题提出个算法消除这个效应。
开发时候还要注意相机往往与其他传感器要时间同步,所以每次处理时间不能波动特别大,因此基于迭代的方法就不可控。开发时候考虑到实用性会更好。
问题复杂性主要表现在以下几个方面:
- 目标GS图像的像素可能不在其对应RS前后图像对应的邻域像素中,这取决于运动类型、3D结构和扫描线时间;
- 下图也可以看出来前后两张图像分别预测中间图像,使用第一张预测时候存在的问题在第二张是不存在的,这也就是为什么要融合前后两个图像来预测。

2 方法
方法输入两张连续的图像,最后输出一个在两个图像中间时刻的校正后的全局图像。
定义 I I I为图像, c c c表示特征, F F F为无扭曲流(undistortion flow), t ∈ { 1 , 2 } t\in\{1,2\} t∈{1,2}表示第几张输入的卷帘快门(RS)图像。 t → g t\rightarrow g t→g表示使用第 t t t个RS的上下文特征warp得到的全局快门(GS)部分。 g g g就是两个GS图中间时刻校正后的GS实例。 l l l表示第 l l l层金字塔,其分辨率是原图的 1 2 l − 1 \dfrac{1}{2^{l-1}} 2l−11。整个网络结构是对称的,因此只考虑第一个RS的处理流程即可。

两个输入RS使用同一个特征特征金字塔网络,权重共享。在金字塔的顶部也就是第
L
L
L层,通过对比两个图像的特征,计算出对应位置的cost volume。之后这个volume和特征
c
1
L
c^L_1
c1L一起输入CNN中,通过一个上采样操作估计出无变形的flow
F
1
→
g
L
−
1
F^{L-1}_{1\rightarrow g}
F1→gL−1,上图中的向上箭头就是上采样,紫色那个图就是flow。在金字塔的二层特征
c
1
L
−
1
c^{L-1}_1
c1L−1,利用得到的无变形flow
F
1
→
g
L
−
1
F^{L-1}_{1\rightarrow g}
F1→gL−1,被warp后得到
c
1
→
g
L
−
1
c^{L-1}_{1\rightarrow g}
c1→gL−1。得到这个特征输入到一个CNN(图中间黄色上面那个网络)预测出一个一个GS图
I
1
→
g
L
−
1
I^{L-1}_{1\rightarrow g}
I1→gL−1。同理,利用第二个图可以预测出
I
2
→
g
L
−
1
I^{L-1}_{2\rightarrow g}
I2→gL−1。然后concate四个数据
I
1
→
g
L
−
1
,
I
2
→
g
L
−
1
,
c
1
→
g
L
−
1
,
c
2
→
g
L
−
1
I^{L-1}_{1\rightarrow g}, I^{L-1}_{2\rightarrow g}, c^{L-1}_{1\rightarrow g}, c^{L-1}_{2\rightarrow g}
I1→gL−1,I2→gL−1,c1→gL−1,c2→gL−1 通过中间黄色的CNN网络会付出一个中间时刻的矫正后的GS图
I
g
L
−
1
I^{L-1}_{g}
IgL−1。
与前面操作相似,利用两个特征 c 1 → g L − 1 , c 2 → g L − 1 c^{L-1}_{1\rightarrow g},c^{L-1}_{2\rightarrow g} c1→gL−1,c2→gL−1又能计算出一个cost volumn(第二列红色框)。然后,这个volumn,前面的第二层特征 c 1 → g L − 1 c^{L-1}_{1\rightarrow g} c1→gL−1和前面计算出的flow F 1 → g L − 1 F^{L-1}_{1\rightarrow g} F1→gL−1仍进一个CNN来估计出一个新的flow F 1 → g L − 2 F^{L-2}_{1\rightarrow g} F1→gL−2。循环这个过程,直到输出与原图一样大的图。
实际上这个网络,第一次输出的三个图可以理解为小分辨的矫正图,之后循环一次尺度变大一倍,直到最后原始大小(不能更大了,因为无特征可用了。)
因此整个网络包含几个关键模块:金字塔特征提取,无畸变流估计,时间中心化的GS图解码网络。
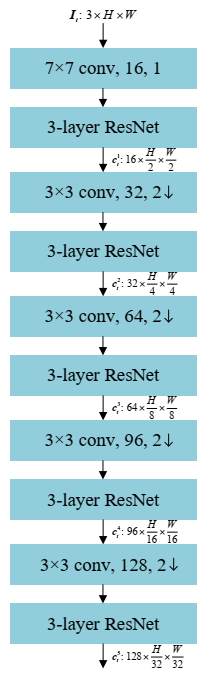
2.1 金字塔特征提取
这个网络的结构很简单,主要是基于Resnet,下采样主要是利用stride =2的卷积。
上下文感知Cost volume 层说了,但没完全说,感觉像是在分析
2.2 无畸变流估计器
前面说了,一个无畸变flow
F
1
→
g
l
−
1
F^{l-1}_{1\rightarrow g}
F1→gl−1的输入是金字塔特征
c
1
→
g
l
−
1
c^{l-1}_{1\rightarrow g}
c1→gl−1和计算出来的cost volumn。这个过程使用的网络是5个DenseNet块,之后再上采样。这个过程的网络结构如下图所示,最后一层的输出的16应该改为8。
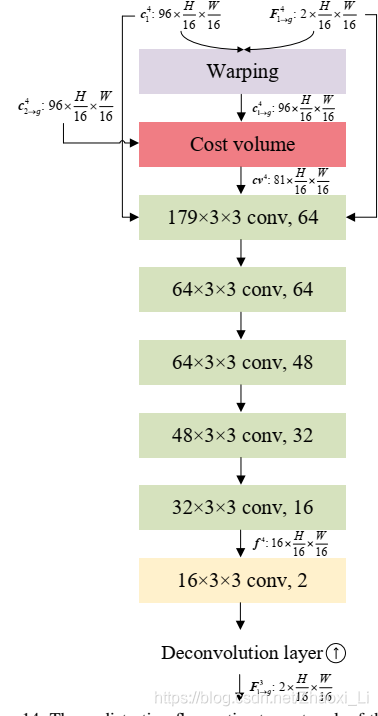
2.3 时间中心化的GS图像解码
这个过程对应之前整个流程图的中间部分,这个decode由3个ResNet块构成,用于提取金字塔特征,然后紧跟一个GS预测层,和一个反卷积层。warp之后的特征 c 1 → g l − 1 , c 2 → g l − 1 c^{l-1}_{1\rightarrow g},c^{l-1}_{2\rightarrow g} c1→gl−1,c2→gl−1和concate这两个特征得到的新特征 c g l − 1 c^{l-1}_{g} cgl−1,可以生成一个正向和反向的GS图 I 1 → g l − 1 I^{l-1}_{1\rightarrow g} I1→gl−1, I 2 → g l − 1 I^{l-1}_{2\rightarrow g} I2→gl−1,以及一个目标GS图 I g l − 1 I^{l-1}_{g} Igl−1。网络的最终输出的分辨率是原图的一半,因此需要在用一个线性上采样及一个卷积层来得到完整分辨率的GS图。
2.4 训练loss
定义 I G T l − 1 I^{l-1}_{GT} IGTl−1为每一个生成的GS I g l − 1 I^{l-1}_g Igl−1对应的真值,那么最终误差由四个小误差加权求和得到。
重构误差。这个很简单,直接把生成 I g l − 1 I^{l-1}_g Igl−1和真值 I G T l − 1 I^{l-1}_{GT} IGTl−1做差求和。
L r = ∑ l = l 0 − 1 L ∣ ∣ I g l − 1 − I G T l − 1 ∣ ∣ 1 L_r = \sum^{L}_{l=l_0-1}||I^{l-1}_g - I^{l-1}_{GT}||_1 Lr=l=l0−1∑L∣∣Igl−1−IGTl−1∣∣1
感知误差。为了减轻模糊效应,定义了一个感知误差来保留预测出的细节,使得生成的GS图更加清晰。公式定义如下,其中 ϕ \phi ϕ表示VGG19模型的conv3_3特征提取器。
L p = ∑ l = l 0 − 1 L ∣ ∣ ϕ ( I g l − 1 ) − ϕ ( I G T l − 1 ) ∣ ∣ 1 L_p = \sum^{L}_{l=l_0-1}||\phi(I^{l-1}_g) - \phi(I^{l-1}_{GT})||_1 Lp=l=l0−1∑L∣∣ϕ(Igl−1)−ϕ(IGTl−1)∣∣1
一致性误差。网络除了预测出 I g l − 1 I^{l-1}_g Igl−1之外,还有两个图像 I 1 → g l − 1 , I 2 → g l − 1 I^{l-1}_{1\rightarrow g}, I^{l-1}_{2\rightarrow g} I1→gl−1,I2→gl−1,这两个图像也可以作为真值的一个近似,因此也要最小化这个误差。
L c = ∑ t = 1 2 ∑ l = l 0 − 1 L ∣ ∣ I t → g l − 1 − I G T l − 1 ∣ ∣ 1 L_c= \sum^{2}_{t=1}\sum^{L}_{l=l_0-1}||I^{l-1}_{t\rightarrow g} - I^{l-1}_{GT}||_1 Lc=t=1∑2l=l0−1∑L∣∣It→gl−1−IGTl−1∣∣1
平滑性误差。主要是约束无扭曲flow F 1 → g l − 1 F^{l-1}_{1\rightarrow g} F1→gl−1 的平滑性。
L s = ∑ t = 1 2 ∑ l = l 0 − 1 L ∣ ∣ Δ F t → g l − 1 ∣ ∣ 2 L_s = \sum^{2}_{t=1}\sum^{L}_{l=l_0-1}||\Delta F^{l-1}_{t\rightarrow g}||_2 Ls=t=1∑2l=l0−1∑L∣∣ΔFt→gl−1∣∣2
3 实验结果
数据集和验证准则细节看论文分析,
算法的效果:
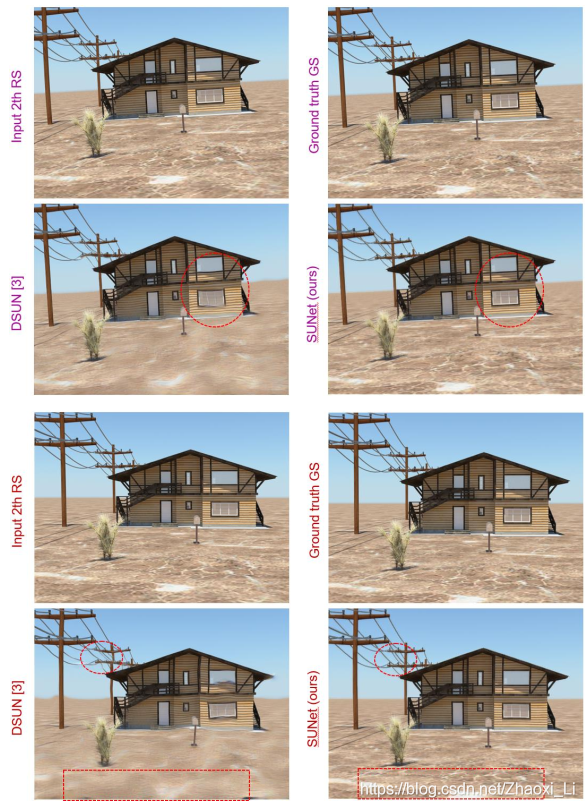
预测出的三个图像的效果,也验证了组合两个图像能够得到更好的图。

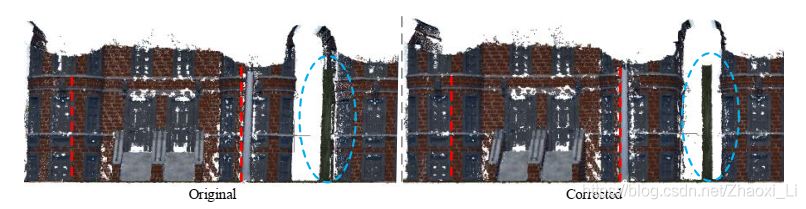
在重建中的应用,减少了由运动产生的重建误差。
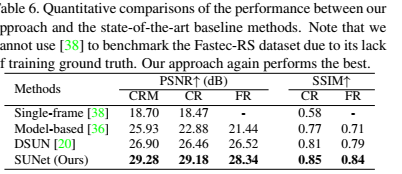
一些量化实验,在多个指标都是最高的,高了2-5个点。
4 总结
作者给了针对卷帘快门运动过程中图像畸变问题给出了一个良好的方案。作者说目前关注与特定时间对应的RS校正问题。在未来的工作中,将探索更具挑战性的任务,例如,由用户操纵曝光时间,以完成相应的RS校正。














 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









