







论文:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
通过强化学习激励LLM的推理能力
DeepSeek 的第一代推理模型,迈出了使用纯强化学习(RL)来提高语言模型推理能力的第一步,探索 LLM 在没有任何监督数据的情况下开发推理能力的潜力,重点关注它们通过纯 RL 过程进行自我进化。这也是第一项验证了 LLM 的推理能力可以纯粹通过 RL 来激励而无需 SFT 的开放式研究。
这里面涉及了两个模型 DeepSeek-R1-Zero 和 DeepSeek-R1 的开发过程:DeepSeek-R1-Zero 是在基础模型上进行纯强化学习的训练,而 DeepSeek-R1 则是基于基础模型进行了多阶段的监督微调和强化学习,接下来就具体看看两个模型的训练过程。
DeepSeek-R1-Zero
Reinforcement Learning on the Base Model
强化学习在推理任务中表现出显著的有效性,但之前的工作严重依赖于监督数据,而收集这些数据需要耗费大量时间。这里探索了 LLM 在没有任何监督数据的情况下开发推理能力的潜力,重点关注它们通过纯强化学习过程进行自我进化(self-evolution)。
强化学习算法
Group Relative Policy Optimization
采用 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models 中的GRPO算法,它放弃了通常与策略模型大小相同的评论家模型,转而根据群体分数来估计基线。算法大致如下:
对每个问题
q
q
q,GPRO 从旧策略
π
θ
o
l
d
\pi_{\theta_{old}}
πθold 中采样一组输出
{
o
1
,
o
2
,
⋯
,
o
G
}
\{o_1, o_2, \cdots, o_G\}
{o1,o2,⋯,oG},然后通过最大化下面的目标函数以优化策略模型
π
θ
\pi_\theta
πθ:
J
G
R
P
O
(
θ
)
=
E
[
q
∼
P
(
Q
)
,
{
o
i
}
i
=
1
G
∼
π
θ
old
(
O
∣
q
)
]
1
G
∑
i
=
1
G
(
min
(
π
θ
(
o
i
∣
q
)
π
θ
old
(
o
i
∣
q
)
A
i
,
clip
(
π
θ
(
o
i
∣
q
)
π
θ
old
(
o
i
∣
q
)
,
1
−
ε
,
1
+
ε
)
A
i
)
−
β
D
KL
(
π
θ
∥
π
ref
)
)
,
D
KL
(
π
θ
∥
π
ref
)
=
π
ref
(
o
i
∣
q
)
π
θ
(
o
i
∣
q
)
−
log
π
ref
(
o
i
∣
q
)
π
θ
(
o
i
∣
q
)
−
1
,
\begin{aligned} \mathcal{J}_{GRPO}(\theta) &= \mathbb{E}\left[ q \sim P(Q), \{ o_i \}_{i=1}^G \sim \pi_{\theta_{\text{old}}} (O|q) \right] \\ &\frac{1}{G} \sum_{i=1}^G \left( \min \left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \ \text{clip}\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1 - \varepsilon, 1 + \varepsilon \right) A_i \right) - \beta \mathbb{D}_{\text{KL}} (\pi_\theta \parallel \pi_{\text{ref}}) \right), \\ &\mathbb{D}_{\text{KL}} (\pi_\theta \parallel \pi_{\text{ref}}) = \frac{\pi_{\text{ref}}(o_i|q)}{\pi_\theta(o_i|q)} - \log \frac{\pi_{\text{ref}}(o_i|q)}{\pi_\theta(o_i|q)} - 1, \end{aligned}
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai, clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∥πref)),DKL(πθ∥πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1,
其中,
ε
\varepsilon
ε 和
β
\beta
β 是超参数,
A
i
A_i
Ai 是优势项,使用对应于每个组内输出的一组奖励
{
r
1
,
r
2
,
⋯
,
r
G
}
\{r_1, r_2, \cdots, r_G\}
{r1,r2,⋯,rG} 来计算:
A
i
=
r
i
−
mean
(
{
r
1
,
r
2
,
⋯
,
r
G
}
)
std
(
{
r
1
,
r
2
,
⋯
,
r
G
}
)
.
A_i = \frac{r_i-\text{mean}(\{r_1, r_2, \cdots, r_G\})}{\text{std}(\{r_1, r_2, \cdots, r_G\})}.
Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG}).
奖励模型
奖励是训练信号的来源,决定了RL的优化方向。为了训练 DeepSeek-R1-Zero,采用了基于规则的奖励系统,该系统主要包含两种类型的奖励:
- Accuracy rewards:准确度奖励模型评估响应是否正确。比如有确定答案的数学问题。
- Format rewards:采用格式奖励模型,强制模型将其思考过程置于
<think>和</think>标签之间。
在开发 DeepSeek-R1-Zero 时,没有应用结果或过程神经奖励模型,因为作者发现神经奖励模型在大规模强化学习过程中可能会产生奖励黑客攻击现象 reward hacking(简单说就是容易被模型钻空子,能找到捷径获取高奖励,但对实现最终目标没有帮助),并且重新训练奖励模型需要额外的训练资源,也会使整个训练流程变得复杂。
训练模版
以下是用于训练 DeepSeek-R1-Zero 的模版。训练的时候,prompt 会被替换为特定的推理问题:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: prompt. Assistant:
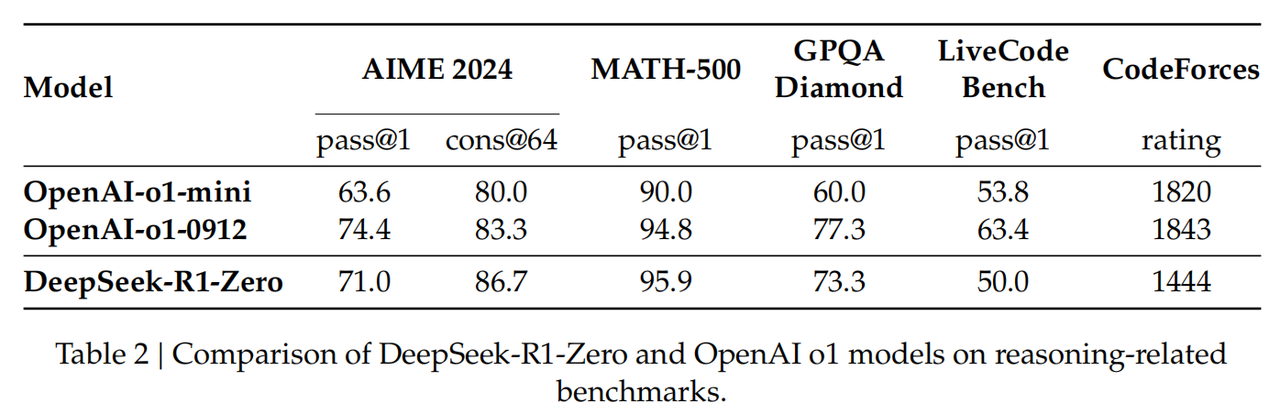
DeepSeek-R1-Zero的性能、自我进化和顿悟时刻
DeepSeek-R1-Zero的性能
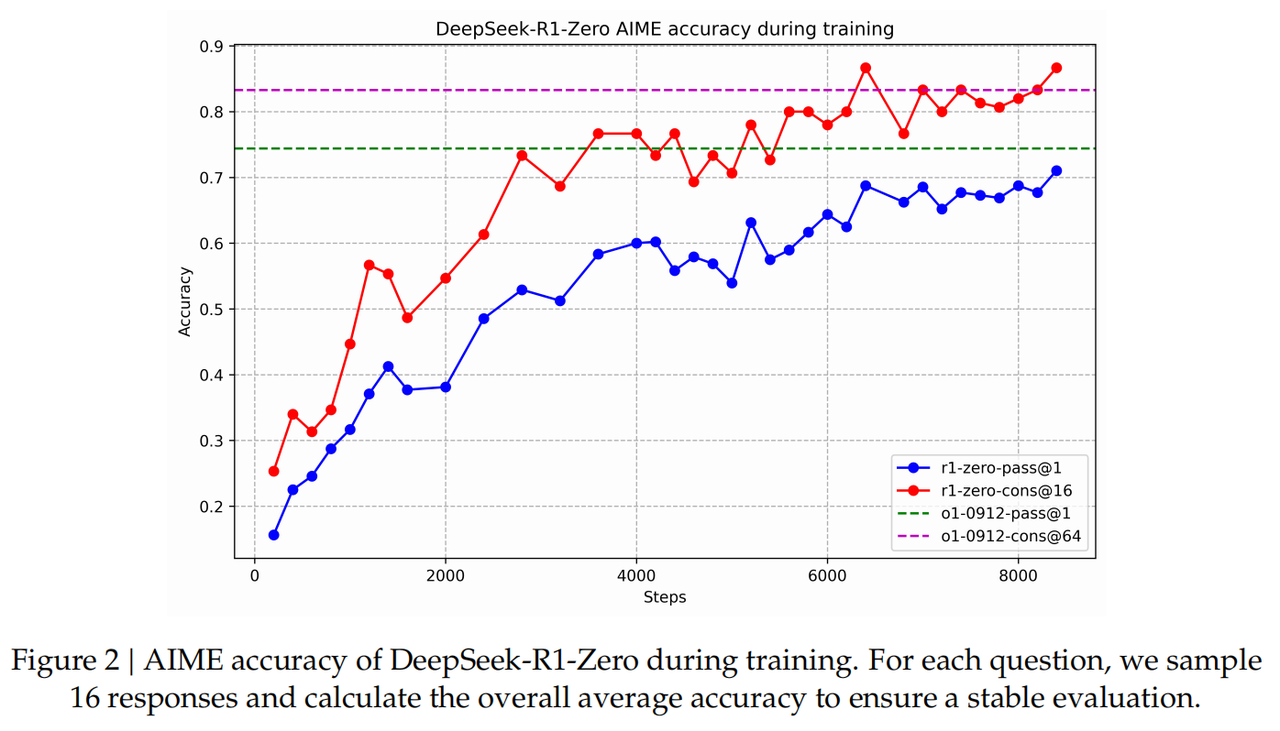
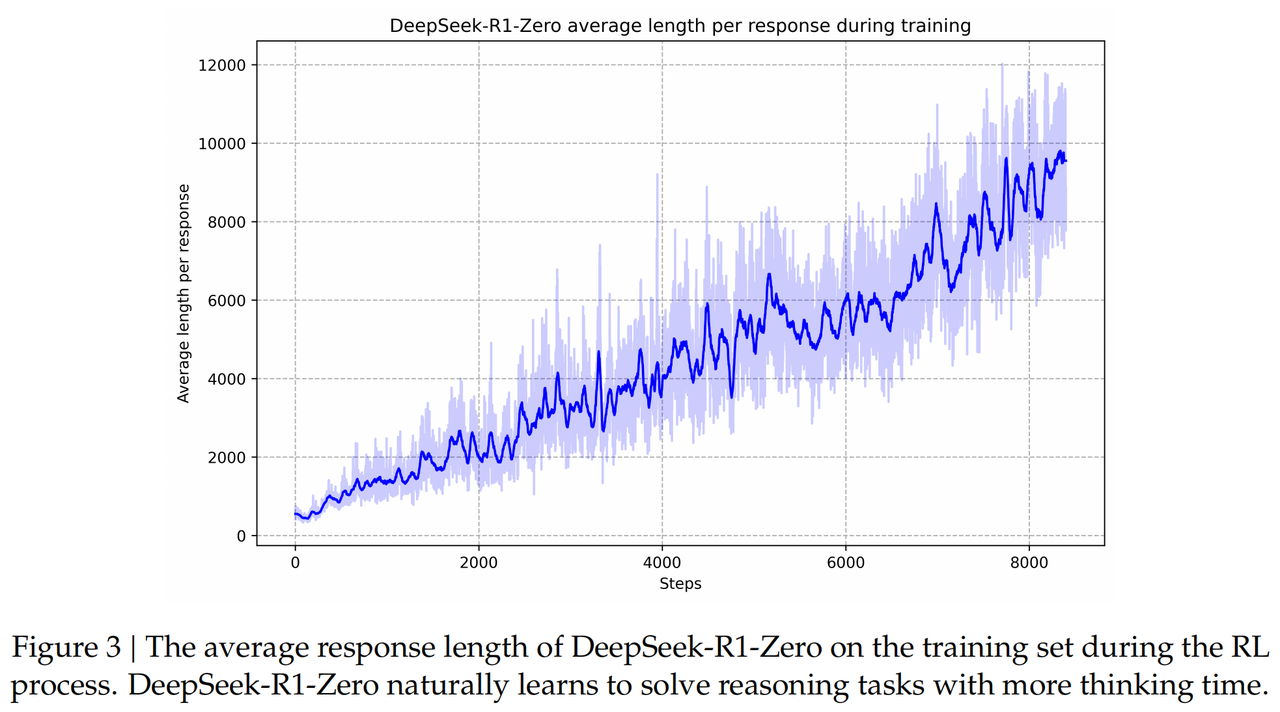
DeepSeek-R1-Zero的自演化过程
在没有监督微调阶段影响的情况下,模型通过RL自我进化:
- 获取了通过增加额外的计算时间(思考)解决越来越复杂的推理任务
- 当计算时间增加时,产生了复杂的行为,如反思回顾、替代方法的探索等
DeepSeek-R1-Zero的顿悟时刻(Aha Moment)

DeepSeek-R1-Zero的缺点
尽管 DeepSeek-R1-Zero 表现出强大的推理能力,并自主开发出意想不到的强大推理行为,但它面临着几个问题。例如,DeepSeek-R1-Zero 面临着可读性差和语言混合等挑战。为了解决这些问题,探索了 DeepSeek-R1,使用具有人类友好冷启动数据的RL方法。
DeepSeek-R1
冷启动下的强化学习
DeepSeek-R1-Zero 的效果不错,能否更进一步提升其能力,这里自然地产生了两个问题:
- 通过加入少量高质量数据作为冷启动,是否可以进一步提高推理性能或加速收敛?
- 我们如何训练一个用户友好的模型,它不仅可以产生清晰连贯的思维链(CoT),而且还能展示出强大的通用能力?
为了解决这些问题,作者设计了一个流程来训练 DeepSeek-R1,该流程由四个阶段组成。
冷启动
与 DeepSeek-R1-Zero 不同,为了防止基础模型在 RL 训练的早期不稳定的冷启动阶段,DeepSeek-R1 构建并收集了少量的长 CoT 数据来对模型进行微调。这里探索了一些方法用于采集这些数据:以一个长 CoT 的样本应用 few-shot 提示、直接提示模型通过反思和验证生成详细答案、以可读格式收集 DeepSeek-R1-Zero 的输出,并通过人工标注员的后处理来完善结果。
在开发 DeepSeek-R1 过程中,收集了数千条冷启动数据用于微调 DeepSeek-V3-Base 作为 RL 的起点。相比 DeepSeek-R1-Zero,冷启动数据的优势包括:
- 可读性:DeepSeek-R1-Zero 的一个关键限制是其内容通常不适合阅读。回复可能混合多种语言或缺乏为用户突出显示答案的 markdown 格式。在为 DeepSeek-R1 创建冷启动数据时,设计使用了一个可读更强的模式,其中包括每个响应末尾的总结,并过滤掉不易阅读的响应。这种可读性更强的输出格式为
|special_token|<reasoning_process>|special_token|<summary>,其中reasoning process是查询问题的 CoT,summary是推理结果的总结。 - 潜力:通过精心设计具有人类先验知识的冷启动数据模式,获得了比 DeepSeek-R1-Zero 更好的性能。论文中如此说到:“We believe the iterative training is a better way for reasoning models.”
面向推理的强化学习
在冷启动数据上对 DeepSeek-V3-Base 进行微调后,采用与 DeepSeek-R1-Zero 相同的大规模强化学习训练流程。此阶段侧重于增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务涉及定义明确且解决方案明确的问题。在这个训练过程中,模型产生的 CoT 经常包含混合的语言。为缓解语言混合的问题,在 RL 训练中引入了一个语言一致性奖励,其计算方式为 CoT 中目标语言单词的比例。之后,将推理任务的准确率和语言一致性的奖励直接相加,形成最终奖励,然后再对微调后的模型进行强化学习训练,直到它在推理任务上实现收敛。
拒绝采样和监督微调
当推理导向的 RL 收敛时,接着利用生成的检查点来收集 SFT(监督微调)数据以供下一轮使用。与最初主要侧重于推理的冷启动数据不同,此阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力。具体如下:
- 推理数据
通过精心构建推理提示词对来自上面 RL 学习的检查点执行拒绝采样(rejection sampling)来生成推理数据。之前的阶段中只包含了可以使用基于规则的奖励系统评估的数据,而在这个阶段,合并了其他数据以扩展数据集,其中一些数据使用生成奖励模型,通过将真实数据和模型预测输入 DeepSeek-V3 进行判断。对每个提示词,会采样多个响应,然后只保留正确的输出。最终总共收集了大约 60 万个推理相关的训练样本。 - 非推理数据
对于非推理数据,例如写作、事实问答、自我认知和翻译等,采用 DeepSeek-V3 流程并重用 DeepSeek-V3 的 SFT 数据集的部分内容。对于某些非推理任务,通过提示让 DeepSeek-V3 在回答问题之前生成潜在的思路链。但是,对于更简单的查询,例如“你好”,则不会提供 CoT 作为响应。最后,总共收集了大约 20 万个与推理无关的训练样本。
在这个阶段,使用了上述精选的约 800k 个样本的数据集对 DeepSeek-V3-Base 进行了两个 epoch 的微调。
针对所有场景的强化学习
为了使模型进一步符合人类偏好,实现了二次强化学习阶段,旨在提高模型的有用性和无害性,同时完善其推理能力。具体来说就是使用奖励信号和各种提示分布的组合来训练模型。对于推理数据,遵循 DeepSeek-R1-Zero 中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般数据,采用奖励模型来捕捉复杂和细微场景中的人类偏好。
训练流程图
这里是两个模型的简单的训练流程关系图,能够更直观地看到两个模型分别经过了哪些训练阶段:
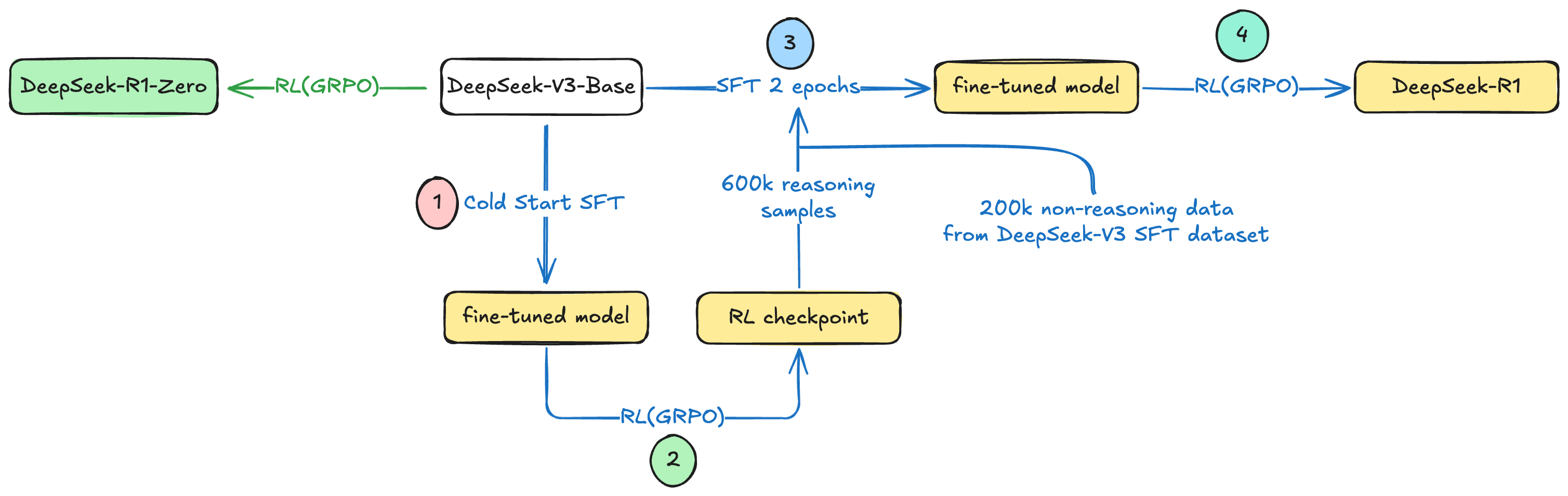


















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











