







DeepSeek LLM
2024 年 1 月 5 日 DeepSeek LLM
这是一个 dense 模型,总体架构基本和 LLaMA 一样,有 7B 和 67B 两个尺寸。这个版本的研究主要是为了后续LLM 的长期发展和效果提升打好基础,即论文名称中的“Longtermism”,就像论文中所说的:
Our study aims to lay the groundwork for future scaling of open-source LLMs, paving the way for further advancements in this domain.
所以这个研究的主要贡献不是发布的大模型效果有多好,而是对scaling laws 的各方面的深入研究,确保其走在有效扩大计算规模的正确道路上,这反映了长期视角,是开发性能持续改进的模型的关键。对 scaling laws 的研究和发现如下:
- 建立了超参数(batch size 和 learning rate)的缩放定律,为确定最优超参数提供了一个经验框架。
- 采用非嵌入 FLOP/token M M M 代替模型参数 N N N 来表示模型规模,从而实现更准确的最佳模型/数据扩大分配策略,和更好地预测大规模模型的泛化损失。
- 预训练数据的质量会影响最佳模型/数据扩展分配策略。数据质量越高,分配给模型扩展的计算预算就越多。
DeepSeekMoE
2024 年 1 月 11 日 DeepSeekMoE
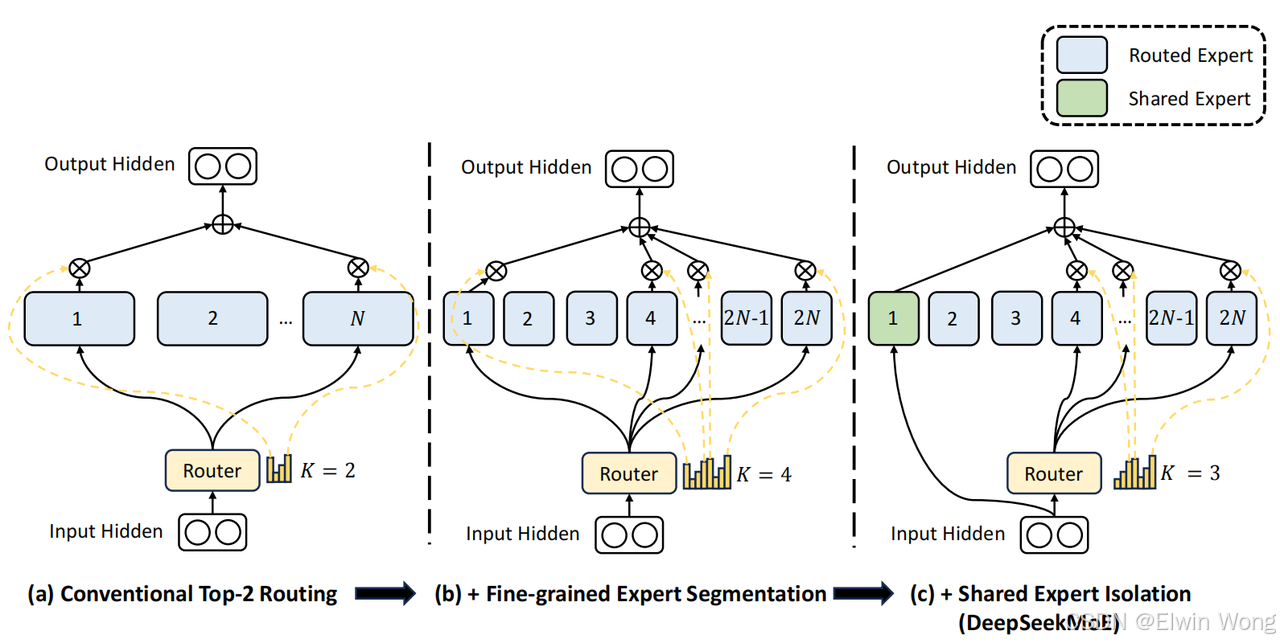
在有充足的训练数据的情况下,通过增加参数和计算预算来扩展语言模型固然可以产生更强大的模型,但是随之而来的是计算成本也会急剧增加,因此需要一种有别于当前主流 dense 模型的架构用于管理计算成本,混合专家 MoE 就是这样一种架构,在扩展模型参数的同时能够管理和控制计算成本。DeepSeekMoE 主要提出了对传统 MoE 架构的一些创新改进,并基于该架构做了大量的实验,验证了该架构的高效性、有效性和可扩展性:
-
架构创新:为了达到终极的专家专业化,提出了两种策略:
更细粒度的专家划分和共享专家隔离,旨在提高专家的专业化水平。
-
实证验证:进行了大量实验来实证验证 DeepSeekMoE 架构的有效性。
-
可扩展性:扩展 DeepSeekMoE 到更大的参数量,也表现出了一致的有效性(DeepSeekMoE 16B 只需要大约 40% 的计算就能达到和 DeepSeek 7B 和 LLaMA2 7B 相当的效果;DeepSeekMoE 145B 只需要 28.5% 的计算能达到和 DeepSeek 67B 相当的性能)
另外,为了解决自动学习路由策略导致的负载均衡问题,引进了两个级别的损失:
- Expert-Level Balance Loss
避免模型总是只选择少数专家,使得其他专家得不到充分的训练 - Device-Level Balance Loss
分布式训练场景下,专家分布在不同设备,避免模型总是选择某个或某几个设备上的专家从而造成计算瓶颈
基于上述的 MoE 架构,先训练了 2B 参数量的模型,验证了该架构的有效性,然后扩展到 16B 规模,评测结果同样展示了该架构的有效性和可扩展性。基于 DeepSeekMoE 16B 进行监督微调 SFT 构建了聊天模型证明了对 MoE 模型进行 SFT 能够进一步提升效果。最后更进一步将模型扩展到 145B 的规模。
DeepSeek-V2
2024 年 5 月 7 日 DeepSeek-V2
强大的 MoE 模型,主要特点是经济训练、高效推理,总参数有 236B,21B 激活参数,支持 128K 上下文长度。
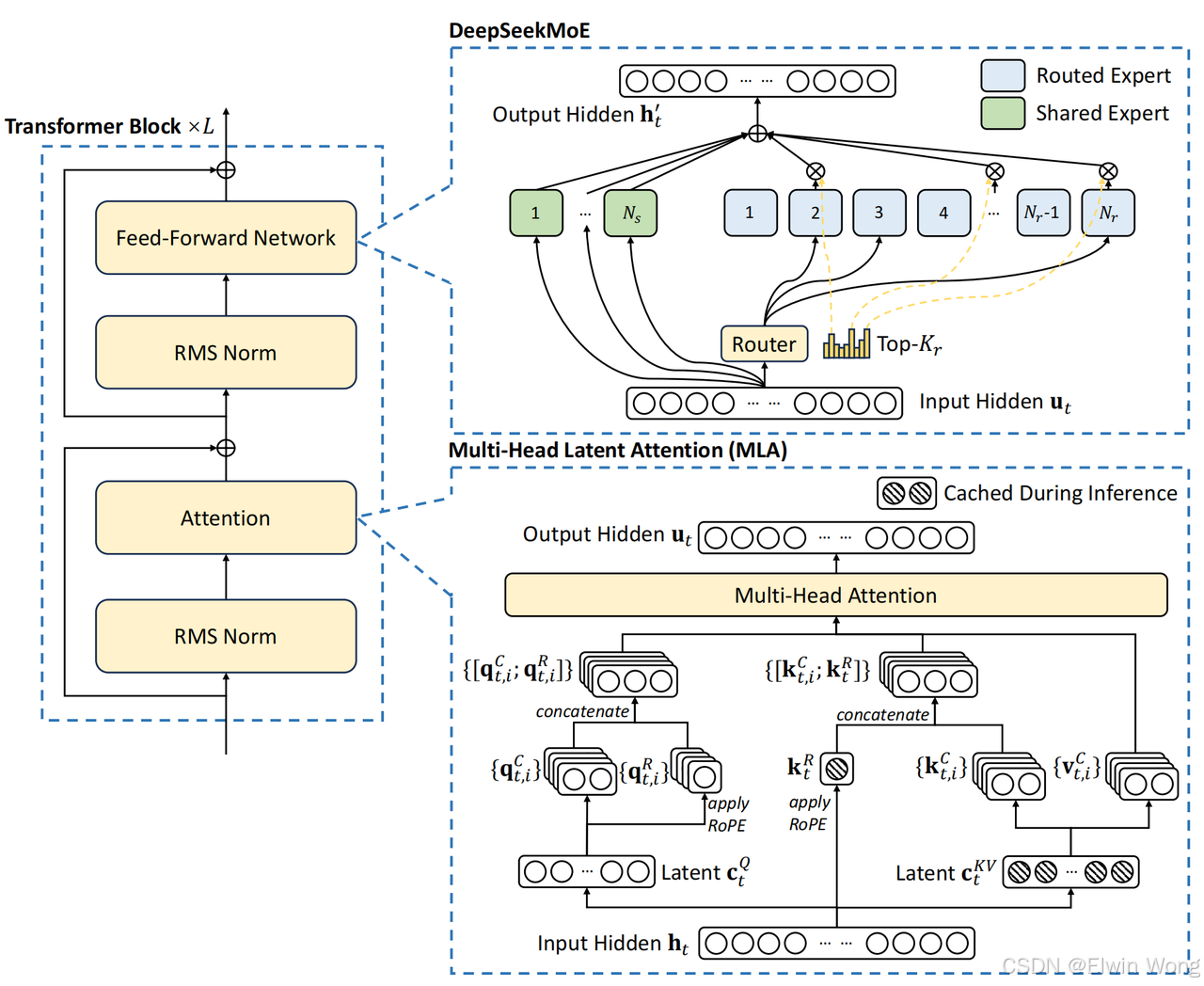
总体还是在Transformer架构内,但针对注意力模块和FFN设计了创新的架构:
- 注意力机制:设计了 MLA(Multi-Head Latent Attention),利用低秩键值联合压缩(Low-Rank Key-Value Joint Compression)极大地减少了键值缓存(key-value cache),消除了推理时 KV cache 的瓶颈,从而支持高效推理。
- FFN:延续采用 DeepSeekMoE 中的高性能 MoE 架构,能够以经济的成本训练强大的模型。
另外,DeepSeek-V2 中还采取了一些措施来限制与 MoE 相关的通信成本和实现负载均衡:
- 设备受限路由
为了限制 MoE 相关的通信成本,在训练过程中,限制每个 token 的目标专家分布在最多 M M M 台设备上。 - 针对负载均衡的辅助损失
- Expert-Level Balance Loss:同 DeepSeekMoE
- Device-Level Balance Loss:同 DeepSeekMoE
- Communication Balance Loss:确保每个设备的通信是均衡的
- Token 丢弃策略
为了进一步减轻负载不平衡造成的计算浪费,在训练过程中引入了设备级 token 丢弃策略。简单来说,就是将超出设备计算预算的 toke 丢弃掉。
训练过程:预训练——>SFT——RL(GRPO), GRPO 强化学习算法是在 DeepSeekMath 中提出的,这是首次在 DeepSeek 通用系列模型中采用。关于强化学习算法的演进,可以看看这篇通俗易懂的 blog:https://huggingface.co/blog/NormalUhr/grpo
DeepSeek-V3
2024 年 12 月 27 日 DeepSeek-V3
MoE 模型,具有 671B 参数,37B 激活参数,延续使用 DeepSeek-V2 的架构,采用 MLA 和 DeepSeekMoE 以实现经济训练和高效推理。与 V2 相比,V3 有以下改进:
- 采用新的针对 MoE 模型的负载均衡措施:
- Auxiliary-Loss-Free Load Balancing
DeepSeek-V2 中主要依赖辅助损失来避免不平衡负载,但辅助损失过大也会损害模型性能,所以为了使负载均衡和模型性能达到一个更好的平衡,采用了无辅助损失的负载均衡策略。 - Complementary Sequence-Wise Auxiliary Loss
防止任何单个序列中的极端不平衡 - Node-Limited Routing
类似于 DeepSeek-V2 中使用的设备受限路由,在训练过程中,确保每个 token 被发送给最多 M M M 个节点,从而控制通信成本。 - No Token-Dropping
由于有效的负载平衡策略,DeepSeek-V3 在整个训练过程中保持了良好的负载平衡。因此,DeepSeek-V3 在训练期间不会丢弃任何 token。
- Auxiliary-Loss-Free Load Balancing
- 使用 Multi-Token Prediction 目标函数
- 预训练过程中采用了很多方法尽可能得降低训练成本以达到更高的训练效率
各种并行、FP8 训练、通信优化等 - 后训练:来自 DeepSeek-R1 的知识提炼
将长思维链(CoT)模型(DeepSeek R1 系列模型之一)中的推理能力提炼到 DeepSeek-V3 中
这样一套组合拳搞下来,最终 DeepSeek-V3 的训练成本只有 $5.576M:

DeepSeek-R1
2025 年 1 月 22 日 DeepSeek-R1
第一代推理模型,迈出了使用纯强化学习(RL)来提高语言模型推理能力的第一步,探索 LLM 在没有任何监督数据的情况下开发推理能力的潜力,重点关注它们通过纯 RL 过程进行自我进化。这也是第一项验证了 LLM 的推理能力可以纯粹通过 RL 来激励而无需 SFT 的开放式研究。这里面涉及了两个模型 DeepSeek-R1-Zero 和 DeepSeek-R1 的开发过程,主要内容如下:
- 强化学习算法
使用 Group Relative Policy Optimization(GRPO)算法,放弃了通常与策略模型大小相同的评论家模型,并且是根据群体分数来估计基线,训练更高效稳定。 - 模型开发
- DeepSeek-R1-Zero:基础模型上的强化学习
-
使用 DeepSeek-V3-Base 作为基础模型,在上面直接应用 GRPO 算法进行 RL 训练
-
奖励建模
奖励是训练信号的来源,决定了 RL 的优化方向,训练 DeepSeek-R1-Zero 采用了一个基于规则的奖励系统,主要包括了两种类型的奖励:- 准确率奖励:评估响应是否正确。比如有确定答案的数学问题。
- 格式奖励:采用格式奖励模型,强制模型将其思考过程置于
<think>和</think>标签之间。
-
训练模板

-
Aha Moment

-
缺点
DeepSeek-R1-Zero 的响应可读性差、存在语言混合等问题
-
- DeepSeek-R1:冷启动下的强化学习
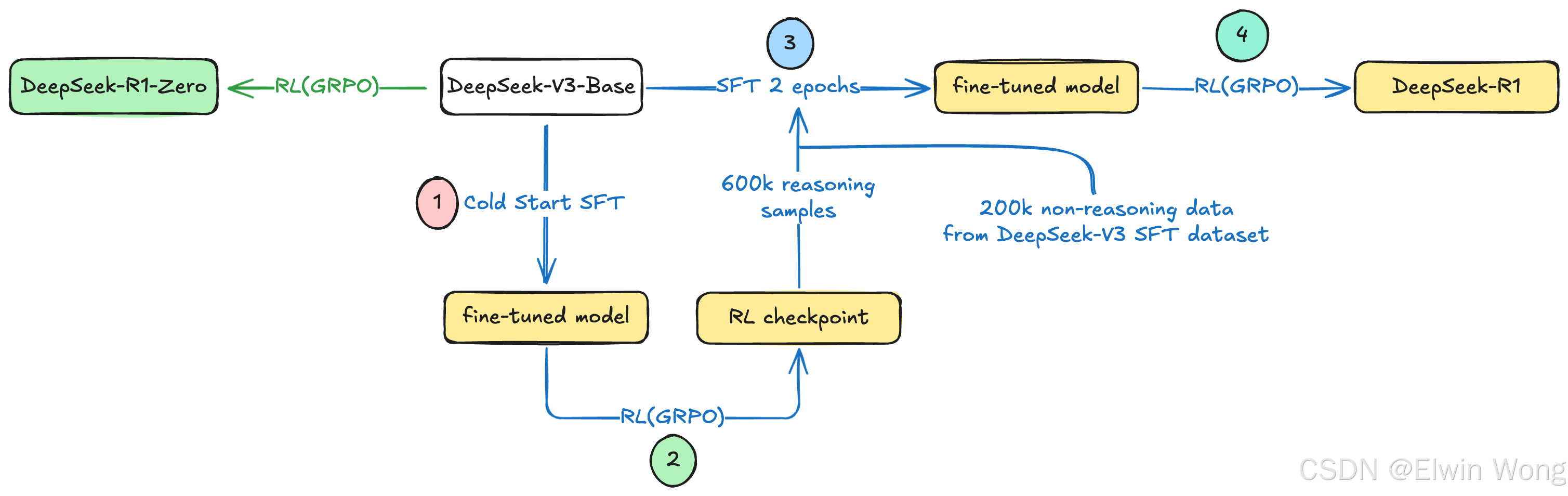
DeepSeek-R1 的训练流程包含四个阶段:- 冷启动
采集了数千条长 CoT 冷启动数据微调 DeepSeek-V3-Base 作为 RL 的启动点。 - 面向推理的强化学习
采用与 DeepSeek-R1-Zero 相同的大规模强化学习训练流程,此阶段重点增强模型的推理能力;
为解决 CoT 经常包含语言混合的问题,引入语言一致性奖励,表示为目标语言单词在 CoT 中的比例。 - 拒绝采样(Rejection Sampling)和监督微调(SFT)
利用上一阶段 RL 收敛后的检查点(模型)采集用于下一轮训练的 SFT 数据,这些数据不仅有推理数据,也包含了其他领域的数据,以增强模型在其他方面的通用能力:- 推理数据:通过拒绝采样从上一阶段得到的模型中采集了大约 600k 推理相关的训练样本;
- 非推理数据:重用了 DeepSeek-V3 所用 SFT 数据集的部分数据 + 通过 DeepSeek-V3 生成部分数据 + 人工设计一些数据,最终采集了大约 200k 和推理无关的训练样本;
使用上述精选的约 800k 个样本的数据集对 DeepSeek-V3-Base 进行了两个 epoch 的微调
- 针对所有场景的强化学习
为了使模型进一步符合人类偏好,实现了二次强化学习阶段,旨在提高模型的有用性和无害性,同时完善其推理能力。具体做法是使用不同奖励信号和各种提示分布的组合来训练模型。
- 冷启动
- DeepSeek-R1-Zero:基础模型上的强化学习
训练流程关系图


















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











