







模型结构
GoogLeNet 吸收了 NiN 中串联网络的思想,并在此基础上做了改进。这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。
Inception 块
GoogLeNet 中,基本的卷积块被称为 Inception 块,如下所示:

四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成 Inception 块的输出。在 Inception 块中,通常调整的超参数是每层输出通道数。
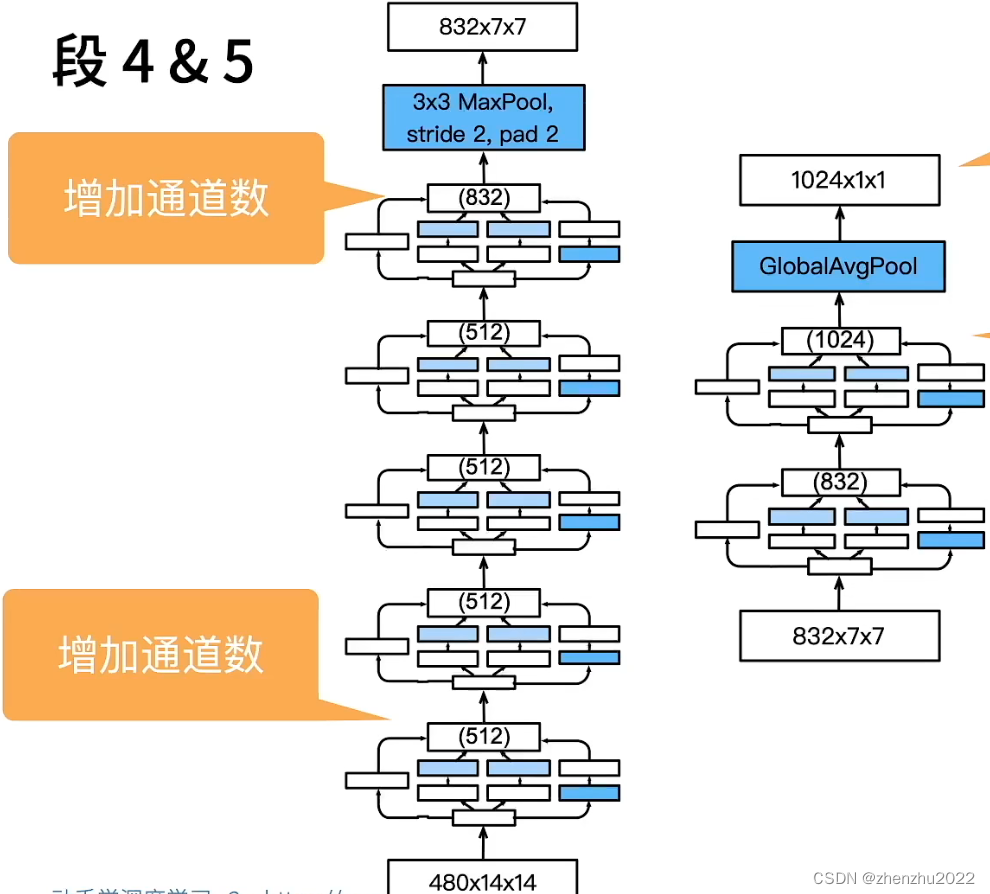
模型细节
GoogLeNet 一共使用9个 Inception 块和全局平均汇聚层的堆叠来生成其估计值。Inception 块之间的最大汇聚层可降低维度。



代码
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchinfo import summary
from tqdm import tqdm
# 加载数据
train_dataset = datasets.FashionMNIST(root="../datasets/", transform=transforms.Compose([transforms.ToTensor(), transforms.Resize(224)]), train=True, download=True)
test_dataset = datasets.FashionMNIST(root="../datasets/", transform=transforms.Compose([transforms.ToTensor(), transforms.Resize(224)]), train=False, download=True)
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=128, shuffle=False)
# 定义Inception类
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4):
super().__init__()
self.b1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
self.b2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.b2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
self.b3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.b3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
self.b4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.b4_2 = nn.Conv2d(in_channels,c4, kernel_size=1)
self.relu = nn.ReLU()
def forward(self, x):
b1 = self.relu(self.b1_1(x))
b2 = self.relu(self.b2_2(self.relu(self.b2_1(x))))
b3 = self.relu(self.b3_2(self.relu(self.b3_1(x))))
b4 = self.relu(self.b4_2(self.b4_1(x)))
return torch.cat((b1, b2, b3, b4), dim=1) # batch_size是第0维,通道是第1维
# 定义GoogLeNet网络结构
class GoogLeNet(nn.Module):
def __init__(self):
super().__init__()
# layer1: 1*224*244 -> 64*112*112 -> 64*56*56
self.layer1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# layer2: 64*56*56 -> 64*56*56 -> 192*56*56 -> 192*28*28
self.layer2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# layer3: 192*28*28 -> 256*28*28 -> 480*28*28 -> 480*14*14
self.layer3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# layer4: 480*14*14 -> 512*14*14 ->... -> 832*14*14 -> 832*7*7
self.layer4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.layer5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)))
self.flatten = nn.Flatten()
self.linear = nn.Linear(1024, 10)
def forward(self, x):
h1 = self.layer1(x)
h2 = self.layer2(h1)
h3 = self.layer3(h2)
h4 = self.layer4(h3)
h5 = self.layer5(h4)
h6 = self.linear(self.flatten(h5))
return h6
# net = GoogLeNet()
# summary(net, (1, 1, 224, 224))
device = "cuda:0" if torch.cuda.is_available() else "cpu"
googlenet = GoogLeNet().to(device)
# 定义超参数
epochs = 10
lr = 1e-4
# 定义优化器
optimizer = torch.optim.Adam(googlenet.parameters(), lr = lr)
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
# 训练
for epoch in range(epochs):
train_loss_epoch = []
for train_data, labels in tqdm(train_dataloader):
train_data = train_data.to(device)
labels = labels.to(device)
y_hat = googlenet(train_data)
loss = loss_fn(y_hat, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_epoch.append(loss.cpu().detach().numpy())
print(f'epoch:{epoch}, train_loss:{sum(train_loss_epoch) / len(train_loss_epoch)}')
with torch.no_grad():
test_loss_epoch = []
right = 0
for test_data, labels in tqdm(test_dataloader):
test_data = test_data.to(device)
labels = labels.to(device)
y_hat = googlenet(test_data)
loss = loss_fn(y_hat, labels)
test_loss_epoch.append(loss.cpu().detach().numpy())
right += (torch.argmax(y_hat, 1) == labels).sum()
acc = right / len(test_dataset)
print(f'test_loss:{sum(test_loss_epoch) / len(test_loss_epoch)}, acc:{acc}')训练结果

PS:图片上的模型参数有一两处错误,以代码为准。















 1970
1970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









