







文章目录
论文基本信息
《Bayesian Optimization Enhanced Deep Reinforcement Learning for Trajectory Planning and Network Formation in Multi-UAV Networks》
《用于多无人机网络轨迹规划与网络形成的贝叶斯优化增强的深度强化学习》
IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 72, NO. 8, AUGUST 2023
在【论文阅读】Adaptive Network Formation and Trajectory Optimization for Multi-UAV-Assisted Wireless Data Offloading 基础上,使用贝叶斯优化驱动MADDPG。
优化决策有:无人机轨迹、网络形成。
优化目标:最小化(完成任务的)总能耗和传输延迟。
摘要
在本文中,我们采用了由一个基站(BS)协调的多架无人机来帮助地面用户(GUs)卸载他们的传感数据。不同的无人机可以调整其轨迹和网络形成,通过多跳中继加速数据传输。轨迹规划的目的是收集所有GUs的数据,而无人机的网络形成优化了多跳无人机网络拓扑,以最小化能耗和传输延迟。采用两步迭代的方法求解了联合网络的形成和轨迹优化问题。首先,我们利用启发式算法设计了自适应网络形成方案,以平衡无人机的能耗和数据队列大小。然后,在固定网络的形成下,在不知道无人机的交通需求和空间分布的情况下,利用多智能体深度强化学习进一步优化无人机的飞行轨迹。为了提高学习效率,我们进一步采用贝叶斯优化的方法,基于历史轨迹点估计无人机的飞行决策。这有助于避免了低效的动作探索,并提高了模型训练中的收敛速度。仿真结果表明,无人机的轨迹规划与网络形成之间存在着紧密的时空耦合。与多个基线相比,我们的解决方案可以更好地利用无人机在数据卸载方面的协作,从而提高能源效率和延迟性能。
1.引言
最近,无人机(uav)已被用于各种无线网络,为地面无线设备提供信道访问,构成了未来物联网(IoT)的重要组成部分,如[1]和[2]。由于硬件的限制,由于有限的能源供应、远程部署位置和非视距(NLoS)信道条件[3],大部分低成本物联网设备可能难以满足数据传输中的服务质量(QoS)要求。这些困难可以通过部署无人机来协助从地面用户(GUs)到远程基站(BSs)或边缘服务器[4]的无线通信来解决。无人机的快速部署、移动性和灵活性使无人机辅助无线网络能够在超出无人机直接覆盖的大服务领域为不同的用户提供服务。它不仅可以扩大通信范围,还可以提高密集物联网的网络容量。
为了探索无人机辅助无线网络的性能增益,无人机的移动性应与收发器的控制策略共同进行优化。在文献中,无人机的移动性已经被用来提高无线网络中的数据速率、能源效率和信息年龄(AoI),如[5]、[6]、[7]。由于一个更好的GU-UAV(G2U)直接信道条件,无人机可以首先飞行到一个感兴趣的点,从gu接收信息,然后帮助将信息转发到远程BS。通过规划无人机的飞行轨迹,所有的gu都有望提高其数据速率,减少传输延迟。因此,我们可以提高整体网络吞吐量,并为更多的ἧ提供服务。该无人机还可以通过联合优化无人机的传输功率和无人机的运动轨迹[5]来提高无线网络的能源效率。与其直接通信到远程BS,图形用户模块可以以更高的数据率上传信息到附近的无人机,以及更低的传输功率。除了提高网络容量和能源效率外,无人机还可以通过规划无人机的运动轨迹,及时收集所有[7]的感知数据,及时收集[7]的信息感知,提高AoI。然而,无人机的轨迹优化是一种高维控制特别是在具有复杂时空耦合的多无人机辅助无线网络中。由于无人机的能量限制、飞行控制中的物理限制以及gu的不同服务需求,它可能会变得更加复杂。例如,多架无人机可以被派覆盖一个大的服务区。这可能会消耗更多的能量,为遥远的无人机报告他们的传感数据回到BS。另一方面,无人机也可以在一个小群中操作,以增加图形单元的信道访问概率。然而,由于无人机的相互干扰,这可能会降低能源效率,使无人机的传输调度复杂化。每架无人机的轨迹规划不仅影响其自身的能量或信息效率,而且还影响其他无人机当前和未来的轨迹。这种不同无人机之间的时空耦合使得优化无人机的任务协作和任务轨迹以满足大群无人机的服务更具挑战性。无人机之间的合作可以通过允许无人机对无人机(U2U)的直接通信来实现,例如,[8]和[9],从而形成无人机的多跳网络,即无人机的网络公式。无人机可以首先收集和缓存无人机的数据,然后当它们在轨迹上相遇时,将数据转发到附近的无人机。无人机也可以在不同的U2U链路之间进行动态切换,从而根据无人机的信道条件、能量状态和数据队列大小来调整网络的形成。
==无人机的联合轨迹优化和自适应网络的形成在文献中尚未得到很好的研究。==根据无人机的网络形成,轨迹优化可以在不同的时隙中离散,然后表示为每个时隙[10]中的机动性控制问题。优化方法通常需要关于gu的分布和交通需求的完整信息。这使得在动态网络环境中进行实际部署更加困难。无模型深度强化学习(DRL)方法也是一种很有前途的技术,以优化无人机的轨迹,如[11]和[12]。它可以通过与网络环境的交互来适应无人机的运动轨迹。DRL算法的典型实现依赖于BS的集中控制,它从所有无人机收集信息,并在每个时间步长联合调整它们的轨迹,以提高整体网络性能。随着无人机数量的增加,这可能需要过多的通信和训练管理费用。另一方面,无人机可以被视为独立的决策主体,它可以根据网络环境的局部观测来调整其轨迹。然而,这种多智能体分散的实现仍然需要集中的培训,这在通信开销方面可能代价高昂。上述挑战促使我们设计一种更有效的算法,共同优化无人机的轨迹和网络形成策略,以满足动态无线网络中gu的交通需求。
在本文中,我们关注多无人机辅助无线网络,并探索通过无人机合作的性能增益。我们的目标是通过联合优化无人机的飞行轨迹和网络形成,来最小化数据收集的时延和能量消耗,这通常被视为两个不同的设计问题,并分别解决[8]。**我们的分析表明,无人机的运动轨迹和网络的形成是密切依赖的。**我们预计无人机的轨迹根据GU的空间分布和交通需求的轨迹会非常不同。当两架无人机飞行距离很远时,它们的U2U通道就会恶化,甚至断开。这意味着无人机的网络形成应该能够适应无人机运动轨迹的变化。为此,我们提出了一种在无人机轨迹优化和自适应网络形成之间的两步迭代算法。自适应网络形成的基本思想是评估无人机的局部资源消耗,保证不同无人机之间的负载平衡。一旦无人机在当前时间段的轨迹变得不稳定,夸大了无人机不平衡的资源消耗,BS将初始化自适应网络的形成,以优化无人机的网络拓扑或信道分配。网络形成的变化进一步促使各无人机更新其轨迹,并利用多智能体深度确定性策略梯度(MADDPG)算法[13]来解决这个问题。此外,为了提高学习效率,我们提出了一种利用贝叶斯优化的动作估计机制来估计每个无人机更有益的动作。基于无人机过去的运动轨迹,动作估计可以避免无效的动作探索,并潜在地提高学习性能。仿真结果表明,与多个基线相比,联合轨迹规划和网络形成可以显著降低传输延迟。自适应网络的形成可以利用无人机的合作作用,有效地提高网络性能。与传统的MADDPG算法相比,贝叶斯优化增强的MADDPG算法具有更高的学习效率、稳定性和奖励性能。
具体来说,我们在本文中的主要贡献总结如下:
- 联合轨迹规划和网络形成:采用多架无人机从GUs中收集数据,并帮助将传感数据转发到远程BS。该无人机的自适应网络形成旨在通过允许U2U多跳中继通信来平衡不同无人机之间的流量负载和资源消耗。我们提出联合优化无人机的运动轨迹和网络形成,以利用无人机的合作增益。
- 能量感知和延迟感知的自适应网络的形成:我们提出了迭代更新无人机的运动轨迹和网络形成的两步解决方案。一旦无人机的轨迹导致资源消耗不平衡,将进行网络形成来恢复无人机之间的资源平衡。轨迹规划是基于MADDPG算法的,而网络的形成则是由无人机的状态信息,包括能量供应、信道条件和数据队列大小所驱动的启发式算法进行更新的。
- 贝叶斯优化增强的MADDPG:我们利用贝叶斯优化,基于过去的轨迹估计无人机的飞行位置,从而提高了传统MADDPG的学习效率。这可以指导无人机的轨迹学习走向一个更有回报的策略。DRL代理的动作探索也为贝叶斯优化提供了更多的样本信息,以做出准确的动作估计。大量的仿真结果表明,与传统的MADDPG算法相比,所提出的学习框架显著地提高了学习性能。
这项工作的一些初步结果已在一篇会议论文[14]中提出。本文进一步提出了贝叶斯优化方法,以提高MADDPG型无人机轨迹规划算法的学习性能。大量的仿真结果也验证了自适应网络的形成和无人机的运动轨迹可以平衡无人机的资源消耗,并最小化数据收集的延迟。本文的其余部分组织如下。第二节讨论了相关的工作。我们在第三节中介绍系统模型,在第四节中介绍了解决方案框架。在第五节中,我们进一步采用贝叶斯优化的方法进行动作估计,以提高学习效率。最后,数值结果和结论分别见第六节和第七节。
2.相关工作
A. Multi-UAV Cooperative Networks
无人机辅助无线网络的一个主要问题是优化无人机的运行轨迹,以最大限度地提高网络性能,如服务覆盖范围、整体网络吞吐量和传输延迟。现有的工作大部分集中在非合作案例上,通过考虑无人机和远程bs之间的直接联系,旨在优化单个无人机的轨迹和传输控制策略。例如,[15]的作者使用无人机从固定位置的图形中收集数据,旨在最小化温室的能源消耗。[16]的作者研究了无人机的放置策略,以最大化其覆盖范围下的无人机的数量。在不考虑U2U连接的情况下,[17]的作者提出了联合编队博弈来研究无人机在大服务区的任务分配问题。每架无人机将被分配一个专门的服务区,以避免资源冲突。这种非合作策略很容易实现,但直接的无人机-bs(U2B)链路可能会限制多无人机网络的服务范围。利用多跳U2U中继通信,增强远程GU[18]的数据采集,可以实现无人机间的任务协作。[19]论文中的作者提出了一种利用无人机将传感信息转发给基站的回程方案。提出了一种构建不同无人机间多跳通信无人机回程的网络编队博弈。[8]的作者进一步提出了一种子信道分配策略,通过联合优化无人机的信道分配和飞行控制,来提高网络编队的吞吐量性能。[20]的作者考虑了一个多跳无人机辅助中继网络来帮助地面上的一组收发器对相互通信。通过优化无人机的部署位置、发射功率和带宽分配,可以使最小传输速率最大化。同样,[9]的作者关注多跳无人机辅助任务卸载系统。无人机联合优化资源配置和部署策略,最大化实时计算能力。考虑到无人机有限的处理能力,在[21]中提出了一种基于距离的无人机合作方案,允许每架无人机向最近邻近的无人机寻求帮助。针对多跳MEC网络,在[22]提出了一种基于缓冲区的路由策略。基于时空流量统计,对[23]中边缘节点的缓存部署进行了优化。通过优化无人机的计算卸载和多跳路由策略,研究了[24]中MEC网络的多无人机路由问题。为了节省无人机在数据聚合中的能耗,[25]论文中的作者提出了针对无人机向接收机传输数据的不同路由方法。每架无人机既可以依赖于逐跳路由算法,也可以根据无人机的数据需求、位置和网络拓扑结构,通过联盟形成博弈算法形成一个联合结构。多无人机网络可以根据其网络状态,包括网络拓扑结构、信道条件、缓冲区大小、能量状态等,形成自适应网络,从而处理更复杂的感知任务,满足异构要求。这激发了我们的这项研究。
B. DRL for UAV-Assisted Wireless Networks
通过与环境的交互,DRL代理可以根据时变的工作负载需求和信道条件,调整无人机的运行轨迹和数据卸载策略。考虑到多个GUs,[26]的作者采用q学习算法,根据无人机的能量状态和位置来适应无人机的速度控制。[27]的作者提出了演员批评方法来优化使用多架无人机的数据收集。首先采用k均值聚类方法对不同的无人机进行聚合,然后采用行为批评方法对无人机的轨迹进行优化。在[28]中采用DDPG联合优化无人机的轨迹和传输调度策略。除了吞吐量最大化外,无人机的快速部署还有助于减少传输延迟或信息年龄(AoI)。[29]的作者研究了具有射频功率传输的无人机辅助无线网络中的AoI最小化。提出了DQN方法来适应无人机的飞行轨迹、无人机的调度和能量收集策略。[30]的作者研究了无人机辅助无线网络中的aoi-能量感知数据收集。提出了TD3算法,通过联合优化无人机的飞行速度、悬停位置和带宽分配进行数据收集,使平均AoI、无人机推进能量和gu传输能量的加权和最小化。
C. Multi-Agent DRL for Trajectory Optimization
多智能体DRL(MADRL)框架也被提出,以优化无人机的轨迹进行数据收集。[31]的作者开发了多智能体DQN方法,这是DQN方法对多无人机场景的一个简单扩展。[32]的作者将每架无人机视为一个独立的DQN代理,它根据其局部位置观察做出决策,以最大限度地提高覆盖所有GUs的实时下行容量。[33]的作者提出了MADDPG方法来优化无人机的目标分配和轨迹规划。MADDPG方法也被采用于[34],以确保无人机辅助无线网络的安全通信。[35]的作者使用了多架无人机来帮助从一组无人机中收集传感信息。提出了演员-评论家DRL方法,通过适应每个无人机的感知和飞行决策来最小化AoI。利用MADDPG算法优化无人机的飞行轨迹和传输策略,在[36]中研究了一个类似的问题。在[37]中提出了多智能体行为批评方法来适应无人机的行动,包括机动性控制策略、计算资源分配和卸载调度决策。[38]的作者研究了多无人机辅助的数据收集,其中无人机可以帮助激活gu,然后通过后向散射通信收集数据。每架无人机也可以飞回一个充电站,在能量不足时给自己充电。提出了一种多智能体深度选择学习(MADOL)算法,通过学习无人机-gus的关联策略来最小化无人机的总飞行时间。
3.系统模型
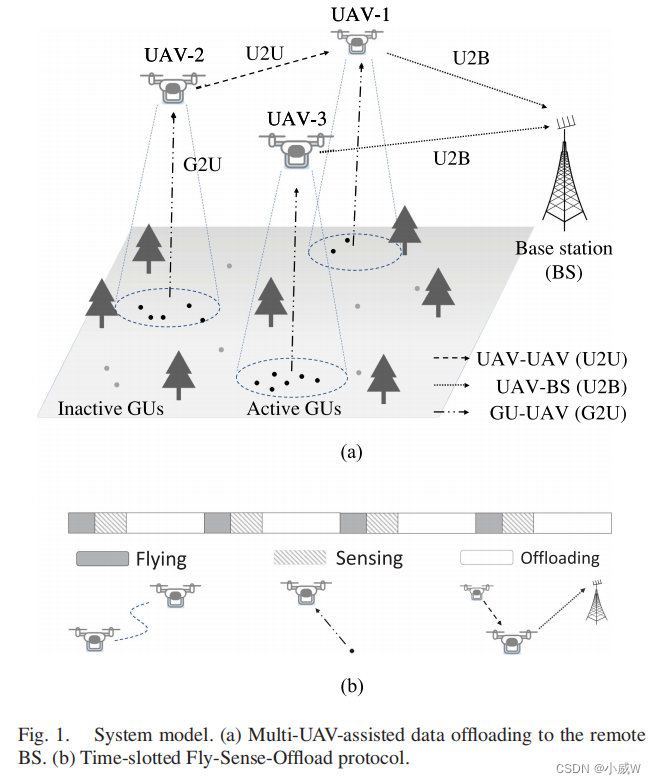
如图1所示,我们考虑了一个BS和多无人机的多无人机辅助无线网络,用集合N = {1,2,…,N}表示。有一组传感器或物联网用户设备,表示为M = {1,2,…,M},空间分布在地面上,可能超出与远程BS的直接通信范围。多架无人机可以四处飞行和收集来自 GUs 的传感数据。采集到的数据首先在无人机上进行缓冲,当无人机的信道条件变得更可取时,再转发到BS。每架无人机都有一个有限的缓冲区大小Dmax。当收集到的传感数据超过无人机的缓冲大小时,缓冲中断。根据无人机的信道条件和能量状态,每架无人机既可以直接连接到基站,也可以通过其他无人机将其信息传递给基站。直接U2U通信使无人机形成多跳网络拓扑,即网络形成,从而可能降低多跳中继通信的整体传输延迟和能耗。
A. Time-Slotted Fly-Sense-Offload Protocol
我们考虑一个如图1(b).所示的时槽框架结构。在每个时隙t∈T {1,2,…}中,每架无人机可以飞到不同的位置,从GUs中收集传感数据,然后将传感数据转发给BS或另一架无人机。每个时隙都有单位长度,可进一步分为三个子槽,即无人机飞行子槽
t
f
t_f
tf、数据传感
t
s
t_s
ts和卸载子槽
t
o
t_o
to。
在飞行子槽tf中,无人机将以可控的速度vi从一个位置飞行到另一个位置。
在传感子槽ts中,无人机将从无人机服务覆盖范围内具有最强传感信号的GU收集传感数据。每个GU m∈M有一个固定量的数据传输需求
W
m
W_m
Wm,当剩余的数据大小为零或无人机的缓冲空间变满时,它将停止传输。
在卸载子槽中,无人机可以直接将其部分数据卸载给BS或附近具有更更好的信道条件和能量供应的无人机。在数据卸载过程中,每架无人机还可以更新自己的状态信息到基站,包括其位置、缓冲区大小、能量状态和信道条件。
所有无人机状态信息的收集将有助于基站适应无人机的运动轨迹和传输控制策略。为简单起见,我们假设传感子槽
t
s
t_s
ts 是固定的,同时飞行和卸载子槽可以联合优化,以提高传输效率。用于多无人机辅助数据卸载的时隙飞感卸载协议允许gu、无人机和BS之间的三种类型的通信链路,具体如下:
- G2U通道用于无人机从GUs中收集数据。我们假设,由于物理障碍,从gu到BS的直接通道是无法获得的。所有的传感数据将由无人机收集,并重新路由到BS。当接收到的信噪比(SNR)达到最小阈值时,每个GU都可以成功地将其数据传输给无人机。
- 如果无人机接近BS,无人机可以使用U2B通道直接与BS通信。我们假设U2B通信依赖于一组专用的报告通道,它们在所有无人机之间共享。U2B信道的数据速率取决于无人机的位置、传输功率和信道条件。
- 在一些无人机远离BS的情况下,U2U通道可以用于连接附近的无人机。gu的传感数据可以通过多跳无人机中继通信转发给基站。
我们还假设每架无人机都有一个天线,因此它可以使用U2B或U2U信道传输数据。此外,U2U和U2B通道共享相同的频谱资源。考虑到有限的信道资源,这里所有无人机共享K个正交子信道,用集合K = {1,2,…,K}表示。一旦G2U链路建立,GU将把其传感数据上传到传感子槽中的无人机。数据收集后,无人机将更新其策略在飞行子槽到。鉴于无人机的悬停位置,每架无人机都可以在其信号覆盖范围下向gu广播一个飞行员信标信号。有流量需求的主动无人机可以以相同的传输功率响应无人机。然后,无人机可以估计不同GUs的信号质量,并选择信号强度最高的GU进行上行数据传输。这样,每架无人机都将获得有关gu的交通需求的信息。每个传感子插槽中的上行数据传输也可以扩展到多种接入场景。当选择多个GUs在同一传感子槽中上传数据时,无人机可以采用非正交多址(NOMA)技术或时分多址(TDMA)协议来协调无人机的上行数据传输,这超出了本文的讨论范围。
B. U2U Links and Network Formation
U2U连接允许无人机形成一个多跳无人机网络,将所有的传感数据转发给BS。我们将这种多跳回程称为无人机的网络形成,它指定了无人机之间U2U连接的可行性。根据无人机的网络形成,每架无人机都可以优化其轨迹,然后通过U2U或U2B通道转发缓冲数据。然而,随着无人机悬停位置的改变,无人机的网络形成可能会由于U2U信道条件的改变而过时。因此,无人机的网络形成必须与无人机的运动轨迹共同进行优化。具体来说,它应该根据无人机的通道条件、能量供应、缓冲区大小和位置进行动态调整。例如,当无人机远离BS时,直接的U2B信道可能会经历低信噪比和较大的传输延迟,这意味着更长的悬停时间和更高的能量消耗。在这种情况下,无人机可以通过使用U2U通道并在多跳中继网络中相互连接来改变网络的形成。在另一种情况下,当gu的数据流量分布不均匀时,一些无人机可能会收集大量的传感数据,而其他无人机的传感数据很少。不平衡的流量负载会导致数据传输的拥塞,增加传输延迟。因此,重载无人机可以通过使用高速U2U通道将数据卸载到其邻居。
为了便于符号,让UAV-0表示固定位置的BS,让˜N=N∪{0}表示包括UAV-0在内的所有无人机的集合。我们定义二进制矩阵
Φ
(
t
)
=
[
φ
i
,
j
k
(
t
)
]
i
,
j
∈
˜
N
,
k
∈
K
Φ(t) = [φ^k_{i,j}(t)]_{i,j∈˜N,k∈\mathcal{K}}
Φ(t)=[φi,jk(t)]i,j∈˜N,k∈K来表示U2U子信道分配策略,即
φ
i
,
j
k
(
t
)
=
1
φ^k_{i,j}(t) = 1
φi,jk(t)=1表示第k个子信道用于UAV-i和UAV-j之间的U2U信道。很容易看到
φ
0
,
j
k
(
t
)
=
0
φ^k_{0,j}(t) = 0
φ0,jk(t)=0 和
φ
j
,
j
k
(
t
)
=
0
φ^k_{j,j}(t) = 0
φj,jk(t)=0为所有的
j
∈
˜
N
j∈˜{N}
j∈˜N。我们要求每个子信道都可以用于信息的传输或接收。因此,无人机的子信道分配受到以下约束:
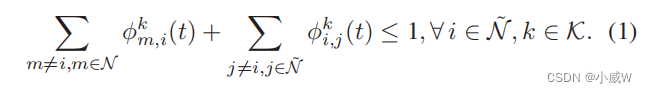
公式分成 m , i m,i m,i 和 i , j i,j i,j 可能是为了表达从 m 到 i 以及从 i 到 j 的U2U信道。
很明显, Φ ( t ) Φ(t) Φ(t) 的可行集指定了无人机的所有可能的网络形成结构。
C. Channel Models and Data Offloading Rates
我们假设所有无人机在固定高度H飞行,以收集gu的传感数据。我们的问题公式和解决方案可以很容易地扩展到时变飞行高度的情况。每个UAV-i的轨迹可以定义为在不同时间段上的一组位置点,即Li=[i(t)]t∈T,其中每个时间段中的位置i (t)由三维(3D)坐标指定,即 ℓ i ( t ) = ( x i ( t ) 、 y i ( t ) 、 z i ( t ) = H ) \ell_i(t)=(x_i (t)、y_i (t)、z_i (t) = H) ℓi(t)=(xi(t)、yi(t)、zi(t)=H)。BS位于坐标的原点,天线的高度由 H b H_b Hb 给出。考虑到 U A V − i UAV-i UAV−i 以有限的速度 v i ( t ) ≤ v m a x v_i (t)≤v_{max} vi(t)≤vmax 向 d i ( t ) d_i(t) di(t)方向移动,UAV-i在下一个时间段t + 1中的位置由 ℓ ( t + 1 ) = ℓ i ( t ) + v i ( t ) d i ( t ) \ell(t + 1)=\ell_i(t) + v_i (t)d_i (t) ℓ(t+1)=ℓi(t)+vi(t)di(t)给出。UAV-i和UAV-j之间的距离由 d i , j ( t ) = ∣ ∣ ℓ i ( t ) − ℓ j ( t ) ∣ ∣ d_{i,j}(t) = ||\ell_i(t)−\ell_j (t)|| di,j(t)=∣∣ℓi(t)−ℓj(t)∣∣给出。
通常,它是无人机和BS之间的视距(LoS)传输。当UAV-i将传感数据转发到子通道k∈K上的UAV-j时,在UAV-j处的接收信号功率可以表示为 p j , i k ( t ) = p i k β i , j u ( d i , j ( t ) ) − α u p^k_{j,i}(t)=p_i^k\beta^u_{i,j}(d_{i,j}(t))^{-\alpha_u} pj,ik(t)=pikβi,ju(di,j(t))−αu,其中 p i k p_i^k pik 表示无人机 UAV-i 在第 k 个子信道的传输功率, β i , j u \beta^u_{i,j} βi,ju 是由收发器的放大器和天线引起的恒定功率增益。路径损耗 ( d i , j ( t ) ) − α u (d_{i,j}(t))^{-\alpha_u} (di,j(t))−αu 依赖于收发器之间的距离,并且 α u \alpha_u αu 表示路径损耗的常数。
关于公式的解释

由于所有的无人机共享同一组信道,因此在不同的收发器之间可能会发生干扰。特别是,如果UAV-m(对于
m
≠
i
m\neq i
m=i)也在子信道k上传输,则对UAV-j的干扰如下:

即所有从m传输到n的传输功率。?
因此,从UAV-i到UAV-j(对于i,j∈˜N)在所有子信道上的卸载速率确定如下:
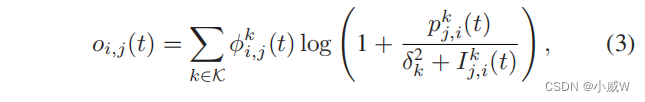
其中,
δ
k
2
δ^2_k
δk2表示第k个子信道上的噪声功率。
同样,我们也可以定义从gu到无人机的信道模型。我们假设每架无人机只在其覆盖LoS信道条件下的gu中收集数据。因此,我们可以采用与U2U和U2B信道类似的对数-距离路径损失模型。设qm表示GU-m的发射功率,dm,i (t)表示GU-m与UAV-i之间的距离。从GU-m到无人机-i的数据速率为
u
i
,
m
(
t
)
=
log
(
1
+
q
m
β
m
,
i
s
(
t
)
)
−
α
s
)
u_{i,m}(t)=\log{(1+q_m\beta^s_{m,i}(t))^{-\alpha_s})}
ui,m(t)=log(1+qmβm,is(t))−αs)。其中
α
s
α_s
αs为路径损耗常数,
β
m
,
i
s
β^s_{m,i}
βm,is表示接收机噪声功率归一化的参考点的信道增益。
注意我们忽略了不同gu之间的相互干扰。这是合理的,因为不同的无人机将停留在不同的位置来收集gu的传感数据。无人机的空间分离避免了GUs在向不同无人机上传信息时的干扰。
D. Data Queue Dynamics at GUs and UAVs
我们的目标是优化无人机的飞行轨迹和网络形成,以最小化传输延迟和总能耗。最初,GU-m有一个固定数量的传感数据Wm,需要卸载到BS。给定固定的传感子槽ts,无人机-i可以从gu中收集部分传感数据,然后将缓冲数据转发到附近的无人机或卸载子槽中的BS。因此,随着时间的推移,无人机和无人机的数据队列会动态更新。对于每个GU-m,其数据队列可以更新如下:
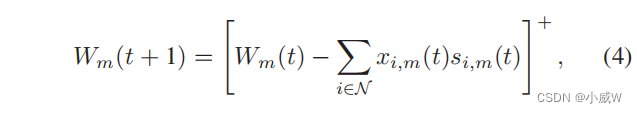
其中
[
X
]
+
=
m
a
x
{
0
,
X
}
[X]^+ = max\{0,X\}
[X]+=max{0,X},我们定义
s
i
,
m
(
t
)
s_{i,m}(t)
si,m(t) 为由无人机-i收集的GU-m的传感数据的量。二进制变量
x
i
,
m
(
t
)
∈
{
0
,
1
}
x_{i,m}(t)∈\{0,1\}
xi,m(t)∈{0,1} 表示第t个时间段内的UAV-i和GU-m之间的关联,即如果
x
i
,
m
(
t
)
=
1
x_{i,m}(t) = 1
xi,m(t)=1,则将收集UAV-i的传感数据
s
i
,
m
(
t
)
s_{i,m}(t)
si,m(t)。通常情况下,由于GU有限的传输能力,我们要求每个GU在每个时隙[8]中最多连接一架无人机,即
∑
i
∈
N
x
i
,
m
(
t
)
≤
1
\sum_{i∈N}x_{i,m}(t)≤1
∑i∈Nxi,m(t)≤1。
让
M
i
M_i
Mi 表示无人机-i的覆盖范围中的gu集合。然后,对于每个无人机-i,从gu中收集到的传感数据的大小可以表示如下:
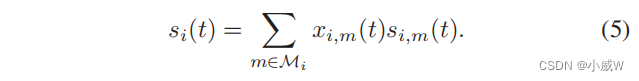
除了新的传感数据si (t)外,无人机-i还可以从其他无人机接收数据。让
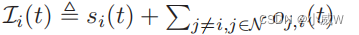
表示到无人机-i的缓冲空间的输入数据。
在卸载的子槽
t
o
t_o
to中,无人机-i将其数据转发到附近的无人机或BS。我们将
O
i
(
t
)
O_i(t)
Oi(t) 定义为如下表示无人机-i的输出数据:
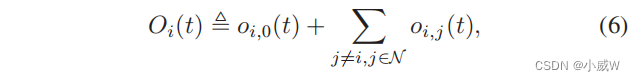
其中,卸载速率
o
i
,
j
(
t
)
o_{i,j}(t)
oi,j(t)在(3)中定义。(6)中的第一项
o
i
,
0
(
t
)
o_{i,0}(t)
oi,0(t)是发送给BS的数据,第二项
∑
j
≠
i
,
j
∈
N
o
i
,
j
(
t
)
\sum_{j\neq i,j∈N}o_{i,j}(t)
∑j=i,j∈Noi,j(t)表示转发给其他无人机的数据。因此,无人机-i的数据队列动态可以表示如下:
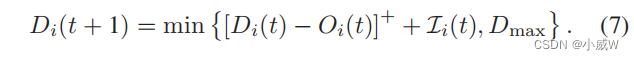
在本文中,我们考虑了一个简单的数据收集策略,即每个无人机被分配给在其覆盖范围下与具有最好信号质量GU。因此,集合Mi总是包含一个对UAV-i信号强度最强的GU,记作GU-m,这可以很容易地确定给定无人机-i的位置。给定传感时间 t s ( t ) t_s(t) ts(t),传感数据的大小可以按如下被计算:
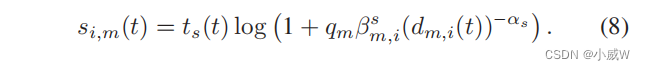
4.PROBLEM FORMULATION AND LEARNING-BASED SOLUTION 问题的制定和基于学习的解决方案
在收集到传感数据后,每架无人机-i将在数据卸载子槽ti,o期间,将缓冲数据转发给附近的无人机或BS。然后,它将飞到飞行子槽ti,f中的下一个点。每架无人机的能耗主要取决于其飞行速度vi (t)、悬停时间ti,o和空中飞行时间ti,f。
我们可以利用[39]中著名的能量模型来描述无人机-i在第t个时间段中的操作能量消耗
e
i
(
t
)
e_i(t)
ei(t)。另外,设
p
i
(
t
)
=
∑
j
∈
N
∑
k
∈
K
t
i
,
o
p
i
,
j
k
φ
i
,
j
k
(
t
)
p_i(t) =\sum_{j∈N}\sum_{k∈K}t_{i,o}p^k_{i,j}φ^k_{ i,j}(t)
pi(t)=∑j∈N∑k∈Kti,opi,jkφi,jk(t) 表示数据卸载时的能量消耗。因此,无人机-i在每个时间段的总能量消耗由
e
^
i
(
t
)
=
e
i
(
t
)
+
p
i
(
t
)
\hat{e}_i(t)=e_i(t)+p_i(t)
e^i(t)=ei(t)+pi(t) 给出。至此,我们可以将能量最小化问题表述如下:
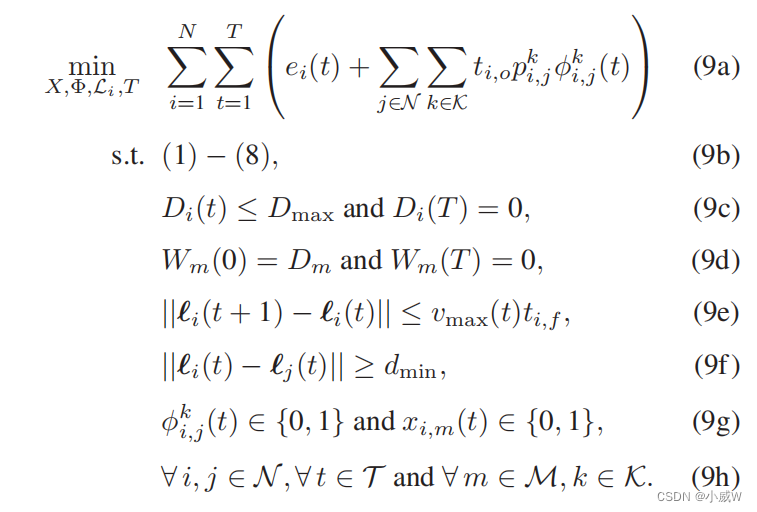
我们的目标是优化网络形成Φ(t)和二进制矩阵X(t)=[xi,m(t)]i∈N,m∈M,它指定了每个时间段t∈T中的G2U关联策略。所有这些矩阵变量都应与无人机对i∈N的轨迹Li共同优化。我们还优化了完成所有gu的数据卸载到远程BS所需的总时间槽数T。
为简单起见,我们可以考虑本文中节所述的固定数据收集策略,即每个无人机-i只从信号强度最高的GU中收集传感数据。因此,G2U关联矩阵X (t)可以知道给定无人机在每个时隙的位置。(1)-(8)中的约束条件规定了无人机和GUs的子信道分配策略和缓冲动力学。(9c)-(9d)中的约束条件确保了所有gu的传感数据都在T个时隙后能够成功地卸载到BS中。(9e)和(9f)中的不等式限制了无人机在不同时隙内的飞行轨迹。实际上,无人机在目标(9a)中的发射功率远低于无人机悬停和飞行的功耗,因此在优化问题中可以省略。
问题(9)是一个混合整数问题,由于无人机的网络形成和轨迹规划之间的时空耦合,难以有效解决。时间跨度T的优化进一步使问题重组不灵活。
一个优化问题是混合整数问题,当且仅当它的一些变量是整数,而其他变量是实数。如果所有变量都是实数,则该问题是连续优化问题。如果所有变量都是整数,则该问题是整数优化问题。混合整数问题通常比连续优化问题和整数优化问题更难求解 ²。
给定一个固定的时间槽数量,无人机和gu可能在其缓冲空间中有剩余的数据,即(9c)-(9d)中的约束可能在T个时间槽结束时不成立。因此,我们修改了(9a)中的目标,将缓冲区中的剩余数据考虑在内,作为惩罚项,并将(9)重新表述为一个联合优化问题,如下:
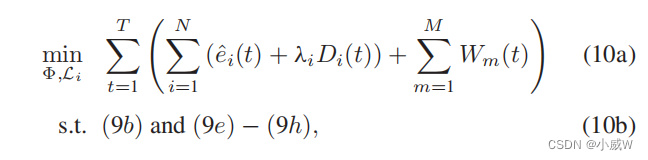
其中,λi是一个常数参数,用于在无人机的能耗和数据队列大小之间进行权衡。这里我们省略了(9a)中无人机的传输功耗,这比远低于悬停和飞行的功耗。
给定一个固定数量的T时隙,我们的目标是共同最小化无人机和GUs的总能量消耗和队列大小。在后续研究中,我们将问题(10)分解为无人机的网络形成和轨迹规划子问题,设计了一个近似解。
A. Adaptive Network Formation(笔者注:一个简单的启发式算法)
在第一个子问题中,我们根据给定无人机的轨迹Li调整无人机的网络形成Φ(t)。因此,我们可以进一步简化问题(10)如下:
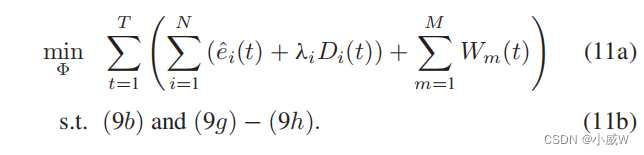
问题(11)变成了一个非线性整数程序。虽然可以用现有的分支和边界方法来求解,但由于无人机和无人机的缓冲空间在不同时间段内的动态演化,它具有很高的计算复杂度。因此,我们提出了一种简单的启发式算法,即能量和延迟感知网络形成(EDANF)算法,以根据无人机的能量消耗和缓冲状态来适应网络形成。
EDA-NF算法的基本思想是在飞行中平衡无人机的能量消耗和队列大小。在每个卸载子槽
t
i
,
o
t_{i,o}
ti,o中,无人机-i还向BS报告其当前状态,包括其位置i (t)、当前网络形成Φ(t)、能耗eˆi (t)和缓冲信息
λ
i
D
i
(
t
)
+
∑
m
∈
M
i
W
m
(
t
)
λ_iD_i(t) +\sum_{m∈M_i}W_m(t)
λiDi(t)+∑m∈MiWm(t),其中包括无人机-i的缓冲大小Di (t)和无人机-i覆盖范围下所有无人机的流量需求。当BS收集所有无人机的状态信息时,它将调整网络编队Φ(t),以平衡无人机的能耗和队列大小。我们假设无人机的状态信息规模较小,不会造成太大的开销。我们首先设计了一个负载平衡系数
b
i
(
t
)
b_i(t)
bi(t)来描述UAV-i的流量相对于整体网络流量的状况,如下所示:
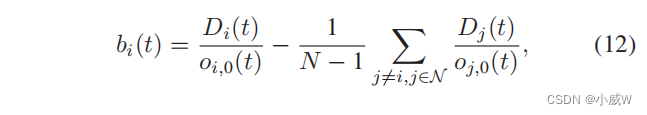
这取决于无人机在缓冲区中的数据大小和通过U2B通道的传输能力。第一项 D i ( t ) o i , 0 ( t ) \frac{D_i(t)}{o_{i,0}(t)} oi,0(t)Di(t) 表示无人机-i通过U2B通道将其数据转发到BS时的预期时间延迟。(12)中的第二项表示所有其他无人机通过其U2B通道的平均时延。如果无人机-i和其他无人机之间的数据流量不平衡,例如,无人机-i在缓冲区中有一个相对较大的数据量,但U2B信道条件较差,我们可以期望一个较大的值 ∣ b i ( t ) ∣ |b_i (t)| ∣bi(t)∣。在这种情况下,无人机-i不需要使用U2B通道,而是与附近的无人机建立U2U链接,并通过更可取的U2U通道卸载部分数据。值得注意的是,网络的形成可能不需要在每个时隙中频繁地更新。特别是,如果所有无人机的负载平衡系数都相对较小,网络的形成将保持不变。
除了负载平衡系数bi (t)外,我们还进一步定义了每个UAV-i的成本函数如下: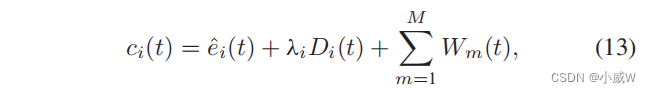
这体现了无人机-i的资源需求,包括其能源消耗eˆi(t)和交通需求。较大的成本值ci (t)意味着无人机需要更多的能量,并由于数据卸载的信道条件不理想而导致过多的传输延迟,而系数bi (t)表征了U2B的直接传输能力。我们首先根据系数bi (t)将所有无人机分为两组,分别用子集g1和g2表示。无人机-i的bi (t)值较大,具有相对沉重的工作量和不令人满意的信道条件。在这种情况下,我们希望为UAV-i建立U2U链路,将其数据卸载到邻近的无人机。因此,我们可以考虑g1和g2之间基于阈值的划分。当bi (t)大于一个阈值bo时,UAV-i分配给集合G1,否则分配给集合G2。G1组中的每架无人机都可以与其他无人机建立U2U连接,而G2组中的无人机有直接的U2B连接。
EDA-NF算法的思想是在两个子集的无人机之间建立U2U连接,从而允许G1中的重载无人机将数据卸载到G2中的轻载无人机。我们可以将U2U信道分配给成本值ci (t)最高的UAV-i,并选择成本值最小cj (t)的子集的UAV-j作为无人机-i的中继节点。我们还需要确保从无人机-i到无人机-j的U2U通道应该满足一个最低的数据速率要求。具体步骤列于算法1中。请注意,算法1依赖于网络状态信息来估计(12)和(13)中的值。阈值bo也是一个关键的设计参数,可以在离线阶段进行实验估计。网络信息可以由无人机收集,并与数据传输一起转发给基站。无人机可以依靠握手协议来建立U2U链接。发射无人机可以向目标无人机发送U2U请求。如果目标无人机不愿意作为中继节点,那么它们之间的U2U链路将是不可行的。
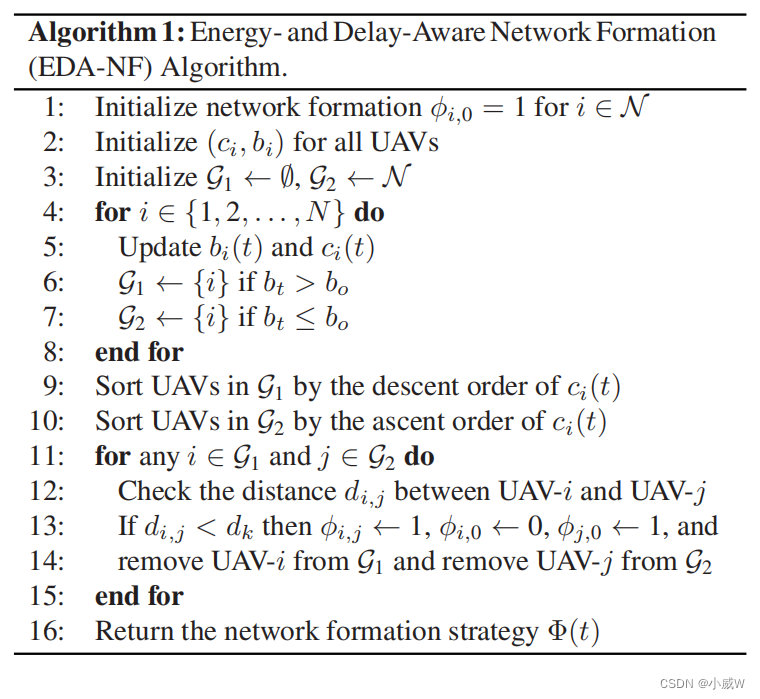
按负载平衡系数 b i ( t ) b_i(t) bi(t)分给G1和G2。(负载压力大的给G1)
按资源需求降序排序G1,升序排序G2。
检查i和j无人机之间的距离,如果小于一个阈 d k d_k dk,就建立U2U连接。
B. Learning for Trajectory Optimization
给定网络形成Φ(t),第二个问题是更新无人机的轨迹如下:
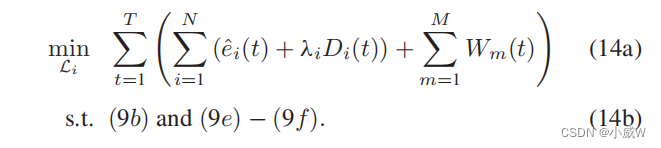
(14)中的轨迹优化是高维的,由于不同无人机之间的时空相互作用,仍然难以直接求解。在后续中,我们提出了问题(14)的无模型DRL方法,将其重新表述为马尔可夫决策过程(MDP)。
(1)MDP Reformulation 马尔可夫决策过程
MDP可以简单地用一个元组(S、A、R)来表征,其中S和a分别表示状态空间和动作空间。奖励函数R分配每个状态-动作对(s (t),a (t))一个质量评估。对于多无人机网络,状态s (t)包括所有无人机的局部状态,即s (t)=(s1(t)、s2(t),…,sN (t))。每架无人机的局部状态si (t)包括其位置 ℓ i ( t ) \ell_i(t) ℓi(t)、网络形成 { φ i , j ( t ) } j ∈ ˜ N \{φ_{i,j}(t)\}_{j∈˜N} {φi,j(t)}j∈˜N、能量状态 E i ( t ) E_i(t) Ei(t)和缓冲区大小 D i ( t ) D_i(t) Di(t)。类似地,我们有一个(t)=(a1(t),a2(t),…,aN (t))作为所有无人机的联合行动。每个无人机的动作ai(t)包括每个时间步长中的飞行方向 d i ( t ) d_i(t) di(t)和速度 v i ( t ) v_i(t) vi(t)。
当每个无人机在第t个时间段执行状态s (t)时,可以获得奖励Ri(s(t),ai (t))。很明显,无人机-i的奖励也取决于其他无人机的行动,表示为一个−i(t)。具体而言,奖励功能
R
i
(
s
(
t
)
、
a
i
(
t
)
)
R_i(s(t)、a_i (t))
Ri(s(t)、ai(t))可分为三部分:能量奖励
R
i
,
e
(
t
)
R_{i,e}(t)
Ri,e(t),传递奖励
R
i
,
d
(
t
)
R_{i,d}(t)
Ri,d(t)和感知奖励
R
i
、
c
(
t
)
Ri、c(t)
Ri、c(t)。能量奖励被简单地定义为无人机-i的能量消耗的负值:
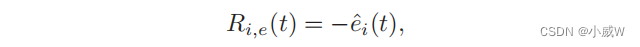
这就敦促无人机-i减少其能源消耗。为了减少传输延迟,每架无人机如果尽可能多地转发数据,就会得到一个奖励。因此,传输奖励
R
i
,
d
(
t
)
R_{i,d}(t)
Ri,d(t) 与成功传输到BS或下一跳无人机的数据的大小成正比,即,
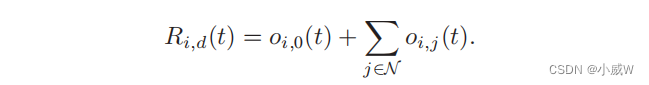
感知奖励用于促进无人机从无人机中收集更多的数据。因此,我们将UAV-i的感知奖励 R i , s ( t ) R_{i,s}(t) Ri,s(t)定义为从其覆盖范围内GUs中收集到的感知数据的大小:
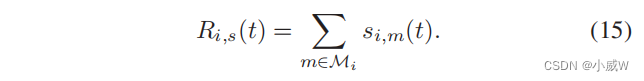
除上述奖励条款外,还附加了一个附加的惩罚条款
R
i
,
p
(
t
)
R_{i,p}(t)
Ri,p(t),以确保无人机-i与其他无人机之间的最小安全距离。如果(9f)中的约束不成立,我们可以简单地给
R
i
,
p
(
t
)
R_{i,p}(t)
Ri,p(t) 分配一个更大的值,即,
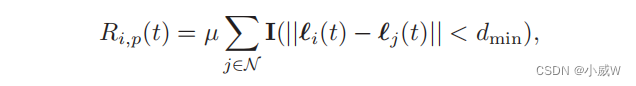
其中,
I
(
⋅
)
I(·)
I(⋅) 表示一个指标函数。为此,我们可以使用不同的组合权重
γ
i
γ_i
γi 来定义UAV-i在每个时间段内的总体奖励函数如下:
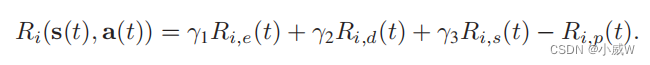
(2)Multi-Agent DRL 多代理深度强化学习
(14)中的连续控制问题可以由actor-critic DRL框架灵活处理,分别使用两组深度神经网络(DNNs)来近似策略函数和值函数。设θ表示无人机策略函数的DNN参数,即actor网络。以确定性策略为重点,参数化的 actor-网络 π ( s t ∣ θ ) π(s_t|θ) π(st∣θ) 将在每个状态 s t s_t st 上生成一个确定性动作 a t = π ( s t ∣ θ ) a_t=π(s_t|θ) at=π(st∣θ),以最大化定义如下的值函数:
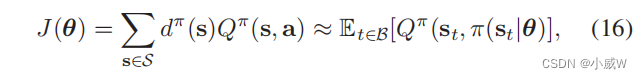
其中,
d
π
(
s
)
d^π(s)
dπ(s) 表示在
a
t
=
π
(
s
t
∣
θ
)
a_t= π(s_t|θ)
at=π(st∣θ) 处遵循确定性策略的稳态分布。给定一个有限的状态转移样本集,我们可以使用采样空间
B
B
B上的期望来近似(16)中的值函数
J
(
θ
)
J(θ)
J(θ)。Q值
Q
π
(
s
t
,
a
t
)
Q^π(s_t,a_t)
Qπ(st,at)有助于评估策略
π
(
s
t
∣
θ
)
π(s_t|θ)
π(st∣θ) 的质量,即大的Q-值意味着在未来的时间步中访问相同状态
s
t
s_t
st时,
a
t
=
π
(
s
t
∣
θ
)
a_t= π(s_t|θ)
at=π(st∣θ) 的操作可能更可取。然而,真正的Q-值在在线学习过程中可能是不可用的。我们进一步要求具有DNN参数w的criitic-网络来近似它,记为
Q
π
(
s
t
,
a
t
∣
w
)
Q^π(s_t,a_t|w)
Qπ(st,at∣w)。因此,(16)中的值函数分别依赖于行为网络和批评者网络的DNN参数
θ
θ
θ和
w
w
w。
取
J
(
θ
)
J(θ)
J(θ)对策略参数
θ
θ
θ的导数,我们可以通过梯度上升方向更新actor网络,以改进值函数
J
(
θ
)
J(θ)
J(θ)。通过确定性策略梯度(DPG)定理[40],该策略梯度可估计如下:
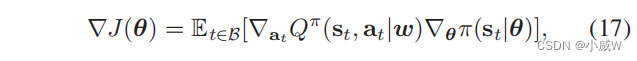
(17)中的策略梯度同时依赖于参与者网络和批评者网络中的参数梯度,这可以很容易地通过梯度反向传播的方法进行评估。批评网络可以通过在线批评网络 Q π ( s t , a t ∣ ∣ w ) Q^π(s_t,a_t||w) Qπ(st,at∣∣w) 与其目标 y t = r t + γ Q π ( s t ′ , a t ′ ∣ w ) y_t=r_t+γQ^π(s_t',a_t'|w) yt=rt+γQπ(st′,at′∣w) 之间的时间差(TD)误差进行更新,其中 r t r_t rt 表示即时奖励, w ′ w' w′ 表示目标批评网络的DNN参数。批评网络的目的是通过梯度下降方向最小化TD误差:
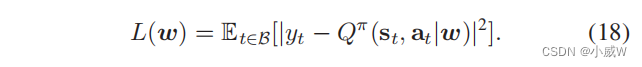
TD error 的计算提供了一个指标,告诉我们我们的 Q 值预测与真实情况相比是如何偏离的,因此它常常用作网络的损失函数的一部分,指导网络参数的更新。
为了提高学习的稳定性,actor网络和critic网络都有其目标版本,参数分别为 θ ′ θ' θ′ 和 w ′ w' w′,可以从在线参数 ( θ , w ) (θ,w) (θ,w)[11]平滑地更新。
使用目标Critic网络的主要目的是为了让学习过程更稳定、减少震荡,并确保更连贯、更平滑的学习曲线。
在多无人机辅助无线网络中,每架无人机的观测不仅取决于自身的行动,还与其他无人机的行为有关。我们可以使用MADDPG算法来学习无人机的轨迹,通过使用集中训练和分散执行方案[40]。上述(16)-(18)中的分析需要稍微修改。具体地说,我们假设每个UAV-i都是一个独立的DRL代理,策略参数为θi,它基于它自己对系统的观察,使用确定性策略
π
i
(
o
i
∣
θ
i
)
π_i(o_i|θ_i)
πi(oi∣θi)输出自己的动作
a
i
a_i
ai。请注意,由于部分可观测性[13],无人机-i的观测oi并不是完全的系统状态。每架无人机-i也有自己的q值估计,这取决于所有无人机的联合行动。令
o
−
i
o_{−i}
o−i 和
a
−
i
a_{−i}
a−i 分别表示其他无人机的观测和作用。我们可以在(17)中修改UAV-i的策略梯度如下:
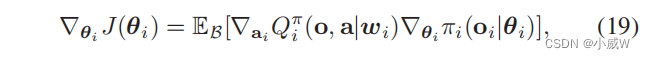
就是把 s t s_t st和 a t a_t at换成了 o o o和 a a a。
其中, o = ( o i , o − i ) o=(o_i,o_{−i}) o=(oi,o−i)和 a = ( a i , a − i ) a=(a_i,a_{−i}) a=(ai,a−i)表示所有无人机的联合观测和行动。这个期望考虑了经验重放缓冲区 B B B中的所有样本。
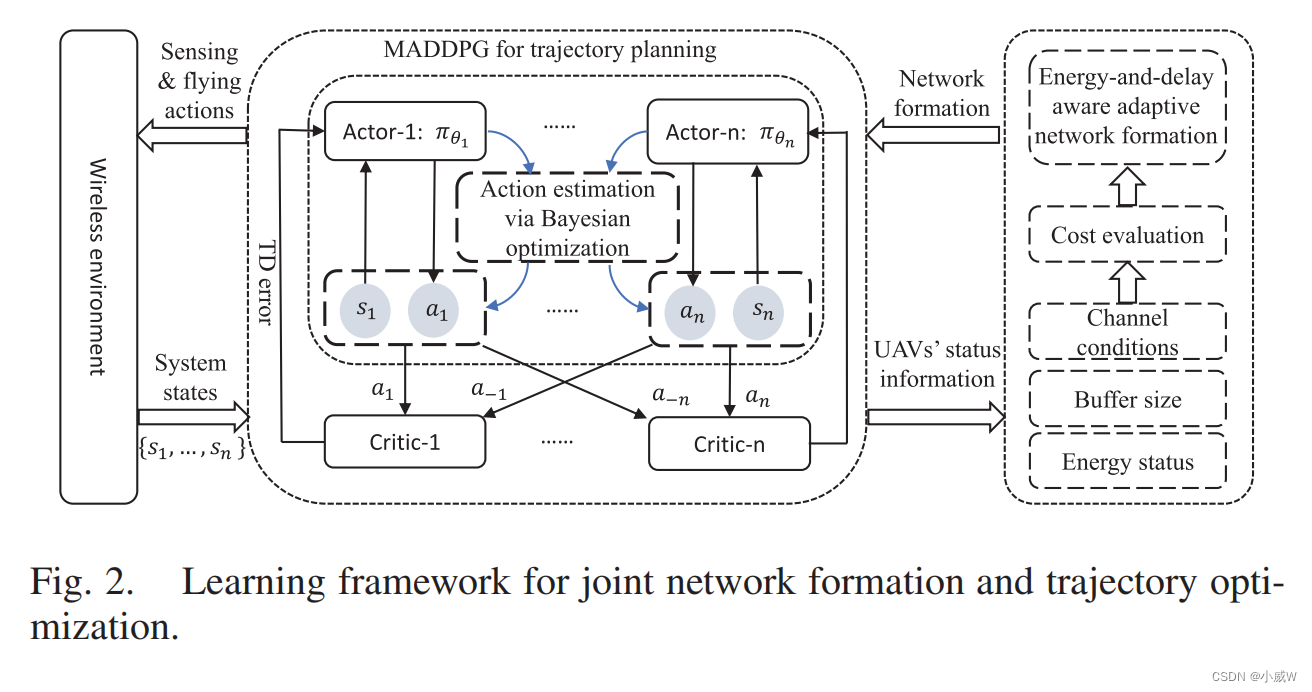
(19)中对个体无人机策略梯度的修正表明,actor 网络πi(oi|θi)可以被本地化,而 critic 网络Qπi(o,|wi)需要全局信息(o,a)。这激发了流行的多智能体系统的集中训练和分散执行方案。离线阶段的集中训练要求BS收集所有无人机的状态更新,并同时训练批评者和参与者网络。经过离线训练后,批评者和行为网络可以被宣布到不同的无人机上,并以分散的方式来指导它们的决策和行动执行。联合网络的形成和轨迹优化的算法框架如图2所示。给定网络形成 Φ ( t ) Φ(t) Φ(t),每个无人机-i通过使用MADDPG算法搜索下一步时间步的最佳飞行动作来更新其轨迹 L i \mathcal{L}_i Li。然后,每架无人机按照其轨迹收集gu的传感数据,并将其转发给BS或下一跳无人机。同时,无人机可以报告其状态更新到BS。因此,BS可以分别通过评估(12)和(13)中无人机的负荷平衡系数和成本函数来检验当前网络形成策略 Φ ( t ) Φ(t) Φ(t) 的质量。如果当前的网络形成夸大了网络条件,如不平衡的能耗和缓冲区大小,则需要自适应网络改造来恢复无人机之间的资源消耗的平衡。
5.ACTION ESTIMATION FOR MADDPG VIA BAYESIAN OPTIMIZATION 通过贝叶斯优化对MADDPG的行动估计
MADDPG算法为多智能体系统中的复杂控制问题提供了一个通用的求解框架。然而,将其直接应用于多无人机的轨迹优化问题仍然具有挑战性。首先,它需要收集所有无人机的观测结果,然后共同调整它们的飞行动作。每架无人机都需要向BS报告其局部观测结果,包括信道信息、能量状态和其缓冲区中的队列大小。由于多跳中继通信中的传输延迟,这在快速变化的无人机网络中可能存在问题。由于无人机的机动性,在基站上进行集中训练的全球信息可能会过时。此外,随着无人机数量的增加,状态空间和行动空间迅速增加。交换无人机的局部观测和行动的通信开销也变得很重要。这导致了过多的训练开销,并导致收敛的不稳定性。
在这一部分中,我们旨在通过使用贝叶斯优化来估计无人机在下一步时间步[41]中的最佳飞行动作,来提高MADDPG的学习效率。鉴于无人机沿着过去的轨迹的观察结果,贝叶斯优化为基于现有采样数据的无模型预测提供了一个通用的数学框架。其基本思想是,与随机行动探索相比,通过贝叶斯优化进行的行动估计可以提供一个更好的行动探索方向。因此,它可以指导无人机的轨迹学习走向一个更有益的政策。这种引导学习可以通过向DRL代理提供动作估计而被视为半监督学习。这在多智能体学习的早期阶段非常有用,在那里随机行动探索可能需要大量的学习片段来热身。
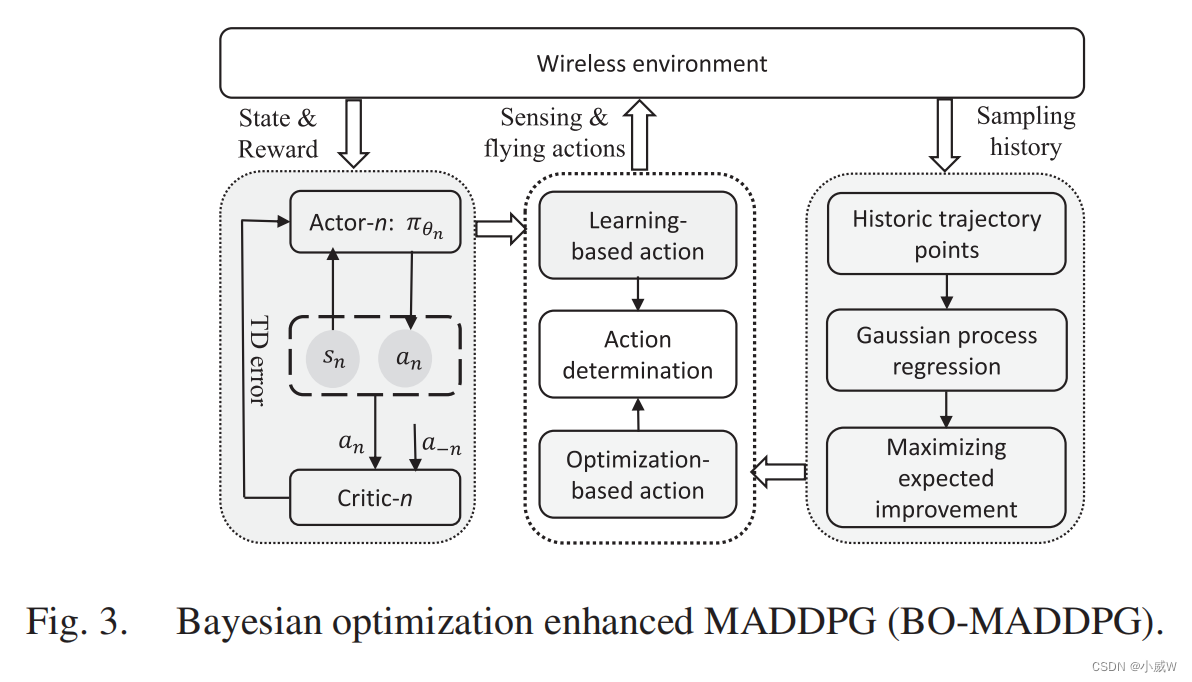
贝叶斯优化增强型MADDPG框架(记为BO-MADDPG)可分为三个部分如图3所示。动作估计模块以无人机的最新轨迹点作为输入,利用贝叶斯优化方法估计下一步时间步的最佳飞行位置。动作估计将与参与者网络学习到的动作一起进一步输入到批评网络。然后,批评者网络根据当前的观察结果来评估两种行为的质量。评论家的质量评估有助于决定将在网络环境中执行哪个操作。通常,我们可以选择一个更有回报的行动和更高的概率,并避免无果的行动探索。这可能会潜在地减少动作空间,并提高多智能体的学习效率。
A. Action Estimation Via Bayesian Optimization 通过贝叶斯优化进行的动作估计
MADDPG算法通过试错探索来适应无人机的轨迹点,其效率非常低,特别是在学习的早期阶段。贝叶斯优化算法可以更简单、更有效地估计无人机的轨迹点。具体来说,我们首先将多无人机轨迹规划问题分解为N个单无人机轨迹规划问题。然后,我们可以对每个无人机进行贝叶斯优化,以估计其在下一个时间步中的飞行动作。
(1)Data-Driven Probabilistic Model 数据驱动概率模型
对于每个UAV-i,设
ℓ
i
(
t
)
\ell_i(t)
ℓi(t)表示其位置,
s
i
(
t
)
=
∑
m
∈
M
i
s
i
,
m
(
t
)
s_i(t) =\sum_{m∈M_i}s_{i,m}(t)
si(t)=∑m∈Misi,m(t) 表示UAV-i在第 t 个时间段收集的传感数据,其中
s
i
,
m
(
t
)
s_{i,m}(t)
si,m(t) 由(8)给出。定义如下内容的函数:
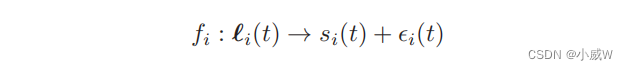
将每个位置点
ℓ
i
(
t
)
\ell_i(t)
ℓi(t) 映射到从GUs中收集到的数据大小
s
i
(
t
)
s_i(t)
si(t)。请注意,函数值
f
i
(
ℓ
i
(
t
)
)
f_i(\ell_i(t))
fi(ℓi(t)) 仅提供了采样数据
s
i
(
t
)
s_i(t)
si(t) 的近似值。
s
i
(
t
)
s_i(t)
si(t) 和
f
i
(
ℓ
i
(
t
)
f_i(\ell_i(t)
fi(ℓi(t) 之间的误差项
ϵ
i
(
t
)
\epsilon_i(t)
ϵi(t) 可以看作是零均值的独立同分布的高斯噪声。通过使用贝叶斯优化,我们的目标是建立一个基于一组历史采样点的概率模型
P
(
f
i
(
H
t
)
∣
D
i
(
t
)
)
P(f_i(H_t)|D_i (t))
P(fi(Ht)∣Di(t)),记为
D
i
(
t
)
=
(
ℓ
i
(
τ
)
,
s
i
(
τ
)
)
τ
∈
H
t
D_i (t)=(\ell_i(τ),s_i(τ))_{τ∈H_t}
Di(t)=(ℓi(τ),si(τ))τ∈Ht,其中
H
t
=
t
−
t
o
,
…
,
t
−
1
,
t
H_t = {t−t_o,…,t−1,t}
Ht=t−to,…,t−1,t代表过去的一组时间隙。模型
P
(
f
i
(
H
t
)
∣
D
i
(
t
)
)
P(f_i(H_t)|D_i (t))
P(fi(Ht)∣Di(t)) 表示
f
i
(
H
t
)
=
{
f
i
(
τ
)
}
τ
∈
H
t
f_i(H_t)=\{f_i(τ)\}_{τ∈H_t}
fi(Ht)={fi(τ)}τ∈Ht在不同轨迹点
{
ℓ
i
(
τ
)
}
τ
∈
H
t
\{\ell_i(τ)\}_{τ∈H_t}
{ℓi(τ)}τ∈Ht 的后验概率分布。很明显,历史样本的|Di (t)|可以为准确估计后验分布P(fi(Ht)|Di (t))提供更多的信息。根据贝叶斯定理,给定Di (t)的后验分布与fi(Ht)的先验分布和似然函数P(Di(t)|fi(Ht))有关:
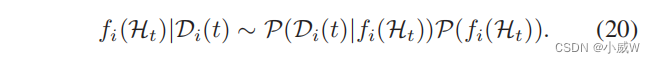
由于无人机不知道 GUs 的空间分布及其交通需求,我们可以使用多变量高斯分布G来建模先验分布
P
(
f
i
(
H
t
)
)
P(f_i(H_t))
P(fi(Ht))[41]:
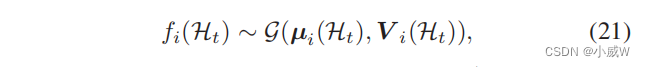
式中,
μ
i
(
H
t
)
μ_i(H_t)
μi(Ht)为均值向量,
V
i
(
H
t
)
=
{
v
τ
,
τ
′
}
τ
,
τ
′
∈
H
t
V_i(H_t)=\{v_{τ,τ'} \}_{τ,τ'∈H_t}
Vi(Ht)={vτ,τ′}τ,τ′∈Ht为
τ
∈
H
t
τ∈H_t
τ∈Ht[42]的轨迹点
ℓ
i
(
τ
)
\ell_i(τ)
ℓi(τ)上每个采样值
s
i
(
τ
)
s_i(τ)
si(τ)的协方差矩阵或核函数。最初,如果没有任何先验信息,我们可以假设
μ
i
=
0
μ_i = 0
μi=0均值为零。此外,协方差矩阵的每个元素
v
τ
,
τ
′
v_{τ,τ'}
vτ,τ′ 可以定义如下:
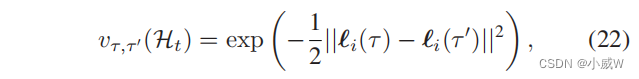
这意味着当两个轨迹点
ℓ
i
(
τ
)
\ell_i(τ)
ℓi(τ) 和
ℓ
i
(
τ
′
)
\ell_i(τ')
ℓi(τ′) 更接近时,直观上的相关值
v
τ
,
τ
′
v_{τ,τ'}
vτ,τ′ 更大。给定(21)中的先验分布和高斯似然
P
(
D
i
(
t
)
∣
f
i
(
H
t
)
)
P(D_i(t)|f_i(H_t))
P(Di(t)∣fi(Ht)),我们可以很容易地得到(20)中的后验分布
P
(
f
i
(
H
t
)
∣
D
i
(
t
)
)
P(f_i(H_t)|D_i(t))
P(fi(Ht)∣Di(t)),可以认为是已知均值和方差[42]的高斯分布。
(2)Predict the Optimal Trajectory Point 预测最优轨迹点
现在,我们的目标是预测UAV-i的一个新的轨迹点 ℓ i ( t + 1 ) \ell_i(t + 1) ℓi(t+1)上的函数值,记为 f i ( t + 1 ) f_i(t + 1) fi(t+1)。给定采样历史 D i ( t ) D_i(t) Di(t),我们可以更新后验分布如下:
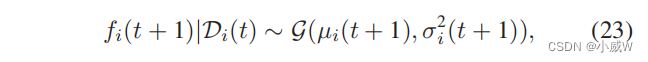
其中,均值和方差
(
μ
i
(
t
+
1
),
σ
i
2
(
t
+
1
))
(μ_i(t+1),σ_i^2(t+1))
(μi(t+1),σi2(t+1))可以从
(
μ
i
(
H
t
),
V
i
(
H
t
))
(μ_i(H_t),V_i(H_t))
(μi(Ht),Vi(Ht))更新。更详细的推导可以参考[41]和[42]中的第2.1章。随着
∣
D
i
(
t
)
∣
|D_i(t)|
∣Di(t)∣ 大小的增加,
f
i
(
t
+
1
)
f_i(t + 1)
fi(t+1)的后验分布将接近真实分布。这使我们能够评估不同轨迹点上的函数值。
为了从无人机群中收集更多的数据,每架无人机-i可以选择下一个飞行轨迹点i(t + 1),以最大化期望的函数值fi(t + 1)。具体地说,我们定义了函数zi,t(i)来描述当UAV-i移动到第t个时隙处的轨迹点i时,函数值
f
i
(
ℓ
i
)
f_i(\ell_i)
fi(ℓi)的预期改进:
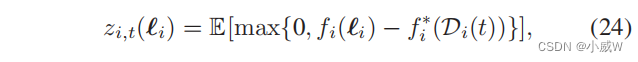
其中, f i ∗ ( D i ( t ) ) f_i^∗(D_i(t)) fi∗(Di(t)) 表示过去采样点的最大函数值,即 f i ∗ = m a x ℓ i ∈ D i ( t ) f i ( ℓ i ) f_i^∗=max_{\ell_i∈D_i(t)}f_i(\ell_i) fi∗=maxℓi∈Di(t)fi(ℓi)。因此,通过最大化期望的改进,可以得到UAVi的最优轨迹点,即 ℓ i ( t + 1 ) = a r g m a x z i , t ( ℓ i ) \ell_i(t + 1)= arg max z_{i,t}(\ell_i) ℓi(t+1)=argmaxzi,t(ℓi)。实际上,寻找最优轨迹点也受到无人机的速度和距离限制的限制。与MADDPG中的随机行动探索相比,对新的轨迹点 ℓ i ( t + 1 ) \ell_i(t + 1) ℓi(t+1)的贝叶斯估计可以提供更多的信息,因为它可以激励无人机收集更多的数据。在移动到新的位置后,无人机将再次收集 GUs 的传感数据,并评估网络形成的质量。
B. Action Estimation for MADDPG 用于MADDPG的动作估计

算法2显示了贝叶斯优化增强的MADDPG(MADDPG)框架。首先,不同无人机的行为者网络将根据个人的局部观察产生其飞行动作。同时,各无人机的贝叶斯优化模块基于历史采样点Di (t)估计后验分布P(fi(t + 1)|Di (t))。通过这样的概率模型,将通过最大化函数值fi(t + 1)的期望改进来估计下一个飞行轨迹点i(t + 1)。这鼓励每个无人机尽可能多地收集传感数据。然后,每架无人机可以从当前位置i (t)飞到下一个位置i(t + 1)。为了便于标注,我们将行为网络的动作预测表示为 { a 1 , a 2 , . . . , a N } \{a_1,a_2,...,a_N \} {a1,a2,...,aN},并将使用贝叶斯优化估计的位置表示为ˆai(t)。所有无人机的动作向量都可以表示为 { a ^ 1 ( t ) , a ^ 2 ( t ) , . . . , a ^ N ( t ) } \{\hat{a}_1(t),\hat{a}_2(t),...,\hat{a}_N(t)\} {a^1(t),a^2(t),...,a^N(t)}。对于每个UAV-i,批评者网络将评估两个动作a1和ˆa1的质量,分别表示为qi和qˆi。根据(24)中的最大化问题的解,可以很容易地得到参考值qˆi。在qi和qˆi之间的比较将决定对所有无人机的最终轨迹点 { a 1 ∗ , a 2 ∗ , . . . , a N ∗ } \{a^∗_1,a^∗_2,...,a^∗_N\} {a1∗,a2∗,...,aN∗}的偏好。一个简单的实现是采取具有更高的行动值的行动,即,如果qˆi大于qi,无人机-i将飞到轨迹点 ℓ i ( t + 1 ) \ell_i(t + 1) ℓi(t+1)。
具体步骤列于算法2中。该两步框架包括基于每个无人机的成本参数(bi(t)、ci (t))的自适应网络形成,以及通过贝叶斯优化增强的多智能体轨迹规划模块算法。在算法2的第6行−10中,通过固定的网络形成,每个无人机-i通过使用演员网络和贝叶斯优化来决定下一个轨迹点。给定两个动作(ai,ˆai)和动作值估计(qi,qˆi),UAV-i可以简单地采取总是采取更高的动作值的贪婪策略。然后,每个UAV-i执行贪婪动作 a i ∗ a^∗_i ai∗,并记录到下一个状态的过渡,如算法2的第11−15行所示。在此之后,每个无人机-i评估其流量条件和成本值,然后使用算法1更新网络的形成。为了实际实现,我们可以依赖于BS和个人无人机的计算资源。BS可以初始化系统,并对无人机的 actor 和 critic 网络进行预先训练。然后,每架无人机都可以根据局部观测产生其局部动作。此外,每个无人机都可以运行贝叶斯优化模块来帮助估计一个更好的轨迹点。请注意,贝叶斯优化并不一定会在每个时间步长中执行,以最小化无人机的计算需求,并促进实际实现。
6.仿真结果
在这部分中,我们给出了仿真结果,以验证联合网络形成和轨迹优化多无人机的性能增益。少量GUs分布在2×2km^2区域,如图1所示。我们将x-y坐标缩放到[−1,1]的范围。BS远离服务区,位于服务区的右上角。无人机和gu都有固定的23 dBm的固定发射功率。无人机的能耗模型是参照[39]中的能耗模型。表I列出了更详细的参数,类似于[8]中的参数设置。
A. Bayesian Optimization Improves Trajectory Planning
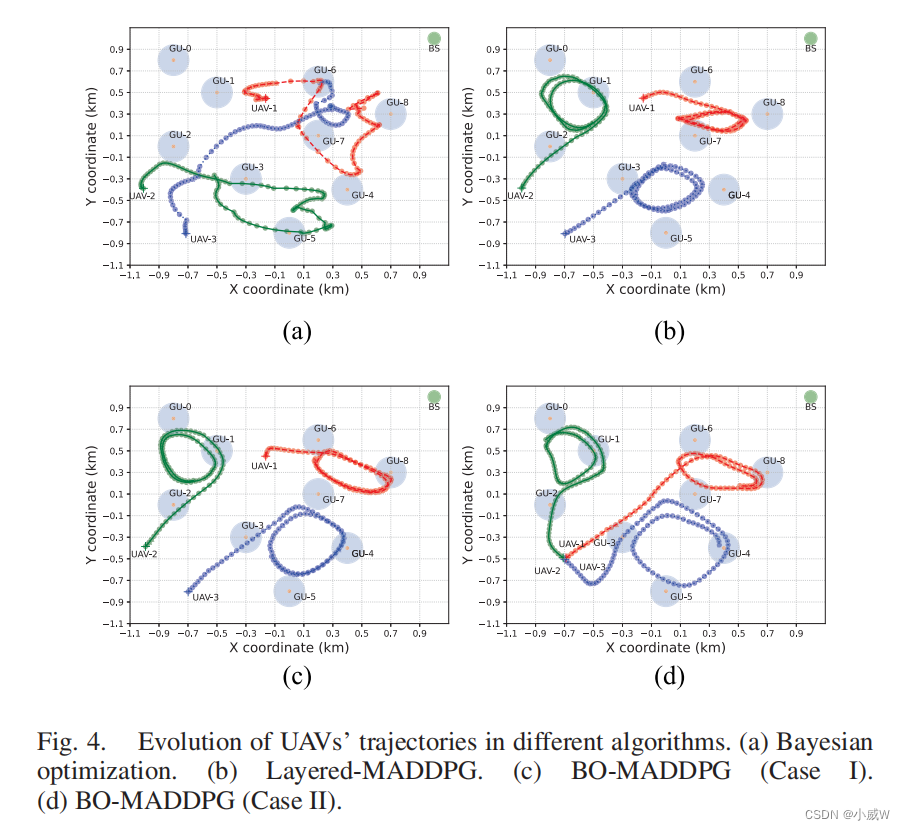
在我们的算法设计中,我们首先提出了Layered-MADDPG框架,该框架依赖于EDA-NF算法来适应网络的形成,同时使用传统的MADDPG算法来学习无人机的轨迹,从而减少了代理的探索行动空间。此外,我们进一步改进了MADDPG算法,利用贝叶斯优化模块估计网络环境,从而得到提高了轨迹学习效率,即表示为BO-MADDPG方法。图4可视化了无人机在不同算法中的轨迹,包括贝叶斯优化算法、分层-MADDPG和BO-MADDPG,这是建立在Lyaered-MADDPG和贝叶斯优化方法上的。图4中不同的颜色表示不同无人机的飞行位置。每架无人机从一个随机起点起飞,沿其轨迹从无人机收集传感数据。图4(a)为贝叶斯优化方法指导下的轨迹规划结果。在这种情况下,每架无人机根据自己的历史轨迹点估计其在下一个时间段的最佳飞行位置。它没有考虑到不同无人机之间的任务协作。因此,贝叶斯优化方法在分散的多无人机网络中的性能受到了限制。不同无人机之间缺乏协调,可能会导致服务冲突或资源浪费。例如,不同的无人机可能有重叠的服务范围。
图4(b)显示了使用LayeredMADDPG算法的轨迹规划,该算法基于集中训练和分散执行方案为每个无人机制定了轨迹策略。集中式训练需要所有无人机的全球信息。经过学习,多架无人机可以协同将整个区域划分为不同的部分,gu的每个部分可以由不同的无人机提供服务。我们可以观察到,整个感知任务最终被分为三个独立的任务组。每个任务组都包含附近gu的一个子集。然后,每架无人机将通过围绕这些无人机飞行,专注于一个任务组的数据收集。这种感知任务的空间划分可以更好地利用无人机的合作,从而潜在地降低整体能耗和传输延迟。与图4(b)中的层状-MADDPG类似,BO-MADDPG也将GUs划分为不同的组,如图4©.所示然而,群体边缘的gus(例如,GU- 7)被给予更高的优先级,并具有更高的传输速率。此外,与分层-MADDPG算法相比,BO-MADDPG算法的轨迹规划更加稳定。与图4©不同,我们进一步假设所有无人机都从图4(d).所示的相同初始位置开始经过学习,无人机可以分散到不同的地区服务。这说明了BO-MADDPG算法利用多无人机合作的有效性。
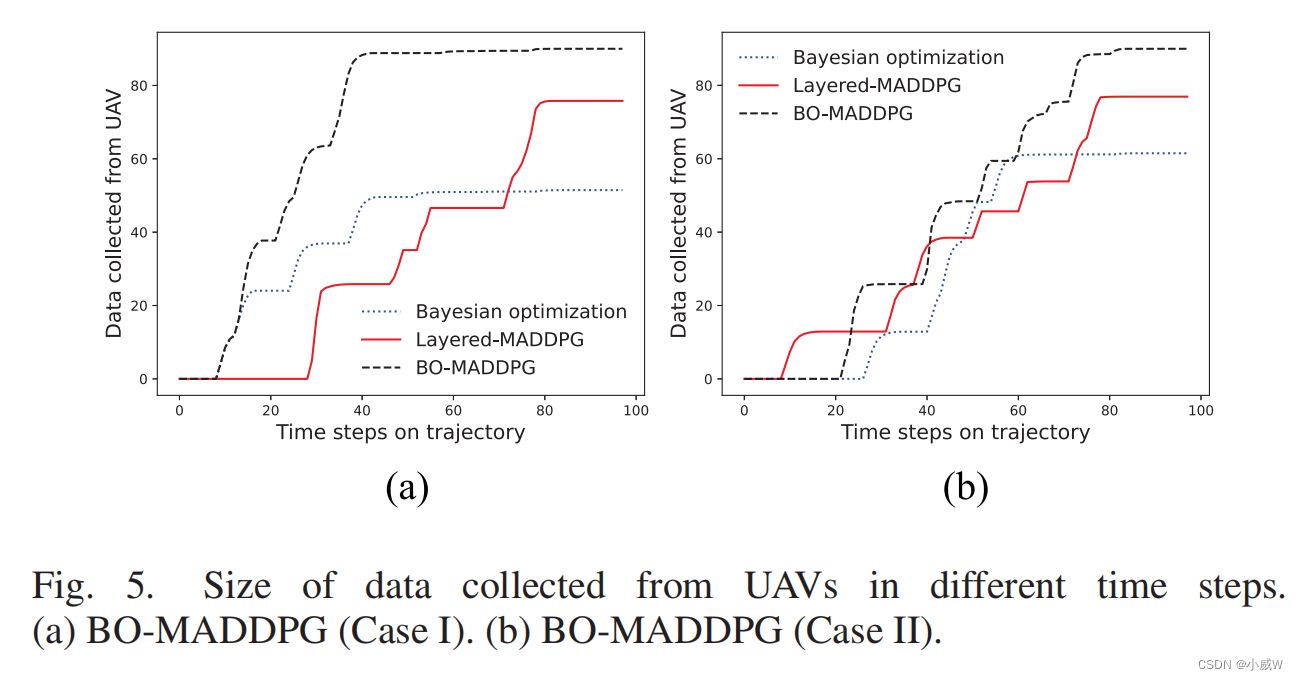
图5显示了不同无人机沿其轨迹收集的传感数据的大小。在每个时隙t中,无人机接收到的传感数据由
R
i
,
s
(
t
)
R_{i,s}(t)
Ri,s(t) 给出,如(15)中的定义。从图5(a)中的比较可以看出,与其他两种情况相比,BO-MADDPG算法获得了更多的传感数据量。这验证了我们的设计概念的优势,通过使用部分信息来指导无模型学习方法获得更好的奖励。图5(b)显示了与图4(d).中轨迹相同的初始位置时类似的结果对于任何一种情况,BO-MADDPG算法都可以从gu中收集最敏感的数据。
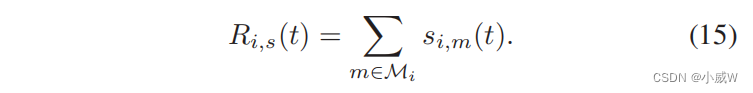
分层-MADDPG算法和BO-MADDPG算法都具有层次结构,可以将网络的形成和轨迹优化分解为两个子问题。这里我们还将它们与传统的MADDPG算法进行了比较,该算法同时联合适应无人机的网络形成和轨迹,记为图6中的Joint-MADDPG。在Joint-MADDPG中,每个无人机的动作ai (t)包括每个时间步长中的飞行方向di (t)、速度vi (t)和网络形成策略φi、j(t)。不同MADDPG算法的收敛性能如图6(a).所示很明显,BO-MADDPG比其他算法收敛得更快,并获得了更高的回报。BO-MADDPG的奖励在早期学习阶段急剧增加,与分层MADDPG算法和Joint-MADDPG算法相比,学习曲线更加稳定、平滑。Joint-MADDPG需要更多的迭代来获得有效的策略。在图6(b)中,我们还评估了学习过程中奖励值的方差。方差越大,意味着学习算法可能由于随机探索而不稳定。从图6(b)可以看出,在早期学习阶段,BO-MADDPG与分层MADDPG和Joint-MADDPG算法具有相当的波动。然而,BO-MADDPG快速收敛到一个稳定的值,且方差更小,而Joint-MADDPG具有高度波动的奖励表现,这表明在训练中存在不稳定性问题。
B. Trajectory Planning With Adaptive Network Formation
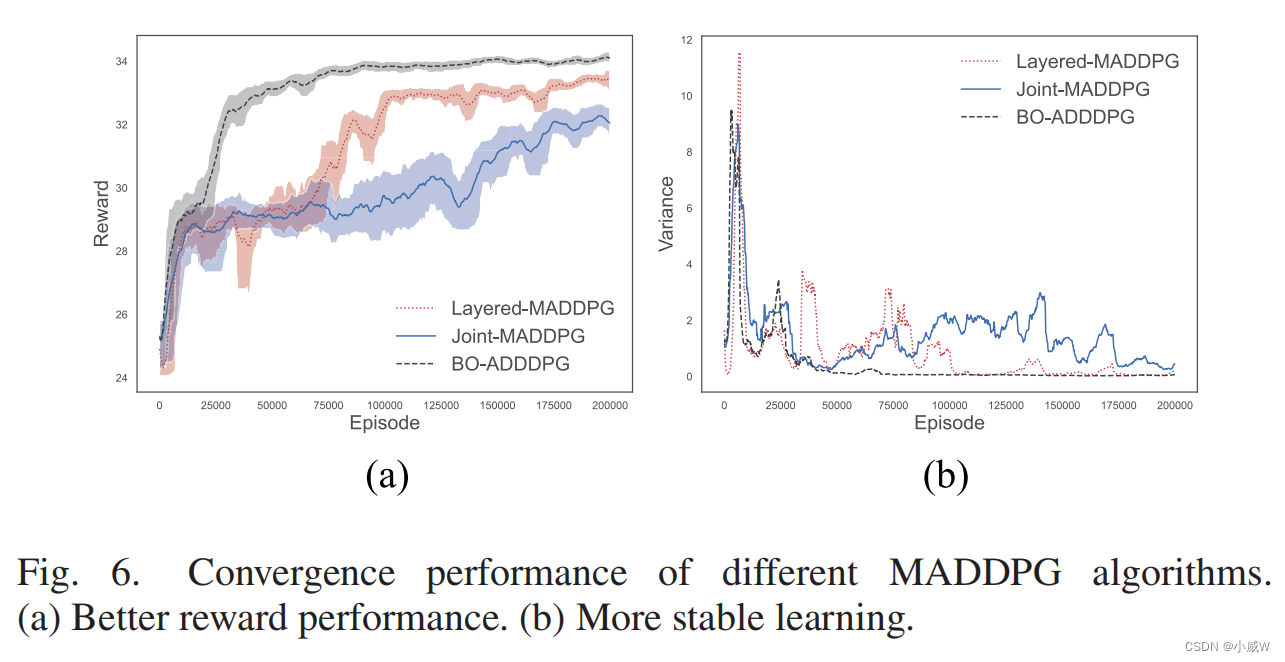
在这一部分中,我们评估无人机的延迟轨迹规划与能量感知自适应网络的形成,即算法1。图7(a)显示了三架无人机的飞行轨迹,也揭示了无人机沿其飞行轨迹飞行时网络形成的动态变化。我们使用不同类型的标记点来表示U2U和U2B的通信模式。空心的圆圈代表了直接的U2B通信。当无人机远离BS时,无人机更喜欢通过U2U通信与下一跳无人机进行通信。这就需要附近的无人机作为中继节点,并将数据转发给BS。因此,我们可以提高数据速率,减少传输延迟。当无人机飞近BS时,U2B通信变得更加可取,我们可以观察到从U2U通信到U2B通信的切换。如图7(a)所示,无人机-1的服务区更接近BS,而无人机-2和无人机-3的服务区则远离BS。因此,UAV-1将作为中继节点,通过使用高速U2U链路帮助UAV-3的数据卸载到BS。当UAV-3接近BS及其U2B通道变得更好时,UAV-3断开U2U与UAV-1的连接。相反,它选择通过U2B链路直接卸载其数据。当无人机-1的工作量过多时,无人机-3也可以作为无人机-2的中继节点。具体来说,在无人机轨迹的时间步长0-8中,即图7(a)中的T0-8中,gu超出了无人机的传感范围。在图7(a)的T9-13中,UAV-2可以从GU-2收集传感数据,而UAV-3和UAV-1仍在传感范围之外。因此,无人机-3可以作为中继节点来辅助无人机-2的数据通过U2U通道进行卸载。在图7(a)的T14-20中,UAV-2将断开其U2U链路并切换到直接的U2B链路,而UAV-3将切换到U2U链路并选择UAV-1作为其中继节点。UAV-1成为最接近BS的,因此其感知数据可以通过使用U2B链路快速转发到BS。类似的分析也适用于图7(a).中的剩余时间步长。
在图7(b)中,我们展示了无人机的缓冲区尺寸沿着运动轨迹的演变。最初,无人机-1的缓冲区大小保持在一个非常低的水平,因为它更接近BS,并有一个更可取的U2B信道条件。无人机-1的传感数据可以通过U2B通道快速卸载到BS中。对于其他两架无人机,它们远离BS,因此它们的缓冲区大小通过使用低速率U2B通道显著增加。当它们的缓冲区尺寸继续增加时,无人机的成本功能就会变得不同。通过在UAV-2/3和UAV-1之间建立U2U链接,驱动网络形成的变化。如图7(b)所示,我们可以观察到UAV-1的缓冲区尺寸增加,而UAV-2和UAV-3的缓冲尺寸相应减小。通过U2U通信,无人机-1将接收到从其他两架无人机卸载的数据。最后,所有无人机同时完成数据卸载。这可以最小化所有无人机的总悬停时间,并稳定其资源消耗。
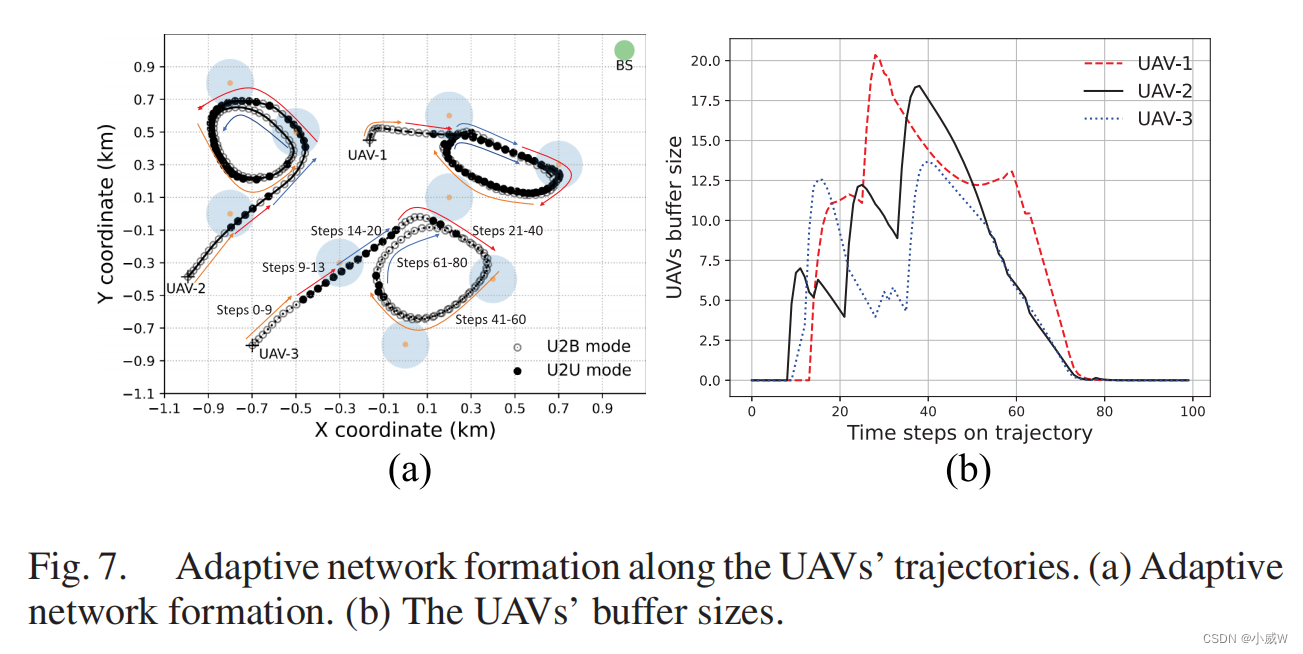
在图8中,我们展示了算法1中驱动无人机自适应网络形成的无人机成本函数和负载平衡系数的演化。较大的成本值ci (t)意味着UAV-i需要更多的能量,并导致数据卸载产生过多的传输延迟,而负载平衡系数bi (t)则代表了U2B的直接传输能力。无人机的网络形成旨在通过平衡不同无人机的两个系数(ci,bi)来平衡无人机的资源需求和传输能力,例如,具有更大的bi (t)的无人机-i可以建立与相邻无人机的U2U链路。如图8(a)所示,通过调整不同无人机之间的U2U链路,无人机的成本值逐渐降低。当UAV-1作为中继节点来协助UAV-2的数据卸载时,UAV-2的成本值迅速下降,而UAV-1的成本在从UAV-2接收到额外的工作量时缓慢下降。当UAV-2的成本值小于UAV-1的成本值达到一定的阈值时,UAV-2将断开U2U通道并切换回U2B通道,以减少UAV-1的工作量。随着所有无人机的成本值下降到一个小值,这个过程继续进行当所有gu完成数据卸载任务时的值。此外,无人机成本值的差异保持在一个较小的范围内,说明所提出的自适应网络形成算法保证了不同无人机之间公平的资源消耗。在图8(b)中,我们展示了无人机的负载平衡系数沿运动轨迹的演变。由于无人机-1更接近BS,并且通过U2B链路具有更高的传输速率,因此最初它的负载平衡系数b1比其他无人机要小得多。无人机-2的工作负载最初很高,但负载平衡系数b2在它通过U2U通道将缓冲数据卸载到无人机-1时迅速下降。
C. Comparison With Different Network Formation Strategy
在这一部分中,我们验证了算法1中的自适应网络形成方法可以提高无人机轨迹学习的奖励性能。第一个基线是非合作策略,这在文献中经常被研究。它假设所有的无人机都有直接的U2B连接来将缓冲的数据卸载到BS。第二个基线类似于[9]中的多跳无人机网络,它允许远程无人机通过多跳中继通信将其工作负载卸载到BS。为了激励无人机的中继通信,我们设计了一种基于缓冲区的算法,当无人机的缓冲区大小超过某个阈值时,允许无人机与附近的无人机建立U2U连接。数据队列积压大小是多跳无线网络[22]中用于路由或传输控制的常用网络信息。第三个基线是在我们在之前的工作[14]中提出的动态网络形成算法(表示为动态nf)。它根据其缓冲区大小、剩余数据和能源消耗为每架无人机维护一个成本值。每架无人机都可以根据自己的成本价值和一跳相邻无人机的成本的比较来调整其U2U连接。除了[14]中的成本值外,算法1中还设计了负载平衡系数来表征每架无人机的传输能力。
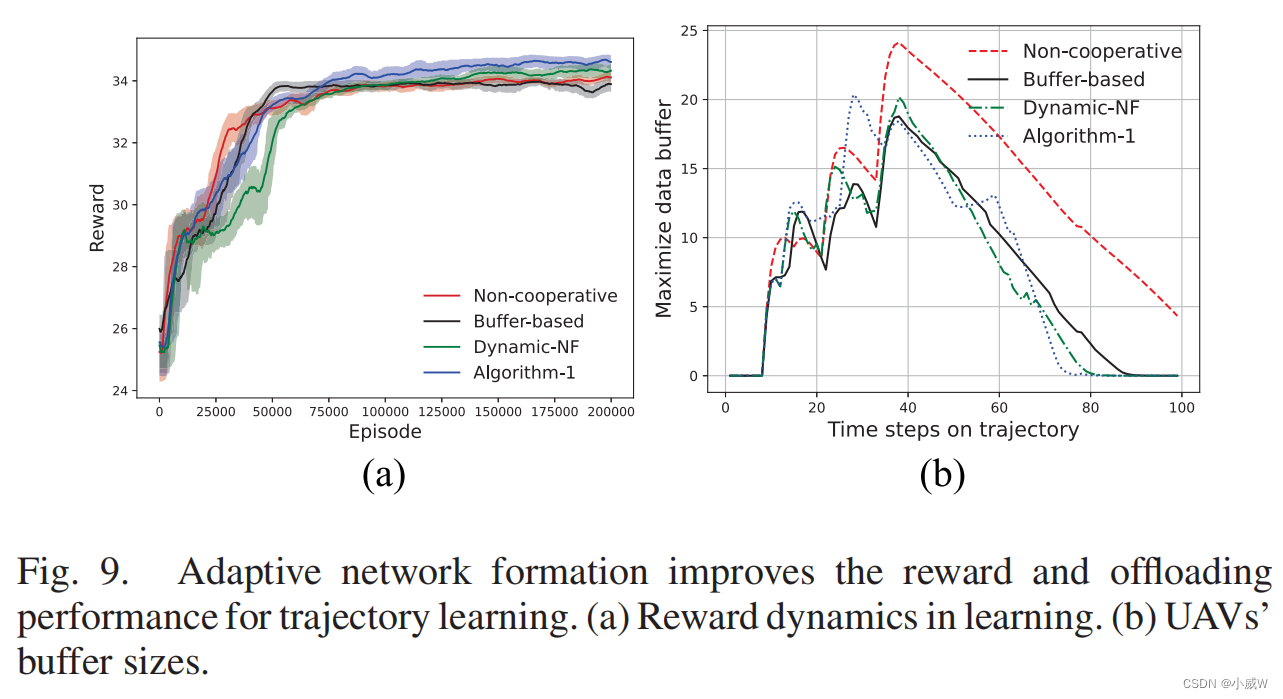
在图9(a)中,我们比较了不同网络形成算法在无人机轨迹规划中的收敛性和奖励性能。非合作策略忽略了无人机的任务合作,显示出最快的收敛速度,但奖励性能较低。基于缓冲的自适应网络形成策略试图利用无人机的任务协作。它忽略了其他可能会影响无人机轨迹的批评者资源限制(例如,无人机的能量状态和GUs的工作量需求)。与非合作策略和基于缓冲区的算法相比,动态-NF算法获得了更高的回报,但收敛速度较慢。我们的算法1比动态的NF-NF算法获得了更好的奖励和更快的收敛速度,如图9(a).所示。在图9(b)中,我们展示了无人机沿着无人机运动轨迹的最大缓冲尺寸。无人机的数据缓冲区可以通过适应无人机的网络形成保持在较低的水平,而非合作策略导致最大的缓冲区大小,特别是对于对BS最差U2B信道条件的远程无人机。基于缓冲区的算法只关注无人机的缓冲区大小。因此,它可以保持如图9(b).所示算法1可以与基于缓冲区的算法具有相当的最大缓冲区大小。然而,与其他基线相比,它可以在更短的时间内完成所有无人机的数据卸载。这意味着算法1可以减少无人机在空中的悬停时间和能量消耗。
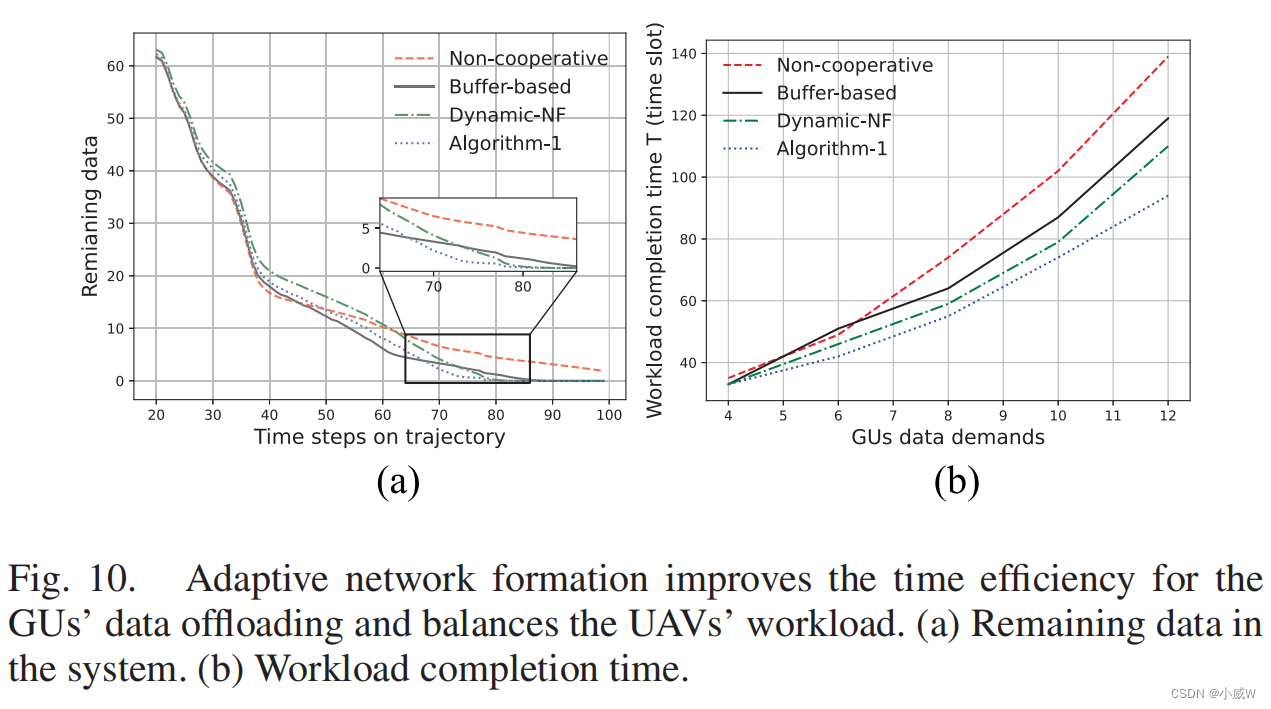
在图10(a)中,我们显示了gu和无人机缓冲区中剩余的总体数据。常见的观察结果是,在所有的算法中,系统中剩余的数据都在逐渐减少。一个有趣的观察结果是,非合作策略最初有一个更快的下降速度,但下降的速度减慢,并显示出一个胖尾巴。这意味着由于速率限制的U2B通道,工作负载完成时间更长。基于缓冲区和动态NF算法可以利用高速U2U链路提高系统容量。与非合作策略相比,工作量完成时间可以显著减少。算法1的卸载性能最好,如图10(a).所示由于gu的工作负载要求较低,算法1实现了与基于缓冲区和动态NF算法相似的工作负载完成时间。我们期望随着GUs的工作负载需求的增加,算法1可以表现得更好。在图10(b)中,我们比较了不同网络形成策略的工作负载完成的时间。很明显,算法1可以在更短的时间内完成传输任务,其性能增益比基线更显著。这意味着我们的算法1可以通过动态适应网络形成来平衡无人机的工作量和资源需求。
7.结论和未来的工作
在本文中,我们提出了一种分层学习算法来联合优化无人机的网络形成和轨迹的无线数据卸载。根据无人机的运动轨迹,网络的形成主要基于无人机的能量消耗和缓冲区大小。当网络形成发生改变时,我们使用多智能体学习算法进一步更新无人机的运动轨迹。此外,为了提高学习效率,我们采用贝叶斯优化的方法,基于历史信息估计无人机的飞行决策。这有助于避免无效的行动探索,提高学习中的收敛性。仿真结果表明,我们的算法可以适应无人机的轨迹网络形成,从而更有效地收集传感数据。
补充
Q & A
Q:论文作者为什么要假设感知子时隙是固定的?这样做合理吗?
A:在本文中,作者假设感知子时隙是固定的,主要是为了简化问题,使得问题更易于建模和求解。这种假设可以使得问题的复杂度降低,同时可以减少算法的计算量和通信开销。此外,感知子时隙的固定假设也可以使得问题更具有实际意义,因为在实际应用中,感知子时隙的长度通常是固定的,例如,LTE系统中的子帧长度就是固定的。因此,这种假设在一定程度上是合理的。然而,在实际应用中,感知子时隙的长度可能会发生变化,因此,在实际应用中,需要根据具体情况来确定感知子时隙的长度。
Q:为什么所有的无人机会共享K个子信道,子信道的数量是由什么决定的?
A:在本文中,所有的无人机共享K个正交子信道,这是因为在多智能体系统中,无人机之间的通信需要占用有限的频谱资源。为了避免频谱资源的浪费和通信干扰,需要对频谱资源进行合理的分配和利用。因此,本文中将频谱资源分成了K个正交子信道,并让所有的无人机共享这些子信道。这样可以避免无人机之间的通信干扰,同时也可以提高频谱资源的利用效率。
子信道的数量K是由频谱资源的总带宽和每个子信道的带宽决定的。在本文中,作者并没有具体说明K的值,因此K的具体取值可能取决于具体的应用场景和系统参数。
Q:在无人机辅助的无线网络研究领域中,一些时隙结构的无人机可以边飞行边传输,另一些论文的时隙结构则不允许无人机边飞行边传输,这两种方式都合理吗?为什么?对应现实中的哪些场景?
A:
目标Critic网络和目标Actor网络

优势函数 GAE




















 76
76

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











