







目录
0、Prepare
本章需要一些 AXI-Stream 的知识,可以参考:
1、Preview
AXI VDMA(AXI Video Direct Memory Access,以下简称 VDMA),是 Xilinx 提供的软核 IP。其功能和 AXI DMA(以下简称 DMA)有些类似,都可以为存储器或者 AXI4-Stream 类目标外设之间提供高带宽直接存储器存取。是专门为视频数据传输定制的 IP;
为什么是 VDMA?
有过嵌入式图像开发经验的同学应该都知道,针对图像的常规操作,软件和硬件交互的方式是:
1、硬件层面,有一片存储空间,它的内容直接映射到显示设备(比如 LCD 等);
2、软件来说,配置好硬件,直接往这片存储空间写对应格式的数据,数据就会显示在显示设备上;
这片空间可以叫显存,或者一个更加通用的名称 FrameBuffer(帧缓冲)!
Xilinx 提供的 VDMA IP 不仅仅集成了 DMA 的功能,还提供针对图像的 FrameBuffer 和 GenLock 同步锁相机制(保证读写同一块帧缓冲的顺序);非常适合搭建高带宽的图像通路;
Xilinx 介绍 VDMA 的文档位于:
https://www.xilinx.com/support/documentation/ip_documentation/axi_vdma/v6_2/pg020_axi_vdma.pdf
2、VDMA
2.1、Features
下面是 VDMA 的系统框图:
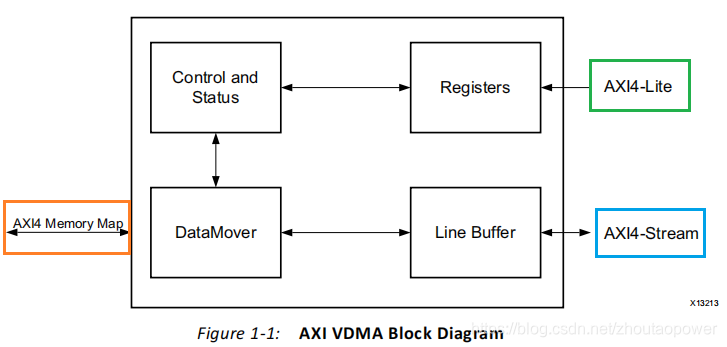
可以看到 VDMA 向外提供了 3 路通路:
1、AXI4-Lite:用于配置 VDMA 的寄存器,来控制 VDMA 的行为;
2、AXI4 Memory Map:用于通过 AXI 4 接口,直接访问 DDR 控制器,进而访问 DDR;
3、AXI4-Stream:用于将图像数据按照 AXI4-Stream 的方式快速的输出,或者读入;
换句话来说,AXI4-Lite 用于 CPU 来给 VDMA 配置 IP 的行为,AXI4 Memory Map 直接和 DDR 交互,也就是 FrameBuffer;AXI4-Stream 用于输出、输入视频流式数据;
VDMA 支持的硬件上的配置如下:
1、AXI4 Memory Map 数据总线宽度支持 32、64、128、256、512和1,024位;
2、AXI4-Stream 支持 8 位的整数倍至 1,024 位的数据总线宽度。AXI4-Stream 数据宽度必须小于或等于相应通道的AXI4数据宽度;
3、支持可选的数据重新排列引擎(DRE)。DRE让对内存的未对齐访问,从而允许帧缓冲区从内存中的任何地址开始;
4、支持同步锁相功能(用于同步读和写同一片 FrameBuffer 的行为仲裁);
5、支持每个通道相互独立的异步时钟;
6、AXI4-Stream 支持动态时钟变换;
7、最大支持 32 个 FrameBuffer;
8、最大支持 64 bits 地址空间;
2.2、Channels defines
在 VDMA 中,定义了几条通路:
2.2.1、Write Channel(S2MM)
PG020 中定义的写数据路径为 AXI VDMA 从 AXI4-Stream Slave 接收数据,然后使用 AXI4 Master 写入到主存的过程;这个过程,我们也叫 S2MM,全称是 AXI4-Stream To AXI4 Memory Map:
S2MM:AXI4-Stream Slave To AXI4 Memory Map
2.2.2、Read Channel(MM2S)
PG020 中定义的读数据路径为 AXI VDMA 从 使用 AXI4 Master 将数据读出来,AXI4-Stream Master 将数据输出;这个过程,我们也叫 MM2S,全称是 AXI4 Memory MapTo AXI4-Stream:
MM2S:AXI4 Memory MapTo AXI4-Stream
不管是读,还是写,他们都是彼此独立的存在,完全不相干的通道;那万一针对同一片 FrameBuffer 即有写,又有读,那咋办?这就是后面要说到的 GenLock;
2.3、Performance
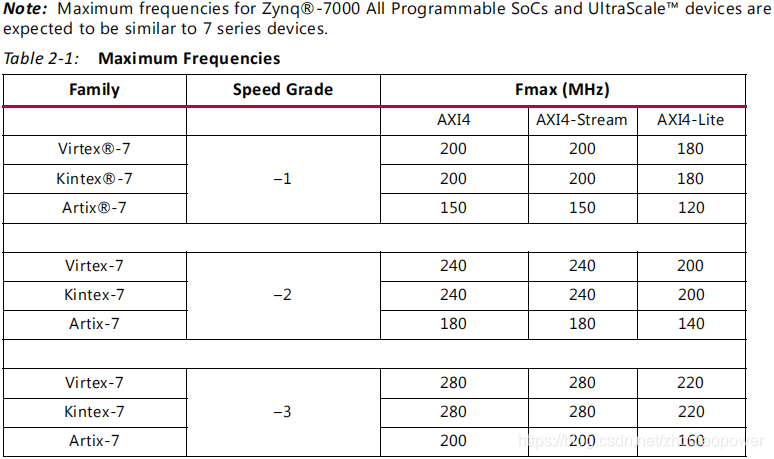
2.3.1、Frequency
针对不同的 FPGA 上,VDMA 能够达到的性能是不一样的,Xilinx 官方给了表格,关于最大时钟频率而言如下:
2.3.2、Latency
下面是 VDMA 核在读和写的 Data path 上的时延:

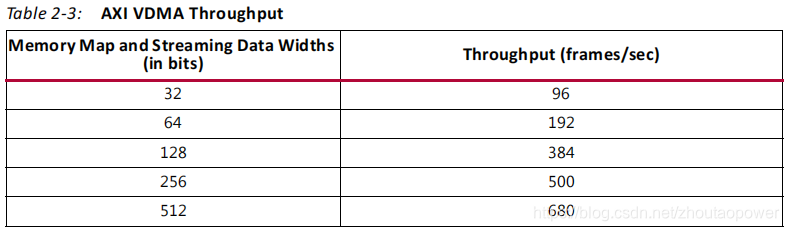
2.3.3、Throughput
不同数据位宽下 HD 的帧吞吐率:
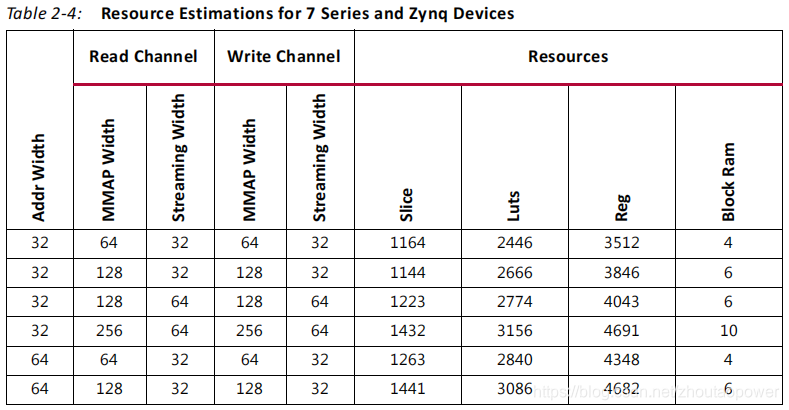
2.3.4、Resource Utilization
资源占用,这里主要是统计了 Slice, LUT,Reg(FF),BRAM:
Zynq-7000 的占用如下:
2.4、Signals
VDMA 模块的信号如下所示: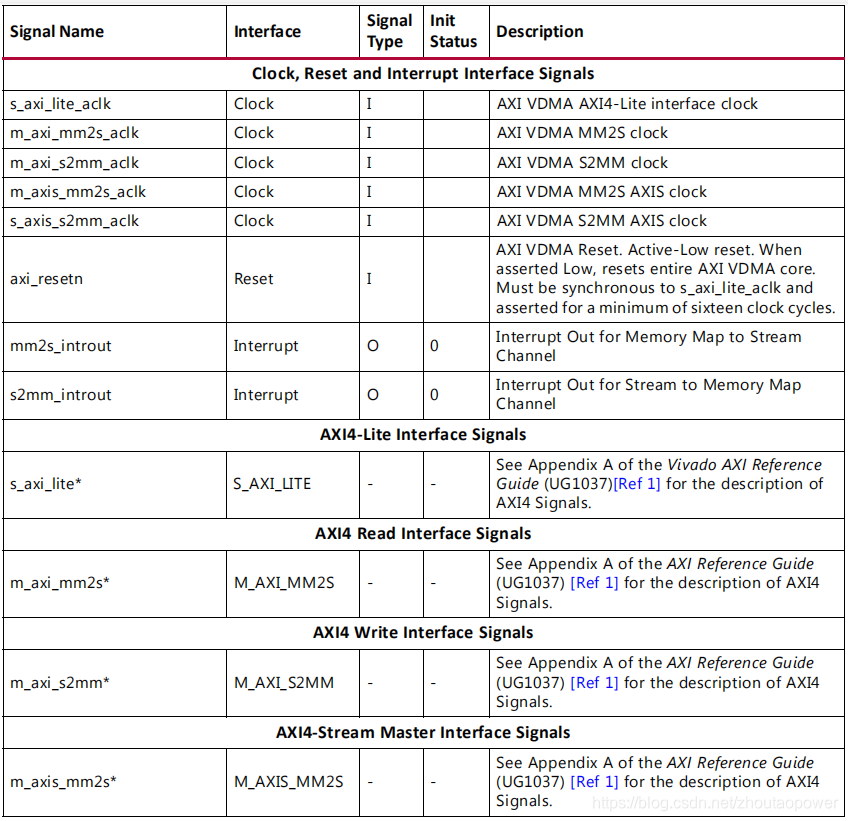
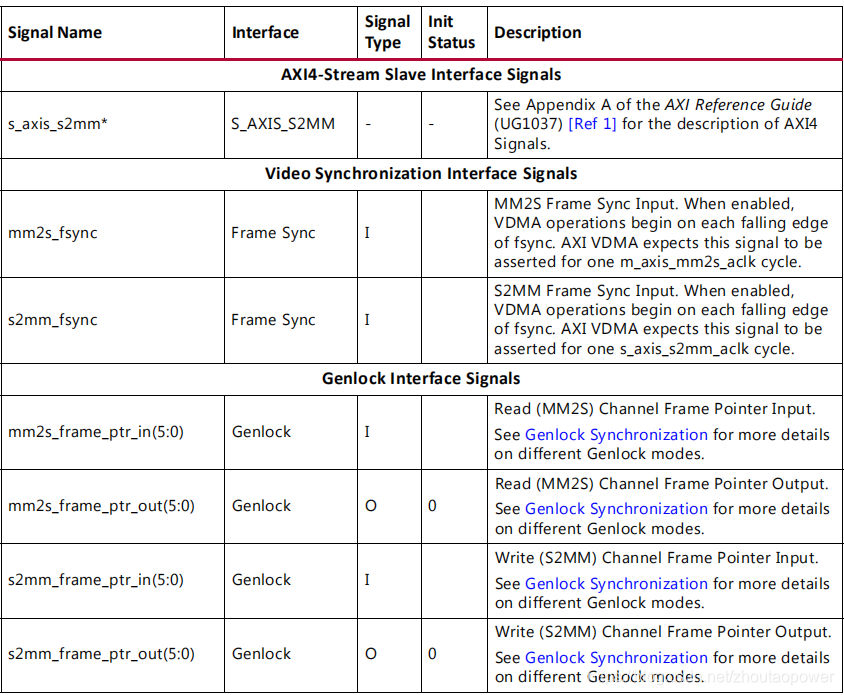
读写通道完全分开,使用不同的时钟;
2.5、Timings
2.5.1、Read Timings (MM2S)
VDMA 的文档中,举例了在 MM2S 的情况下的时序:
以图像为 5 行,每行 16 字节为例:
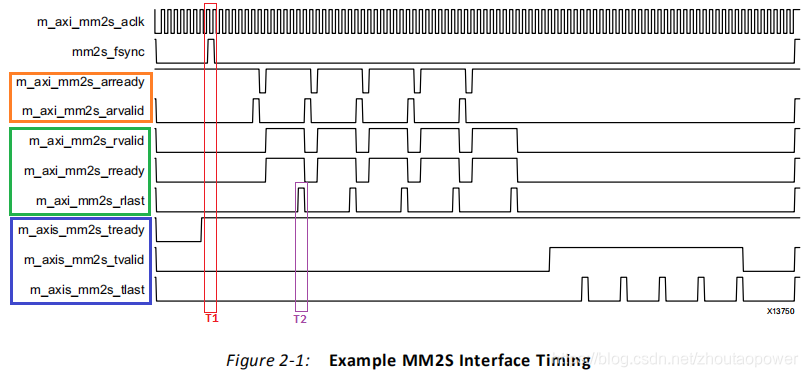
可以看到,首先接收到 mm2s_fsync 信号,VDMA 在 AXI 4 一侧发起地址握手m_axi_mm2s_arready 和 m_axi_mm2s_arvalid(橘黄色)。一共有 5 次,对应了 5 行数据;
地址阶段完成后,完成读信号的握手:m_axi_mm2s_rvalid 和 m_axi_mm2s_rready,VDMA 开始使用 AXI4 Memory Map 读取内存的数据,每一次读 16 Bytes,读完后发送 m_axi_mm2s_rlast;
数据被缓存到 Line Buffer,一直到 AXI-Stream 握手信号有效(蓝色),开始将数据通过 AXI-Stream,往外发送;
2.5.2、Write Timings (S2MM)
写时序类似,不再多说:
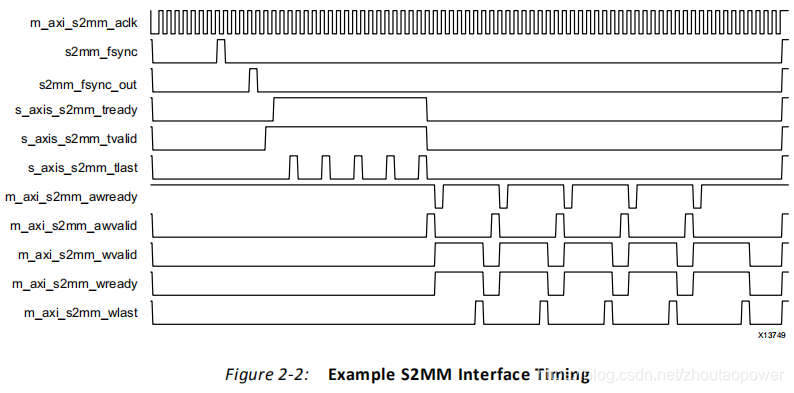
2.6、Registers
VDMA 的寄存器是通过 AXI-Lite 进行配置访问,寄存器主要分为两组:MM2S 和 S2MM:
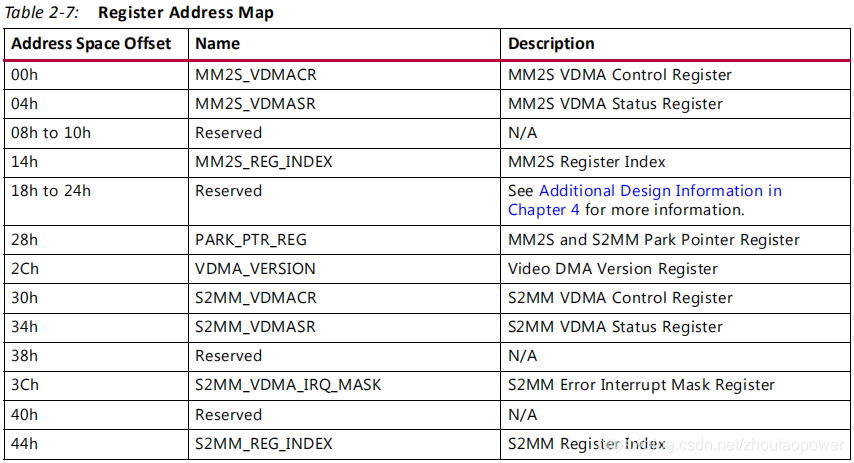

主要配置的内容有:
1、中断的配置,即是否产生一些错误中断,或者一些 Frame Count 中断;
2、使能和禁能 VDMA 或者 GenLock 等;
3、配置要传输图像在内存中 FrameBuffer 的起始地址;
4、配置图像的宽高(这样 VDMA 才知道要传输多大的数据 Size);
5、帧缓存的使用策略;
这里就不一一叙述,有兴趣的同学可以直接参考 PG020 文档描述,或者看看已经总结出来中文版的一些内容,比如:
https://blog.csdn.net/weixin_42639919/article/details/81144746
2.7、GenLock mechanism
在许多视频应用程序中,视频数据输入速度与读取速度不同。为了避免可能导致速率不匹配的潜在不良影响,经常使用帧缓冲。数据写入一个缓冲区,而读取操作在另一个缓冲区进行。
而VDMA的Genlock可防止读取和写入通道同时访问同一帧,也就是防止同时对一帧数据进行读和写操作;
AXI VDMA支持四种模式的 Genlock 同步:
- Genlock Master
- Genlock Slave
- Dynamic Genlock Master
- Dynamic Genlock Slave
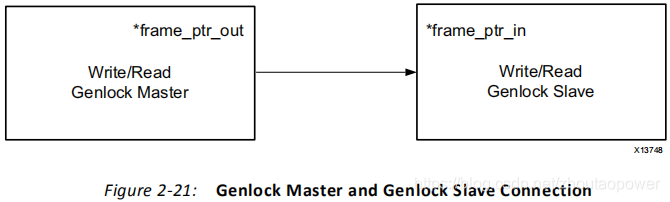
2.7.1、Genlock Master
读通道(MM2S):当配置为Genlock Master时,该通道不会跳过或者重复任一帧数据,并把当前帧的编号输出在mm2s_frame_ptr_out 端口。通道不会检测 mm2s_frame_ptr_in 端口提供的帧编号。Genlock Slave通道应跟随Genlock Master通道变化,但有一定的延迟。延迟大小预定义在寄存器中(*frmdly_stride[28:24])。
写通道(S2MM):当配置为Genlock Master时,该通道不会跳过或者重复任一帧数据,并把当前帧的编号输出到s2mm_frame_ptr_out端口。通道不会检测 s2mm_frame_ptr_in 端口提供的帧编号。Genlock Slave通道应跟随Genlock Master通道变化,但有一定的延迟。延迟大小预定义在寄存器中(*frmdly_stride[28:24])。
换言之,就是 Master 最大,Master 按照规矩走,而 Slave
2.7.2、Genlock Slave
读通道(MM2S):当配置为Genlock Slave时,该通道会通过跳过或者重复一些帧的方式,尝试与Genlock Master同步。通道会对mm2s_frame_ptr_in端口进行采样,获取Genlock Master的帧编号。为了实现状态反馈,通道会把当前帧的编号输出到mm2s_frame_ptr_out端口。
指定通道工作在Genlock Slave模式,必须进行如下操作。
1、将GenlockEn置1(MM2S_VDMACR[3]=1),使能主、从通道之间的Genlock同步。
2、将GenlockSrc置1(MM2S_VDMACR[7]=1),使能内部Genlock模式。如果在Vivado IDE中同时使能读、写通道,该位默认置位。当GenlockSRC=1时,VDMA默认支持内部同步锁相总线。这样一来就没有必要在外部对帧指针端口(*frame_ptr_out和*_frame_ptr_in)进行连接了。
3、根据主从通道的帧率,使用mm2s_frmdly_stride[28:24]设定合适的延迟时间
写通道(S2MM):当配置为Genlock Slave时,该通道会通过跳过或者重复一些帧的方式,尝试与Genlock Master同步。通道会对s2mm_frame_ptr_in端口进行采样,获取Genlock Master的帧编号。为了实现状态反馈,通道会把当前帧的编号输出到s2mm_frame_ptr_out端口。
指定通道工作在Genlock Slave模式,必须进行如下操作。
1、将GenlockEn置1(S2MM_VDMACR[3]=1),使能主、从通道之间的Genlock同步。
2、将GenlockSrc置1(S2MM_VDMACR[7]=1),使能内部Genlock模式。如果在Vivado IDE中同时使能读、写通道,该位默认置位。当GenlockSRC=1时,VDMA默认支持内部同步锁相总线。这样一来就没有必要在外部对帧指针端口(*frame_ptr_out和*_frame_ptr_in)进行连接了。
3、根据主从通道的帧率,使用mm2s_frmdly_stride[28:24]设定合适的延迟时间。
2.7.3、Dynamic Genlock Master
读通道(MM2S):当配置为 Dynamic Genlock Master 时,这个通过会跳过其对应的 Slave 正在操作的帧,Dynamic Genlock Master 通过采集 Dynamic Genlock Slave 发出的当前正在处理的帧号的 mm2s_frame_ptr_in 信号,来进行判断;同时 Dynamic Genlock Master 通过 mm2s_frame_ptr_out 输出上一次访问过的帧编号;
指定通道工作在Dynamic Genlock Master模式,必须进行如下操作。
1、将GenlockEn置1(S2MM_VDMACR[3]=1),使能主、从通道之间的Genlock同步。
2、将GenlockSrc置1(S2MM_VDMACR[7]=1),使能内部Genlock模式。如果在Vivado IDE中同时使能读、写通道,该位默认置位。当GenlockSRC=1时,VDMA默认支持内部同步锁相总线。这样一来就没有必要在外部对帧指针端口(*frame_ptr_out和*_frame_ptr_in)进行连接了。
比如:3 帧的数据,Dynamic Genlock Master 会按照 0,1,2,0,1,2 的顺序循环使用帧存,如果 Slave 一直没有任何操作,那么 Dynamic Genlock Master 会一直重复的去取 0,1,2;如果 Slave 操作了其中一帧,比如 1,那么 Master 就在 0,2,0,2 中去取数据,跳过 1;
写通道(S2MM):当配置为 Dynamic Genlock Master 时,这个通过会跳过其对应的 Slave 正在操作的帧,Dynamic Genlock Master 通过采集 Dynamic Genlock Slave 发出的当前正在处理的帧号的 s2mm_frame_ptr_in 信号,来进行判断;同时 Dynamic Genlock Master 通过 s2mm_frame_ptr_out 输出上一次访问过的帧编号;
2.7.4、Dynamic Genlock Slave
读通道(MM2S):当配置为 Dynamic Genlock Slave 时,它通过 mm2s_frame_ptr_in 采集 Dynamic Genlock Master 发出的信号(Dynamic Genlock Master 上一帧的编号)来访问,同时通过 mm2s_frame_ptr_out 输出当前正在处理的帧的编号;
指定通道工作在Dynamic Genlock Slave模式,必须进行如下操作。
1、将GenlockEn置1(S2MM_VDMACR[3]=1),使能主、从通道之间的Genlock同步。
2、将GenlockSrc置1(S2MM_VDMACR[7]=1),使能内部Genlock模式。如果在Vivado IDE中同时使能读、写通道,该位默认置位。当GenlockSRC=1时,VDMA默认支持内部同步锁相总线。这样一来就没有必要在外部对帧指针端口(*frame_ptr_out和*_frame_ptr_in)进行连接了。
写通道(S2MM):当配置为 Dynamic Genlock Slave 时,它通过 s2mm_frame_ptr_in 采集 Dynamic Genlock Master 发出的信号(Dynamic Genlock Master 上一帧的编号)来访问,同时通过 s2mm_frame_ptr_out 输出当前正在处理的帧的编号;
2.7.5、GenLock Summary
GenLock 是通过封锁通道对同一帧存的访问,来达到读写岔开的目的,根据策略,又分为了普通的和动态的,两种;Master 和 Slave 他们协商是通过帧的编号进行,针对普通的 GenLock Master/Slave,他们之间的协商,仅仅通过 Master 输出当前处理的帧即可,因为 Master 不会错过任何一帧:
针对 Dynamic Genlock Master/Slave 来说,有一个动态协商的过程,属于见缝插针:

2.7.6、Examples
GenLock:
下面的例子中:Write 通道(S2MM)配置为 GenLock Master,Read 通道(MM2S)配置为 GenLock Slave,Write 通道的速度快于 Read 通道:
以 3 帧存为例:
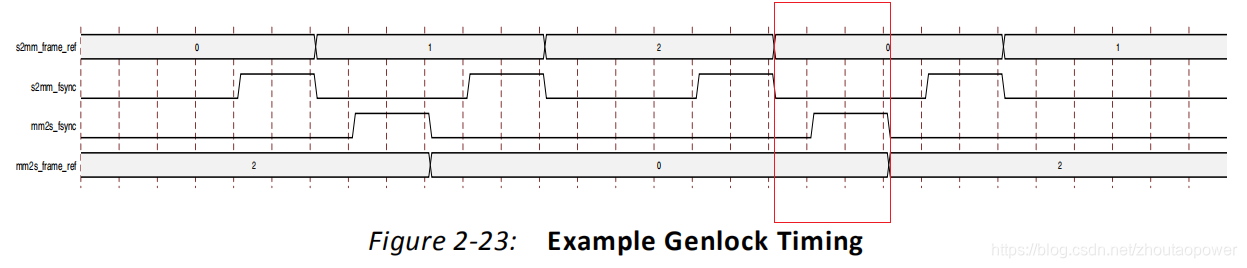
s2mm 顺序访问 0、1、2帧,不受任何影响,因为他是 GenLock Master
mm2s 在 mm2s_fsync 第一个上升沿,发现来自 GenLock Master 的处理帧为 ,1,所以处理 0;
在 mm2s_fsync 第二个上升沿,发现 Master 正在处理 0,那么转到处理 2;
可以看到,在同一时间,其实对 0 帧,还是有重叠访问,即,红色区域;
GenLock Dynamic:
和上面同样的预设条件,只不过换成了 GenLock Dynamic Master/Slave:
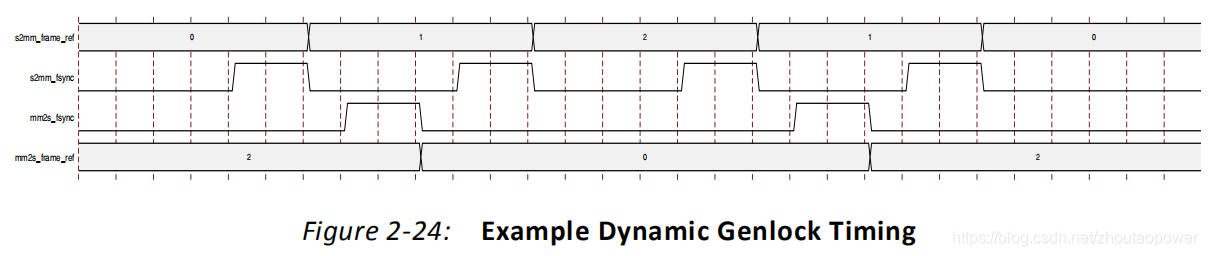
可以看到,其实读写完全不会访问同样的帧;
3、Programming Sequence
VDMA 操作首先需要设置视频参数、起始地址寄存器和VDMA控制寄存器。以下列出了启动 AXI VDMA 操作所需的最少步骤:
1、如果需要,将控制信息写入通道VDMACR寄存器(MM2S的偏移量0x00,S2MM的偏移量0x30)以设置中断使能,并设置VDMACR.RS = 1以启动AXI VDMA通道。
2、将有效的视频帧缓冲区起始地址写入通道START_ADDRESS寄存器1至N,其中N等于帧缓冲区(MM2S的偏移量0x5C最高为0x98,S2MM的偏移量0xAC最高为0xE8)。如果需要,设置REG_INDEX寄存器。
3、当AXI VDMA配置为大于32的地址空间时,每个起始地址将被编程为两个寄存器的组合,其中第一个寄存器用于指定地址的LSB 32位,而下一个寄存器用于指定MSB 32位。
4、写入有效的帧延迟(仅对Genlock从设备有效)至FRMDLY_STRIDE寄存器(对于MM2S,偏移量0x58;对于S2MM,偏移量0xA8)。
5、将有效的水平大小写入通道HSIZE寄存器(MM2S偏移0x54;S2MM 为0xA4)。
6、将有效的垂直大小写入通道VSIZE寄存器(MM2S偏移0x50;S2MM为 0xA0 )。这将启动通道,传输视频数据。
参考阅读:
ZYNQ VDMA:
https://blog.csdn.net/qq_36662353/article/details/107197425
https://blog.csdn.net/weixin_42639919/article/details/81144746
https://blog.csdn.net/long_fly/article/details/79066302
https://blog.csdn.net/weixin_43937539/article/details/106341242
AXI4-Stream

















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









