







参考:
强推:https://zhuanlan.zhihu.com/p/45131536
https://zhuanlan.zhihu.com/p/372835186
https://zhuanlan.zhihu.com/p/262876724
https://baijiahao.baidu.com/s?id=1666580334381729961&wfr=spider&for=pc
- 熵/信息熵: H = − ∑ p ( x ) l o g ( p ( x ) ) H=-\sum p(x)log(p(x)) H=−∑p(x)log(p(x))
注意,信息论中log的底数为2。(以其他底数也无妨,多一个常数倍数而已)
− l o g ( p ( x ) ) -log(p(x)) −log(p(x))为信息量,传递p(x)需要的最小比特数
H
=
−
∑
p
(
x
)
l
o
g
(
p
(
x
)
)
H=-\sum p(x)log(p(x))
H=−∑p(x)log(p(x))则是期望,编码某个随机变量平均需要的比特数
信息量越大,需要的比特数越大,信息熵越大

2、交叉熵:
C
E
(
p
,
q
)
=
−
∑
p
(
x
)
l
o
g
(
q
(
x
)
)
CE(p,q) = -\sum p(x)log(q(x))
CE(p,q)=−∑p(x)log(q(x))
现实中以q(x)来近似本来的p(x),即以q(x)来编码传递p(x)需要的比特数
3、KL散度/相对熵 = 交叉熵-信息熵
D
K
L
(
p
∣
∣
q
)
=
C
E
(
p
,
q
)
−
H
(
p
(
x
)
)
=
−
∑
p
(
x
)
l
o
g
(
q
(
x
)
)
−
(
−
∑
p
(
x
)
l
o
g
(
p
(
x
)
)
)
=
−
∑
p
(
x
)
l
o
g
q
(
x
)
p
(
x
)
=
∑
p
(
x
)
l
o
g
p
(
x
)
q
(
x
)
D_{KL}(p||q)=CE(p,q)-H(p(x))= -\sum p(x)log(q(x))-(-\sum p(x)log(p(x)))=-\sum p(x)log\frac{q(x)}{p(x)}=\sum p(x)log\frac{p(x)}{q(x)}
DKL(p∣∣q)=CE(p,q)−H(p(x))=−∑p(x)log(q(x))−(−∑p(x)log(p(x)))=−∑p(x)logp(x)q(x)=∑p(x)logq(x)p(x)
任何事情都有代价;以p(x)近似表达编码q(x)肯定需要付出代价/附加信息,这个代价就是KL散度。(分类loss中,由于第一项信息熵为常数,所以最小化交叉熵等价于最小化KL散度,即最小化real和output分布)
KL散度在一定程度上衡量了两个分布的差异,具有如下性质:

3、JS散度
KL散度不对称,不满足三角不等式,因此不是距离
JS散度满足对称(满不满足三角不等式不清楚):
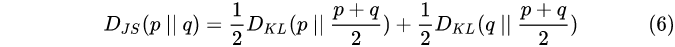
4、F散度(最通用)
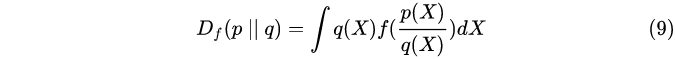

5、Wasserstein距离(Earth-Mover推土机距离)
我们回头看看KL散度的公式,就可以发现KL散度和JS散度有一个隐蔽的问题:如果两个分布 [公式] 离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。这在学习算法中是比较致命的,这就意味这这一点的梯度为0。梯度消失了。
Wasserstein距离可以解决这种问题,Wasserstein距离也叫做Earth-Mover(推土机)距离,之所以叫做推土机距离是因为,它可以形象的使用两个土堆的的移动问题来表达。
我们将两个分布 [公式] 看成两堆土,如下图所示,希望把其中的一堆土移成另一堆土的位置和形状,有很多种可能的方案。推土代价被定义为移动土的量乘以土移动的距离,在所有的方案中,存在一种推土代价最小的方案,这个代价就称为两个分布的 Wasserstein 距离。















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









