







Simple Entity-Centric Questions Challenge Dense Retrievers
原文链接:https://aclanthology.org/2021.emnlp-main.496/
(2021)
摘要
DPR 对于非常见实体效果差
讨论问题:
1)数据增强无法解决
2)robust 段落编码器帮助解决问题适应
由于密集检索模型的成功,开放域问答最近迅速流行,该模型已经超越了仅使用少量监督训练示例的稀疏模型。然而,在本文中,我们证明当前的密集模型还不是检索的圣杯。我们首先构建 EntityQuestions,这是一组基于维基数据事实的简单、实体丰富的问题(例如,“Arve Furset 出生在哪里?”),并观察到密集检索器的性能远远低于稀疏方法。我们研究了这个问题并发现,除非在训练过程中明确观察到问题模式,否则密集检索器只能泛化到常见实体。我们讨论了解决这个关键问题的两个简单解决方案。首先,我们证明数据增强无法解决泛化问题。其次,我们认为更强大的段落编码器有助于使用专门的问题编码器促进更好的问题适应。我们希望我们的工作能够揭示创建一个强大的、通用的密集检索器的挑战,该检索器可以在不同的输入分布上良好地工作。
1. 引言
最近的密集通道检索器在流行的问答数据集上大大优于传统的稀疏检索方法,如 TF-IDF 和 BM25 (Robertson 和 Zaragoza, 2009) (Lee et al 2019, Guu et al 2020, Karpukhin et al 2020, Xiong et al 2021)。
这些密集模型使用监督数据集进行训练,密集通道检索器 (DPR) 模型(Karpukhin 等人,2020 年)表明,仅在 BERT 之上训练 1,000 个监督示例(Devlin 等人,2019 年)就已经优于 BM25,这使其非常有吸引力在实际使用中。
在这项工作中,我们认为密集检索模型还不够鲁棒,无法取代稀疏方法,并研究了密集检索器仍然面临的一些关键缺点
我们首先构建了 EntityQuestions,这是一个简单的、以实体为中心的问题(例如“Arve Furset 出生在哪里?”)的评估基准,结果表明密集检索方法的泛化能力非常差。如表 1 所示,在单个数据集自然问题 (NQ)(Kwiatkowski 等人,2019 年)或常见 QA 数据集组合上训练的 DPR 模型的性能远远低于稀疏 BM25 基线(平均为 49.7% vs 71.2%),某些问题模式的差距绝对达到 60%!
基于这些结果,我们深入探讨了为什么单个密集模型在这些简单问题上表现如此糟糕。我们将这些问题的两个不同方面解耦:实体和问题模式,并确定这些问题的哪些因素给密集模型带来了如此困难。我们发现密集模型只能成功回答基于常见实体的问题,而在稀有实体上会迅速退化。我们还观察到,只有在训练过程中明确观察到问题模式时,密集模型才能泛化到看不见的实体
最后,我们对解决这一关键问题的实际解决方案进行了两项调查。
首先,我们考虑数据增强并分析单任务微调和多任务微调之间的权衡。其次,我们考虑单个固定段落索引并微调专门的问题编码器,从而实现新问题的内存高效传输。我们发现数据增强虽然能够缩小单个领域的差距,但无法持续提高未知领域的性能。我们还发现,构建强大的通道编码器对于成功适应新领域至关重要。我们认为这项研究是构建通用密集检索模型的重要一步。
2. 背景和相关工作
稀疏检索
在密集检索器出现之前,传统的稀疏检索器(例如 TFIDF 或 BM25)是开放域问答系统中事实上的方法(Chen 等人,2017;Yang 等人,2019)。这些稀疏模型使用问题和段落之间的加权术语匹配来测量相似性,并且不会在特定的数据分布上进行训练。众所周知,稀疏模型非常擅长词汇匹配,但无法捕获同义词和释义。
密集检索
相反,密集模型(Lee 等人,2019;Karpukhin 等人,2020;Guu 等人,2020)利用来自监督 QA 数据集的学习表示来测量相似性,并利用 BERT 等预训练的语言模型。在本文中,我们使用流行的密集通道检索器(DPR)模型(Karpukhin 等人,2020)作为我们的主要评估3,并且我们还在附录 A 中报告了 REALM(Guu 等人,2020)的评估。DPR 模型使用两个编码器(即问题编码器和段落编码器)的检索问题,使用 BERT 进行初始化。 DPR 在训练期间使用对比目标,从 BM25 中挖掘批量负例和硬负例。在推理过程中,会对预定义的大量段落(例如,英语维基百科中的 2100 万个段落)进行编码和预索引 - 对于任何测试问题,都会返回相似度分数最高的顶部段落。最近,在改进密集检索方面取得了其他进展,包括结合更好的硬负片(Xiong 等人,2021;Qu 等人,2021)或细粒度短语检索(Lee 等人,2021)。我们将它们留待将来调查。
泛化问题
尽管密集检索器在领域内的表现令人印象深刻,但它们泛化到未见过的问题的能力仍然相对未被充分开发。最近,Lewis 等人 (2021a) 发现流行的 QA 基准上的训练集和测试集之间存在很大的重叠,并得出结论,当前的模型倾向于记住训练问题,并且在非重叠问题上表现明显较差。
AmbER(Chen 等人,2021)测试集旨在研究段落检索器和实体链接器的实体消歧能力。他们发现与常见实体相比,模型在稀有实体上的表现要差得多。与这项工作类似,我们的结果表明密集检索模型的泛化能力很差,尤其是在稀有实体上。我们进一步进行了一系列分析来剖析问题并研究学习鲁棒密集检索模型的潜在方法。最后,另一项并行工作(Thakur 等人,2021)引入了用于检索模型零样本评估的 BEIR 基准,并表明密集检索模型在大多数数据集上的表现均低于 BM25。
3. EntityQuestions
在本节中,我们构建一个新的基准 EntityQuestions,这是一组简单的、以实体为中心的问题,并比较密集和稀疏检索器。
数据收集
我们从维基数据中选择 24 个常见关系(Vrandeciˇ c 和 Krötzsch ´,2014),并使用手动定义的模板(附录 A)将事实(主语、关系、宾语)三元组转换为自然语言问题。为了确保转换后的自然语言问题可以从维基百科中得到回答,我们从 TREx 数据集(Elsahar 等人,2018)中采样三元组,其中三元组与句子对齐作为维基百科中的证据。
我们按照以下标准选择关系:
(1)T-REx 中有足够的三元组(>2k);
(2) 很容易为关系提出明确的问题;
(3)我们不会选择仅与少数候选答案(例如性别)的关系,这在我们评估检索器时可能会导致太多的假阴性;
(4) 我们既包括人员相关关系(例如出生地),也包括非人员关系(例如总部)。对于每个关系,我们随机抽取最多 1,000 个事实来形成评估集。我们报告实体问题所有关系的平均准确度。
结果
我们在 EntityQuestions 数据集上评估 DPR 和 BM25,并在表 1 中报告结果(请参阅附录 A 中的完整结果和示例)。在 NQ 上训练的 DPR 在几乎所有问题集上都明显低于 BM25。例如,在问题“[E] 出生在哪里?”时,使用前 20 名检索准确度,BM25 绝对优于 DPR 49:8%。4 尽管在多个数据集上训练 DPR 可以提高性能(即从 49:7 % 到平均 56:7%),与 BM25 相比仍然明显相形见绌。我们注意到,在有关个人实体的问题上,差距尤其大。
为了测试我们研究结果的普遍性,我们还评估了 REALM (Guu et al, 2020) 在 EntityQuestions 上的检索性能。与 DPR 相比,REALM 采用了称为显着跨度掩蔽(SSM)的预训练任务,以及 Lee 等人(2019)的逆完型填空任务。我们将评估结果包含在附录 A 中。5 我们发现,在所有关系中,REALM 的得分仍然远低于 BM25(平均为 19:6%)。这表明合并 SSM 等预训练任务仍然不能解决这些简单的以实体为中心的问题的泛化问题
4. 剖析问题:实体 vs 问题模式
实体的影响
1)密集检索对于常见实体和训练时期见过的实体,检索效果更好
问题模式对于检索的影响
1)在训练期间见过类似的问题模式对于模型的泛化影响很大
2)段落编码相较于 query 编码对于性能影响更大,使得相似段落的分布更加稀疏,对于检索是有帮助的。
在本节中,我们将研究为什么密集型检索器在这些问题上表现不佳。具体来说,我们想了解较差的泛化是否应归因于(a)新颖的实体,或(b)看不见的问题模式。为此,我们研究了在 NQ 数据集上训练的 DPR,并评估三个代表性问题模板:出生地、总部和创建者。
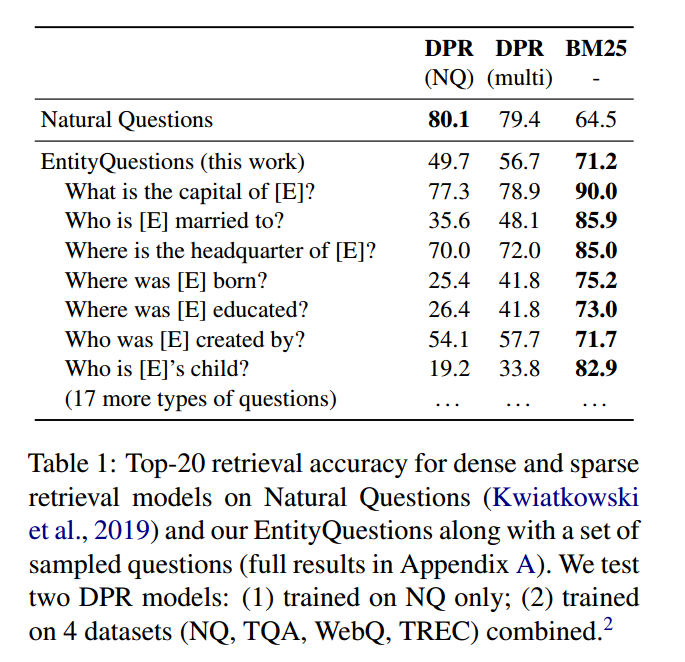
4.1 密集检索表现出流行偏差
我们首先确定问题中的实体 [E] 如何影响 DPR 检索相关段落的能力。为此,我们考虑维基数据中与特定关系关联的所有三元组,并根据维基百科中主题实体的频率对它们进行排序。在我们的分析中,我们使用维基百科超链接计数作为实体频率的代理。接下来,我们将三元组分为 8 个桶,使得每个桶具有大致相同的累积频率。
使用这些桶,我们为每个关系考虑两个新的评估集。第一个(表示为“rand ent”)从每个桶中随机采样最多 1,000 个三元组。第二个(表示为“train ent”)选择每个桶中的所有三元组,这些三元组具有在 NQ 训练集中的问题中观察到的主题实体,如 ELQ 所标识的(Li 等人,2020)。
我们在这些评估集上评估 DPR 和 BM25,并在图 1 中绘制前 20 个准确度。DPR 在最常见的实体上表现良好,但在较稀有的实体上表现迅速下降,而 BM25 对实体频率不太敏感。还值得注意的是,DPR 在 NQ 训练期间看到的实体上的表现通常比在随机选择的实体上表现得更好。这表明 DPR 表示能够更好地表示最常见的实体以及训练期间观察到的实体。
4.2 观察问题有助于泛化
接下来,我们研究当针对问题模式进行训练时,DPR 是否可以泛化到看不见的实体。
对于考虑的每个关系,我们构建一个最多包含 8 个关系的训练集8000 三倍。我们确保训练三元组中的标记不会与相应测试集中三元组中的标记重叠。除了使用评估期间使用的问题模板来生成训练问题外,我们还基于语法不同但语义相同的问题模板构建训练集。7我们在训练集上针对每个关系微调 DPR 模型,并在针对特定关系的 EntityQuestions 评估集并在表 2 中报告结果。
显然,在训练期间观察问题模式使 DPR 能够很好地概括未见过的实体。在所有这三种关系上,DPR 在检索精度方面都可以与 BM25 相媲美甚至优于 BM25。对等效问题模式的训练实现了与精确模式相当的性能,这表明密集模型不依赖于问题的特定措辞。我们还尝试分别微调问题编码器和段落编码器。如表 2 所示,令人惊讶的是,仅训练段落编码器 (OnlyP) 和仅训练问题编码器 (OnlyQ) 之间存在显着差异:例如,在出生地方面,DPR 达到了 72:8% 的准确率微调的段落编码器,而如果仅微调问题编码器,则可以达到 45:4%。这表明段落表示可能是模型泛化的罪魁祸首。

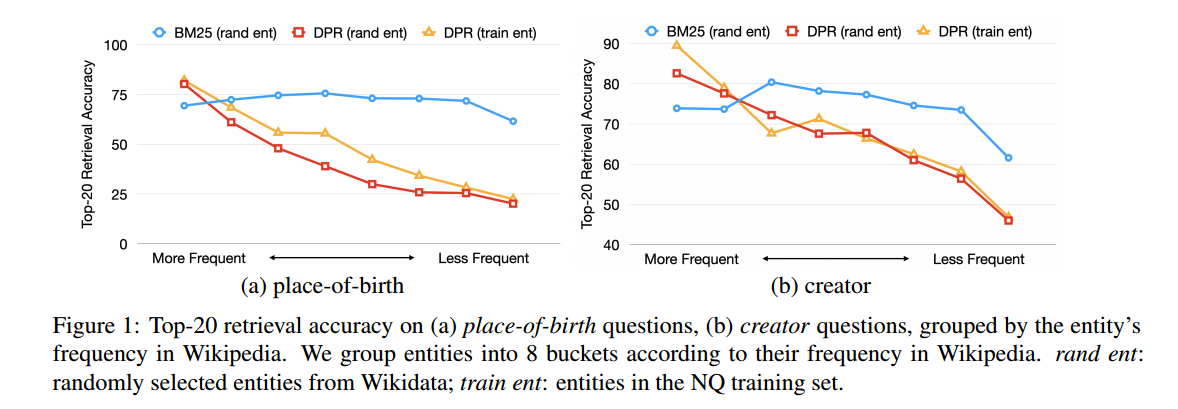
为了了解通道表示从微调中学到了什么,我们使用 t-SNE 可视化微调之前和之后的 DPR 通道空间(Van der Maaten 和 Hinton,2008)。我们在图 2 中绘制了从 NQ 和出生地采样的积极段落的表示。在微调之前,出生地问题的积极段落聚集在一起。使用内积来区分这个聚集空间中的段落更加困难,这解释了为什么仅微调问题编码器会产生最小的增益。微调后,通道分布更加稀疏,更容易区分。
5. 迈向稳健的密集检索
1)passage 编码器优化的前景
2)query 编码器对于不同问题的优化前景
在对问题有了清晰的理解后,我们探索了一些旨在解决泛化问题的简单技术。
数据增强
我们首先探讨对单个 EntityQuestions 关系中的问题进行微调是否有助于泛化整套 EntityQuestions 以及其他 QA 数据集(例如 NQ)。我们为单个关系构建一组训练问题,并考虑两种训练机制:一种是我们仅对关系问题进行微调。第二个是我们以多任务方式对关系问题和 NQ 进行微调。我们对三个关系进行此分析,并在表 3 中报告前 20 个检索准确率。
我们发现,仅对单个关系进行微调可以显着改善 EntityQuestions,但会降低 NQ 的性能,并且平均仍然大大落后于 BM25。当同时对关系问题和 NQ 进行微调时,NQ 的大部分性能得以保留,但 EntityQuestions 的收益要小得多。显然,对一类以实体为中心的问题进行微调并不一定能解决其他关系的泛化问题。原始分布的准确性和新问题的改进之间的这种权衡为通用密集编码器带来了一个有趣的张力。
专门的问题编码器
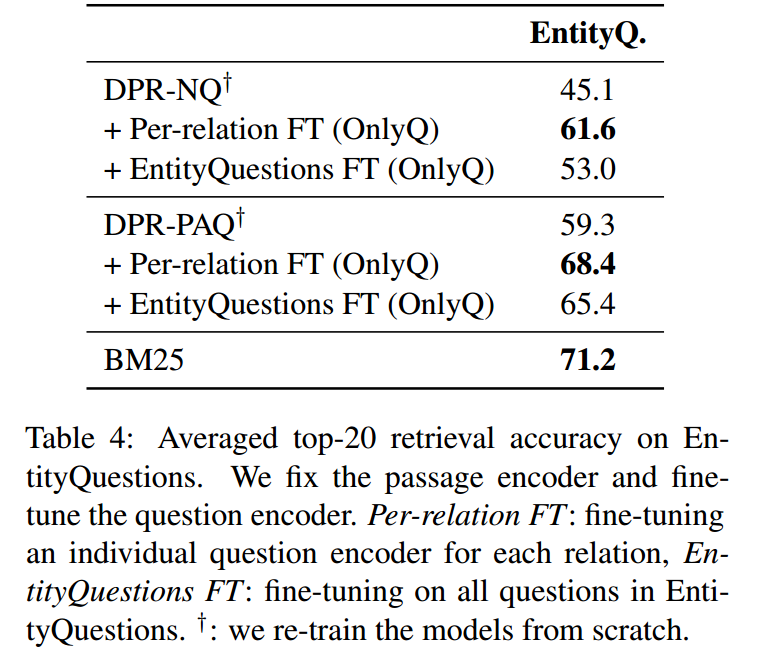
虽然为所有未见过的问题分布建立一个检索模型具有挑战性,但我们考虑另一种方法,即使用单个段落索引并采用专门的问题编码器。由于段落索引在不同的问题模式中是固定的,并且无法通过微调进行调整,因此拥有强大的段落编码器至关重要。
我们比较了两种 DPR 段落编码器:一种基于 NQ,另一种基于 PAQ 数据集(Lewis 等人,2021b)。8 我们期望在 PAQ 上训练的问题编码器更加稳健,因为 (a) 在 PAQ 中采样了 10M 段落,这可以说比 NQ 更加多样化,并且 (b) 所有可能的答案范围都是使用自动工具识别的。我们为 EntityQuestions 中的每个关系微调问题编码器,保持段落编码器固定。如表 4 所示,9 微调在 PAQ 上训练的编码器比微调在 NQ 上训练的编码器提高了性能。这表明 DPR-PAQ 编码器更加稳健和适应性更强,几乎缩小了与使用单通道索引的 BM25 的差距。我们相信,构建强大的通道索引是未来研究更通用检索器的令人鼓舞的途径
6. 结论
在这项研究中,我们表明 DPR 在 EntityQuestions 上的表现明显低于 BM25,EntityQuestions 是一个基于从 Wikidata 挖掘的事实的简单问题数据集。我们得出了关于 DPR 在此数据集上表现如此糟糕的原因的关键见解。我们了解到,DPR 可以记住常见实体的稳健表示,但在训练过程中如果不明确观察问题模式,就很难区分较稀有的实体。
我们建议未来将显式实体记忆纳入密集检索器中,以帮助区分稀有实体。最近的许多作品(Wu 等2020;李等人2020; Cao et al 2021)证明检索器可以轻松学习大量维基百科实体的密集表示。 DPR 还可以利用 EaE(Févry 等人,2020)或 LUKE(Yamada 等人,2020)等实体感知嵌入模型来更好地召回长尾实体。















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









