




中国国产GPU制造商摩尔线程(Moore Threads)在AI加速器领域取得了显著进展,其最新推出的MTT S4000 AI GPU在训练大规模语言模型时表现突出,据称相较于其前代产品有着显著的性能提升。根据cnBeta的报道,搭载S4000 GPU的全新“酷鹅千卡智能计算集群”在AI测试中排名第三,超越了几款基于英伟达AI GPU集群的系统。

### 测试概览:
- **测试场景**:Kua'e Qianka智能计算集群的稳定性测试,使用MT-infini-3B大型语言模型作为基准测试。
- **成绩**:总训练时间为13.2天,期间无故障或中断。
- **排名**:在相同规模的AI GPU集群中(推测为使用相同数量的GPU)排名靠前。
### 性能对比:
尽管报道中没有提供详细的对比数据,如英伟达GPU的具体型号(A100、H100或H200),以及训练负载是否一致(MT-infini-3B与Llama3-3B等模型的训练可能差异较大),但摩尔线程MTT S4000集群的表现仍被视为与英伟达前代A100架构相当或接近Ampere性能水平。MTT S4000不仅大幅超越了自家的S3000和S2000型号,同时也优于英伟达基于Turing架构的AI加速器。
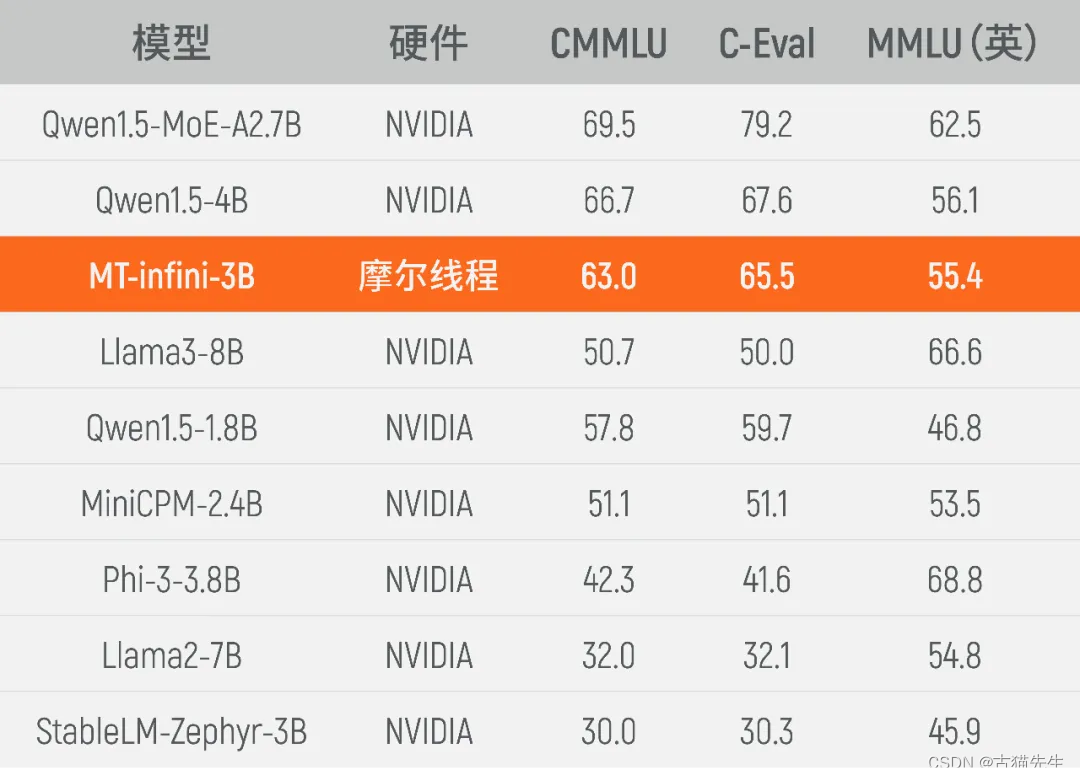
### 意义与展望:
对于成立不足五年的摩尔线程来说,这一成就意义重大,标志着其已能开发出与国际GPU巨头英伟达、AMD及英特尔竞争的AI加速器,虽然尚未在性能上超越,但这为其在超级计算机和AI集群领域追赶甚至超越西方技术奠定了基础。
### 未来挑战与机遇:
- **持续进步**:摩尔线程需要继续在每一代产品中实现显著的性能提升,才能在未来几年内与西方竞争对手的AI GPU同台竞技。
- **游戏图形性能**:尽管在AI性能方面表现出色,但摩尔线程的游戏显卡在测试中表现不佳,部分原因是驱动程序和优化不够成熟。AI计算与实时图形渲染虽都需要强大算力,但两者领域不同,因此在一方的专长并不能直接转化为另一方的能力。
总的来说,摩尔线程MTT S4000在AI训练中的表现是中国在自主GPU技术发展的一个重要里程碑,但要达到与国际领先水平全面竞争还需克服诸多技术和市场挑战。



















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











