







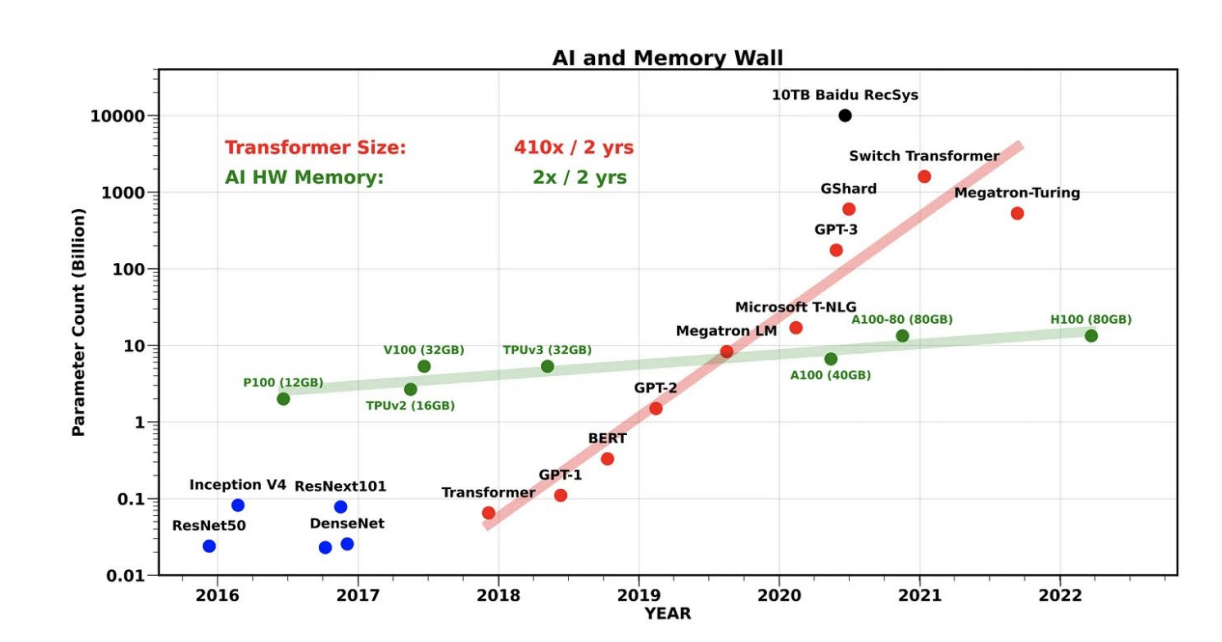
随着机器学习模型的复杂性不断增加,内存使用量也随之增长,因此,内存优化变得尤为重要。
机器学习内存足迹
机器学习模型通常由数据结构如张量和矩阵组成。例如,一个形状为(1000, 1000),每个元素为32位浮点数的二维张量将占用大约4MB的内存。在训练过程中,内存消耗主要来自模型参数、梯度以及优化器状态的存储,还有中间激活值和反向传播缓冲区的存储。内存分配和释放过程中的动态内存管理也可能引发内存泄漏和碎片化的问题。
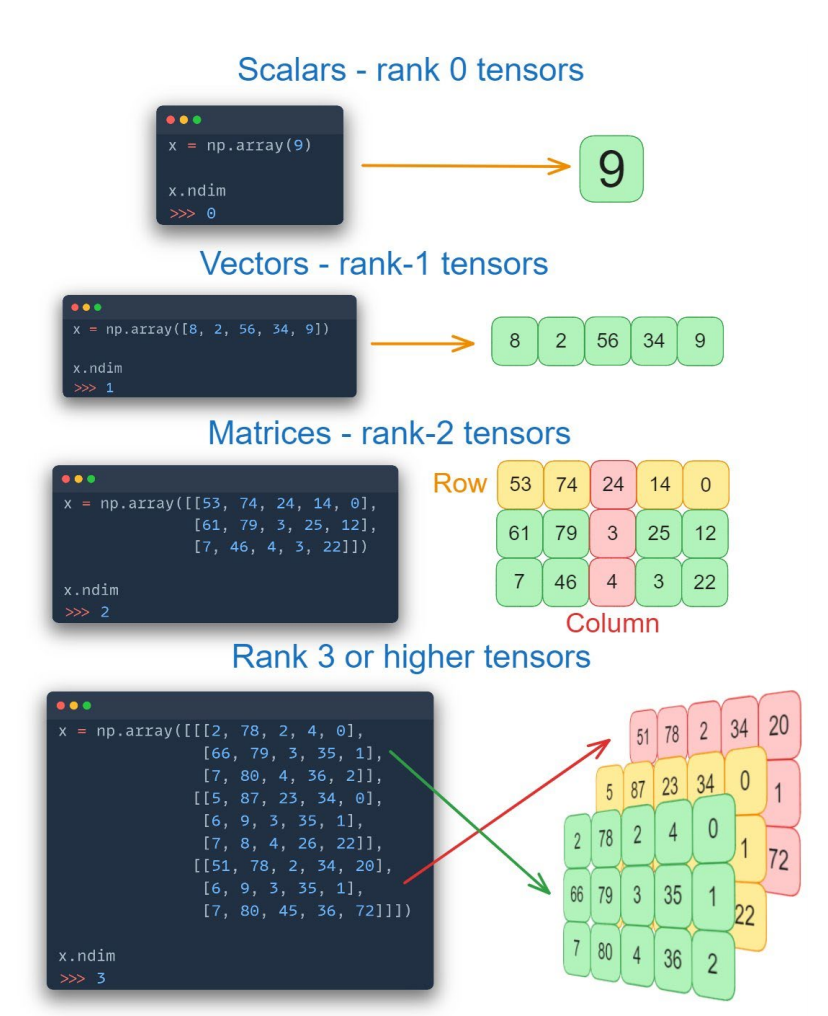
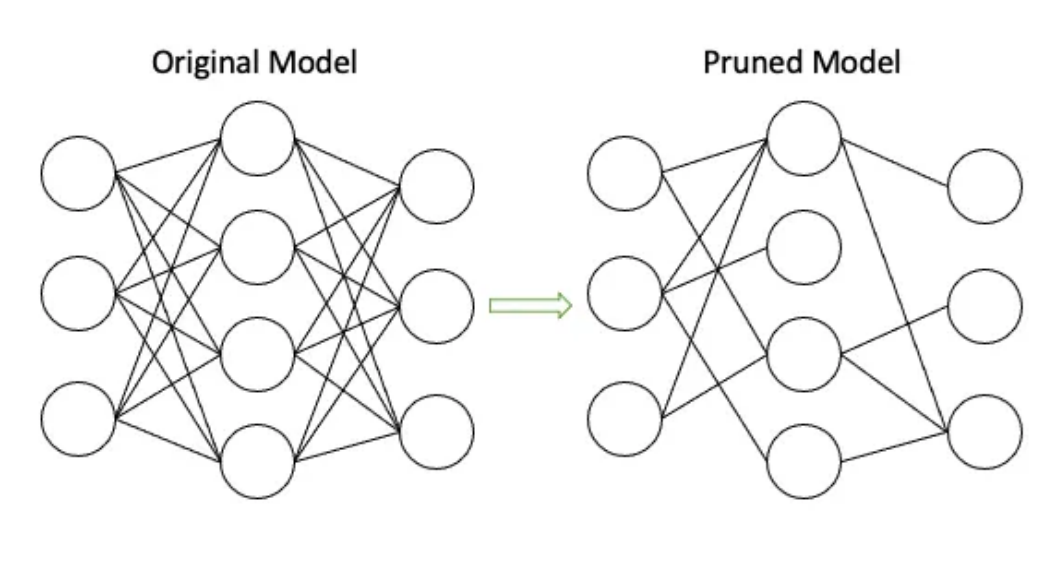
数据量化
数据量化是指降低数据表示的精度,比如将32位浮点数转换为8位整数。量化可以减少内存占用50-75%,同时还能加快计算和推理时间。量化技术分为均匀量化和非均匀量化。前者采用等间距区间,而后者依据数据分布使用变间距区间。后训练量化是在模型训练完成后进行量化,而量化感知训练则是将量化纳入训练过程中,以获得更好的准确性。
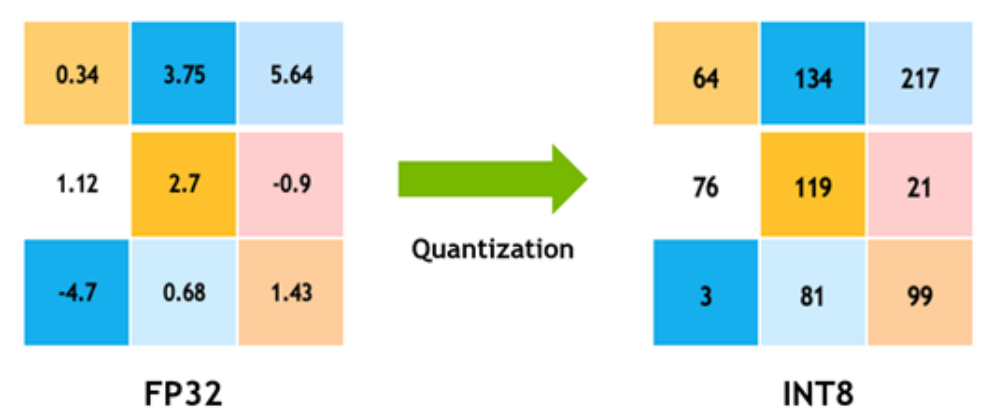
模型剪枝
模型剪枝通过移除不必要的或冗余的模型参数来减少内存占用。剪枝技术包括基于大小的剪枝,即去除绝对值较小的权重,以及结构性剪枝,即移除整个神经元、过滤器或通道。通过逐步剪枝和微调,可以在多轮迭代中逐渐剪枝模型,并通过微调恢复模型性能。剪枝可以减少高达90%的内存占用,并且能加快推理时间和提高能源效率。
高效的小批量选择
小批量选择是指将训练数据分成更小的子集。较大的小批量尺寸需要更多的内存来存储中间激活值和梯度,而较小的小批量尺寸虽然内存需求较低,但可能会影响收敛速度。为了提高效率,可以动态调整小批量尺寸以适应可用内存,并采用梯度累积策略,在更新权重之前执行多次前向和后向传递。
硬件考量
内存优化技术在不同硬件平台上有所不同。对于CPU,可以通过利用缓存层次结构和数据局部性、矢量化(SIMD)并行处理以及内存对齐来提高访问模式的效率。GPU则应利用高带宽内存(HBM),确保数据检索的高效合并,并最大化占用率,最小化CPU和GPU之间的数据传输。而对于专门的加速器(如TPU、FPGA),应利用片上内存以实现快速访问,优化数据流和计算图,并利用低精度算术和结构化稀疏性。
未来方向与研究
未来的内存优化研究将关注自动神经架构搜索(NAS),寻找平衡性能和内存使用的最优架构。量化感知训练(QAT)将在训练过程中联合优化模型参数和量化参数,从而比后训练量化获得更好的准确性。稀疏表示和计算将利用稀疏性进行内存优化,包括稀疏矩阵乘法、卷积和注意力机制。硬件与软件协同设计将联合优化硬件架构和软件算法,定制加速器以适应低精度算术和结构化稀疏性。高效的迁移学习将大规模预训练模型适应资源受限环境,包括模型压缩、知识蒸馏和参数共享技术。
结论
内存优化对于机器学习部署的效率和可扩展性至关重要。数据量化、模型剪枝和高效的小批量选择等技术可以显著减少内存消耗。考虑到硬件差异,硬件感知优化对于在多样化平台上最大化内存效率至关重要。真实世界案例研究表明了内存优化在各个领域的影响力。未来的研究方向为机器学习内存优化提供了有希望的途径,包括自动神经架构搜索、量化感知训练、稀疏计算、硬件与软件协同设计和高效的迁移学习。

















 5569
5569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











