








之前小编也写过多篇AI存储相关的文章,包括AI背景与分层存储的分析,以及AI存储重点从训练转向推理等内容。具体参考:
业内有很多关于AI不同解读对存储需求的分析,每家都有画对应的示意图。在这么多厂商的分析中,小编觉得Solidigm家画的眼前一亮。小编很早就看到了,由于不是公开信息,无法在公众号分享,近期Solidigm在FMS 2024上也公开了相关材料,正好分享给各位读者参考!
Solidigm QLC SSD也是目前市场的主力,在AI场景赚翻了。
-
SK集团(SK hynix和Solidigm):SK集团在2024年第二季度保持了第二大NAND闪存供应商的地位。AI需求的增加显著提升了Solidigm的发货量,尽管PC和智能手机需求有所下调。因此,该集团的bit容量发货量略有减少,但ASP增长了16%,导致NAND闪存营收环比增长13.6%,达到37.16亿美元。SK hynix计划长期将企业SSD发货量的比例提高到40%,以应对AI驱动的高容量企业SSD需求。
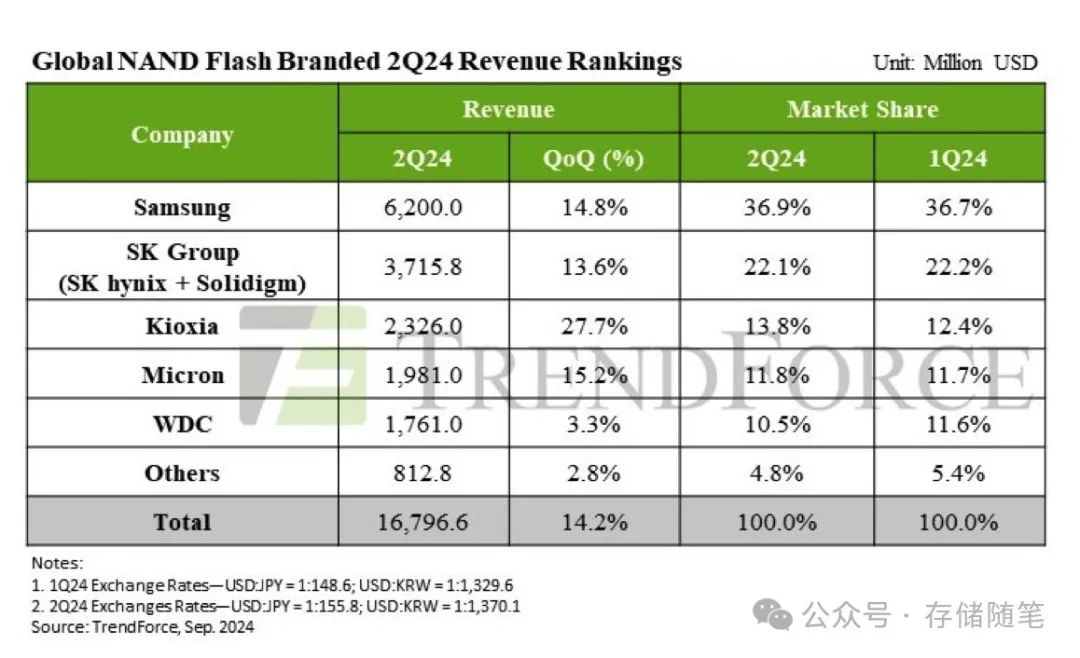
在AI的数据管道中,数据经历了从收集、准备、训练、验证、量化到推断的全过程。每个阶段都有其独特的数据访问模式。例如,在数据获取阶段,原始数据通常以顺序的方式写入对象存储层。随后,在数据准备阶段,数据被读取、预处理,并写回到计算服务器。而在训练阶段,数据以随机顺序暴露给GPU进行训练,并将训练后的模型写回存储。最后,模型在推断阶段被再次读取使用。
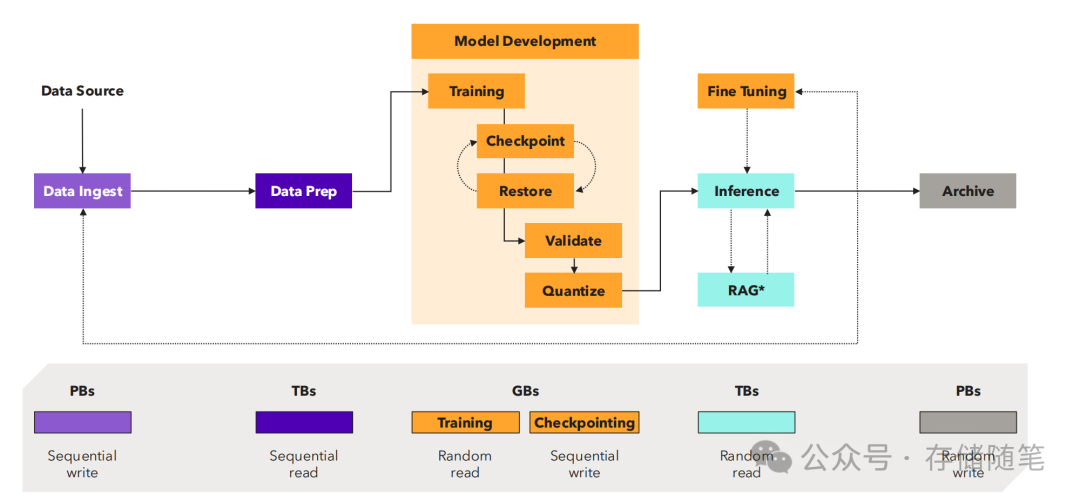
现代AI集群通常由几个不同的存储层级组成。
-
最底层的GPU服务器,它们拥有有限的存储空间(通常是8个U.2插槽)。
-
全闪存性能层,该层的服务器配置了快速存储设备(通常是TLC NAND),以弥补硬盘性能不足。
-
对象存储层,由包含多个存储设备的存储服务器或JBODs组成,当前大多数情况下使用的是硬盘(HDD)。
这样的分层存储架构有助于根据数据访问频率和性能要求合理分配数据。
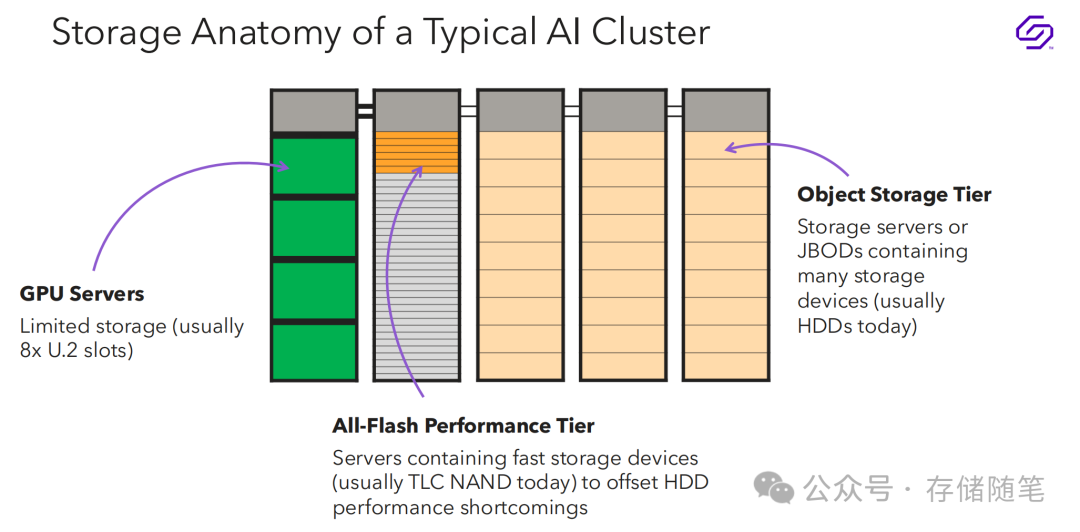
-
数据收集
-
-
原始数据以顺序方式写入对象存储层。这一阶段通常涉及大量的数据写入操作。
-
推荐解决方案:适用于高容量和顺序写入性能的存储设备。
-
-
数据预处理
-
-
数据从对象存储层读取到计算服务器。
-
CPU对原始数据进行预处理,然后将清洗后的数据写回。
-
推荐解决方案:具备顺序读写性能的存储设备。
-

-
训练
-
-
在此阶段,GPU以随机顺序读取数据进行训练。训练结果会被写入存储。
-
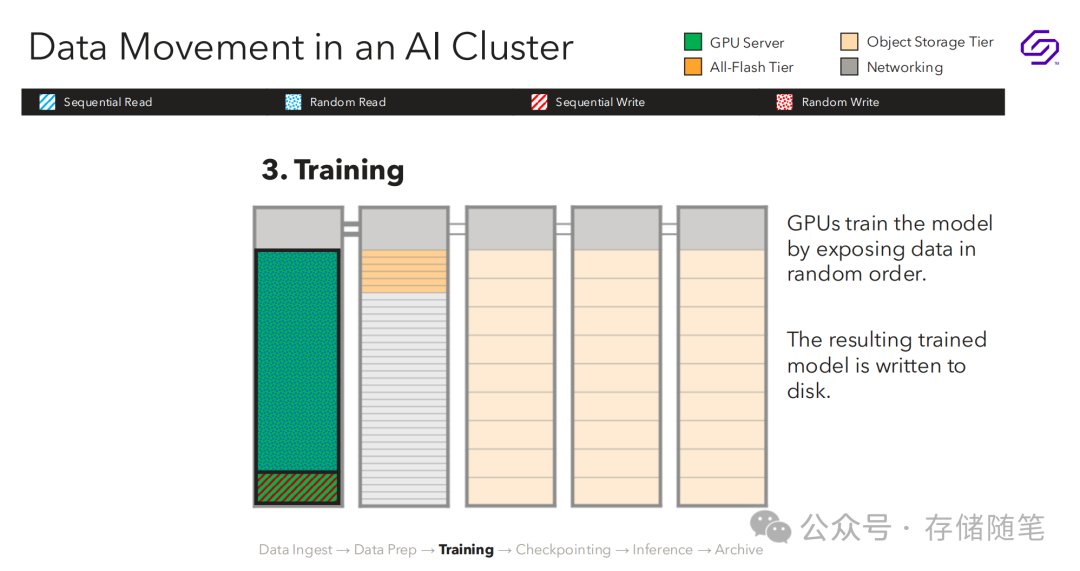
-
检查点
-
-
训练中的模型周期性地被写入磁盘,并按需读回。
-

-
推理与归档
-
-
模型部署后开始接收输入,这会在GPU服务器上产生随机读取活动。
-
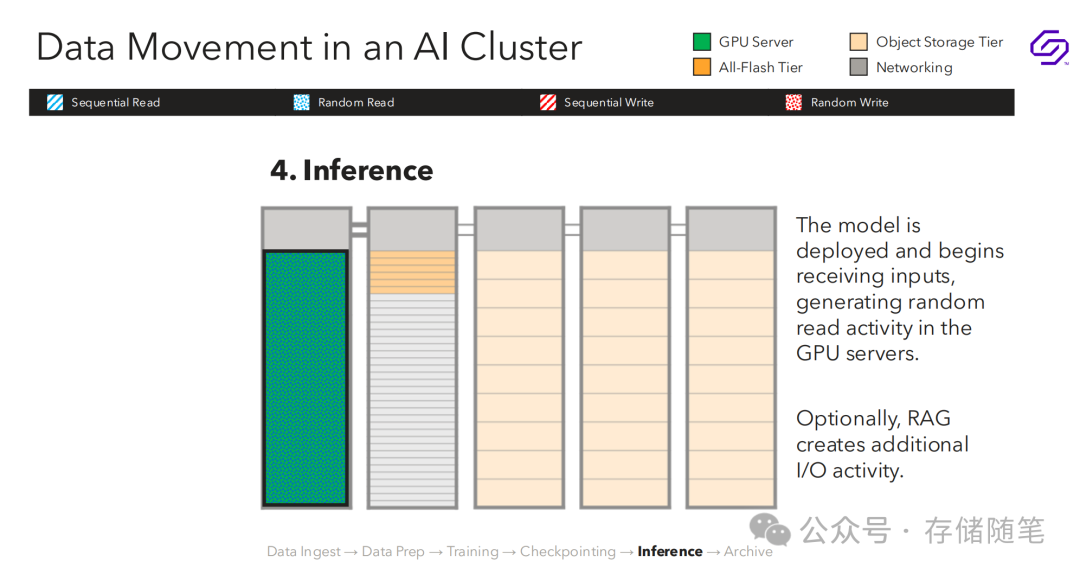
-
-
模型的输入和输出被捕获并写入对象存储层。
-
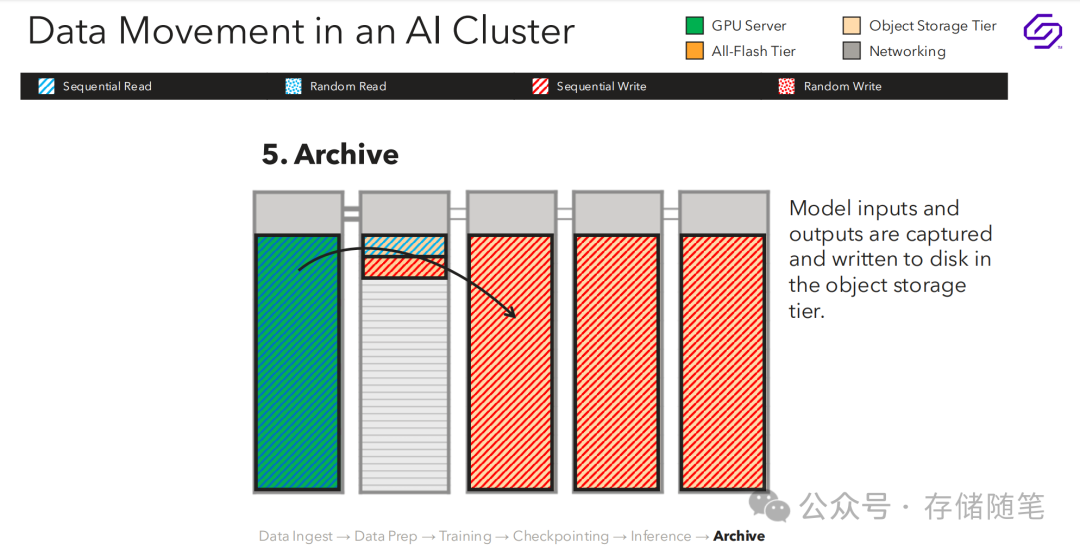
参考文献:FMS2024-Solidigm-《AI Data Pipeline》
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:



















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











