







目前在索引和挖掘时间序列数据方面的研究产生了许多有趣的算法和表示。然而,所考虑的算法和数据大小通常不能代表科学、工程和商业领域中遇到的日益庞大的数据集。在这项工作中,我们展示了如何使用一种新颖的多分辨率符号表示来索引比文献中考虑的任何其他数据集都大几个数量级的数据集。我们的方法允许快速精确搜索和超快速近似搜索。我们将展示如何在数据挖掘算法中利用这两种搜索类型的组合作为子例程,从而允许对包含数百万个时间序列的真正大规模的真实世界数据集进行精确挖掘。
相关工作:
1)Time Series Distance Measures

2)Time Series Representations

那些用星号注释的表示具有非常理想的属性,即允许下界。也就是说,我们可以在简化抽象上定义一个距离度量,该度量保证小于或等于在原始数据上测量的真实距离。正是这个下边界属性允许我们使用一个表示来索引数据,并保证不会出现错误的忽略
3)Review of Classic SAX

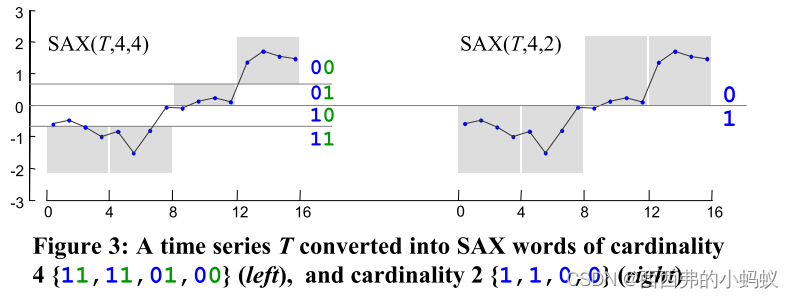

PAA表示减少了一个时间序列的维度,在这种情况下从16到4。SAX表示接受PAA表示作为输入,可获得一个小字母的符号与基数的大小。断点的离散化是通过想象一系列平行轴和标签与一个离散断点标签之间的每个区域。在该区域内的任何PAA值都可以映射到适当的离散值。
虽然SAX表示支持任意断点,但如果我们使用一个有序的数字列表Βreakpoints = β1,…,βa-1,以便N(0,1)高斯曲线下的面积,我们可以确保SAX单词中几乎等概率的符号

计算距离:

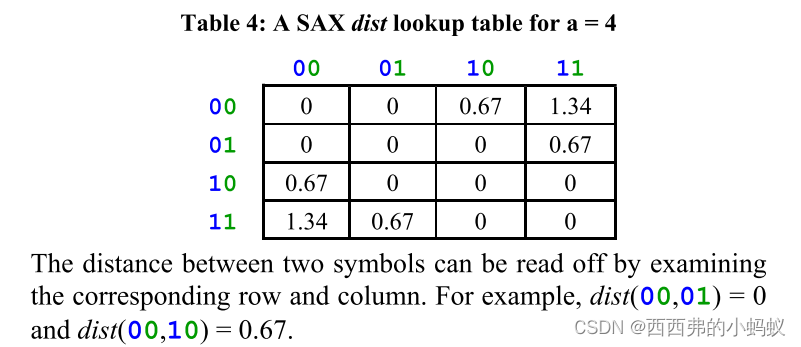
结论: 拥有更多SAX符号或更高的基数将产生更紧密的下界。我们很自然地会问,相对于PAA或DWT等竞争对手,这个下限函数能有多紧?这取决于数据本身和SAX单词的基数,但它与其他方法相比具有惊人的竞争力。为了看到这一点,我们可以测量下界的紧密度,它被定义为小于真实距离的下界距离

结果表明,对于较小的基数,SAX下界相当弱,但对于较大的基数,它迅速接近PAA/DWT的下界。256的基数为8位时,SAX的下限是PAA/DWT的98.5%,但后者需要32位。这告诉我们,如果我们比较表示系数,在它们之间几乎没有选择,但是如果我们进行逐位比较(参见第5节),SAX允许更严格的下界。这是SAX的一个属性,可以利用它来实现超可伸缩的索引。
THE iSAX REPRESENTATION
The Intuition Behind iSAX Indexing
本文的索引主要是用于一个相似性的查找。文中举了一个例子,比如基数为8的,SAX word长度(w)规定为4的这样一对参数,可能产生的不同的iSAX向量个数为。那么磁盘就分成这么多文件,每个文件只放相应的时间序列。
在查找的时候,想要找到相似的时间序列,只需要将输入的时间序列进行iSAX变换,取出对应区域的时间序列,一定相差不多。如果一定要精确的距离最近的,那么首先计算最佳近似的序列和输入序列的真实距离,然后遍历所有LABEL,如果其MINDIST比当前最短的距离要短,那么也计算这个LABEL下的所有序列和输入序列的真实距离。
然而上述所说在实际应用中仍然有一个致命的问题,就是数据倾斜。一个文件中可能存放了特别多序列,也有可能很多文件是空的。空的话查找时就要用一些trick,序列太多的话,明显会影响性能。一个方法是设置一个参数,让一个文件中的序列个数在[1,]之间。
既然设置了上限,就必须要有分割文件/Label的方法。其实就是在SAX word中随机选一个进行2的幂次扩增,1次能扩增成两个文件,以下图为例:

对原文件中的每个序列的某一个PAA segment重新计算PAA值应该落入的区域,然后分入两个文件里。
iSAX Index Construction
通过沿着一个或多个维度增加基数,一组由iSAX字表示的时间序列可以分裂为两个互斥的子集。维数d和字长w (1 d w)提供扇出速率的上限。如果每维基数的每次增加都遵循迭代加倍的假设,那么断点对齐包含重叠,从而在更细的粒度上保留公共iSAX单词和iSAX单词集之间的分层包含。


iSAX的使用允许创建分层的索引结构,包含不重叠的区域[2](不像r -tree等[6]),并控制扇出率。为了具体起见,我们在图5中描述了一个简单的基于树的索引结构,它说明了使用iSAX进行索引的有效性和可伸缩性。
给定基数b、字长w和阈值th (b是可选的;它可以默认为2,也可以设置为从更高的基数开始计算)。索引结构分层地细分SAX空间,导致时间序列条目之间的区分,直到每个子空间中的条目数量低于th。这样的结构是使用树实现的,其中每个节点表示SAX空间的一个子集,因此这个空间是由其后代的联合形成的SAX空间的超集。节点代表的SAX空间与iSAX词一致,通过比较iSAX词来计算节点之间或时间序列之间的值。树中的三类节点及其各自的功能如下所述
Terminal Node 终端节点是一个叶节点,它包含一个指向磁盘上带有原始时间序列条目的索引文件的指针。对应索引文件中的所有时间序列都以终端节点的代表性iSAX字为特征。终端节点表示SAX空间中包含一组时间序列条目所需的最粗粒度。如果插入导致时间序列的数量超过th,则拆分SAX空间(和节点)以提供额外的区分。
Internal Node: 内部节点在SAX空间中指定分裂,当终端节点所包含的时间序列数量超过th时创建内部节点。内部节点根据迭代加倍策略沿着一个或多个维提升基数值,从而分割SAX空间。维护从iSAX单词(表示SAX空间的细分部分)到节点的散列,以区分条目。从触发拆分的终端节点开始的时间序列被插入到新创建的内部节点,并散列到它们各自的位置。如果散列不包含匹配的iSAX条目,则在插入之前创建一个新的终端节点,并相应地更新散列。为简单起见,我们沿单个维度使用二进制分割,使用轮询来确定分割维度。
Root Node: 根节点代表了完整的SAX空间,在功能上类似于内部节点。根节点以基数计算时间序列,即简化表示中每个维度的粒度为b。遇到的iSAX词对应于某些终端或内部节点,用于指导相应的索引函数。

Approximate Search
对于许多数据挖掘应用程序,只需要近似搜索。iSAX索引能够支持非常快的近似搜索;特别是,它们只需要访问单个磁盘。近似方法是由两个相似的时间序列通常用相同的iSAX字表示的直觉推导出来的。在这个假设下,通过在索引中寻找与查询具有相同iSAX表示的终端节点,可以得到近似的结果。这是通过按照拆分策略遍历索引并在每个内部节点匹配iSAX表示来实现的。因为索引是分层的,没有重叠,所以如果存在这样的终端节点,它会被及时识别。到达这个终端节点后,将获取并返回该节点指向的索引文件。这个文件将包含至少一个,最多一个时间序列。对这些时间序列进行主存储器顺序扫描,得到近似的搜索结果
在(非常)罕见的情况下,不存在匹配的终端节点,这样的遍历将在内部节点失败。我们通过沿着树向下进行,选择最后一个分裂维度具有与查询时间序列匹配的iSAX值的节点,从而减轻不匹配的影响。如果在给定的连接处不存在这样的节点,我们只需选择第一个,并继续下降。
Exact Search
获取查询的最近邻居需要大量的计算和I/O。为了提高搜索速度,我们采用了近似搜索和较低的边界距离函数相结合的方法来减小搜索空间。获取最近邻的算法伪代码如表6所示。
获取查询的最近邻居需要大量的计算和I/O。为了提高搜索速度,我们采用了近似搜索和较低的边界距离函数相结合的方法来减小搜索空间。获取最近邻的算法伪代码如表6所示。
因为查询时间序列对我们来说是可用的,所以我们可以自由地使用它的PAA表示来获得两个iSAX单词之间比MINDIST更紧的边界。更具体地说,在查询时间序列的PAA表示和节点所占用SAX空间的iSAX表示之间,使用MINDIST_PAA_iSAX计算节点优先队列排序所用的距离。

EXPERIMENTS
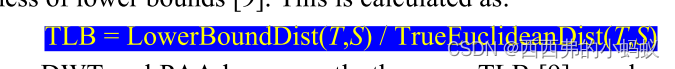
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









