






数据序列相似度搜索是与数据序列集合相关的多项分析任务和应用的核心和重要操作。尽管数据序列索引支持快速相似度搜索,但所有现有索引只能回答单一长度(在索引构建时固定)的查询,这是一个严重的限制。在这项工作中,我们提出了ULISSE,第一个数据序列索引结构,用于回答可变长度的相似度搜索查询。我们的贡献是双重的。首先,我们引入了一种新的表示方法,该方法可以有效且简洁地总结出不同长度的多个序列(不考虑z归一化)。基于所提出的索引,我们描述了近似和精确相似度搜索的有效算法,结合基于磁盘的索引访问和内存中顺序扫描。我们使用几个合成的和真实的数据集实验评估我们的方法。结果表明,与其他竞争方法相比,ULISSE在空间和时间成本方面的效率提高了几倍(最高可达数量级)。
背景:
它们受到不同的限制:要么只支持具有固定大小的查询的相似性搜索,要么不提供可伸缩的解决方案。对于固定长度的解决方案,要求在索引构建时选择这个长度(它应该与索引中序列的长度相同)。
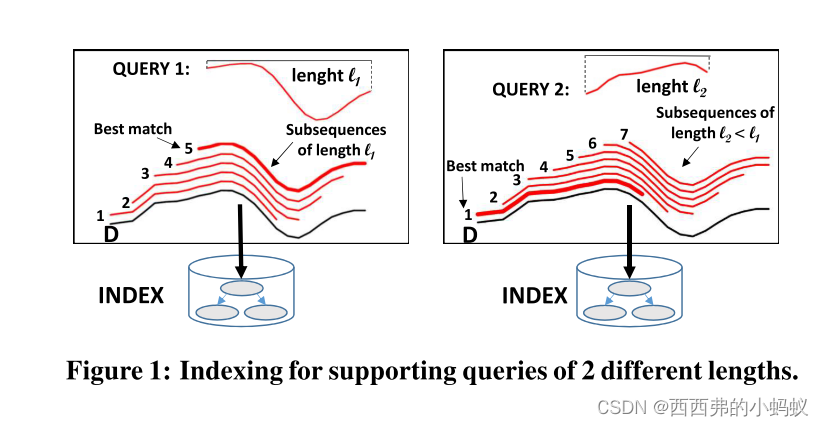
我们的贡献可以总结如下:(I)我们引入了可变长度子序列索引的问题,它需要可回答不同长度查询的单一索引。(II)我们提供了一种新的数据序列汇总技术,能够表示几个连续的不同长度的序列。该技术为所总结的序列生成了简洁的离散包络,可用于非z归一化和z归一化的数据序列。(III)基于这种摘要技术,我们开发了一种索引算法,该算法将序列及其离散摘要组织成一个层次树结构,即ULISSE索引。(IV)我们提出了高效精确和近似的K-NN算法,适用于ULISSE指数。(V)最后,利用合成数据集和真实数据集进行了实验评价。结果表明ULISSE对于其他方法无法处理的数据集大小的有效性和可伸缩性。
问题定义:



THE ULISSE FRAMEWORK
ULISSE方法的关键思想是对一系列集合的简洁summarization ,即重叠子序列
1)Representing Multiple Subsequences


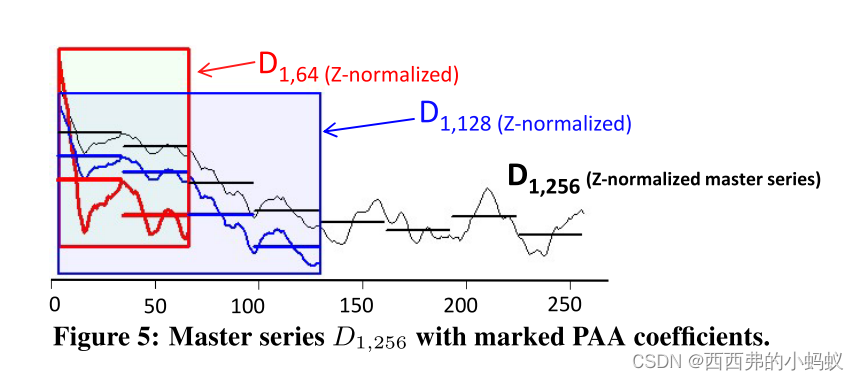
我们用L和U表示PAA系数,它们分别划定了一个围护区的上下部分
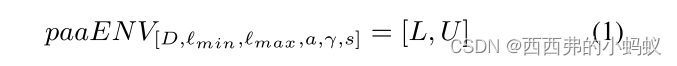
注意:master series的paaENV不应会包含所有PAA的系数,这部分证明跳过(参考论文中的调整方法)
2)Indexing the Envelopes
我们的目标是调整iSAX索引机制


图中显示了主序列的PAA系数计算。它们是通过从点a = 1开始的滑动窗口计算的,它在γ步骤之后停止。Note that the Envelope generates a containment area,
INDEXING ALGORITHM
1 )Non Z-Normalized Subsequences(跳过)

2)Z-Normalized Subsequences


Building the index
我们现在介绍这个算法,它在一个数据序列集合上构建ULISSE索引。我们维护iSAX索引的结构

每个ULISSE内部节点存储Envelope uENV,它表示根在该节点的子树中的所有序列。叶节点包含几个Envelope ,它们通过构造具有相同的iSAX(L)。相反,它们的iSAX(U)是不同的,因为它随着节点中的每一次新插入而更新
SIMILARITY SEARCH WITH ULISSE
1)Lower Bounding Euclidean Distance

EXPERIMENTAL EVALUATION


















 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









