







从患者的体检记录到物联网(IoT)设备的传感器维修记录等,都以大时间序列的形式留下数字痕迹。这些时间序列对象不仅跨越了非常长的时间周期(有时是几年),而且其特点是断断续续但相互关联的时间序列被长时间间隔打断。这种流行的数据类型,我们称之为时间序列复合对象(或TSC),在文献中很大程度上被忽略了。当管理、查询和分析这些大型TSC对象的存储库时,会出现独特的挑战。这包括具有时间错位弹性的适当的相似性语义、对过长和复杂对象的有效存储,以及tsc整体索引。我们证明,最先进的时间序列系统,虽然有效地索引和搜索常规的时间序列数据,但不能支持如此大的TSC数据。在这项工作中,我们介绍了第一个将TSC对象作为一等公民管理的全面解决方案。我们为TSCs引入了新的相似匹配语义和紧凑的错位弹性表示。
在此基础上,我们设计了一个支持tb级TSC数据集的可扩展存储、索引和查询的分布式索引基础设施Sloth。我们的实验研究表明,对于tb尺度的数据集,Sloth的查询响应时间比现有系统快了一个数量级,而对于近似kNN相似度匹配的查询结果,其平均精度(mAP)比现有解决方案的准确率提高了70%。
面临的挑战:
1)TSC-Aware Feature Representation Challenges。需要一种新的TSC感知特征表示,它捕获TSC语义,并在整个TSC对象(测量和差距)中保留特征的位置。
2)TSC-Aware Notions ofSimilarity Challenges
3)TSC-Aware Indexing Challenges 因此,我们必须开发能够感知tsc的索引,以满足按值匹配的双重要求

框架:
SLOTH: DISTRIBUTED INFRASTRUCTURE
TSCs are treated as first-class citizen throughout the infrastructure’s layers ground up starting from storage, indexing, to query processing.
1)TSC-Aware Feature Representation.
为了在TSC对象上有效地应用这种转换,我们需要解决两个主要问题。一是时间间隔,二是时间错位。
我们首先将TSC中的每个时间序列对象表示为一个单独的实例,同时保持它们的开始时间,从而保持间隙语义。然后,我们引入了一种新的tsc感知特征提取技术,显示弹性不同类型的错位
1.1)
作为第一步,我们在特征空间中设计了一种对错位不敏感而又不具有高损耗的表示。这种表示称为移位不敏感SAX直方图.这些无顺序的直方图并不能帮助我们解决在比较过程中哪些SAX片段应该被忽略

This led us to the proposed concept of Locality Preserving Vectorization.
我们提出的技术采用了一种有效的子向量表示结构,其中TS被划分为𝑆子向量,如图4 (b)所示。
Step 2: Shift-Insensitive SAX Histogram.
聚焦一个子向量,我们现在需要在特征空间中呈现它。我们新提出的“移位不敏感SAXHistogram”表示扩展了众所周知的SAX表示。字母表的大小可以是常量。它不受TS长度改变的影响,因此,我们可以用固定大小的字母频率向量来紧凑地表示时间序列,我们称之为移位不敏感SAXHistogram。
它不受TS长度改变的影响,因此,我们可以用固定大小的字母频率向量来紧凑地表示时间序列,我们称之为移位不敏感SAXHistogram。有了这个直方图表示,我们可以有任意多的段。
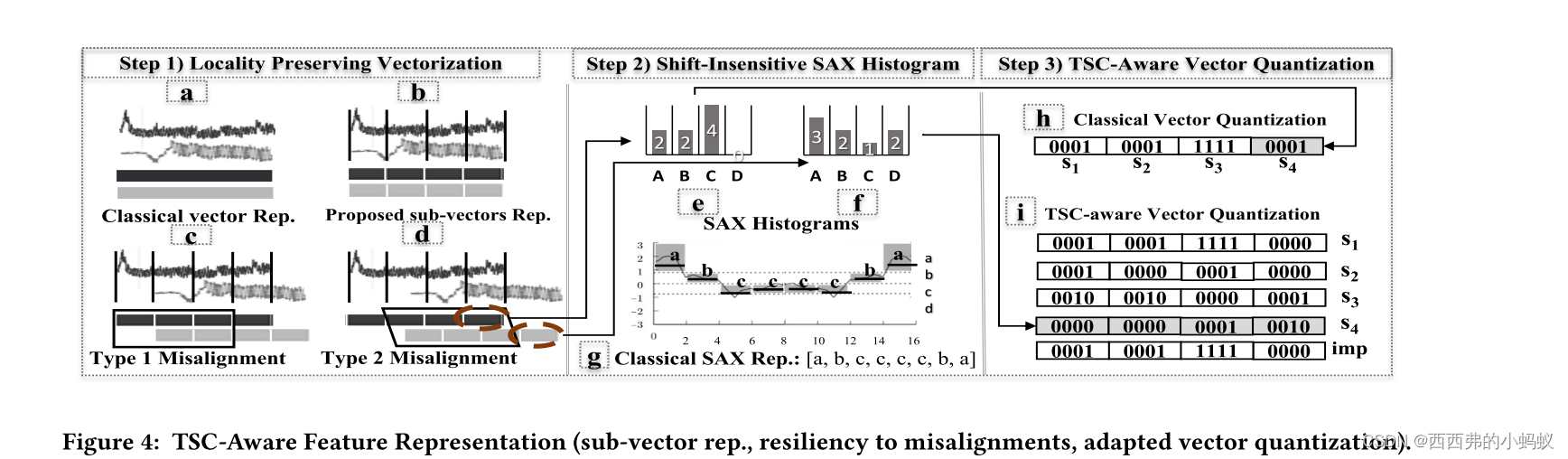
Step 3: TSC-Aware Vector Quantization
这一步的目标是进一步实现表示法的紧凑性。现在我们已经将TS对象转换为它们的子向量shift insensitive sax histograms,我们对它们应用矢量量化。
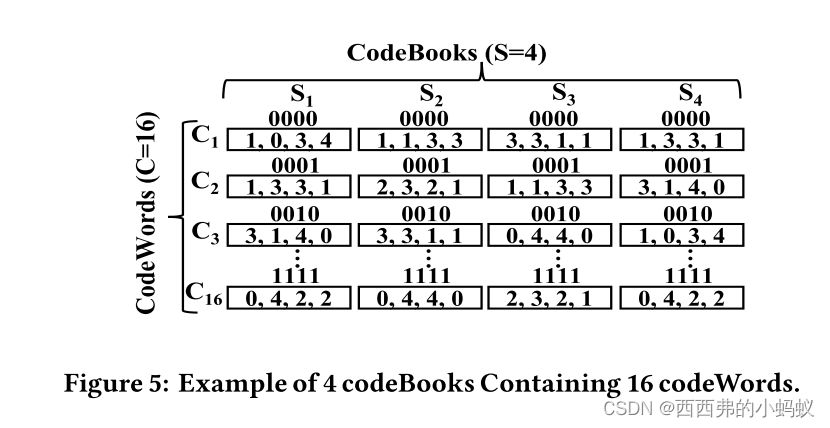

1.2) Proposed TSC-Aware Vector Quantization.
我们现在引入一种策略来适应标准vector quantization。 也就是说,我们不仅将TS对象的子向量映射到它们对应的codebook,而是将它们映射到所有的codebook as in Fig. 4 (i). 因此,数据库中的每个TS将用S表示为(S+1)的矩阵

Sloth Storage and Indexing Framework
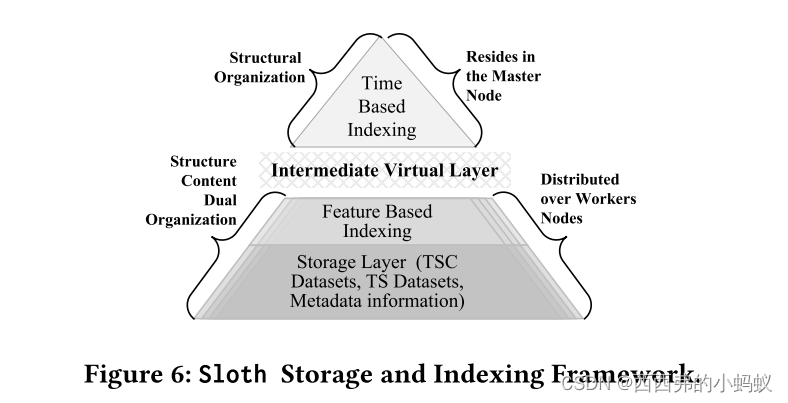
Sloth hybrid index infrastructure consists of two integrated layers. The top layer targets structure-oriented similarity of the whole compounds with regard to the time alignments. The bottom layer targets content-oriented similarity。底层还维护它们所属的TSC的元数据信息。这种混合结构能够同时基于时间和内容搜索TSC空间。它可以有效地支持相似性搜索操作符,例如kNN查询。
1)Top Layer: Structural Organization
这一层是基于时间的,在索引构建期间,它有助于在多个数据分区之间以基于时间的方式变换TSCs的TS对象。
Top Layer: (1) Preprocessing Phase
Top Layer: (2) Time-Based Structure Building 基于时间的结构有两个目标:(1)支持基于结构的相似性,(2)帮助基于时间的tsc数据集的TS对象聚类(即索引)。
Top Layer: (3) Piggybacked Quantization Phase 在使用上面介绍的时间结构对TS对象进行洗牌之前,我们使这个过程更加智能。我们创建矢量量化资源,从而能够将TS对象转换为它们的tsc感知特征表示
Bottom Layer: Structure-Content-Dual Organization.
Bottom Layer: (1) Data Re-Partitioning Phase. 这一步的目标是开始重新定位和调整TS对象,使其能够基于时间进行访问。
Bottom Layer: (2) Local Organization Phase. 在存储方面,这一层由数据分区组成,这些分区是原始TS的存储区域,它们支持tsc的特征表示,以及元数据信息
SLOTH: QUERY PROCESSING LAYER
我们提出了针对不同操作符类型的查询处理算法,重点关注kNN相似度搜索操作符。
Phase 1: Content-based filtering 首先,主服务器按如下方式识别数据分区并将其加载到工作内存中。Now, Sloth starts two level filtering at the bottom layer.
1)First, TS-level structure-based filtering
2)Second, the content-based filtering
Phase 2: TSC-Level filtering. 主节点使用第一层的时间结构进行检查,如果它们的分区还没有在worker的内存中,那么,它将加载它们。
EXPERIMENTAL EVALUATION




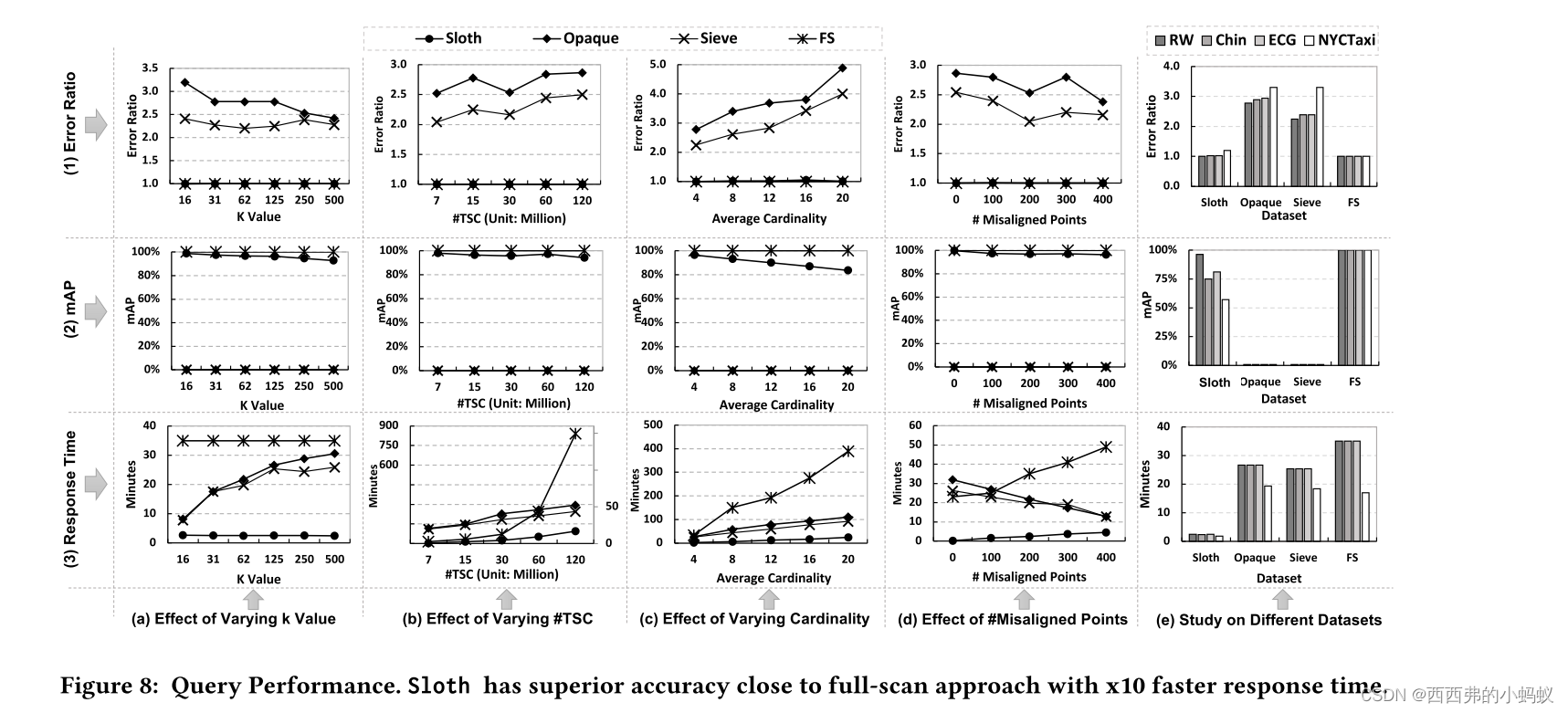

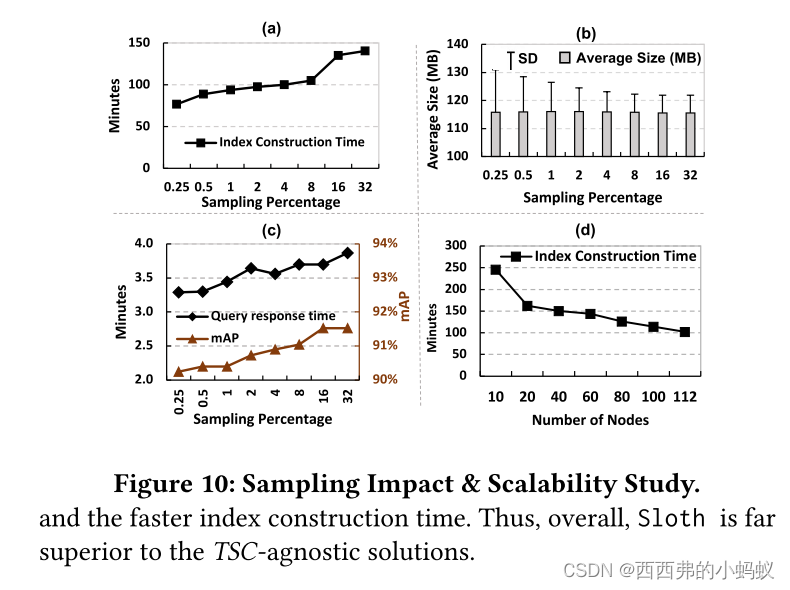
在这两种情况下,Sloth index construction时间都比基线快。之所以会出现这种情况,是因为基线不仅将TS对象转换为iSAX表示,而且还在每个数据分区的TS对象上构建一个树结构
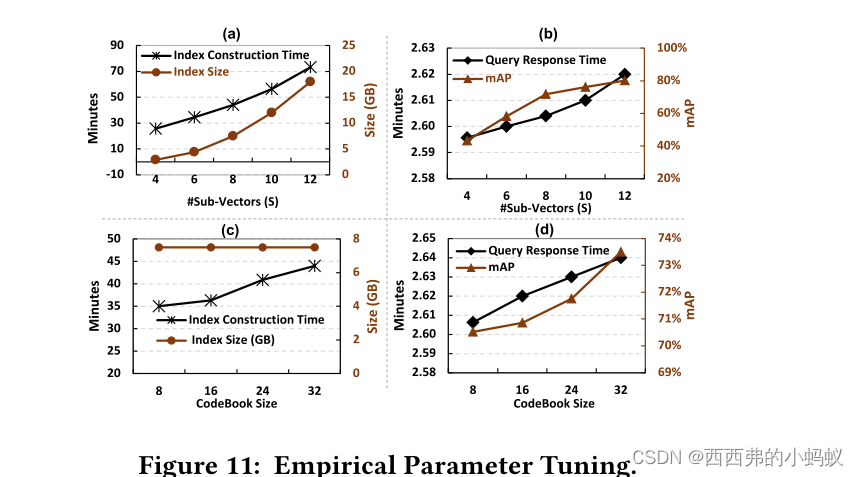
这是因为𝑆越大,我们在预处理阶段生成的codebook越多,量化期间的距离比较次数就越多。索引大小(图11 (a))也因为同样的原因而增加。从图11 (b)可以看出,增加S会略微增加秒级的响应时间。它还显示,mAP从40%提高到80%。从图11 (c)可以看出,由于量化距离比较次数的增加,增加codeBook的大小会对索引构建时间产生影响
总结:文中提出了一个分布式时间序列相似性查询框架。文中主要的创新点1)提出了使用Shift-Insensitive SAX Histogram 这种新的时间序列表征方法,2)提出使用codeBooke,它能够实现有效的表征压缩,但是实验中可以看出,codeBooks增加了距离计算的时间,导致在index创建需要更长的时间。3)文中提出的Sloth Storage and Indexing Framework,该分布式框架,新颖点不强。分布式架构本身就是master node 和slave node ,文中提出的两层结构中,down layer主要完成时间序列数据的slave node分布和管理每个节点上分布的时间序列提取的特征。top layer主要实现slave node选择和codeBooks转化。从这两层的功能上看,没有什么特别新颖的分布式结构。当然这种结构本身也是为了适应CodeBooks方式创建的。
总之,文中最大的新颖点时一种新的时间序列表征和codeBooks的应用。














 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









