






 本文介绍了如何使用ARIMA模型进行数据预处理,然后结合CNN和LSTM进行深度学习时间序列预测,提供了代码片段并展示了模型在生反池DO1数据上的应用,包括预测结果和评估指标如RMSE和R2。
本文介绍了如何使用ARIMA模型进行数据预处理,然后结合CNN和LSTM进行深度学习时间序列预测,提供了代码片段并展示了模型在生反池DO1数据上的应用,包括预测结果和评估指标如RMSE和R2。
整理了ARIMA-CNN-LSTM代码免费分享给大家。效果优异,记得点赞哦~~~
# 帅帅的笔者
# coding: utf-8
import time
time_start = time.time()
import itertools
import sys
import math
import numpy as np
import pandas as pd
from numpy import concatenate
from pandas import concat, DataFrame
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from keras.layers import Dense, Flatten, RepeatVector
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import GRU
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers import Dropout
from statsmodels.tsa.arima_model import ARIMA
import tensorflow as tf
import statsmodels.api as sm
from keras.layers import TimeDistributed
import matplotlib
import warnings
import statsmodels
from scipy import stats
# 调用GPU加速
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
#读入数据
data_raw = pd.read_csv('shao - 单.csv', usecols=[0, 1])
features=['生反池DO1']
data_raw=data_raw[features]
p_min = 0
p_max = 5
d_min = 0
d_max = 2
q_min = 0
q_max = 5
train_results = sm.tsa.arma_order_select_ic(data_raw, ic=['aic', 'bic'], trend='c', max_ar=p_max, max_ma=q_max)
print('AIC', train_results.aic_min_order)
print('BIC', train_results.bic_min_order)
model = statsmodels.tsa.arima.model.ARIMA(data_raw, order=(3, 2, 1))
fit = model.fit()
preds = fit.predict(1,len(data_raw), typ='levels')
preds_pd = preds.to_frame()
preds_pd.index -= 1
arima_result = pd.DataFrame(columns=['生反池DO1'])
arima_result['生反池DO1'] = data_raw['生反池DO1']
arima_result['predicted'] = preds_pd
arima_result['residuals'] = arima_result['生反池DO1'] - arima_result['predicted']
new_data = arima_result
lstm_data = new_data['residuals'][:].values.astype(float)
def series_to_supervised(data, n_in, n_out, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
agg = concat(cols, axis=1)
agg.columns = names
if dropnan:
agg.dropna(inplace=True)
return agg
#生成LSTM所需要的3维数据格式,(样本数,时间步长,特征数)
def dataprepare(values,timestep):
reframed = series_to_supervised(values,timestep, 1)#X,y
values = reframed.values
#划分训练集和测试集
train = values[1:train_len, :]
test = values[train_len:, :]
#得到对应的X和label(即y)
train_X, train_y = train[:, :-1], train[:, -1]
test_X, test_y = test[:, :-1], test[:, -1]
# 把输入重塑成3D格式 [样例,时间步, 特征]
train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1]))
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
print("train_X.shape:%s train_y.shape:%s test_X.shape:%s test_y.shape:%s" % (
train_X.shape, train_y.shape, test_X.shape, test_y.shape))
return train_X,train_y,test_X,test_y
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler_data = scaler.fit_transform(lstm_data.reshape(-1, 1))
train_len = int(len(data_raw) * 0.80)
test_len=len(data_raw)-train_len
print(train_len)
timestep = 13 #滑动窗口
x_train, y_train, x_test, y_test = dataprepare(scaler_data,timestep)
#打印数据形式
print('x_train.shape = ', x_train.shape)
print('y_train.shape = ', y_train.shape)
print('x_test.shape = ', x_test.shape)
print('y_test.shape = ', y_test.shape)
#网络模型
model = Sequential()
model.add(Conv1D(filters=16,kernel_size=2, padding='same', strides=1, activation='relu',input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(MaxPooling1D(pool_size=1))
model.add(Conv1D(filters=16,kernel_size=2, padding='same', strides=1, activation='relu',input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(MaxPooling1D(pool_size=1))
model.add(Flatten())
model.add(RepeatVector(150))
model.add(LSTM(50, input_shape=(x_train.shape[1], x_train.shape[2]),activation='tanh',return_sequences=True))
model.add(LSTM(100, input_shape=(x_train.shape[1], x_train.shape[2]),activation='tanh',return_sequences=True))
model.add(LSTM(250,activation='tanh',return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.summary()
len(model.layers)
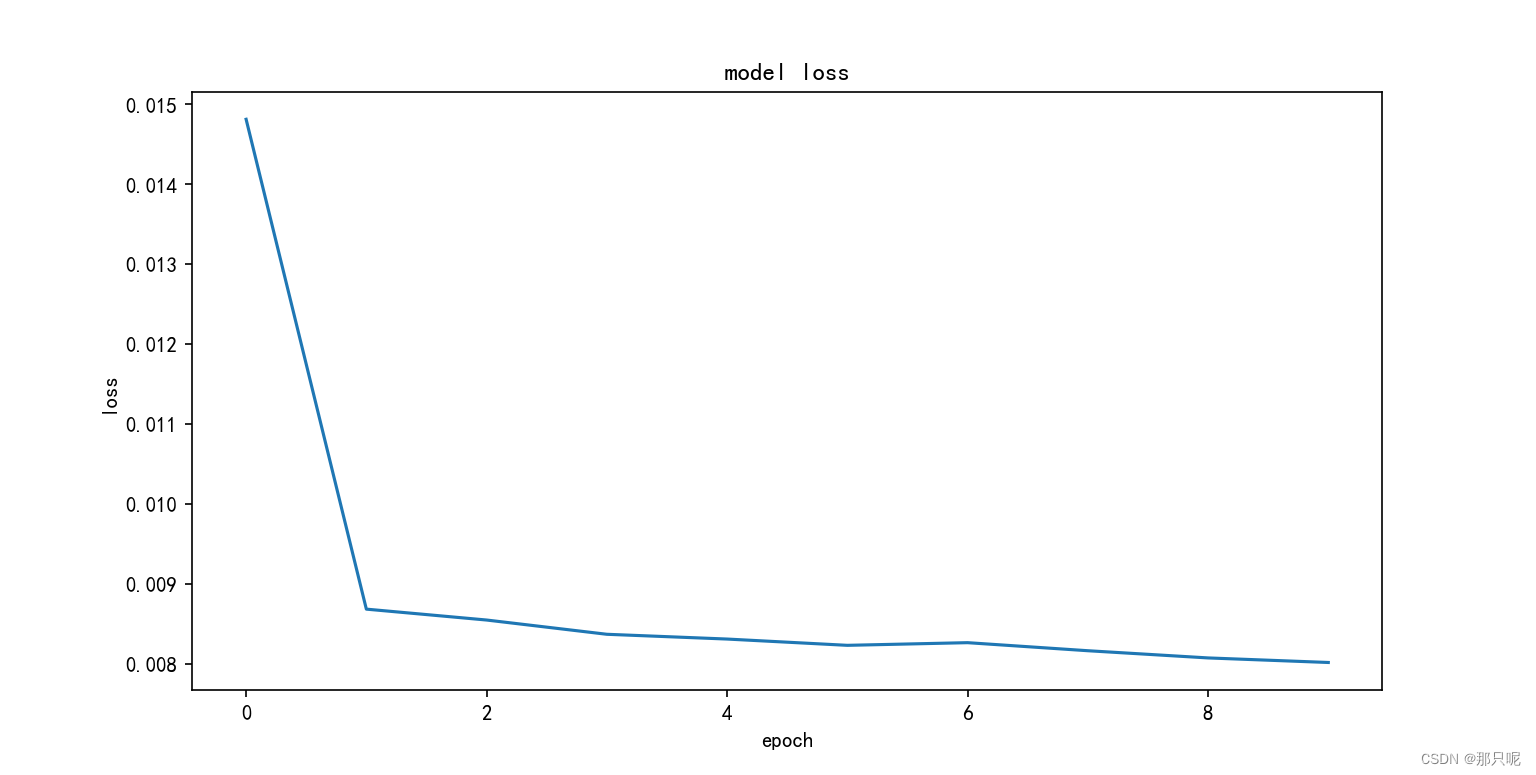
history = model.fit(x_train, y_train, epochs=10, batch_size=64, callbacks=None, validation_split=None,validation_data=None, shuffle=False, verbose=2)
plt.figure(figsize=(9, 2),dpi=150)
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
score2 = model.evaluate(x_train, y_train)
print(score2)
y_test_pred = model.predict(x_test)
#对x_test进行反归一化
test_X = x_test.reshape((x_test.shape[0], x_test.shape[2]))
y_test_pred = concatenate((y_test_pred, test_X[:, 1:]), axis=1)
y_test_pred = scaler.inverse_transform(y_test_pred)
y_test_pred = y_test_pred[:, 0]
y_testy = y_test.reshape((len(y_test), 1))
y_testy = concatenate((y_testy, test_X[:, 1:]), axis=1)
y_testy = scaler.inverse_transform(y_testy)
y_testy = y_testy[:, 0]
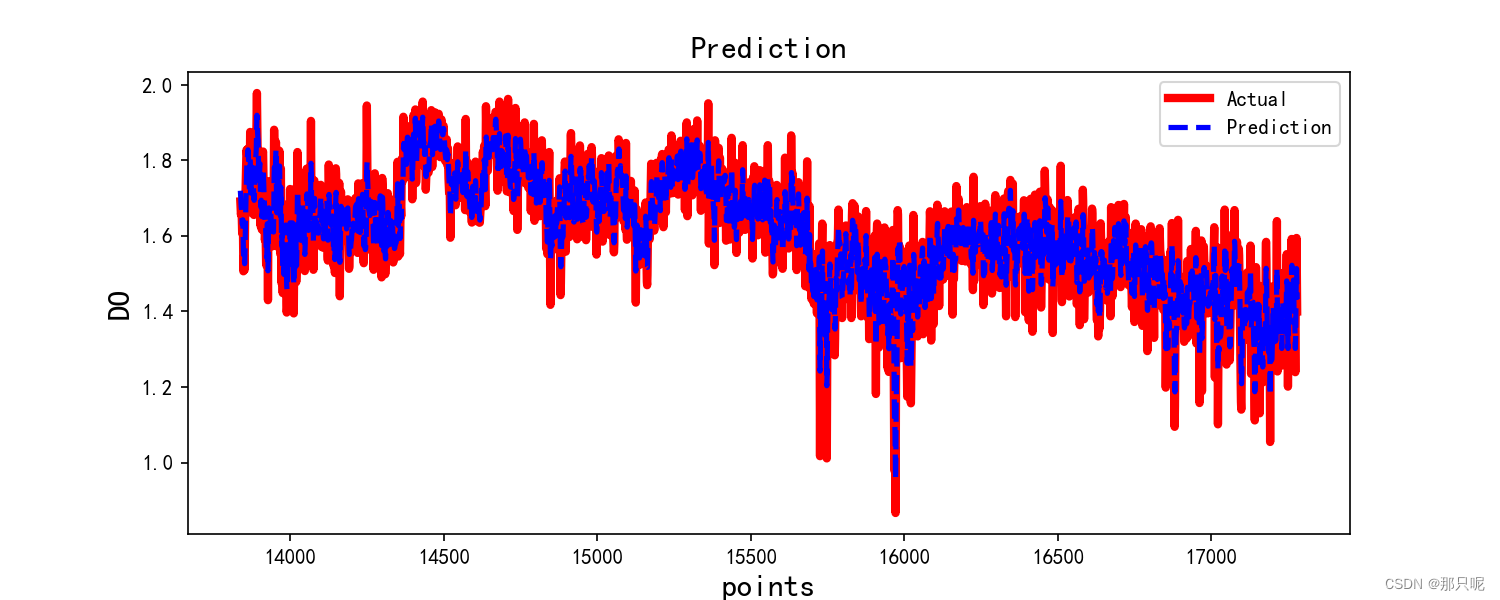
testScore = r2_score(y_testy, y_test_pred)
print('Train Sccore %.4f R2' %(testScore))
train_data, test_data = data_raw[0:int(len(data_raw)*0.8)+timestep], data_raw[int(len(data_raw)*0.8)+timestep:]
draw_test = new_data['predicted'][-len(y_test_pred):].values.astype(float)+y_test_pred
draw_test=draw_test.reshape(-1,1)
testScore = math.sqrt(mean_squared_error(test_data, draw_test))
print('Train Sccore %.4f RMSE' %(testScore))
testScore = mean_absolute_error(test_data, draw_test)
print('Train Sccore %.4f MAE' %(testScore))
testScore = r2_score(test_data, draw_test)
print('Train Sccore %.4f R2' %(testScore))
plt.figure(figsize=(10, 4),dpi=150)
plt.plot(test_data, label="Actual", color='red',linewidth=4)
plt.plot(range(len(x_train)+timestep+1,len(new_data)),draw_test, color='blue',label='Prediction',linewidth=2.5,linestyle="--")
plt.title('Prediction', size=15)
plt.ylabel('DO',size=15)
plt.xlabel('points',size=15)
plt.legend()
plt.show()
time_end = time.time()
time_sum = time_end - time_start
print(time_sum)
更多55+时间序列预测python代码领取:时间序列预测算法全集合--深度学习















 2697
2697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









