







基于GRU的时间序列预测模型python代码分享给大家,记得点赞哦

#!/usr/bin/env python
# coding: utf-8
import time
time_start = time.time()
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, GRU
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
from keras import optimizers
from pylab import *
import tensorflow as tf
mpl.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False
# 调用GPU加速
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
def creat_dataset(dataset, look_back=10):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i: (i+look_back)]
dataX.append(a)
dataY.append(dataset[i+look_back])
return np.array(dataX), np.array(dataY)
dataframe = pd.read_csv('天气.csv',header=0, parse_dates=[0],index_col=0, usecols=[0, 1])#header=0第0行为表头,index_col=0第一列为索引,usecols=[0, 1]选取第一列和第二列
dataset = dataframe.values
dataframe.head(10)
plt.figure(figsize=(10, 4),dpi=150)
dataframe.plot()
plt.ylabel('AQI')
plt.xlabel('time/day')
font = {'serif': 'Times New Roman','size': 20}
plt.rc('font', **font)
plt.show()
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset.reshape(-1, 1))
train_size = int(len(dataset)*0.8)
test_size = len(dataset)-train_size
train, test = dataset[0: train_size], dataset[train_size: len(dataset)]
look_back = 10
trainX, trainY = creat_dataset(train, look_back)
testX, testY = creat_dataset(test, look_back)
model = Sequential()
model.add(GRU(input_dim=1, units=50, return_sequences=True))
model.add(GRU(input_dim=50, units=100, return_sequences=True))
model.add(GRU(input_dim=100, units=200, return_sequences=True))
model.add(GRU(300, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(100))
model.add(Dense(units=1))
model.add(Activation('relu'))
start = time.time()
model.compile(loss='mean_squared_error', optimizer='Adam')
model.summary()
len(model.layers)
history = model.fit(trainX, trainY, batch_size=64, epochs=100, validation_split=None, verbose=2)
print('compilatiom time:', time.time()-start)
#get_ipython().run_line_magic('matplotlib', 'notebook')
fig1 = plt.figure(figsize=(10, 3),dpi=150)
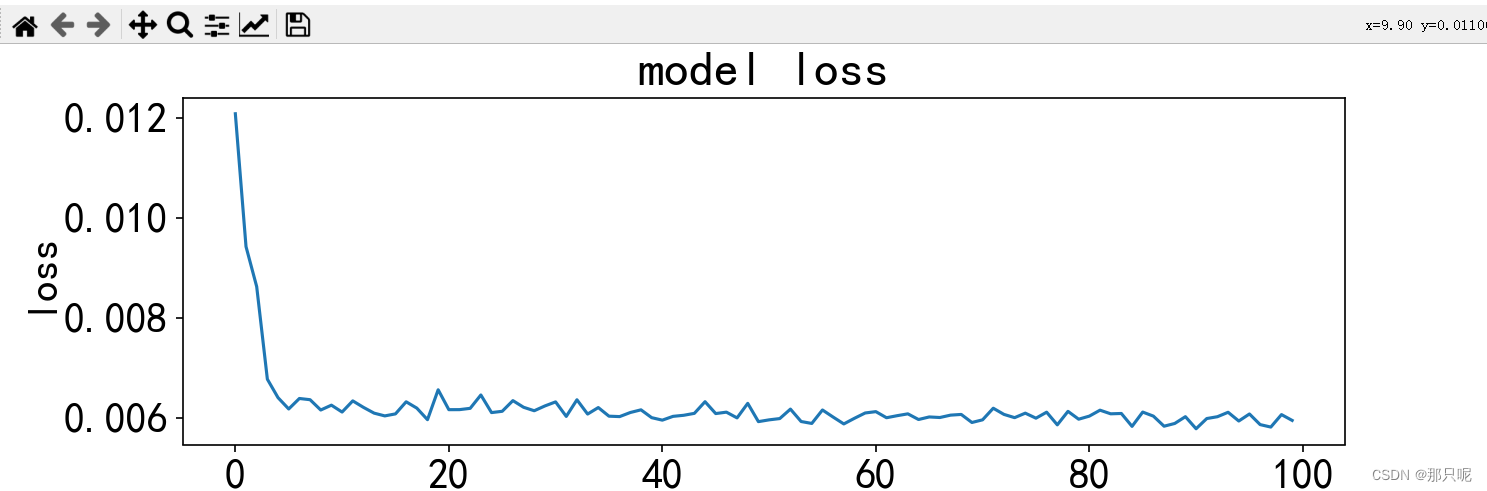
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)
testScore = math.sqrt(mean_squared_error(testY, testPredict[:, 0]))
print('Train Sccore %.4f RMSE' %(testScore))
testScore = mean_absolute_error(testY, testPredict[:, 0])
print('Train Sccore %.4f MAE' %(testScore))
testScore = r2_score(testY, testPredict[:, 0])
print('Train Sccore %.4f R2' %(testScore))
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:] = np.nan
trainPredictPlot = np.reshape(trainPredictPlot, (dataset.shape[0], 1))
trainPredictPlot[look_back: len(trainPredict)+look_back, :] = trainPredict
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:] = np.nan
testPredictPlot = np.reshape(testPredictPlot, (dataset.shape[0], 1))
testPredictPlot[len(trainPredict)+(look_back*2)+1: len(dataset)-1, :] = testPredict
dataset = scaler.inverse_transform(dataset)
#get_ipython().run_line_magic('matplotlib', 'notebook')
plt.figure(figsize=(10, 4),dpi=150)
plt.title(' Prediction',size=15)
plt.plot(dataset, color='red', linewidth=1.5, linestyle="-",label='Actual')
plt.plot(testPredictPlot, color='blue',linewidth=2,linestyle="--", label='Prediction')
plt.legend()
plt.ylabel('AQI',size=15)
plt.xlabel('time/day',size=15)
plt.show()
time_end = time.time()
time_sum = time_end - time_start
print(time_sum)
更多时间序列预测代码获取:时间序列预测算法全集合--深度学习















 4644
4644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









