







一、什么是词向量
词向量最初是用one-hot represention表征的,也就是向量中每一个元素都关联着词库中的一个单词,指定词的向量表示为:其在向量中对应的元素设置为1,其他的元素设置为0。采用这种表示无法对词向量做比较,后来就出现了分布式表征。
在word2vec中就是采用分布式表征,在向量维数比较大的情况下,每一个词都可以用元素的分布式权重来表示,因此,向量的每一维都表示一个特征向量,作用于所有的单词,而不是简单的元素和值之间的一一映射。这种方式抽象的表示了一个词的“意义”。
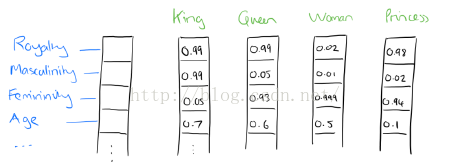
二、词向量推理
实际上,被学习的词向量表示是用一种非常简单的方式捕捉有意义的语法和语义规律。具体来说,对于一个特定关系的词组,语法规律可以看作固定的向量偏移。
三、学习词向量
word2vec的两种形式:CBOW和Skip-gram模型
(1)CBOW
CBOW去除了上下文各词的词序信息,使用上下文各词的平均值。
例如一段散文“The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precises syntatic and semantic word relationships.”,想象这段文字上有一个滑动窗口,包括当前的词和前后的四个词。具体如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8917
8917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









