







EM算法也称期望-最大值算法,是很多机器学习领域算法的基础。最近使用MATLAB软件工具箱CCToolbox进行气旋轨迹聚类,聚类速度很快,效果也很好。所以试图想了解清楚这算法背后的机理。在这里我试着写下一点对EM算法的理解。
EM算法最重要的是确定隐藏变量Z,样本X,以及概率空间θ在实际问题中的具体意义。EM算法主要分为两步,分别为E-step和M-step。E-step主要用于隐藏变量Z的概率值,M-step是使用极大似然法对L(θ)求极大值。通过假设θ的初始值,循环E-step和M-step,值到L(θ)值趋于收敛。
下面主要介绍一下E-step和M-step概率公式所代表的实际意义,以轨迹分类作为示例。;
首先是E-step,E-step主要是确定P(z|x;θ)的大小。下面这个公式是P(z|x;θ)的变形。xi是时间自变量,yi是轨迹距离应变量,可以表示经向或纬向移动距离,k表示类别。αk表示轨迹yi选择类k的概率。我们假设属于类k的轨迹服从高斯分布,pk(yi|xi)当轨迹yi属于类别k时的概率。
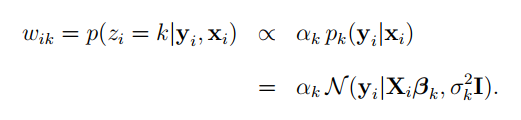
接着是M-step。确定L(θ)的大小。即Q函数的计算公式。下述的Q函数是采用Jensen不等式简化后的一个最终结果。其中wik就是E-step中隐含变量k的估计值。将Q函数中所涉及的θ空间变量求偏导,即使用极大似然法进行估计。
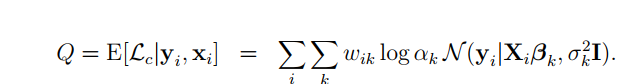
我对cctoolbox工具箱的colorplot进行改进,已放置资源中,有需要的童鞋直接下载即可,无需积分扣除。
引用:
1、https://www.cnblogs.com/pinard/p/6912636.html
2、https://blog.csdn.net/zhihua_oba/article/details/73776553
3、https://wenku.baidu.com/view/3396bb4d6294dd88d0d26bee.html
4、https://www.cnblogs.com/hapjin/p/6623795.html
5、cctoolbox手册,可以看这篇博士论文"Probabilistic Curve-Aligned Clustering and Prediction with Regression Mixture Models"















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









