






1.文章信息
本周阅读的论文是题目为《Multilevel Wavelet Decomposition Network for Interpretable Time Series Analysis》的一篇2018年发表在《Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining》上的涉及时间序列数据预测的文章。
2.摘要
近年来,时间序列应用在几乎所有的学术和工业领域都出现了前所未有的崛起。各种类型的深度神经网络模型被引入到时间序列分析中,但对重要的频率信息还缺乏有效的建模。基于此,文章提出了一种基于小波的神经网络结构,称为多级小波分解网络( multilevel Wavelet Decomposition network, mWDN ),用于建立时间序列分析的频率感知深度学习模型。mWDN模型保留了多级离散小波分解在连续学习中的优势,同时可以在深度神经网络框架下对所有参数进行调整。在mWDN的基础上,进一步提出了两种用于时间序列分类和预测的深度学习模型:残差分类( Residual Classification Flow, RCF )和多频长短时记忆( multi-frequency Long Short-Term Memory, mLSTM )。这两种模型以不同频率的mWDN分解的全部或部分子序列作为输入,通过反向传播算法在全局学习所有的参数,使得基于小波的频率分析能够无缝嵌入到深度学习框架中。在40个UCR数据集和真实用户量数据集上的大量实验表明,基于mWDN的时间序列模型具有良好的性能。特别的,文章提出的一种基于mWDN模型的重要性分析方法,该方法成功地识别出了对时间序列分析至关重要的时间序列元素和mWDN层。这实际上说明了mWDN的可解释性优势,可以看作是对可解释性深度学习的一次深入探索。
3.介绍
近年来,伴随着深度学习领域的飞速发展,不同类型的深度神经网络模型被应用于时间序列处理分析方面并在实际生活中取得了满意的效果,例如循环神经网络(RNN),使用记忆节点来捕捉序列节点的相关性,但大部分的这些模型都没有利用时间序列的频率信息。
小波分解是一种在时域和频域上刻画时间序列特征的常用方法。只管来说,可以将它作为特征提取工具,用于深度模型建模前的数据预处理。虽然这种松散的耦合方式可能会提高原始神经网络模型的预测性能,但没有采用独立的参数推理过程进行全局优化。如何将小波分解整合到深度学习模型中仍然具有挑战性。
这篇文章提出了一个基于小波分解的神经网络模型,叫做多级小波分解网络(mWDN),为时间序列分析搭建了频率感知的深度学习模型。与标准的多级离散小波分解模型(MDWD)相似,mWDN模型可以将一个时间序列分解为一组频率由高到低的子序列,这是模型获得频率因子的关键。但与参数固定的MDWD模型不同,mWDN中的所有参数都可以进行学习,以适应不同学习任务的训练数据。也就是说,mWDN模型既可以利用小波分解对时间序列进行分析,又可以利用深度神经网络的学习能力学习参数。
基于mWDN,文章设计了两种分别用于时间序列分类(TSC)和时间序列预测(TSF)的深度学习模型,即Residual Classification Flow(RCF)和multi-frequency Long Short-Term Memory(mLSTM)。其中TSC的关键问题是从时间序列数据中尽可能提取代表性特征,因此RCF模型采用mWDN不同层级的分解结果作为输入,采用残差学习方法和分类器堆栈的方式挖掘隐藏在子序列中的特征。至于TSF问题,其关键在于根据不同频率下的隐藏趋势推断时间序列数据的未来状态。因此,mLSTM模型将所有由mWDN分解得到的高频子序列数据分别放入独立的LSTM模型中,并将所有LSTM模型的输出进行整合进行最终预测。值得注意的是RCF和mLSTM模型的所有参数,包括mWDN的参数都是使用端对端的反向传播算法进行训练的。通过这种方式,基于小波的频率分析可以无缝的嵌入到深度学习模型中。
4.模型
1. Multi-level Discrete Wavelet Decomposition
多级离散小波分解(如图1)是一种基于小波变换的离散信号分析方法,该方法通过对时间序列进行分解,将时间序列逐级分为低频和高频子序列,从而提取多级时间-频率特征。
以时间序列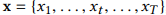 为例,分解得到的第i层的低频和高频子序列分别以
为例,分解得到的第i层的低频和高频子序列分别以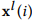 和
和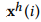 表示。在第i+1层,MDWD使用一个低频滤波和一个高频滤波,对上一层的低频子序列进行卷积操作,如下所示:
表示。在第i+1层,MDWD使用一个低频滤波和一个高频滤波,对上一层的低频子序列进行卷积操作,如下所示:
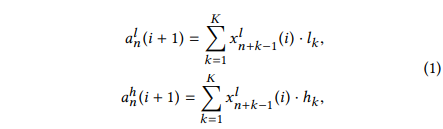
其中,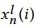 表示第i层中低频率子序列的第n个元素,并且
表示第i层中低频率子序列的第n个元素,并且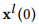 被设置为输入的序列。第i层的低频和高频子序列
被设置为输入的序列。第i层的低频和高频子序列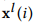 和
和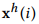 是由中间变量序列
是由中间变量序列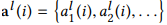 和
和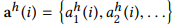 进行二分之一的下采样获得。
进行二分之一的下采样获得。
子序列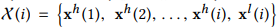 被成为时间序列数据X的第i层分解结果。特别的,该序列满足:1)可以由子序列完整重建原始序列X;2)不同层级的序列具有不同的时间和频率分辨率。随着层级的增加,频率分辨率不断增加,而时间分辨率,特别是低频子序列的时间分辨率不断减小。
被成为时间序列数据X的第i层分解结果。特别的,该序列满足:1)可以由子序列完整重建原始序列X;2)不同层级的序列具有不同的时间和频率分辨率。随着层级的增加,频率分辨率不断增加,而时间分辨率,特别是低频子序列的时间分辨率不断减小。
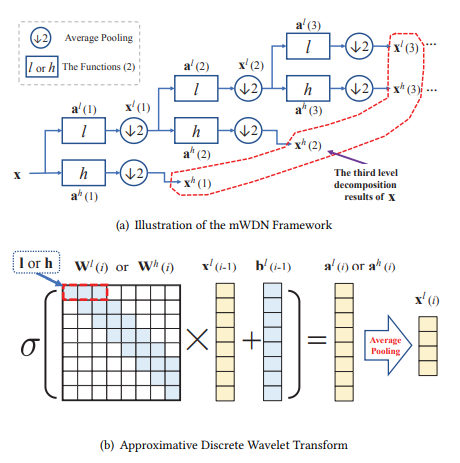
图1 mWDN模型框架
2. Multi-level Wavelet Decomposition Network
图一为mWDN模型的构架图。正如图片中所示,mWDN模型依照以下两个公式分层次分解时间序列数据:
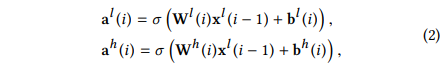
表示sigmoid激活函数,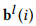 和
和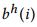 分别是可训练的偏差矩阵,其初始为接近零的随机数值。可以看出来,公式(2)中的方程与公式(1)中的方程非常相似。
分别是可训练的偏差矩阵,其初始为接近零的随机数值。可以看出来,公式(2)中的方程与公式(1)中的方程非常相似。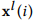 和
和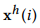 分别表示时间序列X在第i层级分解生成的低频和高频子序列,这是由中间变量
分别表示时间序列X在第i层级分解生成的低频和高频子序列,这是由中间变量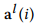 和
和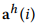 通过平均池化
通过平均池化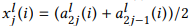 进行下采样所获得。为了实现公式(1)的卷积操作,我们设置了初始化的权重矩阵和如下:
进行下采样所获得。为了实现公式(1)的卷积操作,我们设置了初始化的权重矩阵和如下:

很明显的,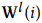 和
和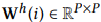 ,其中P是
,其中P是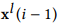 的尺寸大小。权重矩阵中的是满足
的尺寸大小。权重矩阵中的是满足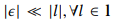 和
和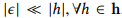 的随机值。文章在模型中使用Daubechies 4 小波系数,其滤波器系数如下:
的随机值。文章在模型中使用Daubechies 4 小波系数,其滤波器系数如下:

由公式(2)到公式(3),文章使用深度神经网络框架实现近似的MDWD模型。值得注意的,虽然权重矩阵初始化为MDWD模型的滤波器系数,但仍然可以根据真实数据的扰动对矩阵进行训练。
3. Residual Classification Flow
TRC任务主要是对未知类别标签的时间序列进行预测分类。其关键是从时间序列数据中提取出明显的特征。由mWDN模型分解得到的自然时间频率特征X可以应用到TSC。在该部分,文章提出了Residual Classification Flow(RCF)网络去挖掘mWDN在TSC任务中的潜在应用。
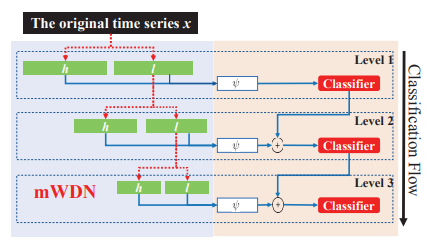
图2 RCF模型框架
RCF模型的框架如图2所示,包含了许多独立的分类器。RCF模型通过前向神经网络将第i层mWDN生成的子序列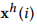 和
和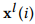 连接在一起:
连接在一起:
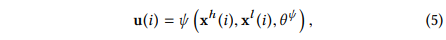
可以表示为一个多层感知机,或者一个卷积神经网络,又或者其他类型的神经网络,并且代表可训练参数。另外,RCF模型采用了残差网络结构将和所有分类器进行连接:
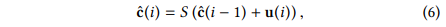
表示softmax分类器,表示时间序列的类别标签的one-hot编码预测值。RCF模型对各层级mWDN的分解结果 进行演化。因为在不同mWDN层级的分解结果有不同的时间和频率分辨率,所以RCF模型可以充分捕捉不同时间和频率分辨率的输入时间序列的模式。换句话说,RCF采用了一种多视图学习方法来实现高性能的时间序列分类。此外,深度残差网络被提出来以解决在使用更深层次的网络结构可能导致训练困难的问题。RCF也继承了这个优点。在式(6)中,第i层级的分类器基于和第i-1层级分类器的决策做出决策。因此,用户可以追加残差分类器直到模型的分类性能不再提高。
进行演化。因为在不同mWDN层级的分解结果有不同的时间和频率分辨率,所以RCF模型可以充分捕捉不同时间和频率分辨率的输入时间序列的模式。换句话说,RCF采用了一种多视图学习方法来实现高性能的时间序列分类。此外,深度残差网络被提出来以解决在使用更深层次的网络结构可能导致训练困难的问题。RCF也继承了这个优点。在式(6)中,第i层级的分类器基于和第i-1层级分类器的决策做出决策。因此,用户可以追加残差分类器直到模型的分类性能不再提高。
4. Multi-frequency Long Short-Term Memory
文章提出了基于mWDN多频率的长短时记忆神经网络解决TSF问题。mLSTM模型的设计是基于对时间序列中隐藏节点的时间相关性与频率密切相关的认知。例如,大尺度的时间相关性,如长时趋势通常处于低频,而小尺度的时间相关性,如短期干扰和事件则通常处于高频。因此文章把复杂的TSF问题划分成许多子问题来预测由mWDN分解得到的子序列,这将会使问题相对更简单,因为子序列的频率组成更加简化。给定一个无限长度的时间序列,在该序列上给出一个从过去到时刻t且大小为T的滑动窗口如下:
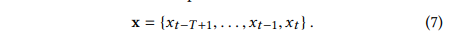
使用mWDN分解X从而获得第i层级的低频和高频序列数据如下:
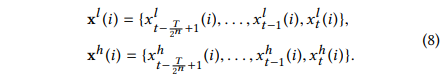
如图3所示,mLSTM模型使用最后一层的分解结果,作为N+1个独立的LSTM子网络的输入。每个子LSTM网络预测中每个子序列的未来状态。最后,通过一个全连接神经网络将各个子LSTM网络的预测值融合在一起得到最终预测结果。
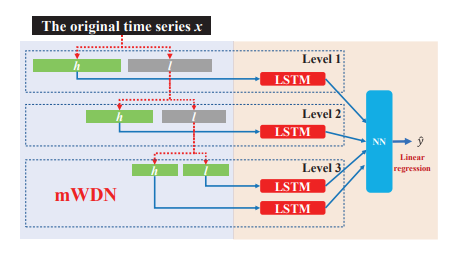
图3 mLSTM框架
5.案例研究
在这部分,文章评估了基于mWDN的模型在解决TSC和TSF问题时的性能。
1. Task 1: Time Series Classification
实验设置:在UCR时间序列库的40个数据集上,对不同的模型的分类性能进行了测试,主要模型如下:
RNN和LSTM:循环神经网络和长短时记忆神经网络是两种经典的深度神经网络模型,广泛应用于时间序列分析。
MLP, FCN, and ResNet:这三种模型被提出作为强有力的baselines用于UCR时间序列库。他们有相同的框架:一层输入层,紧接着三个隐藏偏差块,最后以一个softmax激活函数作为输出层。MLP采用一个全连接层作为它的偏差块,FCN和ResNet则分别采用一个卷积层和残差卷积网络作为它们的偏差块。
MLP-RCF, FCN-RCF and ResNet-RCF:这三个模型使用MLP/FCN/ResNet的偏差块作为公式(5)RCF模型中的。我们比较了RCF模型和MLP/FCN/ResNet的分类效果以验证RCF的有效性。
Wavelet-RCF:该模型与ResNet-RCF模型有着相同的结果,但使用mWDN部分替换了使用固定参数的标准MDWD。我们比较了它和ResNet-RCF模型以验证mWDM中可训练参数的有效性。
对于每个数据集来说,我们每个模型都跑了十次,将返回的平均分类误差作为评价指标。为了比较所有数据集上的表现性能,文章进一步提出了Mean Per-Class Error(MPCE)作为每个模型的评价指标。令为第k个数据集的类别数,表示每个模型在该数据集上的错误率,则每个模型的MPCE计算如下所示:
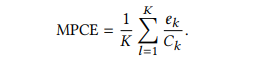
注意,类别数量的因子在MPCE中被抹去。MPCE其取值越小,整体性能越好。
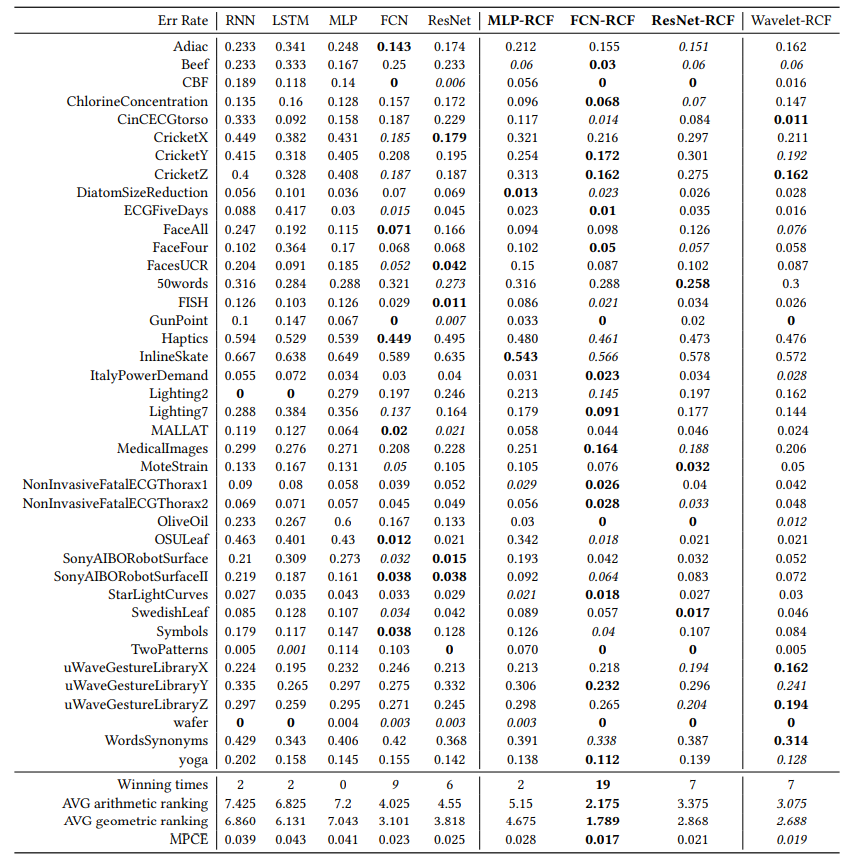
结果&分析:表1展示了实验结果,总结信息列在了下面两行。注意,每个数据集中最好的表现用黑体加粗表示出来,第二好的则用斜体表示出来。在所有baselines中,FCN-RCF取得了最棒的表现,有最小的MACE值,并且在40个数据集中取得了19个数据集的最好表现。而FCN也取得了比较满意的表现,其在9个数据集上的表现最优,并且有比较小的MPCE:0.023,但与FCM-RCF的差距还是比较大。由表格1还可以看出,MLP-RCF在37个数据集上的表现都要优于MLP,ResNet-RCF在27个数据集上的表现要优于ResNet。这表明RCF框架确实是一个可以兼容不同类型深度学习分类器的通用框架,能够显著提升TSC任务的分类性能。
另外,表格1表明Wavelet-RCF在MPCE和AVG排名上取得了第二好的表现性能,这说明由小波分解得到的频率信息对时间序列问题非常有帮助。另外,从表中可以清楚看出ResNet-RCF模型在大多数据集上的性能优于Wavelet-RCF,这有力的证明了我们的RCF框架在深度学习下采用参数可训练的mWDN,而不直接使用传统的小波分解作为特征提取工具的优势。从技术上更准确的讲,与Wavelet-RCF相比,基于mWND的ResNet-RCF模型可以在频域先验和训练数据可能性间取得一个较好的权衡。这也很好解释了为什么基于RCF的模型可以取得更好的预测结果在先前的实验观察中。
表1 Comparison of Classification Performance on 40 UCR Time Series Datasets
2. TaskⅡ: Time Series Forecasting
实验设置:文章测试了mLSTM模型对一个访问量预测场景的预测能力。实验采用了一个名为WuxiCellPhone的真实数据集,该数据集包含了位于无锡市中心的20个手机基站在两周内的用户量时间序列数据,用户量时间序列的统计时间粒度是5min。该实验,选择了以下的模型作为baselines:
SAE (Stacked Auto-Encoders),被广泛应用于各种TSF任务中;
RNN (Recurrent Neural Networks) 和 LSTM (Long Short-Term Memory),专门为时间序列分析所提出的模型;
wLSTM,与mLSTM有相同的结构,但将mWDM部分替换成标准的MDWD。
这部分使用了常用的两个指标去评估模型的表现性能,包括Mean Absolute Percentage Error (MAPE) 和 Root Mean Square Error (RMSE),具体定义如下:
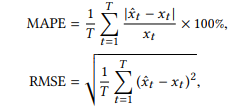
结果&分析:我们比较了在两个TSF场景下(具体场景可以查阅原文)所有模型的表现性能。在第一个场景,文章预测了在子序列期间基站的平均用户数,时段的长度由5到30分钟不定。图4比较了一个星期内20个基站的平均表现性能。从图片可以发现,尽管随着时间长度增加,所有模型的预测误差逐渐变小,但mLSTM还是取得了最好的表现。具体来说,mLSTM模型始终优于wLSTM模型,再次验证了mWDN用于时间序列预测的可行性。
在第二个场景中,文章预测给定时间间隔从0到30分钟后下一个5分钟内的平均用户数。图5比较了mLSTM和其他baselines的预测性能。与场景1观察到的趋势不同,伴随时间刻度增加预测误差会逐渐增加。同时从图5可以看出,mLSTM表现结果再一次优于其他baselines,也证明了由场景一观察到的结果。
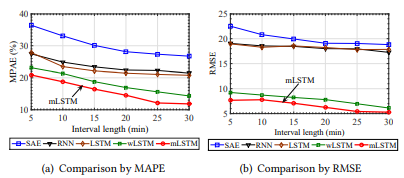
图4 Comparison of prediction performance with varying period lengths(Scenario Ⅰ)
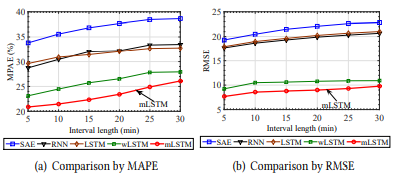
图5 Comparison of prediction performance with varying interval lengths(Scenario Ⅱ)
3. 可解释性研究
在该章节,文章重点介绍了mWDN模型得独特优势:可解释性。由于mWDN嵌入了离散小波分解,因此mWDN的中间层的输出和 继承了小波分解的物理意义。文章采用两个数据集对此进行解释:WuxiCellPhone和ECGFiveDays。图6(a)展示了一天之内手机基站的用户数量序列数据,图6(b)展示了心电图 (ECG) 样本。
继承了小波分解的物理意义。文章采用两个数据集对此进行解释:WuxiCellPhone和ECGFiveDays。图6(a)展示了一天之内手机基站的用户数量序列数据,图6(b)展示了心电图 (ECG) 样本。
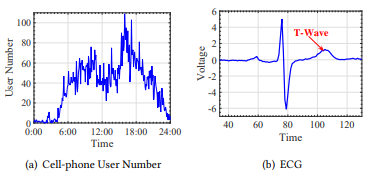
图6 时间序列数据样本
1. 实验动机
图7分别展示了mLSTM和RCF模型中输入图6时间序列样本后mWDN层的输出。图7(a)描述了mLSTM中经过三层小波分解以后的子序列,正如图片所示,由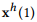 到
到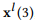 ,中间层的输出对应于输入序列从高到低的频率分量。相同的情况也可以从图7(b)中所看到,分别表示RCF模型前三层的输出,这表明mWDN的中间层继承了小波分解中的频率分解。
,中间层的输出对应于输入序列从高到低的频率分量。相同的情况也可以从图7(b)中所看到,分别表示RCF模型前三层的输出,这表明mWDN的中间层继承了小波分解中的频率分解。
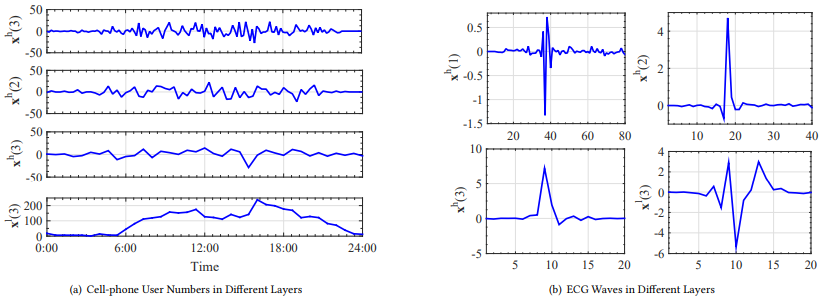
图7 mWDN模型生成的子序列
2. 重要性分析
文章介绍了一种针对mWDN模型重要性分析的方法,旨在量化每个隐藏层对mWDN模型最后输出的影响重要程度。我们定义了使用神经网络进行时间序列分类或预测的问题如下:
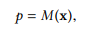
其中M表示神经网络,x表示输入的序列数据并且p表示预测值。给予一个训练好的模型M,如果对第i个元素的一个小的扰动会对输出p造成很大的改变,则说明M对非常敏感。因此,神经网络M对输入序列的第i个元素的敏感度被定义为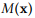 对的偏导数如下式:
对的偏导数如下式:
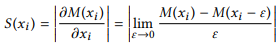
显而易见的,表示给定模型M关于的函数。给定J个训练样本的训练数据集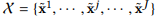 ,输入序列x的第i个元素对模型M的重要性可以定义为:
,输入序列x的第i个元素对模型M的重要性可以定义为:
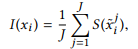
其中是第j个训练样本中第i个元素的取值。
上述重要性的计算公式可以延申到mWDN模型的隐藏层。假设a为mWDN模型的a隐藏层的一个输出,神经网络M可以重新改写为:
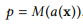
并且a对模型M的敏感性定义为:
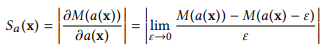
给定一个训练数据集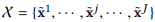 ,a对模型M的重要性计算如下:
,a对模型M的重要性计算如下:
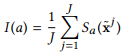
和分别表示一个时间序列元素和一个mWDN层对模型的重要性。
3. 实验结果
图8和图9分别展示了重要性分析的结果。图8中,mLSTM模型在WuxiCellPhone上测试。图8(b)展示了所有元素的重要性图谱,其中x轴表示时间戳,图谱颜色表示特征的重要性:越红越重要。从图谱中可以看出最新的元素比旧的元素更重要,这在时间序列分析场景中是非常合理的,也证明了信息的时间价值。
图8(a)展示了按照频率递增的顺序从上到下排列的隐藏层重要图谱。为了便于比较,文章将输出的长度统一。从图谱中,可以观察到顶部的低频层有着更高的重要性;并且只有具有更高重要性的隐藏层展示了与图8(b)一致的时间价值。这些都预示着mWDN中的低频层对时间序列的成功预测更重要。这并不难理解,因为从低频层捕捉到的信息通常表示人类活动的基本趋势,因此可以很好用于预测未来。
图9描绘了RCF模型在ECGFiverDay数据集上训练的重要性图谱。如图9(b)所示,最重要的元素大概位于100到110的时间轴,与图8(b)十分不同。为了更好理解,回想一下,这个范围对应于心电图的T波,涵盖了心脏放松和准备下一次收缩的这段时间。通常认为,T波异常表明生理功能严重受损。因此,描述T波元素对分类任务更重要。
图9(a)为隐藏层的重要性频谱图,同时按频率的递增顺序从上到下排列。其中一个与图8(a)相反的有趣现象是,高频层对于ECGFiveDays的分类任务更重要。为了理解这一点,我们应该明白低频层捕捉到的ECG曲线的总体趋势对每个人来说都非常相似的,而高频层所捕获的异常波动才是识别心脏病的真正可区分信息。这也揭示了时间序列分类和时间序列预测的不同。
本节的实验证明了结合小波分解和文章提出的重要性分析方法所产生的mWDN模型的可解释性优势,也可以看作是对深度学习黑盒问题的探讨。
6.结论
这篇文章的主要目的是为时间序列分析建立频率感知的深度学习模型。为了实现这个目标,我们首先设计了新的基于小波分解的神经网络结构mWDN,用于时间序列的频率学习,通过使所有参数都可以训练,可以无缝嵌入到深度学习框架中。基于mWDN结构,文章针对时间序列分类和预测任务,进一步设计了两种深度学习模型,并且在大量的真实数据集上进行的实验表明,他们比最先进的模型更具有优势。作为对可解释深度学习的一种新的尝试,文章进一步提出了重要性分析方法,用于识别影响时间序列分析的重要因素,从而验证了mWDN的可解释优点。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!
















 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











