






1 文章信息
文章题为“Task-based End-to-end Model Learning in Stochastic Optimization”,该文于2017年发表至“NIPS”神经信息处理系统会议。文章的核心观点是提出了一种端到端(end-to-end)的方法,用于在随机优化(stochastic optimization)背景下学习概率机器学习模型。这种方法直接捕捉模型最终任务目标,即模型将在实际应用中被评估的标准,而不是仅仅基于训练时使用的准则。
2 摘要
随着机器学习技术的日益普及,我们经常看到预测算法在更广泛的流程中运行。然而,我们训练这些算法的标准通常与我们最终评估它们时使用的标准不同。本文提出了一种端到端的方法,用于学习概率机器学习模型,这种方法直接捕捉它们将在随机规划背景下用于的最终任务目标。我们通过三个实验评估了这种方法:一个经典的库存问题,一个现实世界的电网调度任务,以及一个现实世界的能源存储套利任务。我们展示了在这些应用中,我们提出的方法可以优于传统建模和纯粹的黑盒策略优化方法。
3 引言
预测算法通常被集成到更大的系统中,例如在自动驾驶中使用图像分类算法。然而,这些算法在训练时优化的标准(如准确率或对数似然)可能与它们在实际应用中需要达到的目标(如在自动驾驶中区分行人和树木的重要性)不一致。
作者指出了一个常见的问题,即在训练时使用的"通用损失"(generic loss)可能无法准确反映算法在实际应用中需要最小化的"真实损失"(true loss)。例如,在电力需求预测中,我们关心的是如何使用这些预测来最小化电网调度的成本,而不仅仅是预测的准确性。
传统的两步法,即首先训练一个预测模型,然后在随机规划环境中使用这个模型来计算或近似必要的期望成本。这种方法忽视了系统的真实成本可能从一个在整体似然上表现更差,但在某些特定空间流形上做出更准确预测的模型中受益。
文章提出了一种端到端的学习方法,这种方法直接针对模型的最终任务目标进行优化。在随机规划的背景下,这意味着要最小化模型预测的期望成本,同时可能还要满足一些概率或确定性约束。
4 随机规划中的端到端模型学习
(1)讨论与替代方法
首先定义了从某个真实但未知的分布 D 中抽取的标准输入输出对 ,考虑了动作z∈Z 会产生的期望损失
,考虑了动作z∈Z 会产生的期望损失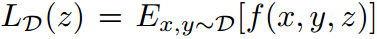 。例如,在电力系统中,根据过去的电力需求x 和未来的电力需求y 来分配电力发电机z,分配的损失对应于未来需求实现时的过剩或不足发电的惩罚。
。例如,在电力系统中,根据过去的电力需求x 和未来的电力需求y 来分配电力发电机z,分配的损失对应于未来需求实现时的过剩或不足发电的惩罚。
作者提出使用参数化模型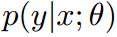 ,来模拟条件分布 𝑦∣𝑥,目标是最小化由这种参数化策略隐含的真实世界成本。通过随机优化过程确定最优动作
,来模拟条件分布 𝑦∣𝑥,目标是最小化由这种参数化策略隐含的真实世界成本。通过随机优化过程确定最优动作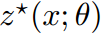 ,这些动作对应于观察到的输入 𝑥 和模型中特定参数 𝜃 的选择。目标是找到参数 𝜃,使得相应的策略
,这些动作对应于观察到的输入 𝑥 和模型中特定参数 𝜃 的选择。目标是找到参数 𝜃,使得相应的策略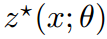 在真实的联合分布 𝑥 和 𝑦 下优化损失。
在真实的联合分布 𝑥 和 𝑦 下优化损失。
损失函数如下:
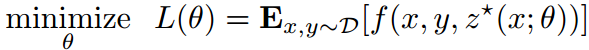 (1)
(1)
实际上我们不知道分布 D,我们通过一个代理随机优化问题来获得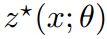 。
。
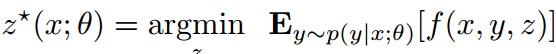 (2)
(2)
由于决策可能受到概率和确定性约束的约束。因此,我们考虑通过一个通用随机优化问题产生的更一般的决策。
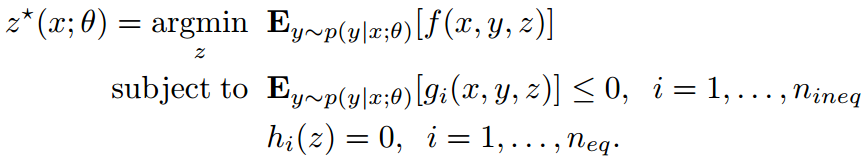 (3)
(3)
在这种情况下,完整的任务损失更为复杂,因为它既捕获了预期成本,也捕获了与约束的任何偏差。比如,我们可以把它写成:
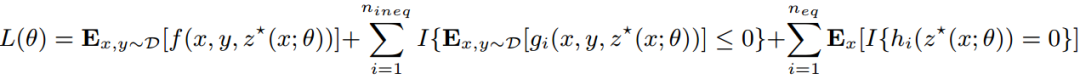 (4)
(4)
实际解决这个问题需要我们对随机规划问题的“argmin”操作符 𝑧∗(𝑥;𝜃) 进行微分。这种微分对于所有类别的优化问题是不可能进行的,因为argmin 操作可能不是连续的。
文章提到,作者找到一种解决公式(1)问题的替代方法。在这里,作者完全放弃学习 𝑦 的任何模型,通过直接从输入 𝑥 学习到动作 𝑧∗(𝑥;𝜃ˉ) 的策略,以最小化在(4)中提出的损失 𝐿(𝜃ˉ)(在这里 𝜃ˉ定义了策略的形式,而不是预测模型)。虽然这种无模型方法在许多情况下可以表现良好,但它们通常非常数据低效,因为策略类别必须具有足够的表示能力来描述足够复杂的策略,而不需要依赖任何底层模型。
该提供了一个中间设置,仍然使用一个替代模型来确定最优决策 𝑧∗(𝑥;𝜃),但是我们根据任务损失而不是任何模型预测精度来调整这个模型。在实践中,最小化对数似然和任务损失的某种加权组合。
(2)优化任务损失
为了解决通用优化问题(4),我们原则上可以采用直接的随机梯度方法,具体为算法1。在每次迭代中我们通过代理随机优化问题(3)来获得 𝑧∗(𝑥,𝜃),使用由我们当前的 𝜃 值定义的分布。然后,我们使用观察到的 𝑦 的真实损失 𝐿(𝜃) 来计算。如果 𝐿(𝜃) 中的任何不等式约束 𝑔𝑖 被违反,我们就在违反的约束上执行梯度步骤;否则,我们就在优化目标 𝑓 上执行梯度步骤。

如果 𝐿(𝜃) 中的任何不等式约束是概率性的,算法1必须适应使用小批量数据,以确定这些概率约束是否得到满足。或者,因为即使是 𝑔𝑖 约束也是概率性的,实践中通常简单地将这些约束以加权形式移到目标函数中,即通过添加某个适当的惩罚乘以函数的正部分,𝜆𝑔𝑖(𝑥,𝑦,𝑧)+,对某些 𝜆>0,来修改目标。实践中,这在违反一个或多个不等式约束的情况下,通常会导致同时在所有违反的约束和目标上执行梯度步骤,通常可以导致更快的收敛。注意,我们只需要将随机约束移到目标中;策略本身的确定性约束将始终被优化器满足,因为它们与模型无关。
(3)随机规划问题最优解的微分
上述方法突出了所提出方法的简单性,但它避免了这种方法的主要技术挑战,即计算依赖于 𝑧∗(𝑥;𝜃) 的 argmin 操作的目标函数的梯度。具体来说,我们需要计算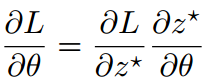 ,这涉及到雅可比矩阵
,这涉及到雅可比矩阵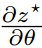 。这是最优解相对于参数 𝜃 的雅可比矩阵。在高层次上,我们首先写出一般随机规划问题(3)的KKT最优条件。微分这些方程并应用隐函数定理给出了我们可以解决以获得必要雅可比矩阵的一组线性方程(期望在分布 𝑦∼𝑝(𝑦∣𝑥;𝜃)上表示为 𝐸𝑦∣𝜃,其中 𝑔 是不等式约束的向量):
。这是最优解相对于参数 𝜃 的雅可比矩阵。在高层次上,我们首先写出一般随机规划问题(3)的KKT最优条件。微分这些方程并应用隐函数定理给出了我们可以解决以获得必要雅可比矩阵的一组线性方程(期望在分布 𝑦∼𝑝(𝑦∣𝑥;𝜃)上表示为 𝐸𝑦∣𝜃,其中 𝑔 是不等式约束的向量):
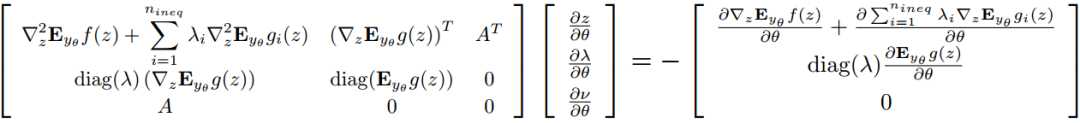 (7)
(7)
左边给出了凸问题的最优性条件,右边给出了在达到的解处相关函数相对于控制参数 𝜃 的导数。在实践中,我们通过使用顺序二次规划来找到给定参数𝜃的最优策略 𝑧∗,使用最近提出的方法快速解决QP的argmin微分来解决必要的线性方程;然后我们在这种策略产生的最优解处取导数。
5 实验
实验一:库存问题
考虑了一个经典的库存库存问题的“条件”变体。在这个问题中,一家公司必须订购某种产品的数量 𝑧,以最小化在某些随机需求 𝑦 上的成本,而这种需求的分布又受到一些观察到的特征 𝑥 的影响(见下图)。订购的产品数量有线性和二次成本,另外还有对超订和欠订的不同的线性/二次成本。目标函数由下式给出:
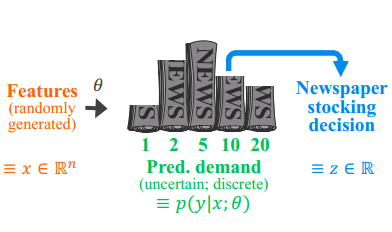
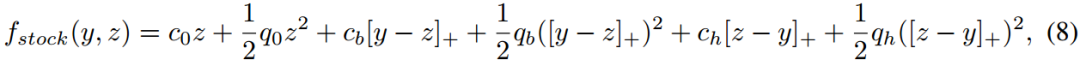
其中,[𝑣]+≡max{𝑣,0}。对于特定的概率模型 𝑝(𝑦∣𝑥;𝜃),我们的代理随机规划问题可以写成:
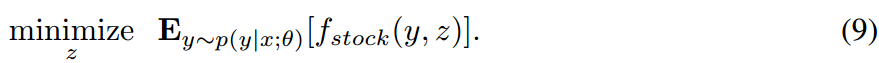
为了简化设置,我们进一步假设需求是离散的,取值为 𝑑1,…,𝑑𝑘,其条件概率为 (𝑝𝜃)𝑖≡𝑝(𝑦=𝑑𝑖∣𝑥;𝜃)。因此,我们的随机规划问题可以简洁地写成联合二次规划问题:
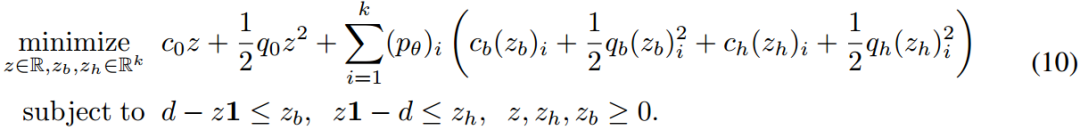
实验设置:我们在两种主要条件下检查我们的算法:真实模型是线性的和非线性的。在所有情况下,我们通过随机采样一些 𝑥∈𝑅𝑛,然后根据 𝑝(𝑦∣𝑥;𝜃)∝exp(Θ𝑇𝑥)(线性真实模型)或 𝑝(𝑦∣𝑥;𝜃)∝exp((Θ𝑇𝑥)2)(非线性真实模型)生成 𝑝(𝑦∣𝑥;𝜃),其中 Θ∈𝑅𝑛×𝑘。我们在这些任务上比较了以下方法:
1)基于真实模型的QP分配(表现最优);
2)MLE方法(线性或非线性概率模型),通过拟合数据到模型,然后通过解决QP来计算分配;
3)纯端到端策略优化模型(使用线性或非线性假设的策略);
4)我们的基于任务的学习模型(线性或非线性概率模型)。
在所有情况下,我们通过在1000个随机示例上运行来评估测试性能,并在10折不同的真实 𝜃∗ 参数上评估性能。
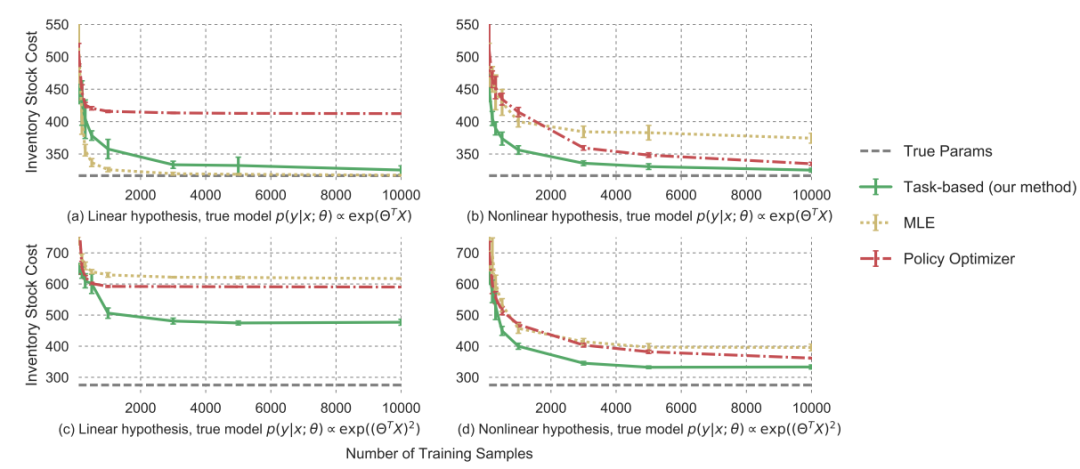
下图(a)和(b)显示了在线性真实模型的情况下,使用线性和非线性模型假设的这些方法的性能。正如预期的那样,线性MLE方法表现最佳,因为真实的底层模型在它可以表示的分布类别中,因此解决随机规划问题是解决真实分布下的真实优化问题的一个很好的代理。尽管非线性MLE的真实模型也在其通用非线性分布类别中,我们看到这种方法需要更多的数据才能收敛,并且在给定较少数据时做出的误差权衡最终不是任务的正确权衡;我们基于任务的方法因此优于这种方法。基于任务的方法还大大优于策略优化神经网络,突出了通过合理模型运行学习过程更加数据高效的事实。请注意,在这里,无论在基于任务的方法中使用线性还是非线性模型都没有区别。
下图(c)和(d)显示了在非线性真实模型的情况下,使用线性和非线性模型假设的性能。情况(c)代表了“不可实现”的情况,真实的底层分布不能由模型假设类别表示。在这里,线性MLE,正如预期的那样,表现得非常差:它无法捕捉真实的底层分布,因此得到的随机规划解决方案预计不会表现良好。线性策略模型也表现不佳。重要的是,基于任务的线性模型在这里表现得更好:尽管它仍然有模型误设定,基于任务的学习过程让我们学习到一个不同于MLE版本的不同线性模型,该模型特别针对任务的分布和损失进行了调整。最后,正如预期的那样,非线性模型在这种情况下比线性模型表现更好,但同样,基于任务的非线性模型优于非线性MLE和端到端策略方法。
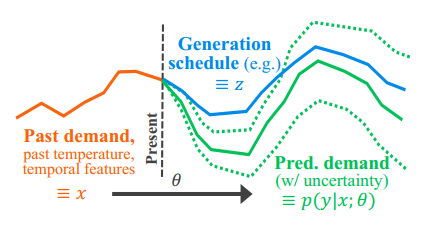
实验二:负载预测和发电机调度
基于8年真实电网数据的电网调度任务。目标是制定一个发电计划 𝑧∈𝑅24,该计划针对未来24小时的每小时电力需求𝑦进行优化,基于电力需求的未知分布(见下图)。目标是最小化总成本,包括发电过剩和不足的惩罚,以及与实际需求𝑦偏差的二次正则化项。具体公式如下:
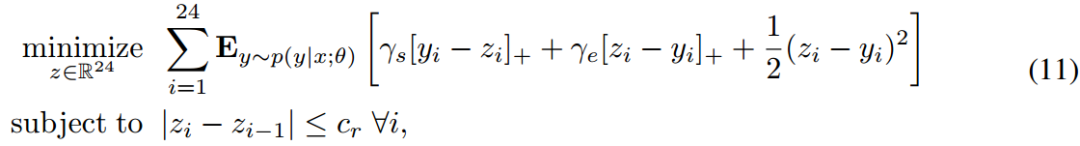
 是电力需求未被满足时的惩罚成本。
是电力需求未被满足时的惩罚成本。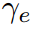 是发电超出需求时的惩罚成本。
是发电超出需求时的惩罚成本。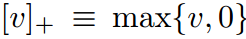 表示非负部分。𝑝(𝑦∣𝑥;𝜃)是给定历史数据 𝑥 下,需求 𝑦 的概率分布。𝐸 表示期望值。约束条件表示:连续时间点之间的发电量变化不能超过一个限制 𝑐𝑟,以避免快速变化对电网稳定性造成影响。
表示非负部分。𝑝(𝑦∣𝑥;𝜃)是给定历史数据 𝑥 下,需求 𝑦 的概率分布。𝐸 表示期望值。约束条件表示:连续时间点之间的发电量变化不能超过一个限制 𝑐𝑟,以避免快速变化对电网稳定性造成影响。
𝑦𝑖 是高斯随机变量,那么这个期望有一个封闭形式,可以通过解析地积分高斯PDF来计算。然后我们使用顺序二次规划(SQP)来迭代近似得到的凸目标作为二次目标,迭代直到收敛,然后使用解处的二次近似来计算必要的雅可比矩阵,这给出了正确的Hessian和梯度项。
下图显示了用于预测第二天每小时电力负荷的2个隐藏层神经网络的架构。我们训练模型以最小化其预测值与实际负荷之间的均方误差,在所有情况下,使用7年的数据来训练模型,并使用随后的1.75年进行测试。
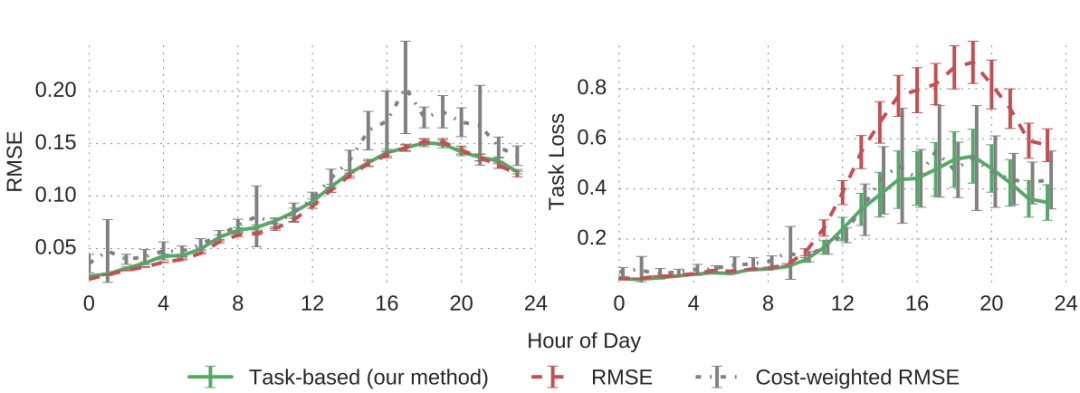
使用这个基础模型(均值和方差)的预测值,通过解决发电机调度问题(11)来获得 𝑧∗(𝑥;𝜃),然后调整网络参数以最小化结果任务损失。我们与传统的随机规划模型进行了比较,后者只最小化均方根误差(RMSE),以及一个按成本加权的RMSE,后者根据其任务损失定期重新加权训练样本。上图显示了三种模型在测试数据集上的性能。正如预期的那样,RMSE模型在预测的均方根误差方面表现最佳(因为它的目标就是最小化这个)。然而,当以任务损失来评估时,基于任务的模型显著优于RMSE模型,这是系统运营商真正关心的实际目标:具体来说,通过38.6%的性能提升超过了传统随机规划方法的表现。成本加权RMSE的性能非常不稳定,总体而言,任务网络通过8.6%的性能提升超过了这种方法。
6 结论
文章提出了一种用于学习将在更大过程中循环使用的机器学习模型的端到端方法。具体来说,考虑在随机规划的背景下训练概率模型,以直接捕捉基于任务的目标。初步实验表明,基于任务的学习方法在所有情况中都显著优于MLE和策略优化方法,除了MLE模型“完美”地表征底层分布的(罕见)情况。该方法还在基于预测负载的高度优化现实世界随机规划算法中实现了38.6%的性能提升。因此,基于任务的方法在优化循环内预测方面显示出了前景。未来的工作包括将我们的方法扩展到具有多轮的随机学习模型,并进一步扩展到模型预测控制和完整的强化学习设置。
















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











