







文章信息

论文题目为《Causal Contextual Prediction for Learned Image Compression》,文章来自IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY,是一篇图像压缩领域论文,文中提出现有的熵模型存在不能捕捉到潜在因素之间的全局空间相关性、潜在向量的通道关系不明确等问题。因此本文提出了分离熵编码的概念,以利用串行解码过程在潜在空间中进行因果上下文熵预测。此外,本文还提出了一个因果全局预测模型来寻找全局参考点,以准确预测解解码点。实验结果表明,本文的压缩模型优于标准的VVC/H.266。就PSNR和MS-SSIM而言,柯达数据集上的编解码器产生了最先进的率失真性能。

摘要

在过去的几年中,本文目睹了学习图像压缩领域取得了令人印象深刻的进展。最近学习的图像编解码器通常基于自编码器,首先将图像编码为低维潜在表示,然后解码以实现重建目的。为了捕获潜在空间中的空间依赖性,先前的研究利用超先验和空间上下文模型建立了熵模型,该模型估计了端到端率失真优化的比特率。然而,这种熵模型在两个方面是次优的:(1)它不能捕捉到潜在因素之间的全局空间相关性。(2)潜在因素的跨渠道关系尚不明确。在本文中,本文提出了分离熵编码的概念,以利用串行解码过程在潜在空间中进行因果上下文熵预测。
提出了一个因果上下文模型,该模型分离了跨渠道的潜在因素,并利用渠道相关关系生成高信息量的相邻上下文。此外,本文提出了一个因果全局预测模型来寻找全局参考点,以准确预测解解码点。
这两种模型都便于熵估计,而不需要传输开销。此外,本文还进一步采用了新的分组分离关注模块来构建更强大的转换网络。实验结果表明,本文的全图像压缩模型优于标准的VVC/H。就PSNR和MS-SSIM而言,柯达数据集上的266编解码器产生了最先进的率失真性能。

贡献

(1)为了进行更有效的上下文建模,本文提出了将潜在表示划分为两个通道组的分离熵编码的概念。因此,本文提出了一个因果背景模型,本文使用跨通道冗余来生成信息丰富的相邻上下文。
(2)本文明确指出,利用全局范围上下文对熵建模至关重要,并提出了一个因果全局预测模型来在全局范围内进行预测。通过扩展的概念单独的熵编码,该模型不需要额外的开销传输,但仍然可以建立全局参考信息。
(3)本文采用群分离注意模块来加强非线性变换网络,该网络比以往的注意设计更强大。本文把这一点作为一种支持本文的论述。

问题定义

在图像压缩的变换编码方法中,编码器使用参数分析变换转化为潜在表示,然后量化形成。因为是离散值,它可以使用熵编码技术,如算术编码(Rissanen和Langdon, 1981)进行无损压缩,并作为比特序列传输。另一方面,解码器从压缩信号中恢复,并对其进行反量化后再进行参数合成变换恢复重构图像。在本文中认为变换和是一般的参数化函数,如人工神经网络(ann),而不是传统压缩方法中的线性变换。然后,参数和封装了神经元的权重等。因此问题定义如下:
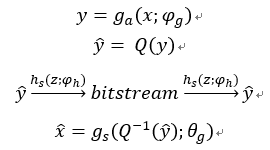

方法

5.1 因果上下文模型
受PixelCNN++预测的的启发,本文提出了一个因果上下文模型来改进熵估计。因果上下文模型将潜在向量y分成跨通道的两组。解码yn时,照例预测第一信道组yn,1的分布,采用掩模卷积fc,1(如图1所示) 结合超先验z生成相邻上下文cn,1。由于串行解码过程,一旦第一组yn,1被解码,本文就可以用这个已知的组来估计第二组yn,2。改进后的掩模卷积fc,2,如图2所示,通过对传统掩模卷积进行修改,可以将相邻的解码后的潜在信号和当前空间位置的前半段潜在信号进行聚合,生成信息更丰富的相邻上下文cn,2。改进的掩模卷积可以看作是掩模卷积与因果卷积之间的一种突变。
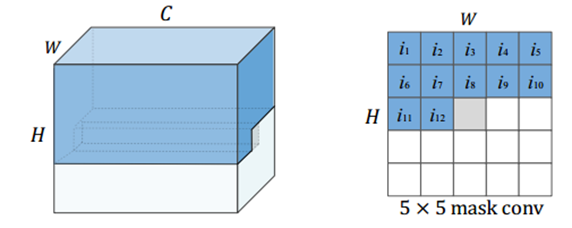
图1:掩码卷积
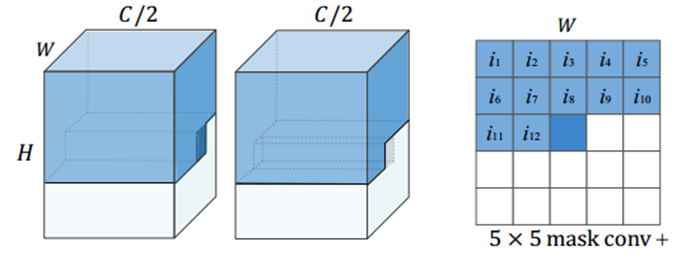
图2:改进掩码卷积
5.2 全局因果上下文模型
上述因果上下文模型有助于捕获空间冗余和通道冗余。他只是提取局部相关性,但忽略全局相关性。在本节中, 本文对其进行了改进,并提出了一个利用潜在特征的长期相关性的因果全局预测模型。所提出的因果全局预测模型也将潜在特征y分成两组。第一信道组yn,1的压缩过程不变,只是利用了超先验和局部上下文模型,如图3a所示。然而,为了估计第二个潜在组的分布,熵模型现在将改进的相邻上下文cn,2和全局上下文cn,3合并。
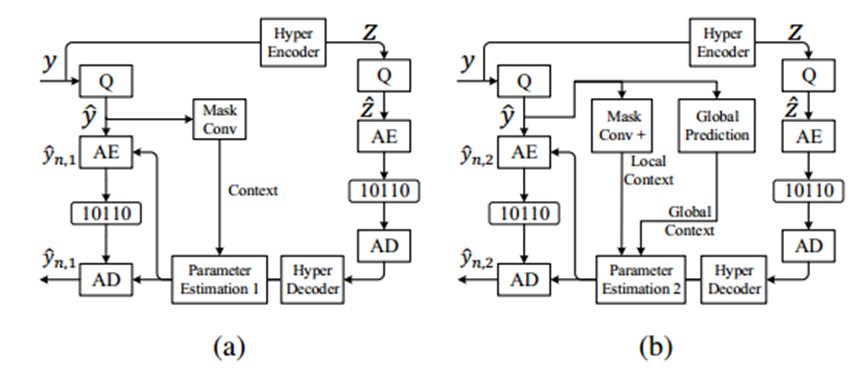
图3:因果全局预测模型
5.3 全局上下文预测
前面的讨论显示了在解码器能够建立准确的全局参考信息的前提下,全局上下文对熵估计的潜力。然而,显式传输相关点的信息是非常耗费比特的。如图4所示,本文发现半潜在向量之间的相似度与整个潜向量之间的相似度相匹配。这意味着整个潜在变量的空间相关性可以通过从前半通道计算的相关矩阵来近似。这一观察结果促使本文利用潜在分离的概念在解码器端生成无比特的全局相关性。由于编码变换网络对自然图像进行了4次步长=2的下行采样,每个空间位置的潜在向量可以大致表示原始图像16×16区域内的上下文。因此,潜在相关矩阵与图像上下文之间存在密切的关系。

图4:潜向量特征
图5显示了全局预测过程。在解码第一个潜在组yn,1之后,本文然后计算所有半向量之间负成对L2距离,产生HW ×HW相关矩阵。由于解码过程是因果关系,相关矩阵被屏蔽为上三角矩阵。为了避免偶尔不准确的预测,本文只保留前k个相关点,并收集它们的指数来生成因果预测指数。这些索引表示当前解码点的k个最相似点,用于索引和在第二组中选择合适的特征。索引后,每个点有k个向量,用来预测当前的解码点。每个预测向量的维数为1 × 1 × c/2。考虑到潜势总共有HW个点,本文现在有kHW个向量作为预测信息。由于当前的预测向量是直接从先前解码的点中收集的,因此本文将这些向量发送到共享多层感知器(MLP)中,这是学习有效表示的常用过程。最后,本文对MLP的输出进行平均,以生成全局上下文。在本文的实验中,本文使用top-4预测生成全局上下文。
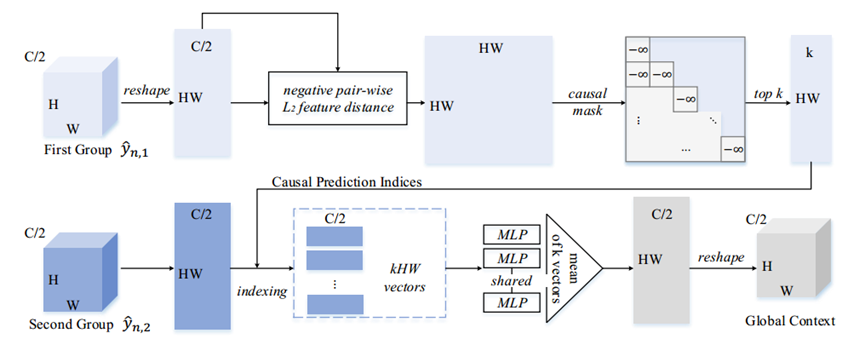
图5:全局上下文预测

实验

为了进行比较,本文在包含24张未压缩图像的柯达数据集上评估了不同的方法。R-D曲线如图6所示。本文的方法与其他现有方法(包括LIC和传统编解码器,如VVC intra和HEVC intra)的性能比较。具体来说,Balle et al.的结果来自于本文的再现模型,其表现与他们的报告非常接近。Minnen等人(NeurIPS2018)和Cheng等人(CVPR2020)的结果直接取自他们的论文,因为本文的复制统计数据略低于他们的报告。复制差距可能是由训练集的差异引起的。虽然本文直接使用整个ImageNet训练集,但没有提到训练集,使用ImageNet的一个子集来避免负样本。对于VVC和HEVC,本文使用官方测试模型VTM 8.0和HM 16.217,配置YUV444为全内模式。
图6定量地表明,本文的方法达到了最先进的率失真性能。具体来说,就PSNR而言,它在所有比特率下都优于VTM 8.0,并且在MS-SSIM的大多数比特率下,它的性能优于之前最先进的方法。本文的方法在VTM 8.0(覆盖0.15,0.4,0.7和1.0 bpp)下实现了5.1%的BD率节省。本文的PSNR-rate曲线上有一个不规则的点(在0.68 bpp),这是模型容量变化的转折点。在图7中,本文提供了一些例子,通过本文的方法获得了令人满意的定性结果,特别是针对MS-SSIM优化的模型。
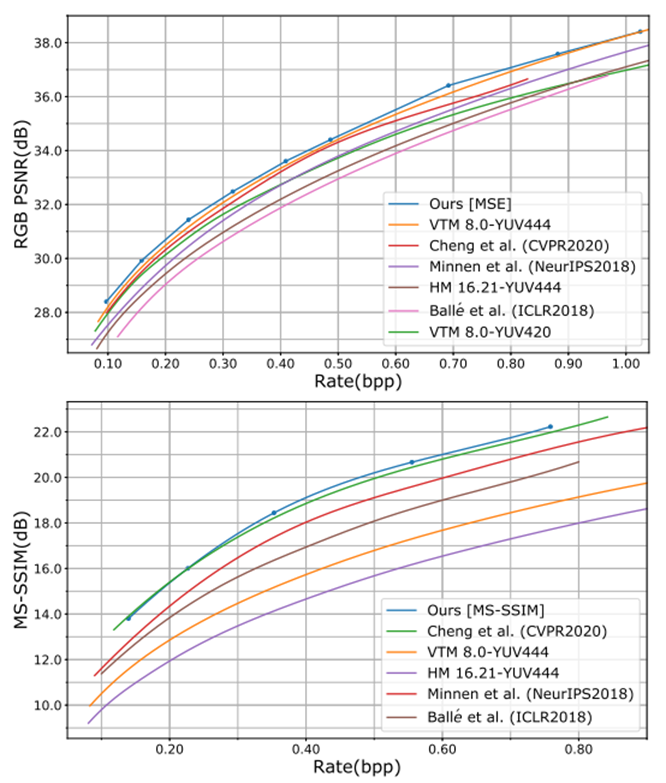
图6 R-D曲线
此外,本文提出的方法有望在具有大量重复模式的图像(如屏幕捕获图像)上呈现更好的结果。在这里,本文评估了本文的方法在一些屏幕内容的HEVC标准测试序列的屏幕捕获图像上的性能。本文注意到,有一些屏幕捕获的图像具有非常简单的背景,只需要很少的比特(< 0.01 bpp),但很容易提供高质量的重建(PSNR > 45dB)。因此,这类图像会对平均率失真性能产生重大影响,使平均统计不可靠。
如图7所示,本文使用仍然在ImageNet数据集上训练的完整压缩模型进行比较。可以观察到,当比特率较低时,本文的方法可以获得更好的性能。验证了本文提出的因果预测方法的有效性。然而,随着比特率和PSNR值的增加,VVC的性能逐渐优于本文的方法。这一结果可以从神经压缩模型的自编码器(AE)极限的角度来解释[46]。本文的神经压缩模型是一个基于vae的模型,其中编码器变换和解码器变换是不可逆的。它不同于传统编解码器中使用的线性可逆变换,如DCT。不可逆变换网络引入了误差和信息损失,从而设定了失真的下界。相比之下,传统编解码器采用的可逆变换不会带来信息丢失。当重建质量很高时,基于学习的压缩模型将达到AE限制导致性能不如传统的编解码器。由于屏幕捕获的图像有很多重复的模式,有些甚至有非常简单的上下文,因此屏幕捕获图像的重建质量自然非常高。因此,当使用基于学习的编解码器压缩屏幕捕获的图像时,由于高质量的重建,很容易遇到AE限制问题。因此,在这种情况下对屏幕捕获的图像进行压缩,本文的方法在比特率较低时优于VVC,但在PSNR值较高时不如VVC。

图7:可视化压缩结果


















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











