







文章信息

论文题目为《Data-driven discovery of partial differential equations》,该文于2017年发表于《Science Advances》上。文章提出了一种稀疏回归方法,能够通过在空间域中的时间序列数据来挖掘给定系统的控制偏微分方程。

摘要

本文提出了一种稀疏回归方法,能够通过在空间域中的时间序列数据来发现给定系统的控制偏微分方程。回归框架依赖于稀疏提升技术来选择最准确地表达数据的控制方程的非线性和偏导数项,避免对所有可能的候选模型组合进行大规模搜索。该方法通过帕累托分析选择简洁模型,平衡模型复杂性和回归精度。时间序列测量可以在欧拉框架中进行,其传感器在空间上是固定的,或者在拉格朗日框架中进行,其传感器动态移动。该方法计算效率高,鲁棒性强,并被证明可以处理跨越多个科学领域的各种典型问题,包括纳维-斯托克斯,量子谐振子和扩散方程。此外,该方法能够通过使用具有不同初始数据的多个时间序列来消除潜在的非唯一动态项之间的歧义。因此,对于行波,该方法可以区分线性波动方程和Korteweg-de Vries方程。该方法为发现参数化时空系统中的控制方程和物理定律提供了一种有前途的新技术,特别难以从第一性原理进行推导的系统。

介绍

在过去几十年里,由于传感器、数据存储和计算资源成本的不断下降,数据驱动的发现方法对科学产生了变革性的影响,促进了对实验产生的高维数据进行表达的各种创新。人们难以从表现时空活动的时间序列数据中发现潜在的物理定律和/或控制方程。传统的推导偏微分方程的理论方法基于守恒定律、物理原理和/或现象学行为。这些第一性原理衍生出了许多在物理学、工程学和生物科学中无处不在的规范模型。然而,仍然有许多复杂的系统无法进行定量分析描述,甚至无法选择合适的变量进行表征(例如,神经科学、电网、流行病学、金融和生态学)。本文提出了一种替代方法来推导控制方程,该方程仅基于在固定数量的空间位置收集的时间序列数据。利用稀疏回归中发现最准确地表示来自大量潜在候选函数库的数据的控制偏微分方程的项。测量可以在欧拉框架中进行,其中传感器在空间上是固定的,或者在拉格朗日框架中进行,其中传感器随着动态移动。本文通过仅从时间序列数据中重新发现广泛的物理定律来证明该方法的成功。数据驱动的动态系统发现方法:包括无方程建模、人工神经网络、非线性回归、经验动态建模、范式识别、非线性拉普拉斯谱分析、紧急行为建模和动态自动推理。在这一系列发展中,利用符号回归和进化算法的开创性贡献能够直接从数据确定非线性动力系统。最近,通过高效的计算方式解决稀疏性稳健地确定控制动力系统。进化和稀疏号回归方法都通过选择简约模型来避免过拟合,通过帕累托分析平衡模型精度和复杂性。本文提出的方法能够从一个大的库中选择正确的线性、非线性和空间导数项,从而从数据中识别偏微分方程,那些关于动态信息最多的项才会被选择作为发现的偏微分方程的一部分。这里提出的创新非常重要,因为它有效地处理时空数据,这是许多规范模型的基本特征。以前的稀疏性提升方法能够从数据中识别常微分方程,但不能处理时空数据或高维测量。本文的新方法有几个有利的实用特点:测量可以在固定或移动框架(欧拉或拉格朗日)中收集,允许广泛应用于各种实验数据;该算法还通过创新的采样策略有效地处理高维数据。非线性动力学的偏微分方程发现(PDE- FIND)算法适用于各种典型模型。

方法论

本文考虑一般形式的参数化非线性偏微分方程:
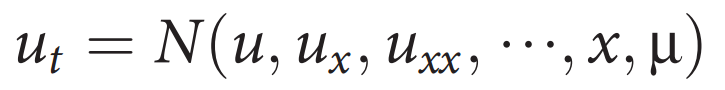
其中下标表示时间或空间上的偏微分,N(∙)是未知方程的右侧,通常是u(x, t)及其导数的非线性函数。本文的目标是给定系统在x中固定数量的空间位置上的时间序列测量值来构建N(∙)。一个关键的假设是函数N(∙)仅由几个项组成,使得函数形式相对于可能的贡献项的大空间来说是稀疏的。因此,考虑到用于构建偏微分方程的候选项的大量集合,本文使用稀疏回归方法来确定哪些右侧项对动态有贡献,而无需在所有可能的项组合中进行难以处理的(np-hard)组合暴力搜索。
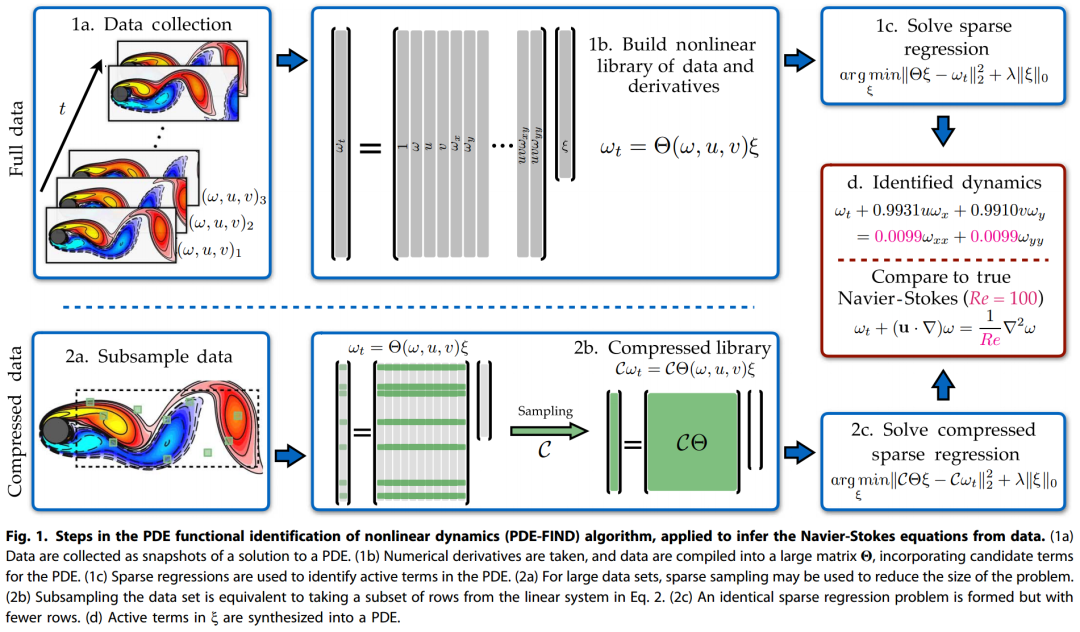
图1 模型架构
在离散化之后,公式1的右侧可以表示为U的函数,U是u(x, t)及其导数的离散版本,通过矩阵Q(U, Q)表示,其中列向量Q包含右侧的任何附加输入项。库Q(U, Q)的每一列对应于控制方程的一个特定候选项,如图1 (1b)所示。PDE的演变可以在这个库中表示如下
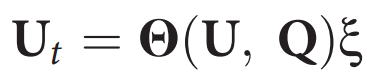
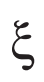 中的每个非零项对应于PDE中的一个项,对于规范PDE,向量
中的每个非零项对应于PDE中的一个项,对于规范PDE,向量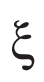 是稀疏的,这意味着只有少数项是相关的。
是稀疏的,这意味着只有少数项是相关的。
该方法是建立在三个关键思想之上的:(i)表示动态的候选函数的完备库,(ii)选择少量函数的稀疏回归,以及(iii)通过帕累托分析对控制方程简洁性选择。即使在测量中存在噪声的情况下,该体系结构也能够准确地计算导数。每种方法详细介绍如下。
(1)建立候选术语库:稀疏回归发现方法(如图1所示)首先将所有空间时间序列数据收集到一个单列向量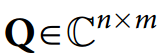 中,表示在m个时间点和n个空间位置上收集的数据。
中,表示在m个时间点和n个空间位置上收集的数据。
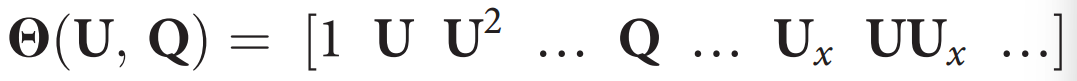
我们假设 是一个足够大的函数库,这意味着
是一个足够大的函数库,这意味着 有足够丰富的列空间,动态将在其范围内,那么偏微分方程使用合适的稀疏向量
有足够丰富的列空间,动态将在其范围内,那么偏微分方程使用合适的稀疏向量 ,方程2能够很好地表示系统的动态行为。这相当于选择足够的候选函数,完整的偏微分方程可以写成不同项的加权和。对于系统动力学的无偏表示,使用最小二乘法简单地求解稀疏向量
,方程2能够很好地表示系统的动态行为。这相当于选择足够的候选函数,完整的偏微分方程可以写成不同项的加权和。对于系统动力学的无偏表示,使用最小二乘法简单地求解稀疏向量 。然而,然而来自数值导数的误差,最小二乘法的解也可能是不准确的。特别是,
。然而,然而来自数值导数的误差,最小二乘法的解也可能是不准确的。特别是, 中主要是非零值,这表明偏微分方程具有库中包含的部分项。
中主要是非零值,这表明偏微分方程具有库中包含的部分项。
(2)稀疏回归:一般来说,我们需要寻找最满足方程2稀疏向量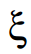 。本文不是通过所有可能的稀疏向量结构进行暴力搜索,一种常见的技术是将问题放宽到一个凸的正则化最小二乘;然而,对于高度相关的数据,这往往表现不佳。相反,本文使用具有硬阈值的脊回归方法来求解问题,STRidge。对于给定超参数,寻找最优的稀疏向量
。本文不是通过所有可能的稀疏向量结构进行暴力搜索,一种常见的技术是将问题放宽到一个凸的正则化最小二乘;然而,对于高度相关的数据,这往往表现不佳。相反,本文使用具有硬阈值的脊回归方法来求解问题,STRidge。对于给定超参数,寻找最优的稀疏向量 :
:
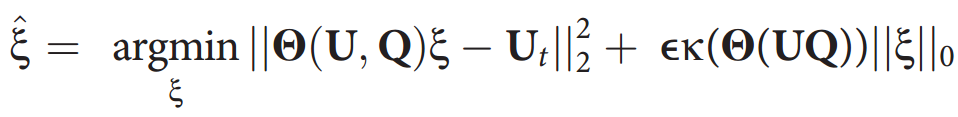
(3)导数的数值计算:数值导数的正确计算是该方法成功的关键,特别是当离散值包含测量噪声时。考虑到有限差分近似的精度问题,本文采用了一些更鲁棒的数值微分方法。高斯核平滑和Tikhonov微分都进行了研究,但由于难以平衡控制偏差-方差,因此难以实现。对高频项也考虑了带有阈值的谱微分,但由于其对周期域的限制和实现适当阈值函数的困难而没有使用。从噪声数据中计算导数最可靠、最稳健的方法是多项式插值。对于计算导数的每个数据点,P次的多项式适合于大于P个点,并且多项式的导数近似于数值数据的导数。靠近边界的点难以拟合多项式,因此不用于回归。这种方法远非完美;靠近边界的数据很难区分,本文发现这可能会严重影响PDE-FIND的结果。

实验

图1展示了成功识别给定物理系统测量数据的正确PDE动力学的算法过程。具体而言,在给定雷诺数下,模拟绕圆柱的流体流动,并对涡度和速度进行密集或稀疏采样,以正确重建众所周知的Navier-Stokes方程。值得注意的是,PDE的系数和雷诺数的识别精度达到了百分之一以内的误差。该图展示了我们创新的数学结构,它结合了稀疏回归、潜在函数形式的库以及简约模型选择。
图1还表明,对于由二维和三维问题生成的大型数据集,PDE-FIND算法可以有效地用于子采样数据。这一区别至关重要,因为全面状态测量通常在计算和实验上都是难以获取的,而且可能使回归过程变得不必要地昂贵。我们随机选择一组空间点,并在时间上均匀地进行子采样,从而只使用数据集的一小部分。从数学上讲,这相当于忽略线性系统Ut = Q(U, Q)x中的一部分行,如图1中的2a和2b所示。尽管我们在回归中只使用了线性系统中的一小部分空间点,但为了计算库中的导数项,仍需要使用附近的点。这些导数是通过使用靠近每个测量位置的少量空间局部化点,通过多项式插值来计算的。因此,虽然子采样仅使用了回归中的一小部分点,但我们在每个测量点周围利用了局部信息。
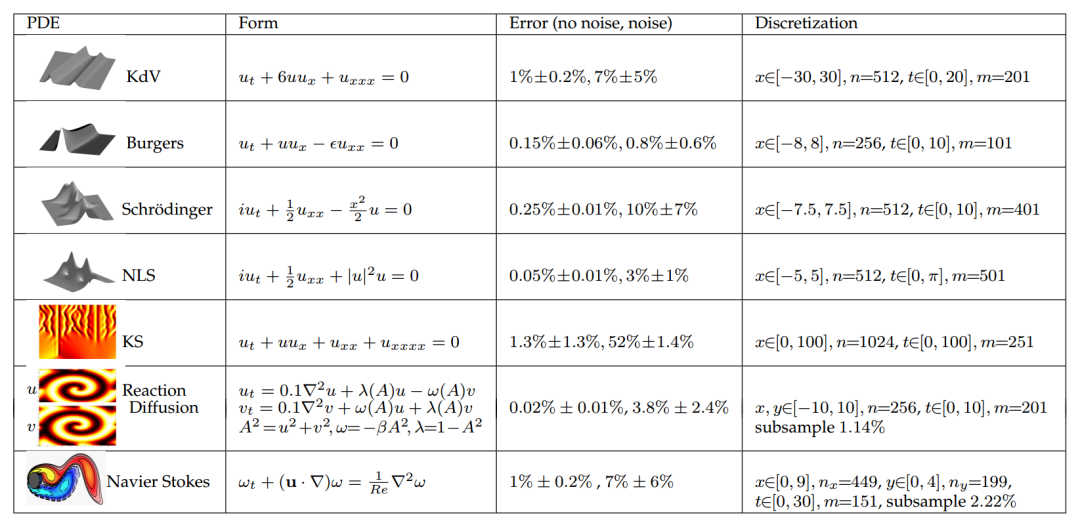
图2 实验所识别的方程
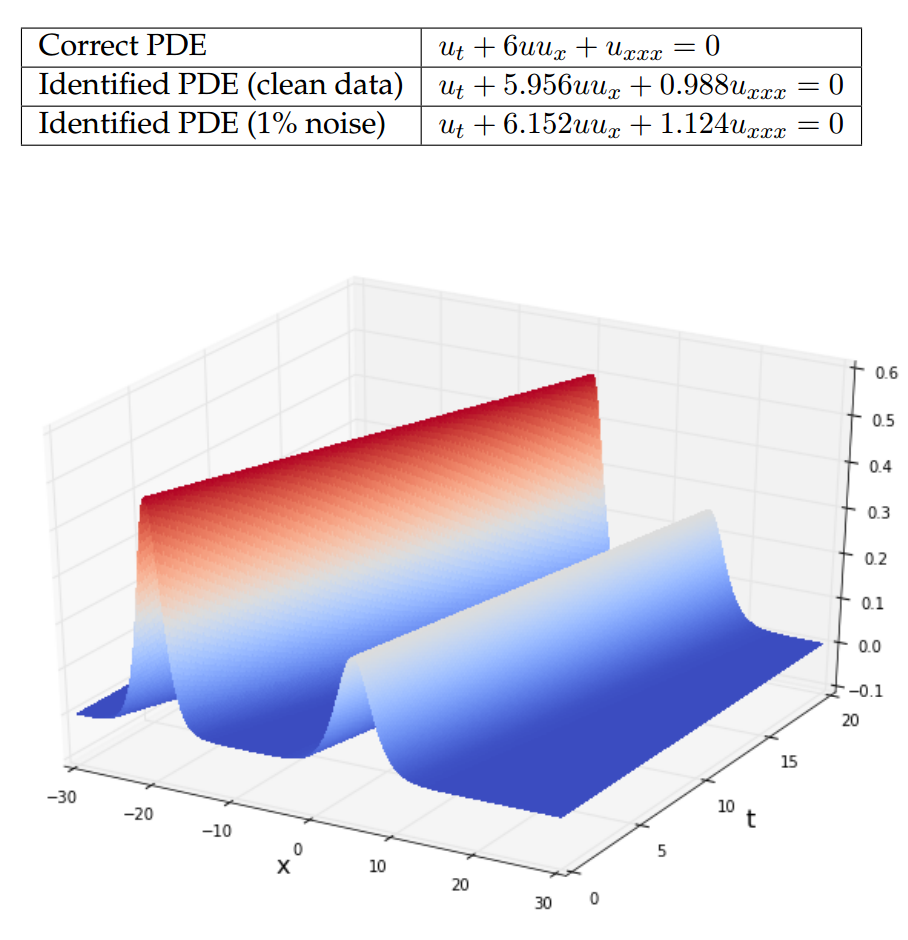
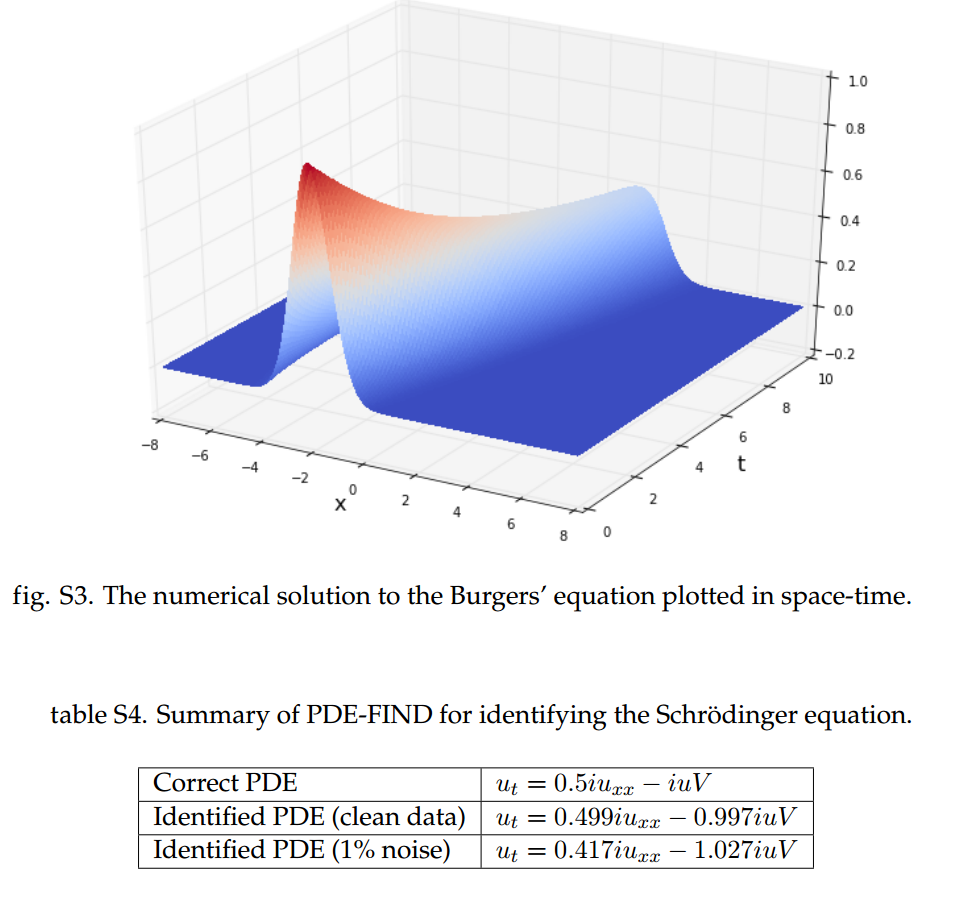
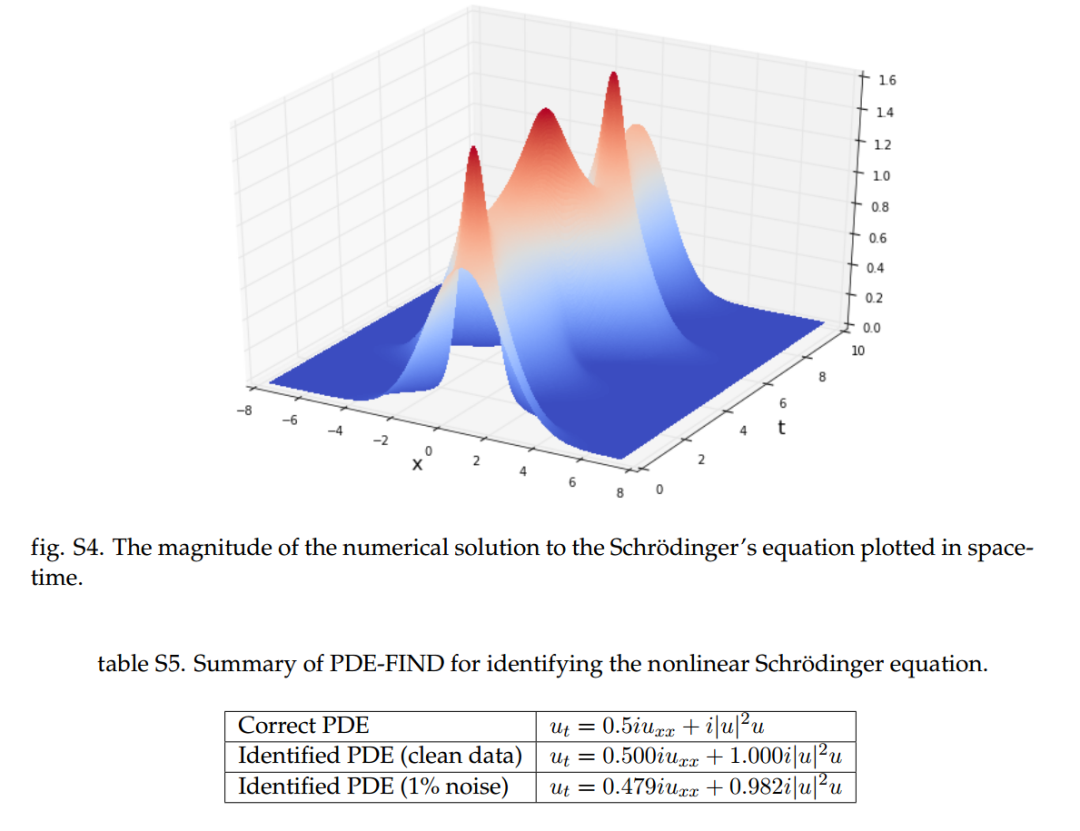
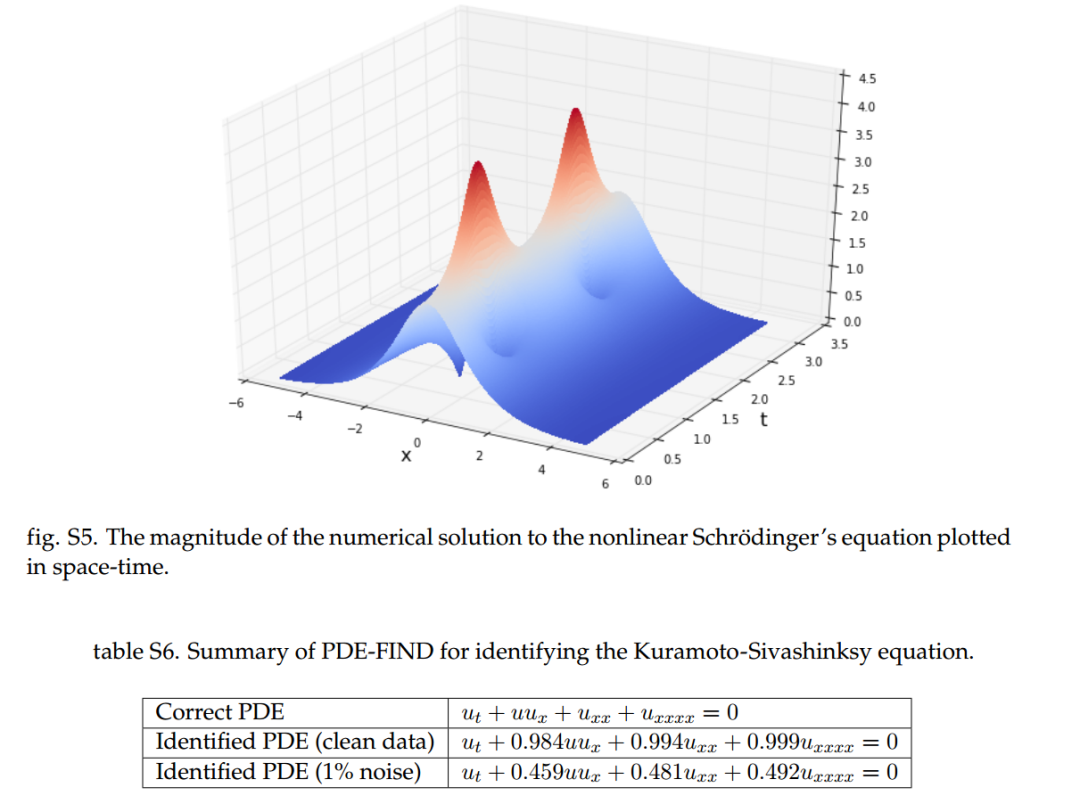
图3 实验结果

结论

PDE-FIND是一种可行的、数据驱动的现代应用工具,在第一原理推导可能是棘手的(例如,神经科学、流行病学和动态网络),但在新的数据储存和传感器技术正在彻底改变人们对空间域的物理或生物物理过程的理解。本文是第一个数据驱动的回归技术,在发现物理定律时明确地考虑了空间导数,从而显着扩大了对各种复杂系统的适用性。传统的方法,如将模型简化为基于收集数据的局部线性嵌入,无法实现研究科学家的基本目标:从观测中构建非线性模型,以表征观测动态并推广到参数空间的未采样区域。例如,我们可以发现Re = 100时的Navier-Stokes方程和特定的边界条件,并利用这些知识准确地模拟没有收集数据的新边界条件。目标是收集不同雷诺数对应的一系列流动条件下的数据,并推断参数化的Navier-Stokes方程和雷诺数。


















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











