







表情符号!
1、基线模型:Emojifier-V1
2、Emojifier-V2:在 Keras 中使用 LSTM:
将使用词向量表示来构建 Emojifier。
你有没有想过让你的短信更有表现力?您的 emojifier 应用程序将帮助您做到这一点。因此,与其写“恭喜您晋升!让我们喝杯咖啡,聊聊。爱你!“,表情符号可以自动将其变成”恭喜你晋升!👍 让我们喝杯咖啡,聊聊。☕️ 爱你!❤️"
或者,如果你对表情符号不感兴趣,但有朋友给你发了疯狂的短信,使用了太多的表情符号,你也可以使用表情符号来回击他们。
您将实现一个模型,该模型输入一个句子(例如“今晚去看棒球比赛吧!”),并找到最适合与此句子一起使用的表情符号(⚾️)。在许多表情符号界面中,您需要记住这是❤️“心”符号而不是“爱”符号。但是使用词向量,你会看到,即使你的训练集只显式地将几个单词与特定的表情符号相关联,你的算法也将能够概括测试集中的单词并将其关联到同一个表情符号,即使这些单词甚至没有出现在训练集中。这允许您构建从句子到表情符号的准确分类器映射,即使使用小型训练集也是如此。
在本练习中,您将从使用单词嵌入的基线模型 (Emojifier-V1) 开始,然后构建一个更复杂的模型 (Emojifier-V2),该模型进一步合并了 LSTM。
import numpy as np
from emo_utils import *
import emoji
import matplotlib.pyplot as plt
一、基线模型:Emojifier-V1
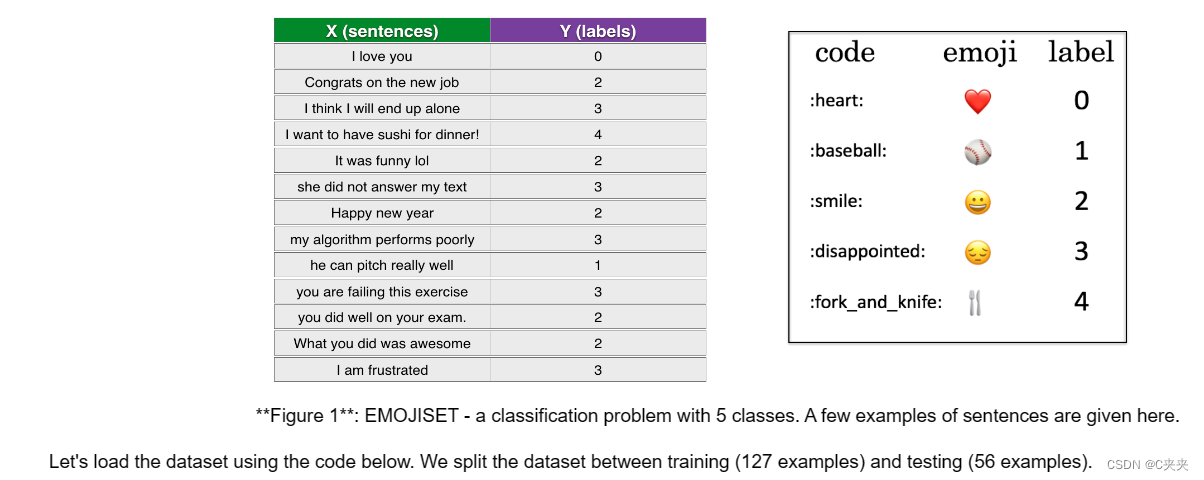
1、数据集 EMOJISET
让我们从构建一个简单的基线分类器开始。
您有一个很小的数据集 (X, Y),其中:
1、X 包含 127 个句子(字符串)
2、Y 包含一个介于 0 和 4 之间的整数标签,对应于每个句子的表情符号
X_train, Y_train = read_csv('data/train_emoji.csv')
X_test, Y_test = read_csv('data/tesss.csv')
maxLen = len(max(X_train, key=len).split())
运行以下单元格以打印来自X_train的句子和来自Y_train的相应标签。更改索引以查看不同的示例。由于 iPython 笔记本使用的字体,心形表情符号可能被涂成黑色而不是红色。
index = 1
print(X_train[index], label_to_emoji(Y_train[index]))
2、Emojifier-V1 概述
在这一部分中,您将实现一个名为“Emojifier-v1”的基线模型。

模型的输入是对应于句子的字符串(例如“我爱你)。在代码中,输出将是一个形状为 (1,5) 的概率向量,然后您传入一个 argmax 层以提取最有可能的表情符号输出的索引。
为了将我们的标签转换为适合训练 softmax 分类器的格式,让我们将 Y从其当前形状 当前形状 (m,1)变成“一热表示(m,5),其中每一行都是一个 one-hot 向量,给出一个示例的标签,您可以使用下一个代码截图器来执行此操作。在这里,Y_oh 代表变量名称 Y_oh_train 和 Y_oh_test 中的“Y-one-hot”:
Y_oh_train = convert_to_one_hot(Y_train, C = 5)
Y_oh_test = convert_to_one_hot(Y_test, C = 5)
# 看看 convert_to_one_hot() 做了什么。随意更改索引以打印出不同的值。
index = 50
print(Y_train[index], "is converted into one hot", Y_oh_train[index])
现在,所有数据都可以输入到 Emojify-V1 模型中。让我们实现模型!
3、实现 Emojifier-V1
如图(2)所示,第一步是将输入句子转换为词向量表示,然后将它们平均在一起。与前面的练习类似,我们将使用预训练的 50 维 GloVe 嵌入。运行以下单元格以加载包含所有矢量表示形式的word_to_vec_map。
word_to_index, index_to_word, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')
您已加载:
word_to_index:词典从单词到词汇表中的索引的映射(400,001 个单词,有效索引范围为 0 到 400,000)
index_to_word:从索引到词汇表中相应单词的字典映射
word_to_vec_map:字典将单词映射到其 GloVe 向量表示。
运行以下单元格以检查它是否有效。
word = "cucumber"
index = 289846
print("the index of", word, "in the vocabulary is", word_to_index[word])
print("the", str(index) + "th word in the vocabulary is", index_to_word[index])
练习:实现 sentence_to_avg()。您将需要执行两个步骤:
1、将每个句子转换为小写,然后将句子拆分为单词列表。X.lower() 和 X.split() 可能很有用。
2、对于句子中的每个单词,访问其 GloVe 表示形式。然后,对所有这些值求平均值。
将句子(字符串)转换为单词列表(字符串)。提取每个单词的 GloVe 表示形式并将其值平均为编码句子含义的单个向量。
参数:
sentence -- 字符串,来自 X 的一个训练示例
word_to_vec_map -- 字典将词汇表中的每个单词映射到其 50 维向量表示中
返回:avg -- 关于句子的平均向量编码信息,形状为 (50,) 的 numpy-array
# GRADED FUNCTION: sentence_to_avg
def sentence_to_avg(sentence, word_to_vec_map):
# Step 1: Split sentence into list of lower case words (≈ 1 line)
words = sentence.lower().split()
# Initialize the average word vector, should have the same shape as your word vectors.
avg = np.zeros((50,))
# Step 2: average the word vectors. You can loop over the words in the list "words".
for w in words:
avg += word_to_vec_map[w]
avg = avg/len(words)
return avg
avg = sentence_to_avg("Morrocan couscous is my favorite dish", word_to_vec_map)
print("avg = ", avg)

模型
您现在已经完成了实现 model() 函数的所有部分。使用 sentence_to_avg() 后,您需要通过前向传播传递平均值,计算成本,然后反向传播以更新 softmax 的参数。
练习:实现图 (2) 中描述的 model() 函数。假设这里是 Yoh(“Y one hot”) 是输出标签的 one-hot 编码,您需要在前向传递中实现并计算交叉熵成本的方程为:
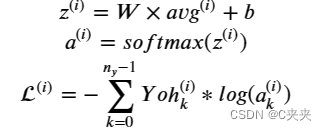
有可能提出一个更有效的矢量化实现。但是,由于我们使用 for 循环将句子一次一个地转换为 avg^{(i)} 表示,因此这次我们不要打扰。
我们为您提供了一个函数 softmax()。
在numpy中训练词向量表示的模型。
参数:
X -- 输入数据,字符串形式的句子 numpy 数组,形状为 (m, 1)
Y -- 标签,0 到 7 之间的整数的 numpy 数组,形状的 numpy 数组 (m, 1)
word_to_vec_map -- 字典将词汇表中的每个单词映射到其 50 维向量表示中
learning_rate -- 随机梯度下降算法的learning_rate
num_iterations -- 迭代次数
返回:
pred -- 预测向量,形状的 numpy-array (m, 1)
W -- softmax层的权重矩阵,形状为(n_y,n_h)
b -- Softmax层的偏置,形状为(n_y,)
# GRADED FUNCTION: model
def model(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400):
np.random.seed(1)
# Define number of training examples
m = Y.shape[0] # number of training examples
n_y = 5 # number of classes
n_h = 50 # dimensions of the GloVe vectors
# Initialize parameters using Xavier initialization
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
# Convert Y to Y_onehot with n_y classes
Y_oh = convert_to_one_hot(Y, C = n_y)
# Optimization loop
for t in range(num_iterations): # Loop over the number of iterations
for i in range(m): # Loop over the training examples
# Average the word vectors of the words from the j'th training example
avg = sentence_to_avg(X[i], word_to_vec_map)
# Forward propagate the avg through the softmax layer
z = np.dot(W, avg) + b
a = softmax(z)
# Compute cost using the j'th training label's one hot representation and "A" (the output of the softmax)
cost = -np.sum(Y_oh[i] * np.log(a))
# Compute gradients
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h))
db = dz
# Update parameters with Stochastic Gradient Descent
W = W - learning_rate * dW
b = b - learning_rate * db
if t % 100 == 0:
print("Epoch: " + str(t) + " --- cost = " + str(cost))
pred = predict(X, Y, W, b, word_to_vec_map)
return pred, W, b
print(X_train.shape)
print(Y_train.shape)
print(np.eye(5)[Y_train.reshape(-1)].shape)
print(X_train[0])
print(type(X_train))
Y = np.asarray([5,0,0,5, 4, 4, 4, 6, 6, 4, 1, 1, 5, 6, 6, 3, 6, 3, 4, 4])
print(Y.shape)
X = np.asarray(['I am going to the bar tonight', 'I love you', 'miss you my dear',
'Lets go party and drinks','Congrats on the new job','Congratulations',
'I am so happy for you', 'Why are you feeling bad', 'What is wrong with you',
'You totally deserve this prize', 'Let us go play football',
'Are you down for football this afternoon', 'Work hard play harder',
'It is suprising how people can be dumb sometimes',
'I am very disappointed','It is the best day in my life',
'I think I will end up alone','My life is so boring','Good job',
'Great so awesome'])
运行下一个单元格以训练模型并学习 softmax 参数 (W,b)。
pred, W, b = model(X_train, Y_train, word_to_vec_map)
print(pred)

4、检查测试集性能
print("Training set:")
pred_train = predict(X_train, Y_train, W, b, word_to_vec_map)
print('Test set:')
pred_test = predict(X_test, Y_test, W, b, word_to_vec_map)
Train set accuracy 97.7
Test set accuracy 85.7
鉴于有 5 个类,随机猜测的准确率为 20%。在仅对 127 个示例进行训练后,这是相当不错的性能。
在训练集中,算法看到了带有标签❤️的句子“我爱你”。但是,您可以检查训练集中是否未出现“崇拜”一词。尽管如此,让我们看看如果你写“我崇拜你”会发生什么。
X_my_sentences = np.array(["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "you are not happy"])
Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map)
print_predictions(X_my_sentences, pred)
了不起!因为 adore 具有与 love 相似的嵌入,因此该算法甚至正确地泛化到一个它以前从未见过的词。诸如heart,dear,loved或adore之类的词具有类似于love的嵌入向量,因此也可能有效—请随意修改上面的输入并尝试各种输入句子。它的效果如何?
请注意,它并没有正确地表达“你不快乐”。这种算法忽略了单词顺序,因此不擅长理解“不快乐”等短语。
打印混淆矩阵还有助于了解哪些类对模型来说更难。混淆矩阵显示标签为一个类(“实际”类)的示例被算法错误地标记为另一个类(“预测”类)的频率。
print(Y_test.shape)
print(' '+ label_to_emoji(0)+ ' ' + label_to_emoji(1) + ' ' + label_to_emoji(2)+ ' ' + label_to_emoji(3)+' ' + label_to_emoji(4))
print(pd.crosstab(Y_test, pred_test.reshape(56,), rownames=['Actual'], colnames=['Predicted'], margins=True))
plot_confusion_matrix(Y_test, pred_test)
记住的内容:
- 即使有 127 个训练示例,你也可以得到一个相当好的表情符号模型。这是由于词向量给你的泛化能力。
- Emojify-V1 在诸如 “This movie is not good and not enjoyable” 之类的句子上表现不佳,因为它无法理解单词的组合——它只是将所有单词的嵌入向量平均在一起,而不注意单词的顺序。您将在下一部分构建更好的算法。
二、Emojifier-V2:在 Keras 中使用 LSTM:
让我们构建一个 LSTM 模型,该模型将单词序列作为输入。该模型将能够考虑单词顺序。Emojifier-V2 将继续使用预先训练的单词嵌入来表示单词,但会将它们输入到 LSTM 中,LSTM 的工作是预测最合适的表情符号。
运行以下单元以加载 Keras 包。
import numpy as np
np.random.seed(0)
from keras.models import Model
from keras.layers import Dense, Input, Dropout, LSTM, Activation
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
np.random.seed(1)
from keras.initializers import glorot_uniform
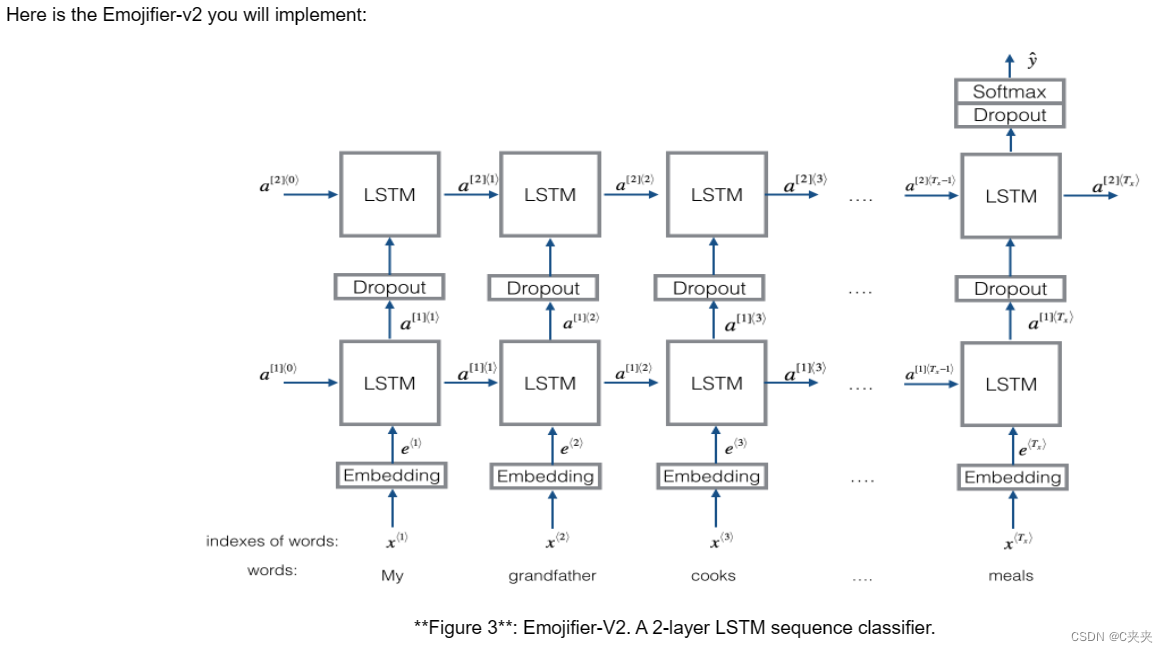
1、模型概述
2、Keras 和小型批处理
在本练习中,我们希望使用小批量训练 Keras。但是,大多数深度学习框架要求同一小批量中的所有序列具有相同的长度。这就是矢量化的工作原理:如果你有一个 3 个单词的句子和一个 4 个单词的句子,那么它们所需的计算是不同的(一个需要 LSTM 的 3 个步骤,一个需要 4 个步骤),所以不可能同时执行它们。
常见的解决方案是使用填充。具体来说,设置最大序列长度,并将所有序列填充为相同的长度。例如,在最大序列长度为 20 的情况下,我们可以用“0”填充每个句子,以便每个输入句子的长度为 20。因此,句子“我爱你”将表示为 (ei,elove,eyou,0⃗ ,0⃗ ,…,0⃗ ).在此示例中,任何超过 20 个单词的句子都必须被截断。选择最大序列长度的一种简单方法是只选择训练集中最长句子的长度。
3、嵌入层
在Keras中,嵌入矩阵表示为“层”,并将正整数(对应于单词的索引)映射到固定大小的密集向量(嵌入向量)。它可以使用预训练的嵌入进行训练或初始化。在这一部分中,您将学习如何在 Keras 中创建 Embedding() 层,并使用笔记本中之前加载的 GloVe 50 维向量对其进行初始化。由于我们的训练集非常小,因此我们不会更新单词嵌入,而是保留其值。但在下面的代码中,我们将向你展示 Keras 如何允许你训练或固定这一层。
Embedding() 层采用大小(批处理大小、最大输入长度)的整数矩阵作为输入。这对应于转换为索引(整数)列表的句子,如下图所示。
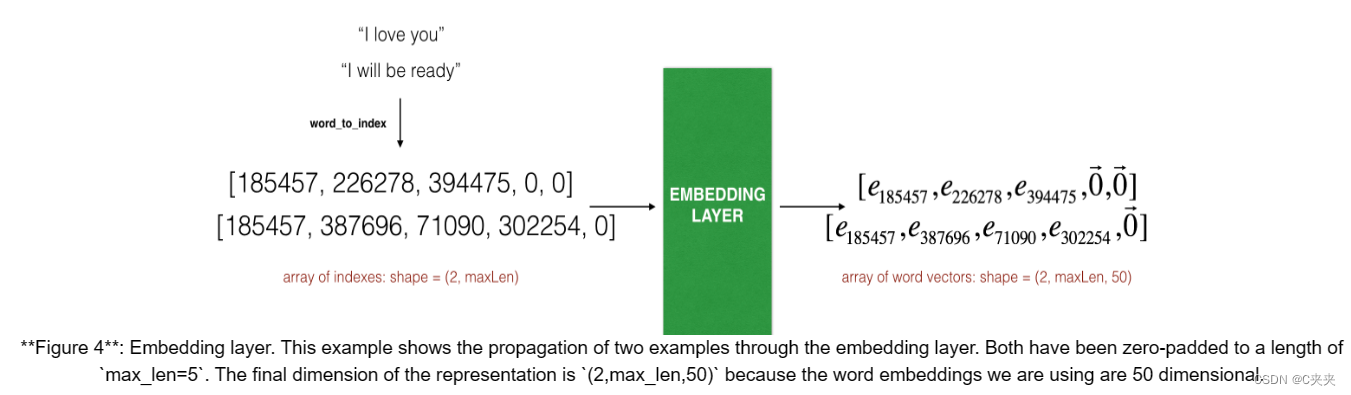
图 4:嵌入层。此示例显示了两个示例通过嵌入层的传播。两者都被零填充到“max_len=5”的长度。表示的最后一个维度(2,max_len,50)”,因为我们使用的单词嵌入是 50 维的。
输入中的最大整数(即单词索引)不应大于词汇量。该层输出一个形状数组(批量大小、最大输入长度、词向量的维度)。
第一步是将所有训练句子转换为索引列表,然后对所有这些列表进行零填充,使它们的长度是最长句子的长度。
练习:实现以下函数,将 X(字符串形式的句子数组)转换为与句子中的单词相对应的索引数组。输出形状应能够提供给 Embedding()(如图 4 所示)。
将句子数组(字符串)转换为与句子中的单词相对应的索引数组。
输出形状应设置为可以提供给 'Embedding()'(如图 4 所示)。
参数:
X -- 句子(字符串)数组,形状为 (m, 1)
word_to_index -- 包含映射到其索引的每个单词的字典
max_len -- 句子中的最大字数。您可以假设 X 中的每个句子都不超过此值
返回:X_indices -- 与 X 句子中的单词相对应的索引数组,形状为 (m, max_len)
# GRADED FUNCTION: sentences_to_indices
def sentences_to_indices(X, word_to_index, max_len):
m = X.shape[0] # number of training examples
# Initialize X_indices as a numpy matrix of zeros and the correct shape
X_indices = np.zeros((m, max_len))
for i in range(m):
# loop over training examples
# Convert the ith training sentence in lower case and split is into words. You should get a list of words.
sentence_words = X[i].lower().split()
# Initialize j to 0
j = 0
# Loop over the words of sentence_words
for w in sentence_words:
# Set the (i,j)th entry of X_indices to the index of the correct word.
X_indices[i, j] = word_to_index[w]
# Increment j to j + 1
j = j + 1
return X_indices
X1 = np.array(["funny lol", "lets play baseball", "food is ready for you"])
X1_indices = sentences_to_indices(X1,word_to_index, max_len = 5)
print("X1 =", X1)
print("X1_indices =", X1_indices)
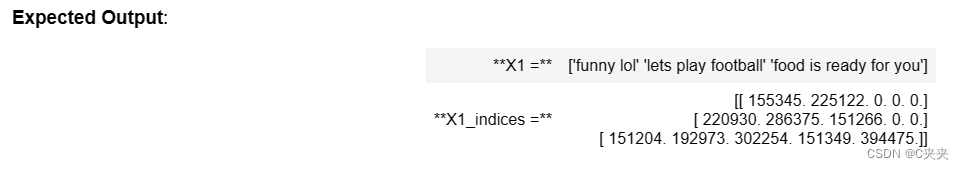
让我们使用预先训练的词向量在 Keras 中构建 Embedding() 层。构建此层后,您将 sentences_to_indices() 的输出作为输入传递给它,Embedding() 层将返回句子的单词 embeddings。
练习:实现 pretrained_embedding_layer()。您将需要执行以下步骤:
1、将嵌入矩阵初始化为具有正确形状的零的 numpy 数组。
2、使用从word_to_vec_map中提取的所有单词嵌入填充嵌入矩阵。
3、定义 Keras 嵌入层。使用 Embedding()。确保在调用 Embedding() 时设置 trainable = False,使此层不可训练。 如果要设置 trainable = True,则它将允许优化算法修改单词嵌入的值。
4、将嵌入权重设置为等于嵌入矩阵
创建一个 Keras Embedding() 层并加载预训练的 GloVe 50 维向量。
参数:
word_to_vec_map -- 字典将单词映射到其 GloVe 向量表示。
word_to_index -- 词典从单词到词汇表中的索引映射(400,001 个单词)
返回:embedding_layer -- 预训练层 Keras 实例
# GRADED FUNCTION: pretrained_embedding_layer
def pretrained_embedding_layer(word_to_vec_map, word_to_index):
vocab_len = len(word_to_index) + 1 # adding 1 to fit Keras embedding (requirement)
emb_dim = word_to_vec_map["cucumber"].shape[0] # define dimensionality of your GloVe word vectors (= 50)
# Initialize the embedding matrix as a numpy array of zeros of shape (vocab_len, dimensions of word vectors = emb_dim)
emb_matrix = np.zeros((vocab_len, emb_dim))
# Set each row "index" of the embedding matrix to be the word vector representation of the "index"th word of the vocabulary
for word, index in word_to_index.items():
emb_matrix[index, :] = word_to_vec_map[word]
# Define Keras embedding layer with the correct output/input sizes, make it trainable.
# Use Embedding(...). Make sure to set trainable=False.
embedding_layer = Embedding(vocab_len,emb_dim, trainable=False)
# Build the embedding layer, it is required before setting the weights of the embedding layer. Do not modify the "None".
embedding_layer.build((None,))
# Set the weights of the embedding layer to the embedding matrix. Your layer is now pretrained.
embedding_layer.set_weights([emb_matrix])
return embedding_layer
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
print("weights[0][1][3] =", embedding_layer.get_weights()[0][1][3])
weights[0][1][3] = -0.3403
3、构建 Emojifier-V2
现在让我们构建 Emojifier-V2 模型。您将使用您构建的嵌入层来执行此操作,并将其输出馈送到 LSTM 网络。
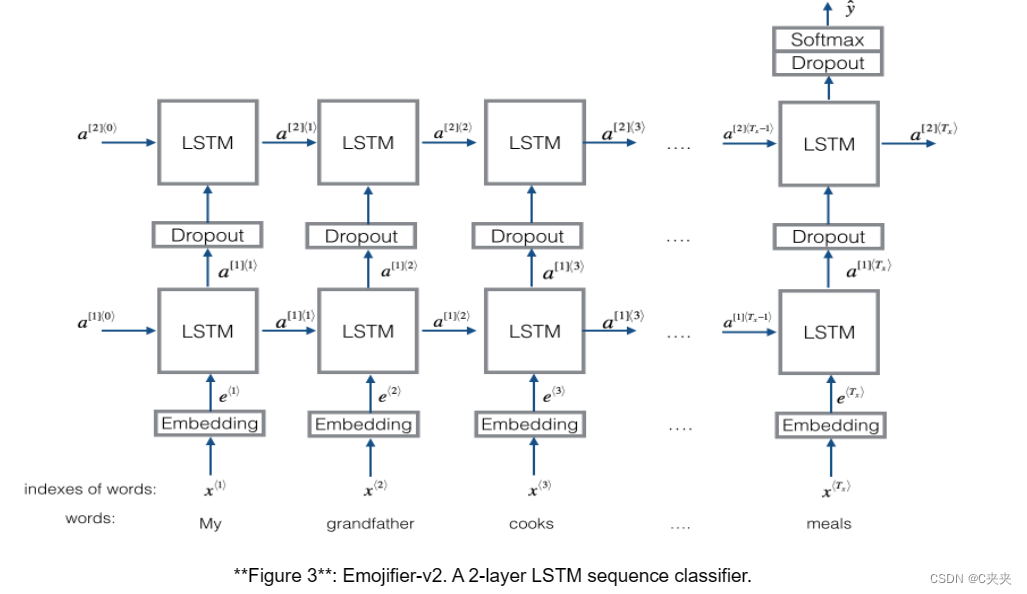
练习:实现 Emojify_V2(),它构建了图 3 所示架构的 Keras 图。该模型将由 input_shape 定义的形状为 (m, max_len, ) 的句子数组作为输入。它应该输出形状为 (m, C = 5) 的 softmax 概率向量。您可能需要 Input(shape = …, dtype = ‘…’)、LSTM()、Dropout()、Dense() 和 Activation()。
创建 Emojify-v2 模型图形的函数。
参数:
input_shape -- 输入的形状,通常为 (max_len,)
word_to_vec_map -- 字典将词汇表中的每个单词映射到其 50 维向量表示中
word_to_index -- 词典从单词到词汇表中的索引映射(400,001 个单词)
返回:model -- Keras 中的模型实例
# GRADED FUNCTION: Emojify_V2
def Emojify_V2(input_shape, word_to_vec_map, word_to_index):
# Define sentence_indices as the input of the graph, it should be of shape input_shape and dtype 'int32' (as it contains indices).
sentence_indices = Input(shape = input_shape, dtype = 'int32')
# Create the embedding layer pretrained with GloVe Vectors (≈1 line)
embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
# Propagate sentence_indices through your embedding layer, you get back the embeddings
embeddings = embedding_layer(sentence_indices)
# Propagate the embeddings through an LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a batch of sequences.
X = LSTM(128, return_sequences=True)(embeddings)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X trough another LSTM layer with 128-dimensional hidden state
# Be careful, the returned output should be a single hidden state, not a batch of sequences.
X = LSTM(128, return_sequences=False)(X)
# Add dropout with a probability of 0.5
X = Dropout(0.5)(X)
# Propagate X through a Dense layer with softmax activation to get back a batch of 5-dimensional vectors.
X = Dense(5, activation='softmax')(X)
# Add a softmax activation
X = Activation('softmax')(X)
# Create Model instance which converts sentence_indices into X.
model = Model(inputs=sentence_indices ,outputs=X)
return model
运行以下单元格以创建模型并检查其摘要。由于数据集中的所有句子都少于 10 个单词,因此我们选择了 max_len = 10。你应该看到你的架构,它使用“20,223,927”参数,其中 20,000,050(单词嵌入)是不可训练的,其余 223,877 是。因为我们的词汇量有 400,001 个单词(有效索引从 0 到 400,000),所以有 400,001*50 = 20,000,050 个不可训练的参数。
model = Emojify_V2((maxLen,), word_to_vec_map, word_to_index)
model.summary()
像往常一样,在 Keras 中创建模型后,您需要编译它并定义要使用的损失、优化器和指标。使用 categorical_crossentropy loss、adam optimizer 和 [‘accuracy’] 指标编译模型:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
是时候训练你的模型了。Emojifier-V2 模型将形状数组(m、max_len)作为输入,并输出形状(m、类数)的概率向量。因此,我们必须将X_train(作为字符串的句子数组)转换为X_train_indices(作为单词索引列表的句子数组),并将Y_train(标签作为索引)转换为Y_train_oh(标签作为单热向量)。
X_train_indices = sentences_to_indices(X_train, word_to_index, maxLen)
Y_train_oh = convert_to_one_hot(Y_train, C = 5)
在 X_train_indices 和 Y_train_oh 上拟合 Keras 模型。我们将使用 epochs = 50 和 batch_size = 32。
model.fit(X_train_indices, Y_train_oh, epochs = 50, batch_size = 32, shuffle=True)
模型在训练集上应执行接近 100% 的准确率。您获得的确切精度可能略有不同。运行以下单元格以在测试集上评估模型。
X_test_indices = sentences_to_indices(X_test, word_to_index, max_len = maxLen)
Y_test_oh = convert_to_one_hot(Y_test, C = 5)
loss, acc = model.evaluate(X_test_indices, Y_test_oh)
print()
print("Test accuracy = ", acc)
测试准确率应在 80% 到 95% 之间。运行下面的单元格以查看错误标记的示例。
# This code allows you to see the mislabelled examples
C = 5
y_test_oh = np.eye(C)[Y_test.reshape(-1)]
X_test_indices = sentences_to_indices(X_test, word_to_index, maxLen)
pred = model.predict(X_test_indices)
for i in range(len(X_test)):
x = X_test_indices
num = np.argmax(pred[i])
if(num != Y_test[i]):
print('Expected emoji:'+ label_to_emoji(Y_test[i]) + ' prediction: '+ X_test[i] + label_to_emoji(num).strip())
现在,您可以在自己的示例中尝试它。在下面写下你自己的句子。
# Change the sentence below to see your prediction. Make sure all the words are in the Glove embeddings.
x_test = np.array(['you are not happy'])
X_test_indices = sentences_to_indices(x_test, word_to_index, maxLen)
print(x_test[0] +' '+ label_to_emoji(np.argmax(model.predict(X_test_indices))))
以前,Emojify-V1 模型没有正确标记“你不开心”,但我们对 Emojiy-V2 的实现是正确的。(Keras 每次的输出都略有随机性,因此您可能没有得到相同的结果。目前的模型在理解否定(如“不快乐”)方面仍然不是很稳健,因为训练集很小,所以没有很多否定的例子。但是,如果训练集更大,LSTM 模型在理解如此复杂的句子方面会比 Emojify-V1 模型好得多。
你应该记住的:
- 如果你有一个训练集很小的 NLP 任务,使用词嵌入可以显着帮助你的算法。单词嵌入允许模型处理测试集中甚至可能没有出现在训练集中的单词。
- 在 Keras(以及大多数其他深度学习框架)中训练序列模型需要一些重要的细节:
- 要使用小批量,需要填充序列,以便小批量中的所有示例都具有相同的长度。
- 可以使用预训练值初始化“Embedding()”层。这些值可以固定,也可以在数据集上进一步训练。但是,如果您的标记数据集很小,则通常不值得尝试训练大型预训练的嵌入集。
- ‘LSTM()’ 有一个名为 ‘return_sequences’ 的标志,用于决定是要返回每个隐藏状态还是只返回最后一个状态。
- 您可以在 ‘LSTM()’ 之后使用 ‘Dropout()’ 来规范您的网络。
感谢 Alison Darcy 和 Woebot 团队对创建此任务的建议。Woebot 是一个聊天机器人朋友,随时准备 24/7 与您交谈。作为 Woebot 技术的一部分,它使用词嵌入来理解您所说的话的情绪。你可以去玩 http://woebot.io

















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









