







 这是一个关于自然语言处理的编程作业,涉及构建表情生成器。首先从基准模型Emojifier-V1开始,使用词嵌入处理数据,然后构建更复杂的Emojifier-V2模型,该模型包含LSTM。通过预训练的GloVe嵌入和Keras的LSTM,模型能够理解和预测句子的情绪,即使在训练集较小的情况下也能取得较好的泛化能力。
这是一个关于自然语言处理的编程作业,涉及构建表情生成器。首先从基准模型Emojifier-V1开始,使用词嵌入处理数据,然后构建更复杂的Emojifier-V2模型,该模型包含LSTM。通过预训练的GloVe嵌入和Keras的LSTM,模型能够理解和预测句子的情绪,即使在训练集较小的情况下也能取得较好的泛化能力。
原文链接
如果打不开,也可以复制链接到https://nbviewer.jupyter.org中打开。
自然语言处理与词嵌 Operations on word vectors 词向量运算
欢迎来到第二周的第二个编程作业。你将使用单词向量表示来构建表情生成器。
你有没有想过让你的短信更有表现力?你的emojifier应用程序将帮助你做到这一点。所以与其写“恭喜你升职了!我们喝杯咖啡聊聊天吧。“我爱你!”表情生成器可以自动将此转换为“恭喜你升职!👍 我们喝杯咖啡聊聊天吧。☕️爱你!❤️"
你将实现一个输入句子的模型(例如“我们今晚去看棒球赛吧!”)找到最合适的表情符号与这个句子一起使用(⚾️)。在许多emoji界面中,你需要记住❤️ 是“心”的象征而不是“爱”的象征。但是使用单词向量,你会发现即使你的训练集只显式地将几个单词与一个特定的表情符号相关联,你的算法也能够将测试集中的单词概括并关联到同一个表情符号,即使这些单词甚至没有出现在训练集中。这允许你构建从句子到表情的准确分类器映射,甚至使用一个小的训练集。
在本练习中,你将从使用词嵌入的基准模型(Emojifier-V1)开始,然后构建一个更复杂的模型(Emojifier-V2),该模型进一步包含了LSTM。
让我们开始了。首先加载你需要的包。
import numpy as np
from emo_utils import *
import emoji
import matplotlib.pyplot as plt
#%matplotlib inline
1-基准模型:Emojifier-V1
1.1-数据集EMOJISET
让我们从构建一个简单的基准分类器开始。
你有一个很小的数据集(X,Y)
- X:包含了127个字符串类型的短句
- Y:包含了对应短句的标签(0-4)
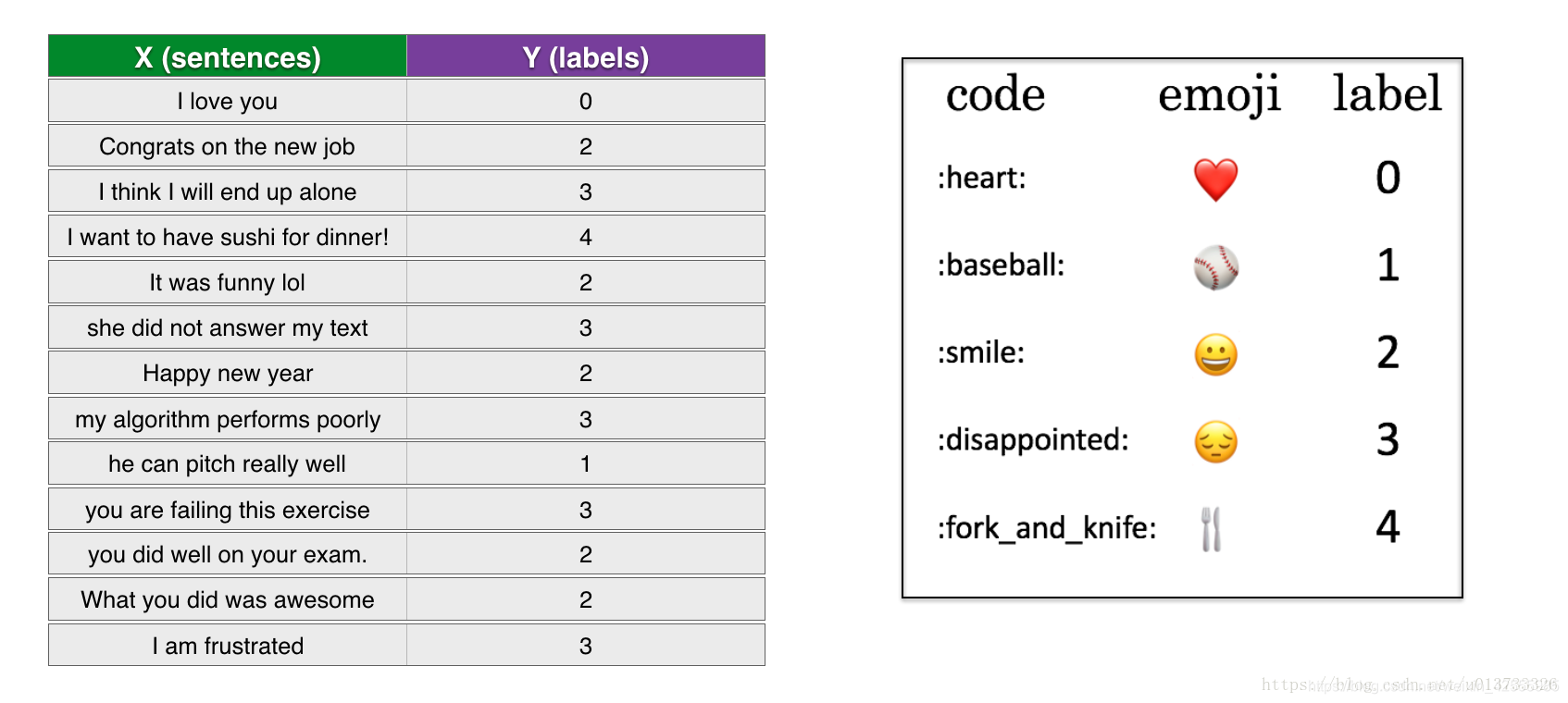
让我们使用下面的代码加载数据集。我们将数据集分为训练(127样本)和测试(56样本)。
X_train, Y_train = read_csv('data/train_emoji.csv')
X_test, Y_test = read_csv('data/tesss.csv')
maxLen = len(max(X_train, key=len).split())
运行以下代码以打印 X t r a i n X_train Xtrain中的句子和 Y t r a i n Y_train Ytrain中相应的标签。更改索引以查看不同的样本。
index = 6
print(X_train[index], label_to_emoji(Y_train[index]))
结果
Stop saying bullshit 😞
1.2-Emojifier-V1概述
在本节,你需要实现一个基准模型-Emojifier-v1。
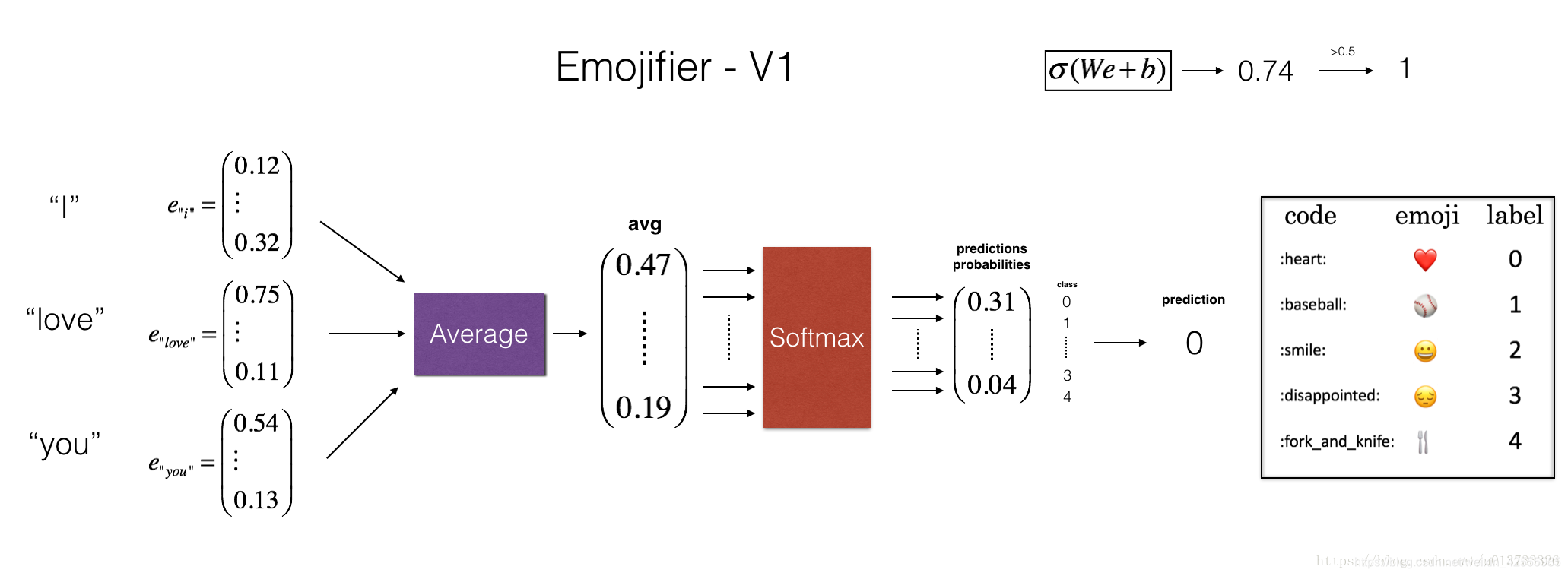
如上图,模型的输入是一个对应于一个句子的字符串(例如“我爱你”)。在代码中,输出将是形状(1,5)的概率向量,然后传入argmax层以提取最可能的emoji输出的索引。
为了使我们的标签成为适合于训练softmax分类器的格式,让我们将 Y Y Y从其当前形状current shape ( m , 1 ) (m,1) (m,1)转换为“one-hot表示” ( m , 5 ) (m,5) (m,5),其中每一行是一个one-hot向量,给出一个样本的标签,你可以使用下面的代码来执行此操作。在这里, Y o h Y_oh Yoh代表变量名 Y o h t r a i n Y_oh_train Yohtrain和 Y o h t e s t Y_oh_test Yohtest中的“Y-one-hot”:
'''
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)]
return Y
'''
Y_oh_train = convert_to_one_hot(Y_train, C = 5)
Y_oh_test = convert_to_one_hot(Y_test, C = 5)
让我们看一下convert_to_one_hot()函数做了什么。你可以尝试改变index看看不同的结果。
index = 50
print(Y_train[index], "is converted into one hot", Y_oh_train[index])
结果
0 is converted into one hot [1. 0. 0. 0. 0.]
现在所有的数据都已经准备好送入Emojify-V1模型。让我们来实现模型。
1.3-实现Emojifier-V1
如上一小节图所示,第一步是将一个输入句子转换成词向量表示法,然后求平均值。与前面的练习类似,我们将使用预训练的50维GloVe嵌入。运行以下代码以加载word_to_vec_map,其中包含所有向量表示。
word_to_index, index_to_word, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')
如果运行上面代码遇到以下报错
for line in f:
UnicodeDecodeError: 'gbk' codec can't decode byte 0x93 in position 3136: illegal multibyte sequence
解决方法和上一个练习一致。
修改emo_utils.py代码如下
import codecs
def read_glove_vecs(glove_file):
#with open(glove_file, 'r') as f:
with open(glove_file, 'r',encoding='utf-8') as f:
以下省略
完成后,你已经载入了
- word_to_index: 从单词到词汇表索引的字典类型映射(400001个单词,有效索引从0到400000)
- index_to_word: 从索引到词汇表中相应单词的字典类型映射
- word_to_vec_map: 从词汇到对应GloVe向量的字典类型的映射
运行以下代码看看是否正常运行
word = "cucumber"
index = 289846
print("the index of", word, "in the vocabulary is", word_to_index[word])
print("the", str(index) + "th word in the vocabulary is", index_to_word[index])
结果
the index of cucumber in the vocabulary is 113317
the 289846th word in the vocabulary is potatos
练习:分2步实现sentence_to_avg()函数
- 把每个句子转换为小写,然后把句子分割为列表。你可以使用X.lower() 与 X.split()。
- 对于句子中的每一个单词,转换为GloVe向量,然后对它们取平均。
代码如下
# GRADED FUNCTION: sentence_to_avg
def sentence_to_avg(sentence, word_to_vec_map):
"""
Converts a sentence (string) into a list of words (strings). Extracts the GloVe representation of each word
and averages its value into a single vector encoding the meaning of the sentence.
将句子转换为单词列表,提取其GloVe向量,然后将其平均。
Arguments:
sentence -- string, one training example from X 字符串类型,从X中获取的样本。
word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
字典类型,单词映射到50维的向量的字典
Returns:
avg -- average vector encoding information about the sentence, numpy-array of shape (50,)
对句子的均值编码,维度为(50,)
"""
### START CODE HERE ###
# Step 1: Split sentence into list of lower case words (≈ 1 line)
# 第一步:分割句子,转换为列表。
words = sentence.lower().split()
# Initialize the average word vector, should have the same shape as your word vectors.
# 初始化均值词向量
avg = np.zeros(50,)
# Step 2: average the word vectors. You can loop over the words in the list "words".
# 第二步:对词向量取平均。
for w in words:
avg += word_to_vec_map[w]
avg = np.divide(avg, len(words))
### END CODE HERE ###
return avg
测试一下
avg = sentence_to_avg("Morrocan couscous is my favorite dish", word_to_vec_map)
print("avg = ", avg)
结果
avg = [-0.008005 0.56370833 -0.50427333 0.258865 0.55131103 0.03104983
-0.21013718 0.16893933 -0.09590267 0.141784 -0.15708967 0.18525867
0.6495785 0.38371117 0.21102167 0.11301667 0.02613967 0.26037767
0.05820667 -0.01578167 -0.12078833 -0.02471267 0.4128455 0.5152061
0.38756167 -0.898661 -0.535145 0.33501167 0.68806933 -0.2156265
1.797155 0.10476933 -0.36775333 0.750785 0.10282583 0.348925
-0.27262833 0.66768 -0.10706167 -0.283635 0.59580117 0.28747333
-0.3366635 0.23393817 0.34349183 0.178405 0.1166155 -0.076433
0.1445417 0.09808667]
模型
现在你已经完成了实现model()函数的所有步骤。在使用sentence_to_avg()之后,你需要通过前向传播传递平均值,计算成本,然后反向传播来更新softmax的参数。
练习:实现上一节图中的model()函数。这里假设 Y o h Yoh Yoh(“Y one hot”)是输出标签的one hot编码,则需要在前向传播中实现并计算交叉熵代价的等式为:
z ( i ) = W × a v g ( i ) + b (2-1) z^{(i)}=W×avg^{(i)}+b\tag{2-1} z(i)=W×avg(i)+b(2-1)
a ( i ) = s o f t m a x ( z ( i ) ) (2-2) a^{(i)} = softmax(z^{(i)}) \tag{2-2} a(i)=softmax(z(i))(2-2)
L ( i ) = − ∑ k = 0 n y −
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









