






世界模型(World Model)是人工智能算法模型的一种新概念,旨在模仿人类和动物通过观察与交互自然地学习关于世界运作方式的知识。
这一理念由深度学习之父杨丽坤Yann LeCun提出,作为通往通用人工智能(AGI)的路径之一。
不同于以大数据和大算力驱动的Transformer流派,世界模型学派认为实现AGI需要AI具备真正的常识性的理解能力,这些能力只能通过对世界的内在表征来获得。
世界模型的核心在于它能够估计感知未提供的世界状态信息,并预测未来可能的状态变化,比如基于Actor模块提出的动作序列所导致的世界状态变化。这种模型不仅需要处理大量的照片、音频、视频和文本数据,还需要具备推理行动后果的能力,从而更真实地反映现实世界中的物理规则和因果关系。例如,在模拟篮球的真实弹跳时,一个具有基本物理认知的世界模型会比传统生成式模型提供更加精确的结果。
然而,构建这样的世界模型面临诸多挑战,包括巨大的计算需求、模型的幻觉问题以及内化训练数据中的偏见等。此外,如何让这些模型能够进行反事实推理,即假设环境中的某些因素发生变化后结果会如何不同,也是研究者们正在探索的方向。尽管如此,世界模型为实现更高级别的智能提供了有希望的研究途径,尤其是在强化学习和机器人技术等领域中,它们被用来提高智能体在复杂动态环境中的表现。
当AI领域中讲到 世界/world、环境/environment 这个词的时候,通常是为了与 智能体/agent 加以区分。研究智能体最多的领域,一个是强化学习,一个是机器人领域。因此可以看到,world models、world modeling最早也最常出现在机器人领域的论文中。
通用智能的两个流派
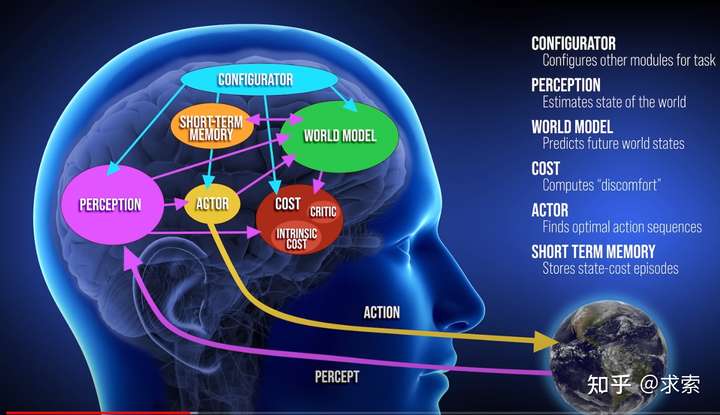
通往通用智能之路,目前有两个流派。 一个是以OpenAI为代表的Transformer学派,通过大数据大参数大算力以自回归的方式走向通用人工智能,最近发布的Sora体现的涌现能力初步隐含着通用人工智能的韵味,期待GPT-5能够更上一层楼,让我们在有生之年看到AGI。 另外一个流派是以杨立昆(Yann LeCun)为代表的世界模型学派,这一学派认为自回归的Transformer是无法通往AGI。Yann LeCun认为,人类和动物能够通过观察,简单的交互,以及无监督的方式学习世界知识,这蕴含的潜在能力构成了常识的基础。这种常识能够让人类在陌生的环境下完成任务。基于世界模型,Yann LeCun提出了自主智能系统的体系架构,包含6个核心模块,配置器(Configurator)是协调指挥中心,负责协调、配置和执行其他模块;感知(Perception)针对给定的任务,由配置器调用,感知世界状态和提取任务相关信息;世界模型(World Model)主要的职责是估计Perception未提供的关于世界状态的缺失信息,并预测合理的未来世界状态,比如预测由 Actor 模块提出的一系列动作所导致的未来世界状态;角色(Actor)负责寻找最优的行动方案;成本(Cost)负责计算智能体的不适值(discomfort),目标是最小化内在成本的未来值;短期记忆(Short Term Memory)负责跟踪当前和预测的世界状态以及相关成本。
添加图片注释,不超过 140 字(可选)
世界模型(world models)
今天world models这个词影响最大的,可能是Jurgen 2018年放到arxiv的这篇以“world models”命名的文章,该文章最终以 “Recurrent World Models Facilitate Policy Evolution”的title发表在NeurIPS‘18。

添加图片注释,不超过 140 字(可选)
该论文中并没有定义什么是World models,而是类比了认知科学中人脑的mental model,引用了1971年的文献。

mental model是人脑对周边世界的镜像
mental model
Wikipedia中介绍的mental model,很明确的指出其可能参与认知、推理、决策过程。并且说到 mental model 主要包含mental representations 和 mental simulation 两部分。
an internal representation of external reality, hypothesized to play a major role in cognition, reasoning and decision-making. The term was coined by Kenneth Craik in 1943 who suggested that the mind constructs "small-scale models" of reality that it uses to anticipate events.
到这里还是说得云雾缭绕,那么论文中的结构图一目了然的说明了什么是一个world model
添加图片注释,不超过 140 字(可选)
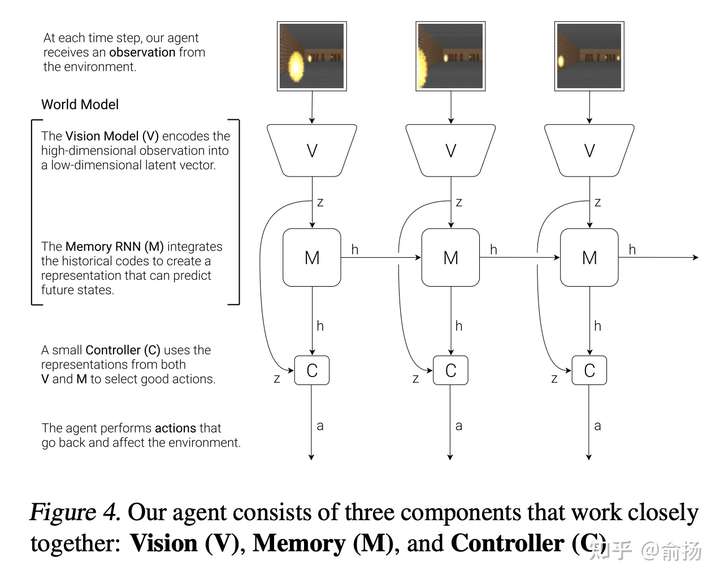
图中纵向V->z是观测的低维表征,用VAE实现,水平的M->h->M->h是序列的预测下一个时刻的表征,用RNN实现,这两部分加起来就是World Model。
也就是说,World model的主要包含状态表征和转移模型,这也正好对应mental representations 和 mental simulation。
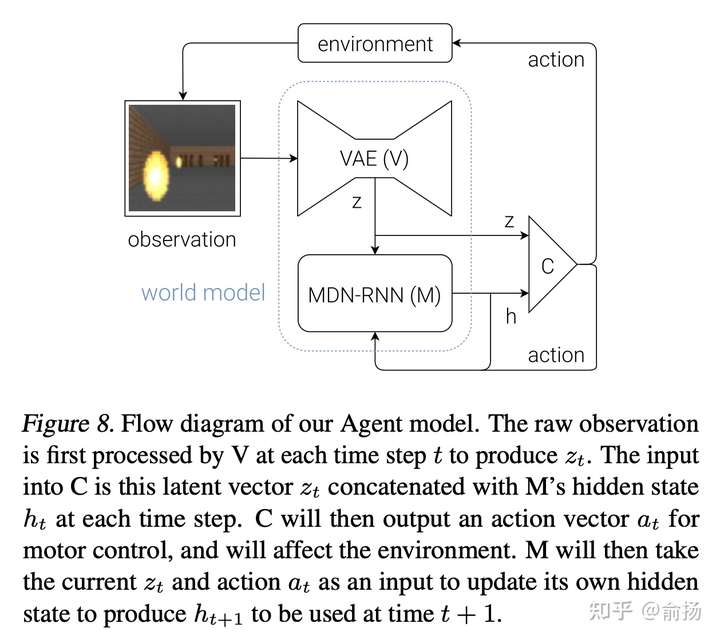
看到上面这张图可能会想,这不是所有的序列预测都是world model了?其实熟悉强化学习的同学能一眼看出来,这张图的结构是错误(不完整)的,而真正的结构是下面这张图,RNN的输入不仅是z,还有动作action,这就不是通常的序列预测了(加一个动作会很不一样吗?是的,加入动作可以让数据分布自由变化,带来巨大的挑战)。
添加图片注释,不超过 140 字(可选)
Jurgen的这篇论文属于强化学习领域。那么,强化学习里不是有很多model-based RL吗,其中的model跟world model有什么区别?答案是没有区别,就是同一个东西。Jurgen先说了一段

基本意思就是,不管有多少model-based RL工作,我是RNN先驱,RNN来做model是我发明的,我就是要搞。
在Jurgen文章的早期版本中,还说到很多 model-based RL,虽然学了model,但并没有完全在model中训练RL。

添加图片注释,不超过 140 字(可选)
没有完全在model中训练RL,实际上并不是model-based RL的model有什么区别,而是model-based RL这个方向长久以来的无奈:model不够准确,完全在model里训练的RL效果很差。这一问题直到近几年才得到解决。
聪明的Sutton在很久以前就意识到model不够准确的问题。在1990年提出Dyna框架的论文Integrated Architectures for Learning, Planning and Reacting based on Dynamic Programming(发表在第一次从workshop变成conference的ICML上),管这个model叫action model,强调预测action执行的结果。RL一边从真实数据中学习(第3行),一边从model中学习(第5行),以防model不准确造成策略学不好。

添加图片注释,不超过 140 字(可选)
世界模型的分类
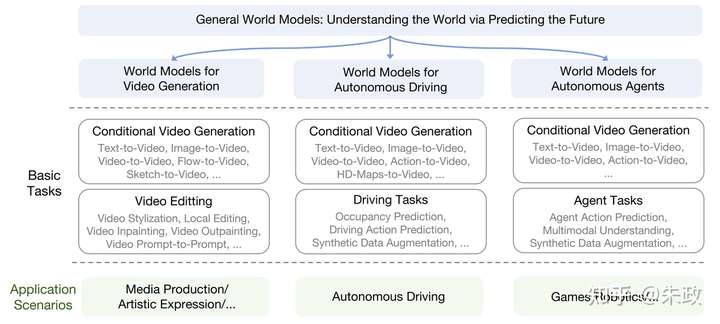
从预测未来的角度给出了世界模型的统一定义,并在下图中介绍了视频生成、自动驾驶、通用智能体和机器人领域世界模型的应用情况:
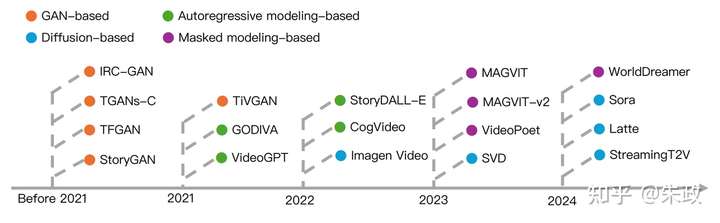
在视频生成领域,有多种流行的生成方法,包括GAN、扩散模型、自回归、掩码建模等,从下图的时间轴研究进展来看,进入2024年,基于扩散模型的方法占据了主导地位,Sora也是采用了扩散模型作为基础生成方法。
添加图片注释,不超过 140 字(可选)
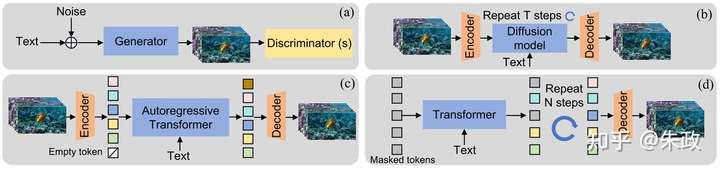
(a)GAN (b)扩散模型 (c)自回归(d)掩码建模
在综述中,我们也根据OpenAI的技术报告,分析了Sora的基本结构,并从训练数据、架构、效率等方面讨论了为什么Sora有成为世界模拟器的潜力。
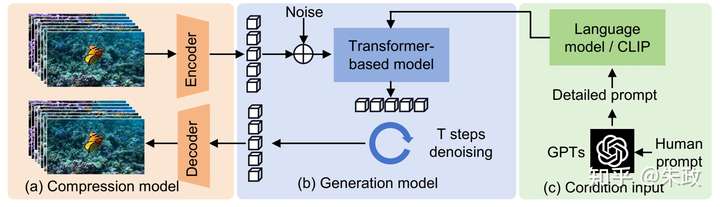
添加图片注释,不超过 140 字(可选)
除了视频生成领域,在自动驾驶中,世界模型在最近两年也是常见词,从下图中可以看出,2023和2024年集中出现了一批基于世界模型的端到端模型、2D/3D生成方法:
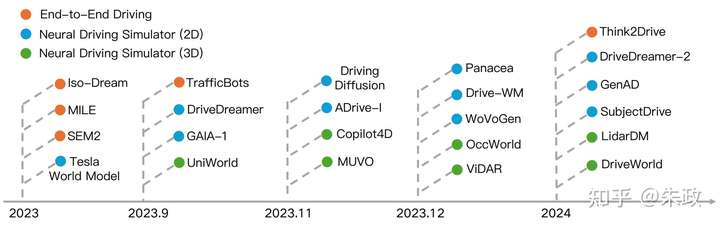
添加图片注释,不超过 140 字(可选)
同时,在通用智能体和机器人领域,基于世界模型的相关研究更是层出不穷,RSSM、Transformer、JEPA、Diffusion各自都有不少工作。其中,JEPA是LeCun力推的算法,他也多次在演讲中表示对世界模型潜力的极大关注,并预言世界模型将会取代自回归模型成为新一代智能系统的基础。
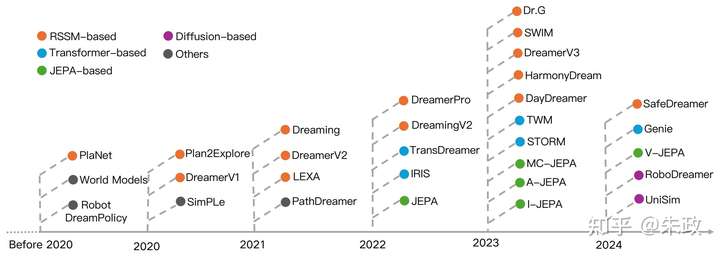
添加图片注释,不超过 140 字(可选)
因为世界模型是一个新兴领域的研究,尚存在这许多问题和挑战,我们在综述的最后一部分也对此进行了讨论和分析,涵盖了以下方面:因果和反事实推理、模拟物理定律、泛化能力、计算效率和性能评估等;同时,综述也展望了世界模型未来的发展方向,希望能给业界的相关研究贡献一点见解。
world model与决策
可以看到,world model对于决策十分重要。如果能获得准确的world model,那就可以通过在world model中就反复试错,找到现实最优决策。
这就是world model的核心作用:反事实推理/Counterfactual reasoning , 也就是说,即便对于数据中没有见过的决策,在world model中都能推理出决策的结果。
了解因果推理的同学会很熟悉反事实推理这个词,在图灵奖得主Judea Pearl的科普读物The book of why中绘制了一副因果阶梯,最下层是“关联”,也就是今天大部分预测模型主要在做的事;中间层是“干预”,强化学习中的探索就是典型的干预;最上层是反事实,通过想象回答 what if 问题。Judea为反事实推理绘制的示意图,是科学家在大脑中想象,这与Jurgen在论文中用的示意图异曲同工。
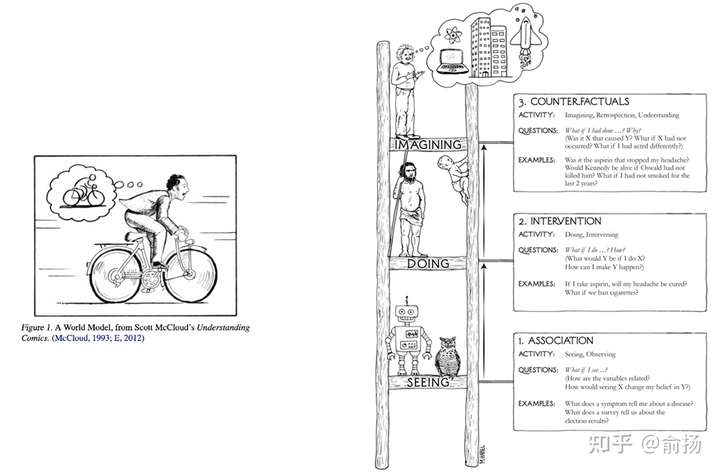
左:Jurgen论文中的世界模型示意图。右:Judea书中的因果阶梯。
到这里我们可以总结,AI研究人员对world model的追求,是试图超越数据,进行反事实推理,回答what if问题能力的追求。这是一种人类天然具备,而当前的AI还做得很差的能力。一旦产生突破,AI决策能力会大幅提升,实现全自动驾驶等场景应用。
世界模型的应用
预测未来的角度给出了世界模型的统一定义,并在下图中介绍了视频生成、自动驾驶、通用智能体和机器人领域世界模型的应用情况:
添加图片注释,不超过 140 字(可选)
因为世界模型是一个新兴领域的研究,尚存在这许多问题和挑战,我们在综述的最后一部分也对此进行了讨论和分析,涵盖了以下方面:因果和反事实推理、模拟物理定律、泛化能力、计算效率和性能评估等;同时,综述也展望了世界模型未来的发展方向,希望能给业界的相关研究贡献一点见解。
世界模型与空间智能的差别
世界模型是指常数类的视觉建模,到物理机理。世界模型侧重于虚拟现实;
空间智能是指利用人工智能理解视频中空间的逻辑与关系。空间智能侧重于理解现实并做出反应。
LWM
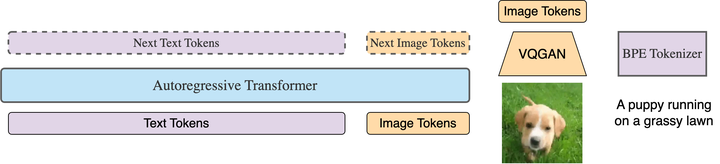
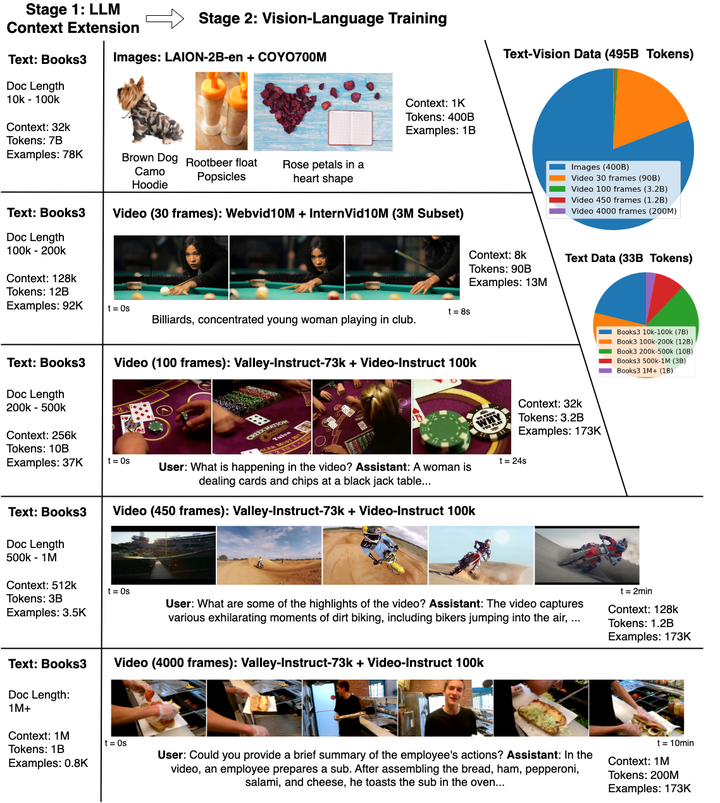
LWM提出了一种能够处理百万长度序列的模型架构和训练方法。LWM基于Transformer架构,并采用了Blockwise RingAttention技术,这种技术能够在不牺牲计算效率的情况下,显著扩展模型的上下文窗口。具体来说,Blockwise RingAttention通过将序列划分为多个块,并在块之间进行高效的注意力计算,从而避免了传统注意力机制中计算复杂度随序列长度平方增长的问题。这种方法使得模型能够在有限的计算资源下,处理长达百万个token的序列。
在训练过程中,作者采用了逐步扩展上下文长度的策略。模型从处理较短的序列(如32K tokens)开始,逐步增加到1M tokens。这种逐步训练的方法不仅有助于模型更好地学习长距离依赖关系,还能够有效降低训练成本。此外,为了增强模型在长文本和长视频上的理解能力,作者还设计了一个模型生成问答数据集,通过让模型生成问题和答案对,来模拟长文本对话场景,进一步提升了模型的长上下文理解能力。
添加图片注释,不超过 140 字(可选)
模型的多模态能力
LWM不仅在长文本处理上取得了突破,还在视频理解任务中展现了强大的能力。通过将视频帧转化为离散的token,并与文本token一起输入到模型中,LWM能够同时处理文本和视频内容。这种多模态的设计使得模型能够在长视频中检索关键信息,并回答与视频内容相关的问题。例如,在处理长达一小时的视频时,LWM能够准确地回答关于视频中某个特定场景的问题,这在以往的模型中是很难实现的。
在长文本检索任务中,LWM能够在百万长度的上下文中准确地找到关键信息,其性能远超现有的语言模型。在长视频理解任务中,LWM也展现了强大的能力,能够在处理大量视频帧的同时,准确地回答与视频内容相关的问题。这些结果表明,LWM不仅在理论上能够处理百万长度的序列,而且在实际应用中也具有很高的效率和准确性。
添加图片注释,不超过 140 字(可选)
从应用前景来看,LWM的出现为人工智能在长文本和长视频领域的应用开辟了新的可能性。例如,在教育领域,LWM可以帮助学生更好地理解和分析长篇学术论文或文学作品;在娱乐领域,LWM可以用于视频内容的智能推荐和分析,帮助用户更快地找到他们感兴趣的视频片段。此外,LWM的多模态能力也为开发更加智能的人机交互系统提供了技术支持,例如智能客服、虚拟助手等。
Sora是不是 world simulator?
simulator这个词更多出现在工程领域,起作用与world model一样,尝试那些难以在现实世界实施的高成本高风险试错。OpenAI似乎希望重新组成一个词组,但意思不变。
Sora生成的视频,仅能通过模糊的提示词引导,而难以进行准确的操控。因此它更多的是视频工具,而难以作为反事实推理的工具去准确的回答what if问题。
甚至难以评价Sora的生成能力有多强,因为完全不清楚demo的视频与训练数据的差异有多大。
更让人失望的是,这些demo呈现出Sora并没有准确的学到物理规律。已经看到有人指出了Sora生成视频中不符合物理规律之处[ OpenAI 发布文生视频模型 Sora,AI 能理解运动中的物理世界,这是世界模型吗?意味着什么? ]
我猜测OpenAI放出这些demo,应该基于非常充足的训练数据,甚至包括CG生成的数据。然而即便如此那些用几个变量的方程就能描述的物理规律还是没有掌握。OpenAI认为Sora证明了一条通往simulators of the physical world的路线,但看起来简单的堆砌数据并不是通向更高级智能技术的道路。
Sora技术实现
Sora主要是利用了Diffusion和Transformer模型
首先是Diffusion模型,也叫扩散模型,它的原理是给一张图片加噪声,再把加了噪声的图片还原回去,AI学会了这种加噪/去噪的方法来生成我们想要的图片。
transformer是一个模型,主要用来捕捉全局,这两个模型各有优缺点,Diffusion注重细节,可以生成精美图片,transformer更擅长掌控全局。
V-JEPA
Meta在OpenAI发布Sora的当天发布了V-JEPA(视频联合嵌入预测架构,Video Joint Embedding Predictive Architecture)。这个架构是基于Yann LeCun的世界模型和自主智能体设计的。Meta认为这是通向先进机器智能(Advancing Machine Intelligence)的关键一步。 Meta 副总裁兼首席 AI 科学家 Yann LeCun 表示: “V-JEPA 是朝着更扎实地理解世界迈出的一步,因此机器可以实现更通用的推理和规划,”他在 2022 年提出了最初的联合嵌入预测架构(JEPA)。“我们的目标是构建先进的机器智能,可以像人类一样学习更多知识,形成周围世界的内部模型,以有效地学习、适应和制定计划,以完成复杂的任务。” V-JEPA 是一种非生成模型,它通过预测抽象表示空间中视频的缺失或屏蔽部分来学习。这类似于之前的图像联合嵌入预测架构 (I-JEPA)比较图像的抽象表示(而不是比较像素本身)的方式。与试图填补每个缺失像素的生成方法不同,V-JEPA 可以灵活地丢弃不可预测的信息,从而将训练和样本效率提高1.5倍到6倍。 由于V-JEPA采用自监督学习方法,因此完全使用未标记的数据进行预训练。标签仅用于在预训练后使模型适应特定任务。事实证明,这种类型的架构比以前的模型更有效,无论是在所需的标记示例数量方面,还是在学习未标记数据时所投入的总工作量方面。借助 V-JEPA,在这两个方面都看到了效率的提升。 使用V-JEPA,模型只显示了一小部分上下文,而遮掩了视频的大部分内容。然后,要求预测器填补缺失的空白——不是根据实际像素,而是作为这个表示空间中更抽象的描述。
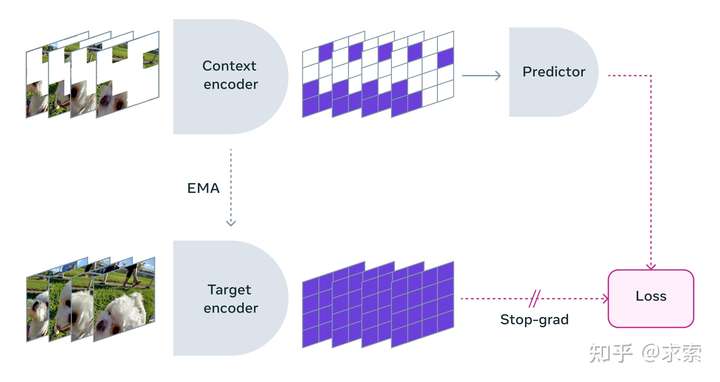
添加图片注释,不超过 140 字(可选)
遮掩策略(Masking Strategy) V-JEPA没有接受过理解特定类型动作的训练。取而代之的是,它对一系列视频进行了自监督训练,并学习了许多关于世界如何运作的事情。该团队还仔细考虑了遮掩(masking)策略——如果你不遮掩视频的大面积区域,而是随机采样补丁,就会使任务变得过于简单,你的模型不会学到世界的特殊复杂信息。 同样重要的是要注意,大多数视频变化有些缓慢,如果你遮掩了视频的一部分,但只在特定的瞬间,模型可以看到之前和/或之后的内容,由于变化缓慢,模型几乎学不到任何有趣的东西。因此,该团队使用了一种方法,在空间和时间上都掩盖了视频的某些部分,这迫使模型学习并发展对场景的理解。 高效预测 在抽象表示空间中进行这些预测非常重要,因为它允许模型专注于视频所包含内容的更高层次的概念信息,而不必关注下游任务不重要的细节类型。毕竟,如果视频显示一棵树,您并不关心每片叶子的微小运动。 V-JEPA是第一个擅长“冻结评估”的视频模型,这意味着我们在编码器和预测器上进行了所有自监督的预训练,而不再人为触碰模型的这些部分。如果想让他们学习一项新技能时,只是在上面训练一个小型的轻量级专用层或一个小网络,这是非常高效和快速的。
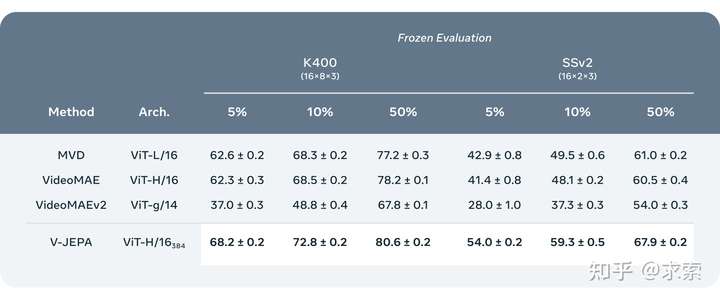
添加图片注释,不超过 140 字(可选)
传统大模型如果要适应新的任务必须进行全面的微调,这意味着在预训练模型之后,当您希望调整模型以承担该任务时非常擅长细粒度动作识别时,您必须更新所有模型中的参数或权重。这个模型整体上变得专门用于完成一项任务,它不再擅长其他事情。如果要向模型传授不同的任务,则必须使用不同的数据,并且将整个模型专门用于该任务。使用 V-JEPA,我们可以在没有任何标记数据的情况下对模型进行一次预训练,修复它,然后将模型的相同部分重用于几个不同的任务,例如动作分类、细粒度对象交互的识别和活动定位。
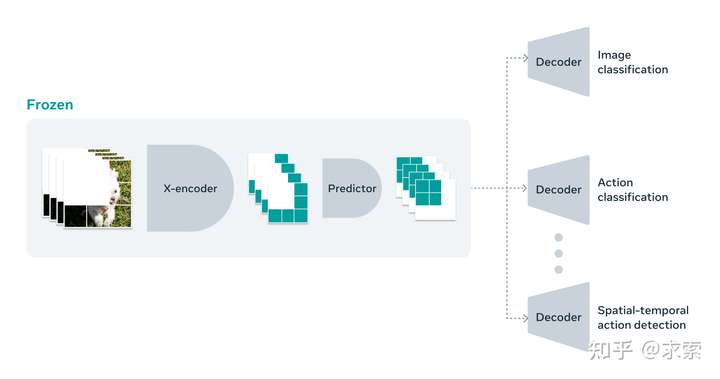
添加图片注释,不超过 140 字(可选)
未来研究的途径
虽然V-JEPA中的“V”代表“视频”,但它只考虑了迄今为止视频的视觉内容。接下来考虑将音频与视觉效果相结合。 作为概念验证,当前的 V-JEPA 模型擅长细粒度对象交互,并区分随时间变化的对象到对象交互。例如,如果模型需要能够区分某人放下笔、拿起笔和假装放下笔但实际上并没有放下笔,那么与以前用于高级动作识别任务的方法相比,V-JEPA 是相当不错的。然而,这些事情只是相对较短的时间尺度上起作用。如果你向 V-JEPA 展示几秒钟的视频剪辑,可能长达10秒,那很适合。因此,另一个重要的步骤是考虑模型在更长的时间范围内进行预测的能力。
通往 AMI 的道路
迄今为止,V-JEPA主要是关于感知的——理解各种视频流的内容,以便获得关于我们周围世界的一些背景。这个联合嵌入预测架构中的预测器可以作为早期的物理世界模型:你不必看到框架中发生的一切,它可以从概念上告诉你那里发生了什么。下一步,应该是如何使用这种预测变量或世界模型进行规划或决策。 在不需要严格监督的情况下,可以在视频数据上训练 JEPA 模型,并且它们可以像婴儿一样观看视频——只是被动地观察世界,学习很多关于如何理解这些视频上下文的有趣事情,这样,使用少量标记数据,您可以快速获得新任务和识别不同操作的能力。 V-JEPA是一个研究模型,可以去探索一些未来的应用。例如,我们希望 V-JEPA 提供的上下文对我们的具身 AI 工作以及我们为未来的 AR 眼镜构建上下文 AI 助手的工作有用。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









