






【摘要】
在计算机视觉领域,设计计算高效的网络架构仍然是一项持续的必要任务。本文将状态空间语言模型Mamba应用于具有线性时间复杂度的视觉骨干VMamba。VMamba的核心是带有2D选择性扫描(SS2D)模块的视觉状态空间(VSS)块堆栈。SS2D通过沿着四条扫描路线遍历,弥合了1D选择性扫描的有序性和2D视觉数据的非顺序结构之间的差距,这有助于从各种来源和角度收集上下文信息。基于VSS块,我们开发了一系列VMamba架构,并通过一系列架构和实现增强来加速它们。大量实验表明,VMamba在各种视觉感知任务中表现良好,与现有的基准模型相比,其输入缩放效率更高。源代码可在https://github.com/MzeroMiko/VMamba。
简介
视觉表征学习仍然是计算机视觉的一个基础研究领域,在深度学习时代取得了显著进展。为了表示视觉数据中的复杂模式,已经提出了两类主要的骨干网络,即卷积神经网络(CNN)[49,27,29,53,37]和视觉变换器(ViTs)[13,36,57,66],并在各种视觉任务中得到了广泛的应用。与CNN相比,ViTs通常在大规模数据上表现出更优的学习能力,因为它们整合了自我注意机制[58,13]。然而,自我注意力相对于令牌数量的二次复杂性在涉及大空间分辨率的下游任务中带来了巨大的计算开销。
为了应对这一挑战,已经做出了重大努力来提高注意力计算的效率[54,36,12]。然而,现有的方法要么限制了有效感受野的大小[36],要么在各种任务中表现明显下降[30,60]。这促使我们开发一种新的视觉数据架构,同时保持香草式自我注意机制的固有优势,即全局感受野和动态加权参数[23]。
最近,Mamba[17]是自然语言处理(NLP)领域的一种创新状态空间模型(SSM)[17,43,59,71,48],已成为一种有前景的线性复杂长序列建模方法。从这一进步中汲取灵感,我们介绍了VMamba,这是一种视觉骨干,集成了基于SSM的块,以实现高效的视觉表示学习。然而,Mamba的核心算法,即并行选择性扫描操作,本质上是为处理一维序列数据而设计的。当将其应用于处理视觉数据时,这带来了挑战,因为视觉数据缺乏视觉组件的固有顺序排列。为了解决这个问题,我们提出了2D选择性扫描(SS2D),这是一种为空间域遍历设计的四向扫描机制。与自我关注机制相反(图1(a)),SS2D使得每个图像块仅通过沿其相应扫描路径计算的压缩隐藏状态来获取上下文知识(图1(b)),从而将计算复杂度从二次型降低到线性型。
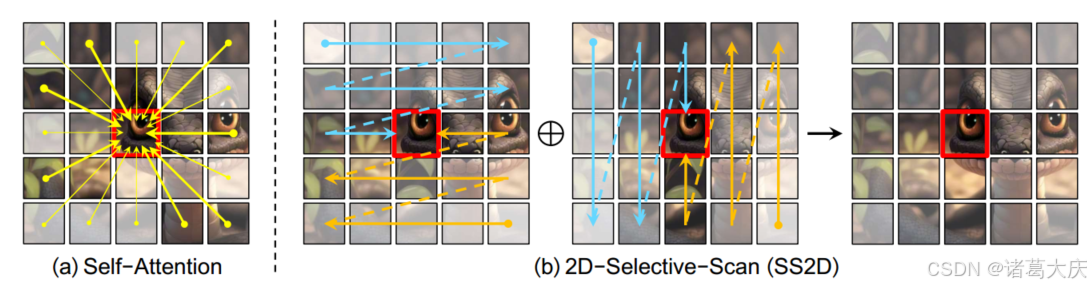
图1:通过(a)自我关注和(b)提出的2D选择性扫描(SS2D)建立图像块之间相关性的比较。红色框表示查询图像补丁,其不透明度表示信息丢失的程度。
在VSS块的基础上,我们开发了一系列VMamba架构(即VMambaTenny/Small/Base),并通过架构改进和实施优化来提高其性能。与基于CNN(ConvNeXt[37])、ViTs(Swin[36]、HiViT[66])和SSM(S4ND[44]、Vim[69])构建的基准视觉模型相比,VMamba在各种模型尺度上在ImageNet-1K[9]上始终实现了更高的图像分类精度。具体而言,VMamba Base的前1名准确率为83.9%,超过Swin 0.4%,吞吐量大大超过Swin的40%(646比458)。VMamba的优势延伸到多个下游任务,VMamba Tiny/Small/Base在COCO上的目标检测中实现了47.3%/48.7%/49.2%mAP[33](1×训练计划)。这分别比Swin高4.6%/3.9%/2.3%和ConvNeXt高3.1%/3.3%/2.2%。对于ADE20K上的单尺度语义分割[68],VMamba Tiny/Small/Base实现了47.9%/50.6%/51.0%的mIoU,分别比Swin高3.4%/3.0%/2.9%,比ConvNeXt高1.9%/1.9%/1.9%。此外,与基于ViT的模型不同,VMamba在保持可比性能的同时,FLOP呈线性增长,而ViT模型的计算复杂度随输入令牌数量呈二次增长。这展示了其最先进的输入可扩展性。
本研究的贡献:
•我们提出了VMamba,这是一种基于SSM的视觉骨干,用于线性时间复杂度的视觉表示学习。采用了一系列架构和实现改进来提高VMamba的推理速度。
•我们引入了2D选择性扫描(SS2D)来桥接1D阵列扫描和2D平面遍历,使选择性SSM能够扩展到处理视觉数据。
•VMamba在各种视觉任务中取得了良好的性能,包括图像分类、对象检测和语义分割。它还对输入序列的长度表现出显著的适应性,显示出计算复杂度的线性增长。
相关工作
卷积神经网络(CNN)。自AlexNet[31]以来,人们一直在努力提高基于CNN的模型在各种视觉任务中的建模能力[49,52,27,29]和计算效率[28,53,64,46]。引入了复杂的算子,如深度卷积[28]和可变形卷积[5,70],以提高CNN的灵活性和效率。最近,受变形金刚成功的启发[58],现代CNN[37]通过将长程依赖性[11,47,34]和动态权重[23]集成到其设计中,表现出了有前景的性能。
视觉变压器(ViTs)。作为一项开创性的工作,ViT[13]探索了基于vanilla Transformer架构的视觉模型的有效性,强调了大规模预训练视觉模型对于图像分类任务的重要性。为了减少ViT对大型数据集的依赖,DeiT[57]引入了一种师生蒸馏策略,将知识从CNN转移到ViT,并强调了归纳偏见在视觉感知中的重要性。遵循这种方法,后续研究提出了分层ViTs[36,12,61,39,66,55,6,10,67,1]。
另一个研究方向是提高自我注意的计算效率,这是ViTs的基石。线性注意力[30]将自我注意力重新表述为核特征图的线性点积,利用矩阵积的结合性将计算复杂度从二次型降低到线性型。GLA[65]引入了一种硬件高效的线性注意力变体,它平衡了内存移动和并行性。RWKV[45]还利用线性注意力机制将可并行化的变压器训练与循环神经网络(RNN)的有效推理相结合。RetNet[51]增加了一种门控机制,以实现可并行计算路径,为递归提供了一种替代方案。RMT[15]通过将时间衰减机制应用于空间域,进一步将其扩展到视觉表示学习。
状态空间模型(SSM)。尽管ViT架构在视觉任务中被广泛采用,但由于自我注意力的二次复杂性,尤其是在处理长输入序列(如高分辨率图像)时,ViT架构面临着重大挑战。为了提高扩展效率[8,7,45,51,41],SSM已成为变压器的有力替代品,引起了广泛的研究关注。Gu等人[21]证明了基于SSM的模型在使用HiPPO初始化处理长期依赖关系方面的潜力[18]。
为了提高实际可行性,S4[20]提出将参数矩阵归一化为对角结构。此后出现了各种结构化的SSM模型,每种模型都提供了不同的架构增强,例如复杂的对角线结构[22,19]、对多输入多输出的支持[50]、对角线加低秩分解[24]和选择机制[17]。这些进步也被整合到更大的表示模型中[43,41,16],进一步突显了结构化状态空间模型在各种应用中的通用性和可扩展性。虽然这些模型主要针对文本和语音等长距离和连续数据,但有限的研究探索了将SSM应用于具有二维结构的视觉数据。
前述
SSM
SSM起源于卡尔曼滤波器[32],是线性时不变(LTI)系统,通过隐藏状态h(t)∈RN将输入信号u(t)εR映射到输出响应y(t)ωR。具体而言连续时间SSM可以表示为如下线性常微分方程(ODE),

其中A∈RN×N,B∈RN x 1,C∈R1×N,D∈R1是加权参数。
SSM的离散化。为了集成到深度模型中,连续时间SSM必须提前进行离散化。具体来说,对于时间间隔[ta,tb],t=tb时隐藏状态变量h(t)的解析解可以表示为
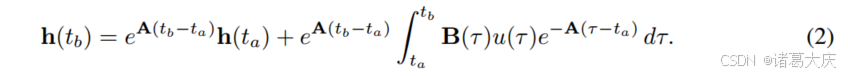
通过使用时间尺度参数∆(即dτ|ti+1 ti=\8710》i)进行采样,h(tb)可以通过以下公式进行离散化:
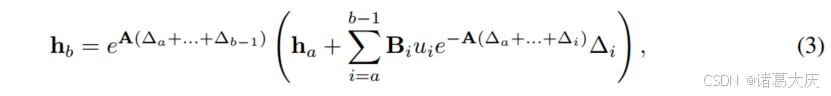
其中[a,b]是相应的离散步长间隔。值得注意的是,该公式近似于零阶保持(ZOH)方法获得的结果,该方法在基于SSM的模型文献中经常使用(详细证明请参阅附录A)
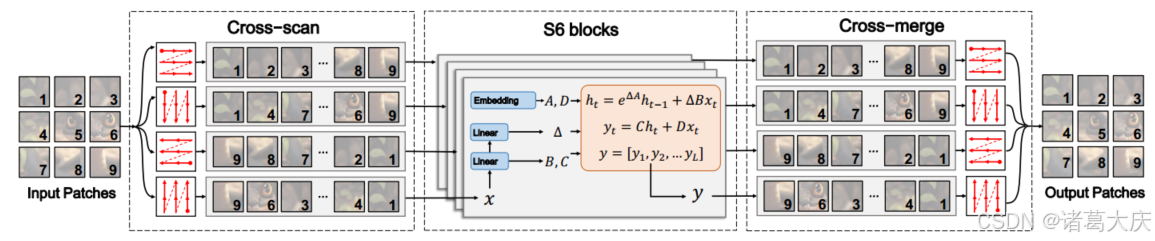
图2:二维选择性扫描(SS2D)示意图。输入补丁沿着四个不同的扫描路径(交叉扫描)遍历,每个序列由单独的S6块独立处理。然后合并结果以构建2D特征图作为最终输出(交叉合并)。
选择性扫描机制。为了解决LTI SSM(方程1)在捕获上下文信息方面的局限性,Gu等人[17]提出了一种新的SSM参数化方法,该方法结合了输入相关的选择机制(称为S6)。然而,对于选择性SSM,时变加权参数对隐藏状态的有效计算提出了挑战,因为卷积无法适应动态权重,使其不适用。然而,由于可以推导出方程3中hb的递归关系,因此仍然可以使用具有线性复杂性的关联扫描算法[2,42,50]有效地计算响应yb(详细解释见附录B)
VMamba:视觉状态空间模型
网络体系结构
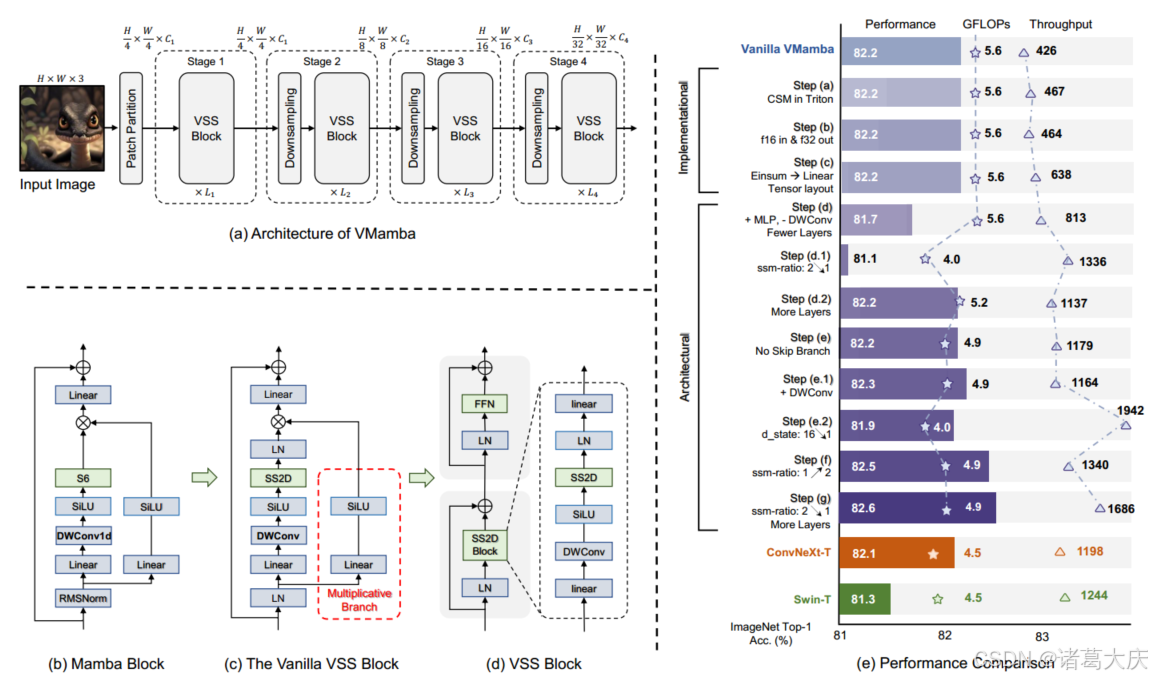
我们以三种规模开发VMamba:微型、小型和基础(分别称为VMamba-T、VMamba-S和VMamba-B)。VMamba-T的架构概述如图3(a)所示,详细配置见附录E。输入图像I∈R H×W×3首先由茎模块划分为块,得到空间维度为H/4×W/4的二维特征图。在不加入额外的位置嵌入的情况下,采用多个网络级来创建分辨率为H/8×W/8、H/16×W/16和H/32×W/32的分层表示。具体来说,每个阶段都包括一个下采样层(第一阶段除外),后面是一堆视觉状态空间(VSS)块。
VSS块作为Mamba块的视觉对应物[17](图3(b))用于表示学习。VSS块的初始架构(在图3(c)中称为“香草VSS块”)是通过替换S6模块来制定的。S6是Mamba的核心,实现了全局感受野、动态权重(即选择性)和线性复杂度。
我们用新提出的2D选择性扫描(SS2D)模块替换它,更多细节将在下一小节中介绍。为了进一步提高计算效率,我们删除了整个乘法分支(图3(c)中红色框突出显示),因为门控机制的效果已经通过SS2D的选择性实现。因此,改进的VSS块(如图3(d)所示)由一个带有两个残差模块的单个网络分支组成,模仿了普通变压器块的架构[58]。本文中的所有结果都是使用该架构中使用VSS块构建的VMamba模型获得的。
视觉数据的二维选择性扫描(SS2D)
虽然S6中扫描操作的顺序性质与涉及时间数据的NLP任务很好地一致,但当应用于视觉数据时,它构成了一个重大挑战,视觉数据本质上是非顺序的,包含空间信息(例如,局部纹理和全局结构)。为了解决这个问题,S4ND[44]用卷积运算重新表述了SSM,通过外积直接将核从1D扩展到2D。然而,这种修改限制了权重依赖于输入,导致捕获上下文信息的能力有限。因此,我们坚持使用选择性扫描方法[17]进行输入处理,并提出了2D选择性扫描(SS2D)模块,以使S6适应视觉数据,同时不损害其优势。
图2显示,SS2D中的数据转发包括三个步骤:交叉扫描、使用S6块进行选择性扫描和交叉合并。具体来说,SS2D首先将输入补丁沿四条不同的遍历路径展开为序列(即交叉扫描)。然后使用单独的S6块并行处理每个补丁序列,并对得到的序列进行整形和合并,以形成输出图(即交叉合并)。通过使用互补的1D遍历路径,SS2D允许图像中的每个像素在不同方向上整合来自所有其他像素的信息。这种整合有助于在2D空间中建立全局感受野。


















 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









