







🌞欢迎来到深度学习实战的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2025年2月8日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

位置编码和词向量
就是在计算注意力权重时,引入表示相对距离的位置参数。
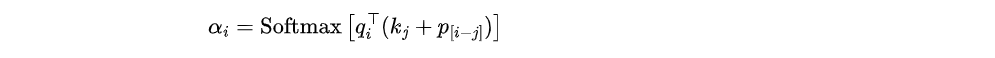
基于三角函数的绝对位置编码
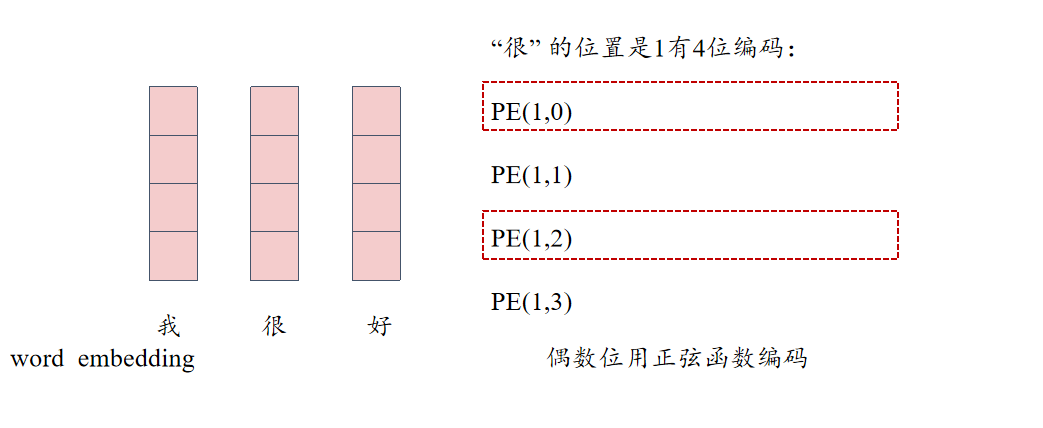
在 Transformer 模型中,词向量(Word Embeddings)的表示是通过将输入的词嵌入(Embedding)和位置编码(Positional Encoding)相加得到的。
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, emb_dim, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建一个 (max_len, emb_dim) 的矩阵
pe = torch.zeros(max_len, emb_dim)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 位置索引
div_term = torch.exp(torch.arange(0, emb_dim, 2).float() * (-math.log(10000.0) / emb_dim)) # 分母
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置用 sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置用 cos
pe = pe.unsqueeze(0) # 增加 batch 维度
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1), :] # 给输入加上位置信息
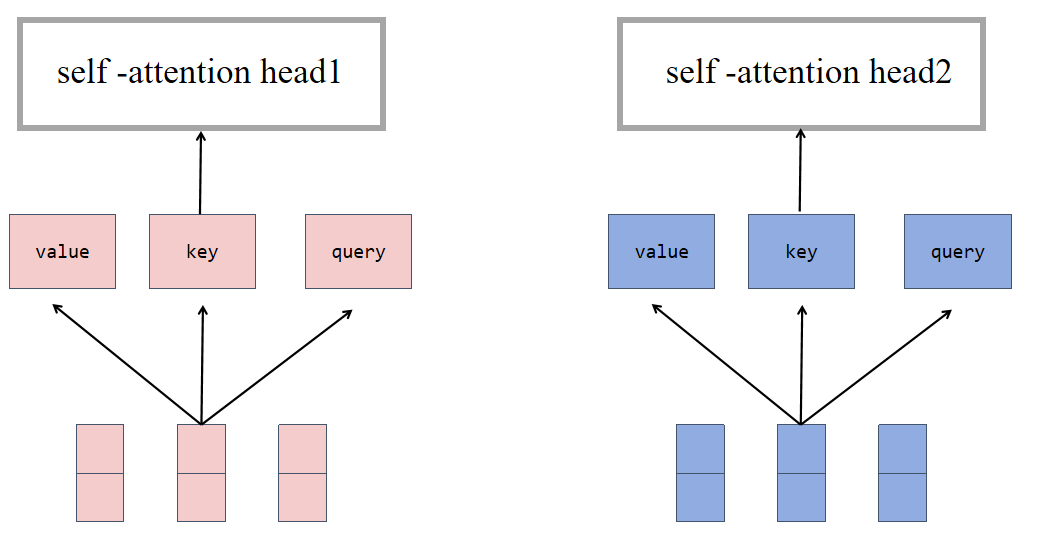
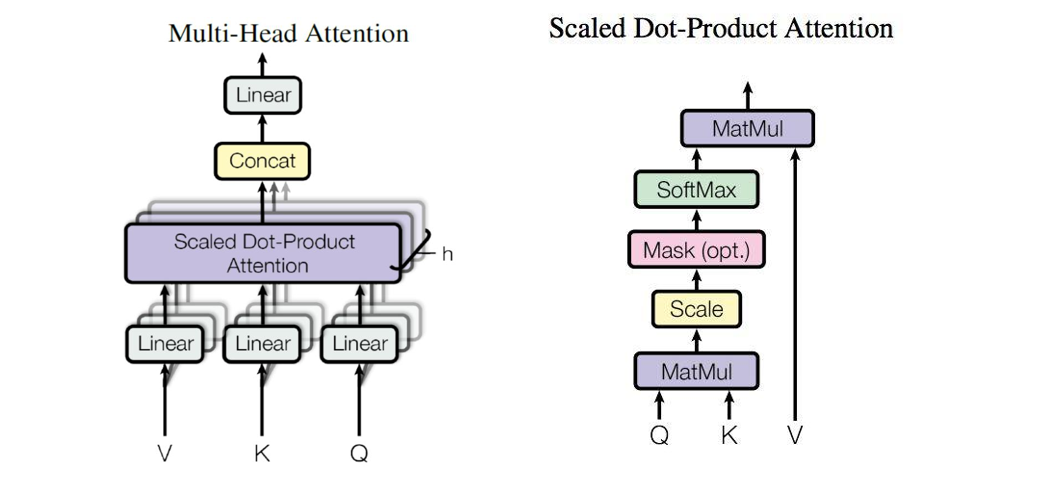
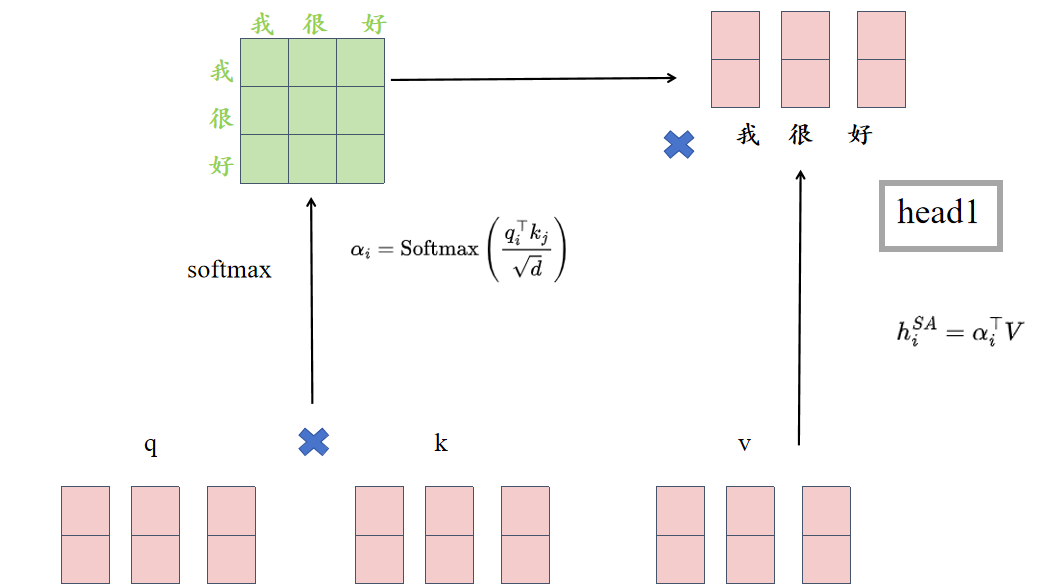
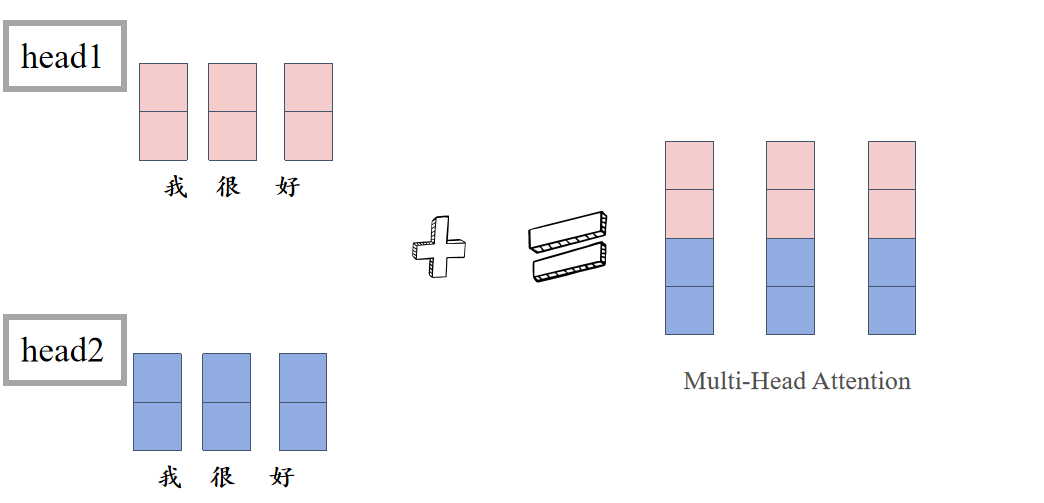
多头注意力机制
对词向量Xi分割成m个长度为d/m的子向量,对每一个子向量进行缩放点积。
q,k,v(因为X转换空间后,更加专注于注意力的学习)
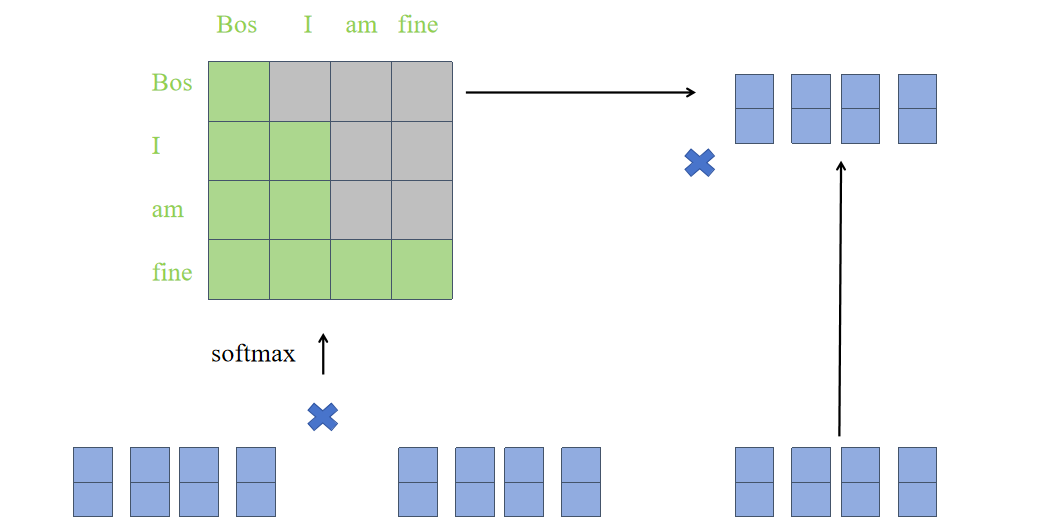
掩码的注意力机制
在解码的时候,把i<j位置设置Mij=0即可
class MultiHeadSelfAttention(nn.Module):
def __init__(self, emb_dim, num_heads):
super(MultiHeadSelfAttention, self).__init__()
assert emb_dim % num_heads == 0 # 确保能被整除
self.num_heads = num_heads
self.head_dim = emb_dim // num_heads # 每个头的维度
self.scaling = self.head_dim ** -0.5 # 缩放因子
self.qkv_proj = nn.Linear(emb_dim, emb_dim * 3) # 线性变换 Q, K, V
self.fc_out = nn.Linear(emb_dim, emb_dim) # 输出层
def forward(self, x):
batch_size, seq_len, emb_dim = x.shape
# 计算 Q, K, V
qkv = self.qkv_proj(x).reshape(batch_size, seq_len, self.num_heads, 3 * self.head_dim)
q, k, v = qkv.chunk(3, dim=-1) # 拆分成 Q, K, V
# 计算注意力分数
attn_scores = torch.einsum("bqhd,bkhd->bhqk", q, k) * self.scaling # (batch, heads, seq_len, seq_len)
attn_probs = torch.softmax(attn_scores, dim=-1) # 归一化
# 加权求和
attn_output = torch.einsum("bhqk,bkhd->bqhd", attn_probs, v)
attn_output = attn_output.reshape(batch_size, seq_len, emb_dim) # 变回原形状
return self.fc_out(attn_output) # 通过线性层输出
非线性层的设计(使用残差连接和层归一化)
第二个公式里面我认为还应该加上![]()
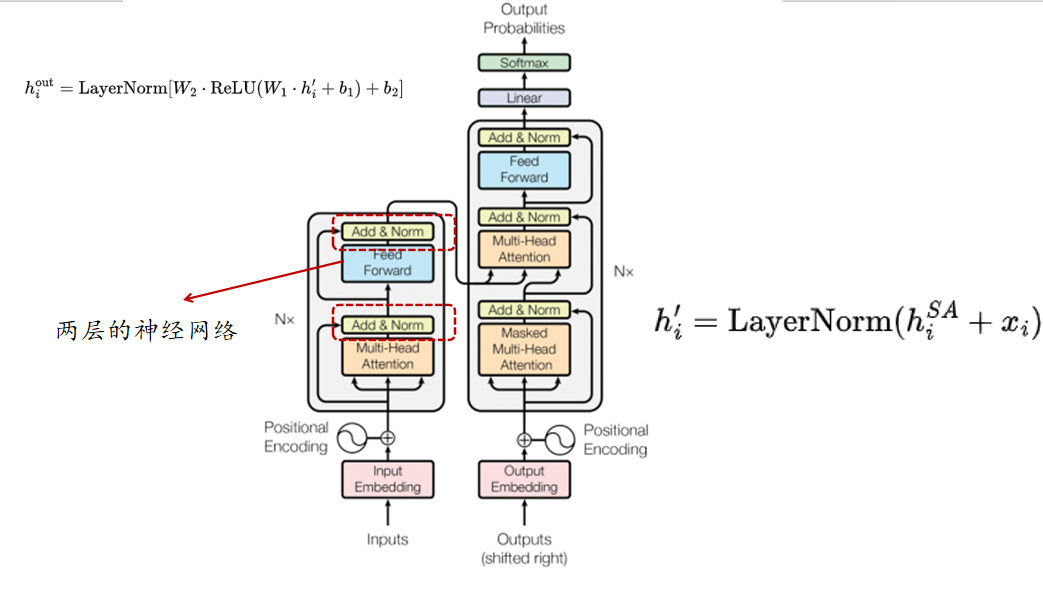
最后的输出
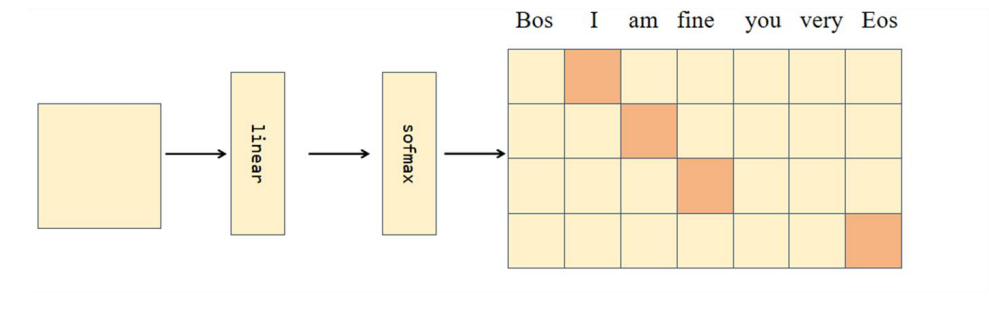
编码器
class EncoderLayer(nn.Module):
def __init__(self, emb_dim, num_heads, ffn_dim):
super(EncoderLayer, self).__init__()
self.attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm1 = nn.LayerNorm(emb_dim)
self.ffn = nn.Sequential(
nn.Linear(emb_dim, ffn_dim),
nn.ReLU(),
nn.Linear(ffn_dim, emb_dim)
)
self.norm2 = nn.LayerNorm(emb_dim)
def forward(self, x):
x = self.norm1(x + self.attn(x)) # 残差 + 归一化
x = self.norm2(x + self.ffn(x)) # 前馈网络 + 归一化
return x
class DecoderLayer(nn.Module):
def __init__(self, emb_dim, num_heads, ffn_dim):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm1 = nn.LayerNorm(emb_dim)
self.cross_attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm2 = nn.LayerNorm(emb_dim)
self.ffn = nn.Sequential(
nn.Linear(emb_dim, ffn_dim),
nn.ReLU(),
nn.Linear(ffn_dim, emb_dim)
)
self.norm3 = nn.LayerNorm(emb_dim)
def forward(self, x, enc_output):
x = self.norm1(x + self.self_attn(x))
x = self.norm2(x + self.cross_attn(x, enc_output, enc_output)) # 关注 Encoder 输出
x = self.norm3(x + self.ffn(x))
return x
解码器
class DecoderLayer(nn.Module):
def __init__(self, emb_dim, num_heads, ffn_dim):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm1 = nn.LayerNorm(emb_dim)
self.cross_attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm2 = nn.LayerNorm(emb_dim)
self.ffn = nn.Sequential(
nn.Linear(emb_dim, ffn_dim),
nn.ReLU(),
nn.Linear(ffn_dim, emb_dim)
)
self.norm3 = nn.LayerNorm(emb_dim)
def forward(self, x, enc_output):
x = self.norm1(x + self.self_attn(x))
x = self.norm2(x + self.cross_attn(x, enc_output, enc_output)) # 关注 Encoder 输出
x = self.norm3(x + self.ffn(x))
return x
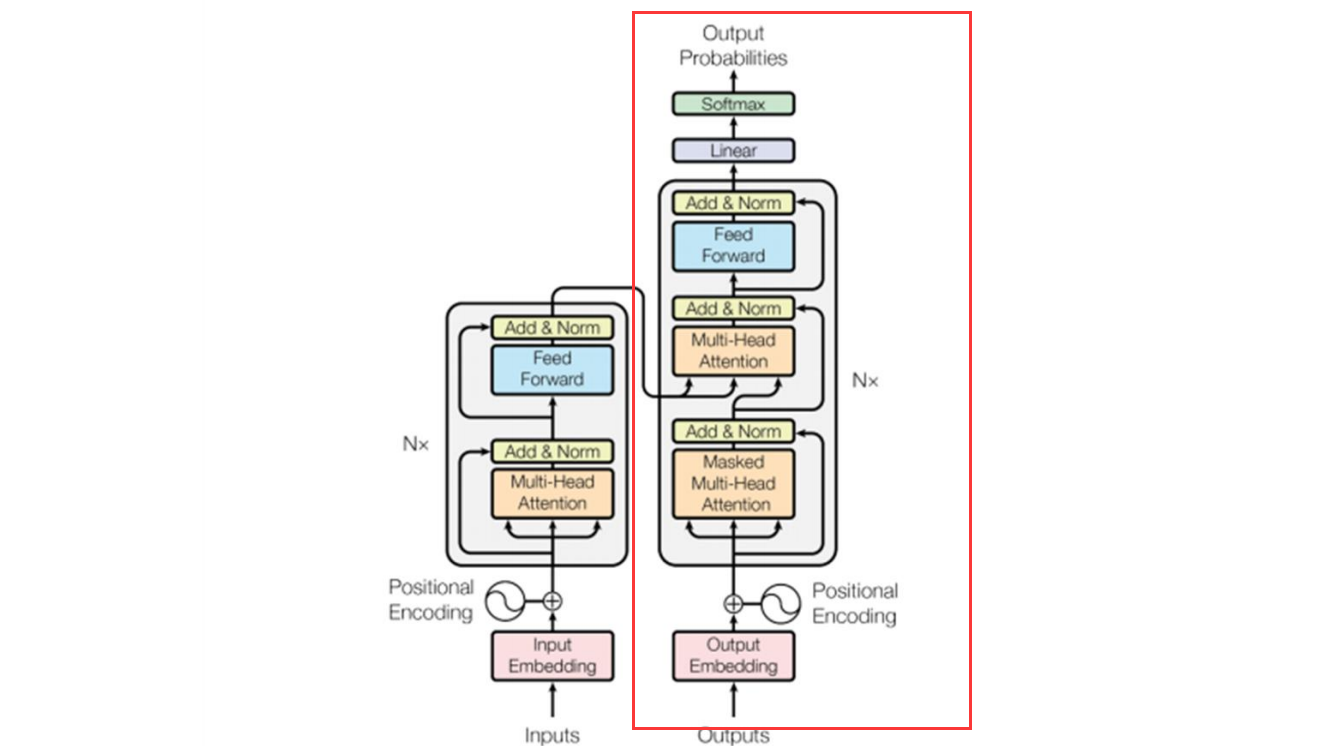
Transformer 整体结构
class Transformer(nn.Module):
def __init__(self, vocab_size, emb_dim, num_heads, ffn_dim, num_layers):
super(Transformer, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim)
self.pos_encoder = PositionalEncoding(emb_dim)
self.encoder = nn.Sequential(*[EncoderLayer(emb_dim, num_heads, ffn_dim) for _ in range(num_layers)])
self.decoder = nn.Sequential(*[DecoderLayer(emb_dim, num_heads, ffn_dim) for _ in range(num_layers)])
self.fc_out = nn.Linear(emb_dim, vocab_size)
def forward(self, src, tgt):
src = self.pos_encoder(self.embedding(src))
tgt = self.pos_encoder(self.embedding(tgt))
enc_output = self.encoder(src)
dec_output = self.decoder(tgt, enc_output)
return self.fc_out(dec_output)
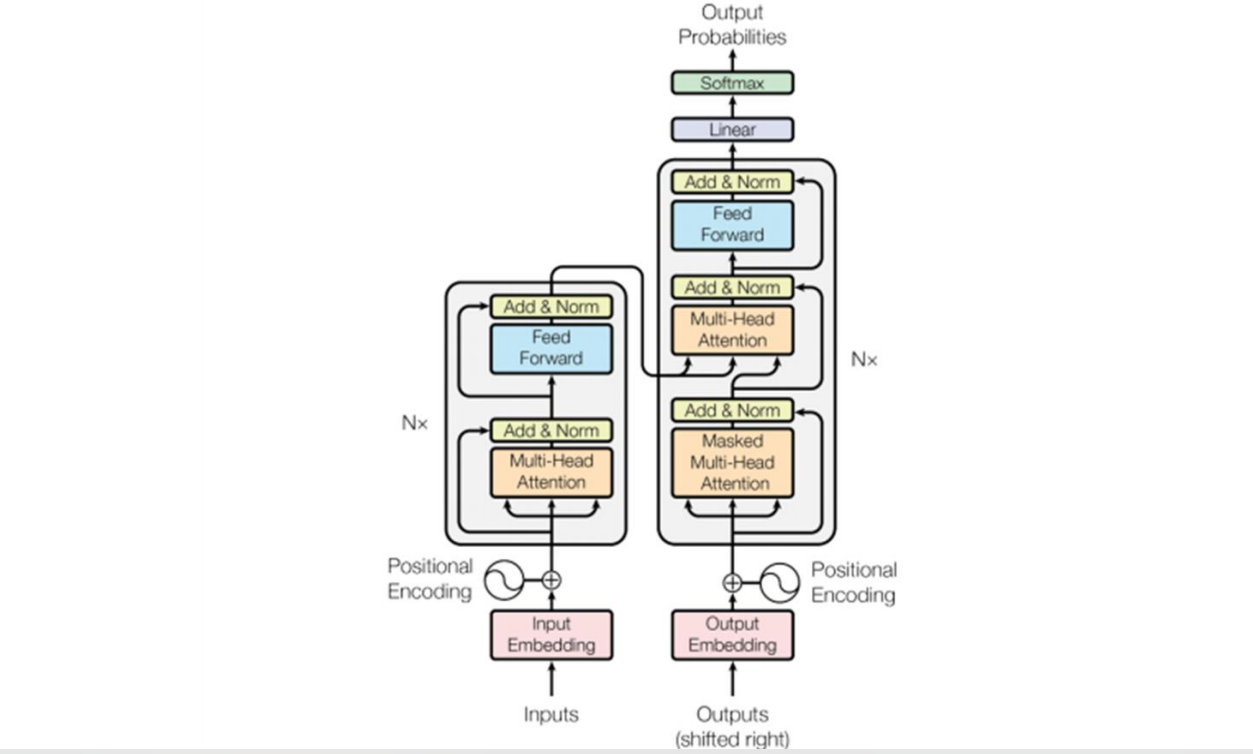
完整代码
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, emb_dim, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建一个 (max_len, emb_dim) 的矩阵
pe = torch.zeros(max_len, emb_dim)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 位置索引
div_term = torch.exp(torch.arange(0, emb_dim, 2).float() * (-math.log(10000.0) / emb_dim)) # 分母
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置用 sin
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置用 cos
pe = pe.unsqueeze(0) # 增加 batch 维度
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1), :] # 给输入加上位置信息
class MultiHeadSelfAttention(nn.Module):
def __init__(self, emb_dim, num_heads):
super(MultiHeadSelfAttention, self).__init__()
assert emb_dim % num_heads == 0 # 确保能被整除
self.num_heads = num_heads
self.head_dim = emb_dim // num_heads # 每个头的维度
self.scaling = self.head_dim ** -0.5 # 缩放因子
self.qkv_proj = nn.Linear(emb_dim, emb_dim * 3) # 线性变换 Q, K, V
self.fc_out = nn.Linear(emb_dim, emb_dim) # 输出层
def forward(self, x):
batch_size, seq_len, emb_dim = x.shape
# 计算 Q, K, V
qkv = self.qkv_proj(x).reshape(batch_size, seq_len, self.num_heads, 3 * self.head_dim)
q, k, v = qkv.chunk(3, dim=-1) # 拆分成 Q, K, V
# 计算注意力分数
attn_scores = torch.einsum("bqhd,bkhd->bhqk", q, k) * self.scaling # (batch, heads, seq_len, seq_len)
attn_probs = torch.softmax(attn_scores, dim=-1) # 归一化
# 加权求和
attn_output = torch.einsum("bhqk,bkhd->bqhd", attn_probs, v)
attn_output = attn_output.reshape(batch_size, seq_len, emb_dim) # 变回原形状
return self.fc_out(attn_output) # 通过线性层输出
class EncoderLayer(nn.Module):
def __init__(self, emb_dim, num_heads, ffn_dim):
super(EncoderLayer, self).__init__()
self.attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm1 = nn.LayerNorm(emb_dim)
self.ffn = nn.Sequential(
nn.Linear(emb_dim, ffn_dim),
nn.ReLU(),
nn.Linear(ffn_dim, emb_dim)
)
self.norm2 = nn.LayerNorm(emb_dim)
def forward(self, x):
x = self.norm1(x + self.attn(x)) # 残差 + 归一化
x = self.norm2(x + self.ffn(x)) # 前馈网络 + 归一化
return x
class DecoderLayer(nn.Module):
def __init__(self, emb_dim, num_heads, ffn_dim):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm1 = nn.LayerNorm(emb_dim)
self.cross_attn = MultiHeadSelfAttention(emb_dim, num_heads)
self.norm2 = nn.LayerNorm(emb_dim)
self.ffn = nn.Sequential(
nn.Linear(emb_dim, ffn_dim),
nn.ReLU(),
nn.Linear(ffn_dim, emb_dim)
)
self.norm3 = nn.LayerNorm(emb_dim)
def forward(self, x, enc_output):
x = self.norm1(x + self.self_attn(x))
x = self.norm2(x + self.cross_attn(x, enc_output, enc_output)) # 关注 Encoder 输出
x = self.norm3(x + self.ffn(x))
return x
class Transformer(nn.Module):
def __init__(self, vocab_size, emb_dim, num_heads, ffn_dim, num_layers):
super(Transformer, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_dim)
self.pos_encoder = PositionalEncoding(emb_dim)
self.encoder = nn.Sequential(*[EncoderLayer(emb_dim, num_heads, ffn_dim) for _ in range(num_layers)])
self.decoder = nn.Sequential(*[DecoderLayer(emb_dim, num_heads, ffn_dim) for _ in range(num_layers)])
self.fc_out = nn.Linear(emb_dim, vocab_size)
def forward(self, src, tgt):
src = self.pos_encoder(self.embedding(src))
tgt = self.pos_encoder(self.embedding(tgt))
enc_output = self.encoder(src)
dec_output = self.decoder(tgt, enc_output)
return self.fc_out(dec_output)
# 设置 Transformer 参数
vocab_size = 7 # 假设中英词典大小都一样
emb_dim = 16 # 词向量维度
num_heads = 2 # 多头注意力
ffn_dim = 32 # 前馈神经网络隐藏层大小
num_layers = 2 # 编码器 & 解码器的层数
# 创建 Transformer 模型
model = Transformer(vocab_size, emb_dim, num_heads, ffn_dim, num_layers)
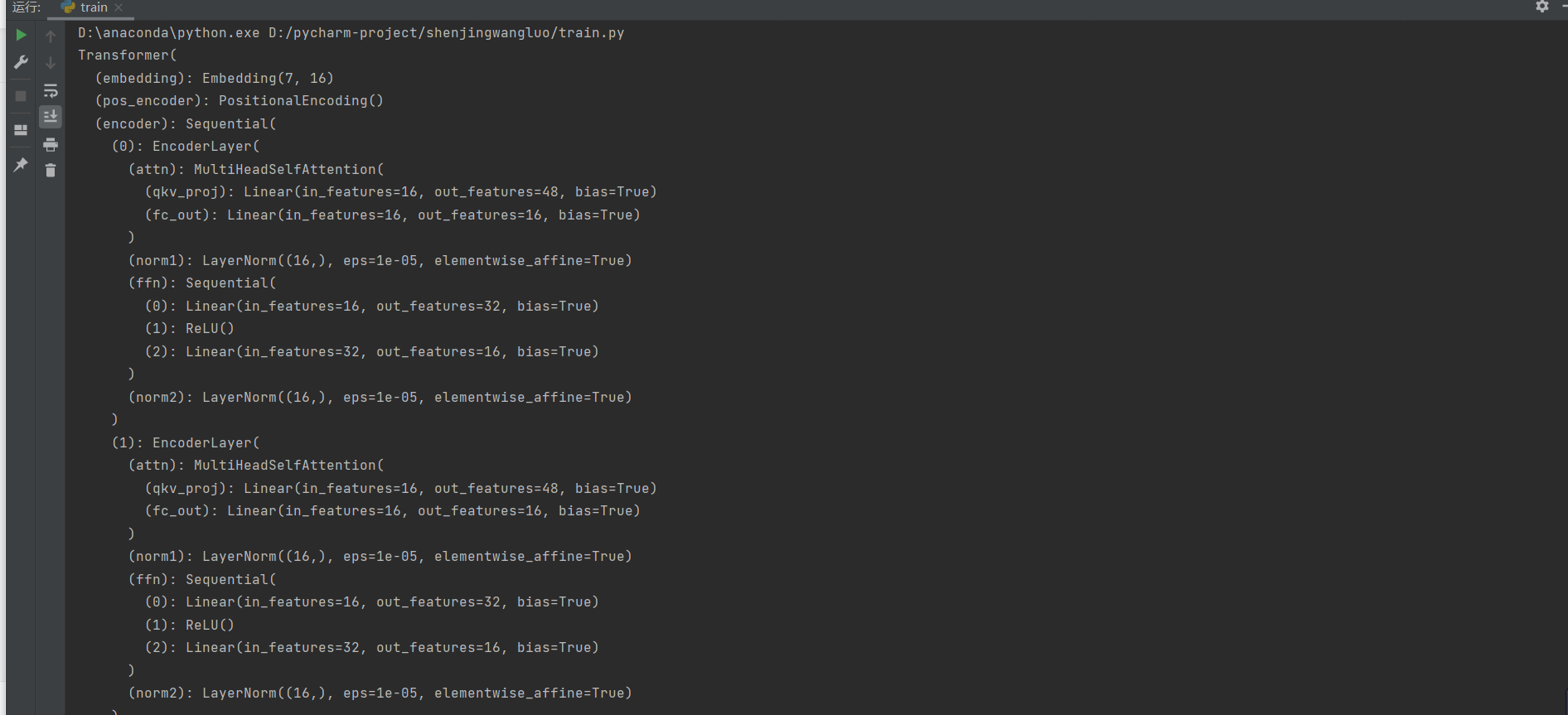
print(model)



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











