









因子分解机(Factorization Machine, FM)是由Steffen Rendle提出的一种基于矩阵分解的机器学习算法。目前,被广泛的应用于广告预估模型中,相比LR而言,效果强了不少。
一、FM背景
FM(Factorization Machine)主要目标是:解决数据稀疏的情况下,特征怎样组合的问题。以一个广告分类的问题为例,根据用户画像、广告位以及一些其他的特征,来预测用户是否会点击广告(二分类问题)。数据如下:
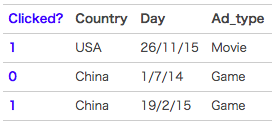
Clicked?是分类值,表明用户是否点击了此广告。1表示点击,0表示未点击。而Country,Day,Ad_type则是Categorical特征(类别特征),一般都是进行one-hot编码处理。
将上面的离散特征数据进行one-hot编码以后(假设Country,Day,Ad_type类别只有图中几种),如下图所示

显然可以看出,特征从最初的3个变成了现在的7个。而实际工程当中,由于有的Categorical特征维度会非常大(比如地区等),如果采用One-Hot编码,那么互联网公司的动辄上亿个特征的数据集就是这么来的了。
因式分解机是一种基于LR模型的高效的学习特征间相互关系,
对于因子分解机FM来说,最大的特点是对于稀疏的数据具有很好的学习能力。
二、FM优点
① FMs allow parameter estimation under very sparse data where SVMs fails.(FM模型可以在非常稀疏的数据中进行合理的参数估计,而SVM做不到这点)
② **FMs have linear complexity,**can be optimized in the primal and do not rely on support vectors like SVMs.
(在FM模型的复杂度是线性的,优化效果很好,而且不需要像SVM一样依赖于支持向量。)③ FMs are a general predictor that can work with any real valued feature vector. In contrast to this, other state-of-the-art factorization models work only on very restricted input data.
(FM是一个通用模型,它可以用于任何特征为实值的情况。而其他的因式分解模型只能用于一些输入数据比较固定的情况。)
三、FM模型
在一般的线性模型中,是各个特征独立考虑的,没有考虑到特征与特征之间的相互关系。但实际上,大量的特征之间是有关联的。最简单的以电商为例,一般女性用户看化妆品服装之类的广告比较多,而男性更青睐各种球类装备。那很明显,女性这个特征与化妆品类服装类商品有很大的关联性,男性这个特征与球类装备的关联性更为密切。如果我们能将这些有关联的特征找出来,显然是很有意义的。
一般的线性模型为(
n
为特征维度):
对于度为2的因子分解机(FM)的模型为:
其中,
v∈Rn,k
,
<vi,vj>
<script type="math/tex" id="MathJax-Element-551"><\mathbf v_i,\mathbf v_j></script>表示的是两个大小为
k
的向量之间的点积:
与线性模型相比,FM的模型就多了后面特征组合的部分。
四、FM求解
在基本线性回归模型的基础上引入交叉项,如下:
组合部分的特征相关参数共有 n(n−1)2 个。但是在数据很稀疏的情况下,满足 xi , xj 都不为0的情况非常少,这样将导致 ωij 无法通过训练得出,无法对相应的参数进行估计。
这里,采用的方法是:对每一个特征分量 xi 引入辅助向量 vi=(vi1,vi2,...,vik) 。然后,利用 vivTj 对交叉项的系数 ωij 进行估计
令
则
这就对应了一种矩阵的分解。对
k
值的限定,对FM的表达能力有一定的影响,下图为论文中说明的

下面,求
<vi,vj>
<script type="math/tex" id="MathJax-Element-1255"><\mathbf v_i ,\mathbf v_j></script>,这块的求解用到了
((a+b+c)2−a2−b2−c2)/2
求出交叉项。过程如下:















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









