






一、简述
多模态 LLM 是能够处理多种类型输入的大型语言模型, 多模态 LLM 可以接受不同的输入模态(音频、文本、图像和视频)并返回文本作为输出模态。
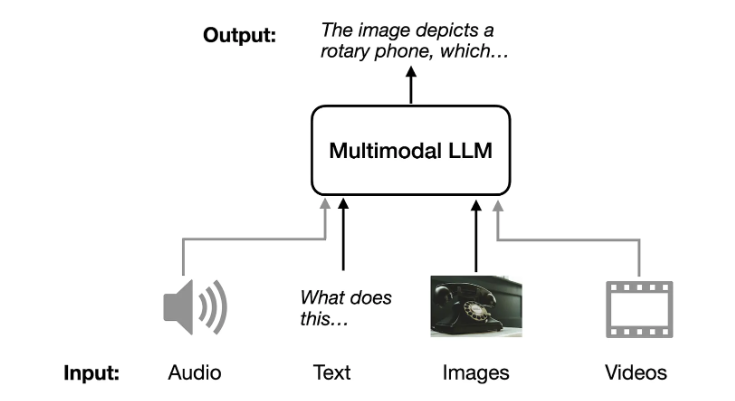
多模态 LLM 的一个直观的应用场景是为图像生成描述,提供输入图像,模型会生成图像的描述,如下图所示。

当然,还有许多其它应用场景。比如从 PDF 表格中提取信息并将其转换为 LaTeX 或 Markdown。
二、构建多模态 LLM
构建多模态 LLM 有两种主要方法: 统一嵌入解码器架构方法; 跨模态注意力架构方法。
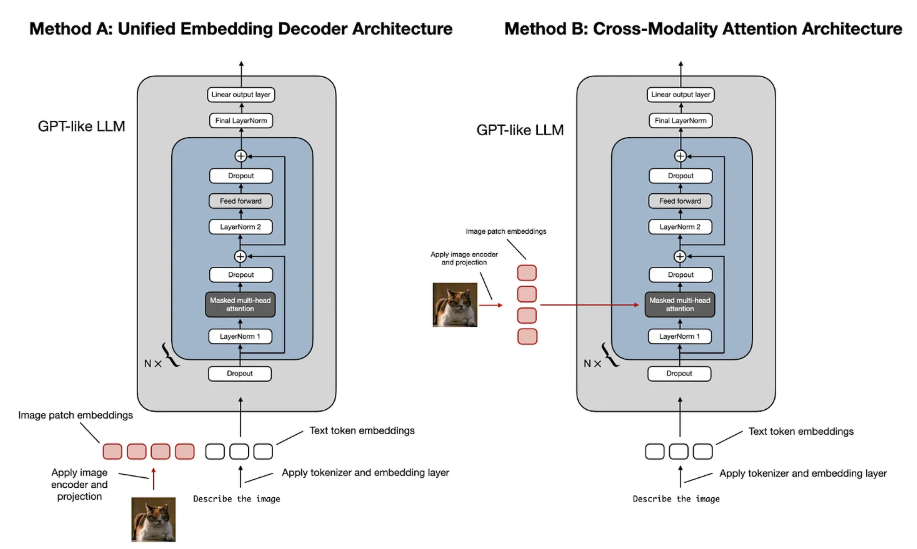
如上图所示,统一嵌入-解码器架构使用单个解码器模型,很像 GPT-2 或 Llama 3.2 等未经修改的 LLM 架构。在这种方法中,图像被转换为与原始文本令牌具有相同嵌入大小的令牌,从而允许 LLM 在连接后同时处理文本和图像输入令牌。而跨模态注意力架构采用交叉注意力机制,将图像和文本嵌入直接集成到注意力层中。
1、统一嵌入解码器架构
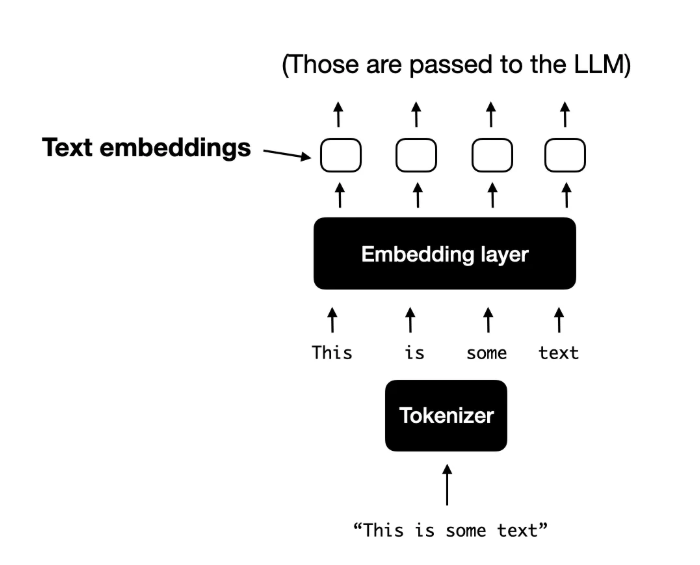
在统一的嵌入-解码器架构中,图像被转换为嵌入向量,类似于在标准纯文本 LLM 中将输入文本转换为嵌入的方式。 对于处理文本的典型纯文本 LLM,文本输入通常是标记化的(例如,使用字节对编码),然后通过嵌入层传递,如下图所示。
1.1、图像编码器
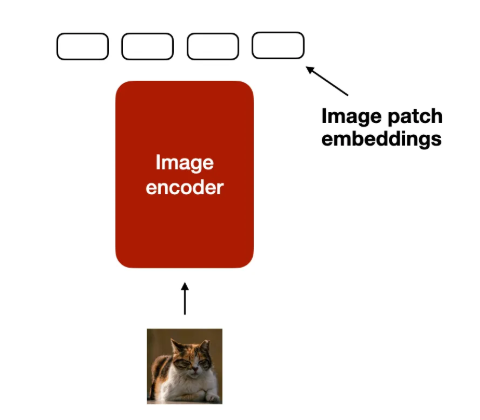
与文本的分词化和嵌入类似,图像嵌入是使用图像编码器模块(而不是分词器)生成的,如下图所示。
上面显示的图像编码器内部处理流程是,要处理图像,我们首先将其分成更小的块,这与在分词化过程中将单词分成子词非常相似。然后,这些补丁由预训练的视觉转换器 (ViT) 编码,如下图所示。
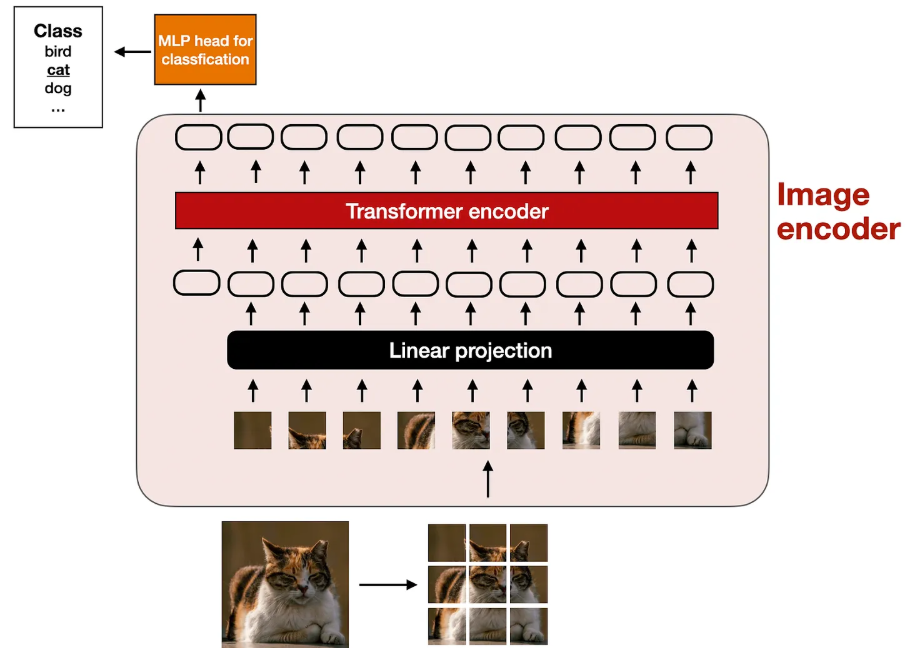
1.2、线性投影模块
上图所示的 “线性投影” 由单个线性层(即全连接层)组成。此层的目的是将图像块(展平为矢量)投影为与 transformer 编码器兼容的嵌入大小。此线性投影如下图所示。展平为 256 维向量的图像块将向上投影到 768 维向量。
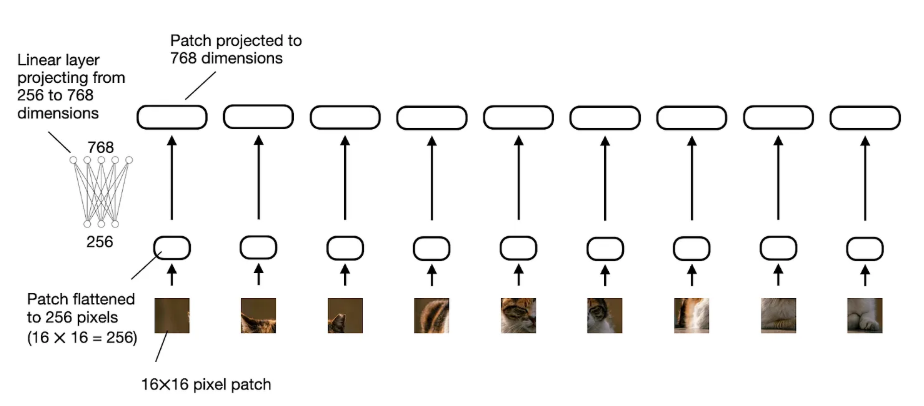
在 PyTorch 代码中,我们可以实现图像补丁的线性投影,如下所示:
import torch
class PatchProjectionLayer(torch.nn.Module):
def __init__(self, patch_size, num_channels, embedding_dim):
super().__init__()
self.patch_size = patch_size
self.num_channels = num_channels
self.embedding_dim = embedding_dim
self.projection = torch.nn.Linear(
patch_size * patch_size * num_channels, embedding_dim
)
def forward(self, x):
batch_size, num_patches, channels, height, width = x.size()
x = x.view(batch_size, num_patches, -1) # Flatten each patch
x = self.projection(x) # Project each flattened patch
return x
# Example Usage:
batch_size = 1
num_patches = 9 # Total patches per image
patch_size = 16 # 16x16 pixels per patch
num_channels = 3 # RGB image
embedding_dim = 768 # Size of the embedding vector
projection_layer = PatchProjectionLayer(patch_size, num_channels, embedding_dim)
patches = torch.rand(
batch_size, num_patches, num_channels, patch_size, patch_size
)
projected_embeddings = projection_layer(patches)
print(projected_embeddings.shape)
# This prints
# torch.Size([1, 9, 768])有一些方法可以用卷积运算代替线性层,这些运算可以实现为在数学上等效。
layer = torch.nn.Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
image = torch.rand(batch_size, 3, 48, 48)
projected_patches = layer(image)
print(projected_patches.flatten(-2).transpose(-1, -2).shape)
# This prints
# torch.Size([1, 9, 768])1.3、图像与文本分词
现在,我们了解了图像编码器(以及作为编码器一部分的线性投影)的用途,让我们回到前面的文本分词化类比,了解文本和图像分词化和嵌入,如下图所示。
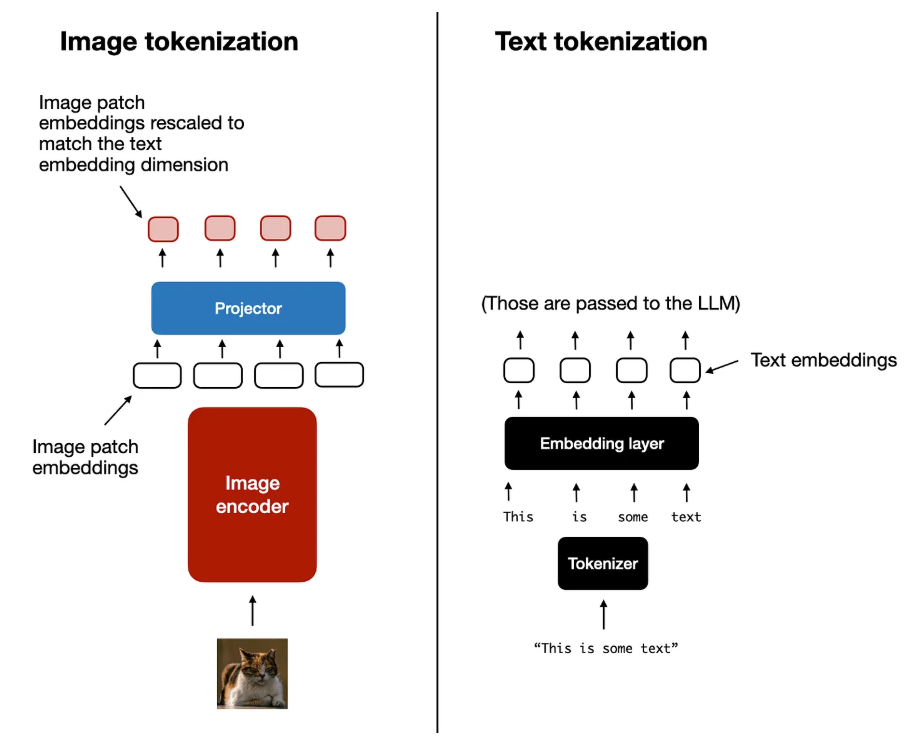
如上图所示,目的是将图像编码器输出投影到与嵌入文本标记的尺寸匹配的维度中。
图像补丁嵌入与文本标记嵌入具有相同的嵌入维度,我们可以简单地将它们连接为 LLM 的输入,如本节开头的图所示。 我们在本节中讨论的 image encoder 通常是预训练的 vision transformer。比较流行的选择是 CLIP 或 OpenCLIP。
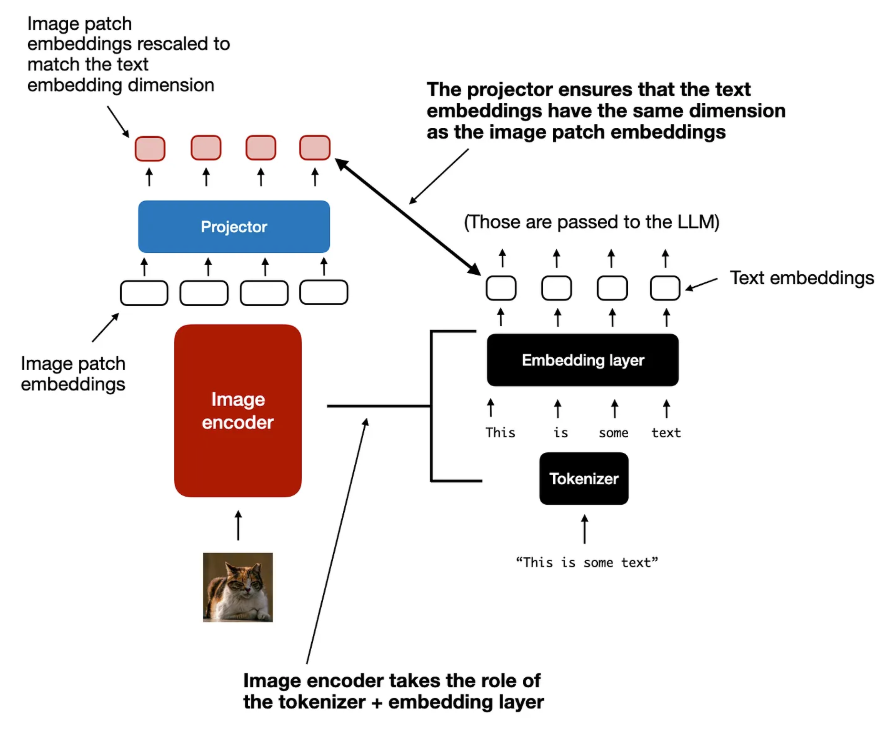
也有直接对补丁进行操作的方法 。
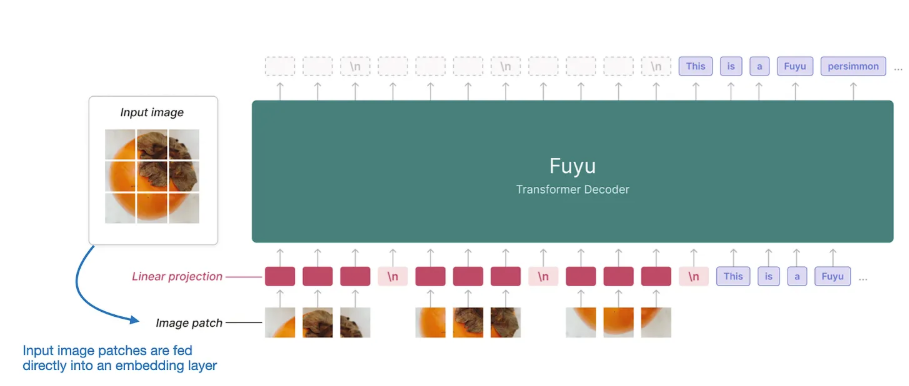
如上图所示,将输入补丁直接传递到线性投影(或嵌入层)中,以学习自己的图像补丁嵌入,而不是像其他模型和方法那样依赖额外的预训练图像编码器。这大大简化了架构和训练设置。
2、跨模态注意力架构
点击多模态 LLM 的工作原理简述查看全文。

















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









