









版权声明:本文为博主原创文章,未经博主允许不得转载。
之前,我写过一篇关于Rwordseg包的分词,链接为:http://blog.csdn.net/wzgl__wh/article/details/52528925
今天,我主要想谈谈自己对jiebaR这个包。现在我也比较推荐使用jiebaR这个包,原因也大概总结了一下几点。
|
| JiebaR | Rwordseg |
| 函数数量 | 51个 | 9个 |
| 更新速度 | 快,cran最新版更新于2016-09-28 | 慢,R-Forge最新版更新于2013-12-15 |
| 安装难度 | 容易 | 难,需要安装Java。 |
| 分词引擎 | 多 | 只有一种(隐马尔科夫模型) |
(个人观点,还望大家在留言区补充)
一、分词
首先,我们来看一下jiebaR里面最重要的一个函数worker函数,通过它,我们可以设置一些分词类型,用户词典,停用词等等。函数原型为:
现在来说说每个参数的作用。
| 参数 | 作用 |
| type | 指分词引擎类型,这个包包括mix, mp, hmm, full, query, tag, simhash, keyword,分别指混合模型,支持最大概率,隐马尔科夫模型,全模式,索引模型,词性标注,文本Simhash相似度比较,关键字提取。 |
| dict | 词库路径,默认为DICTPATH. |
| hmm | 用来指定隐马尔可夫模型的路径,默认值为DICTPATH,当然也可以指定其他分词引擎 |
| user | 用户自定义的词库 |
| idf | 用来指定逆文本频率指数路径,默认为DICTPATH,也可以用于simhash和keyword分词引擎 |
| stop_word | 用来指定停用词的路径 |
| qmax | 词的最大查询长度,默认为20,可用于query分词类型。 |
| topn | 关键词的个数,默认为5,可以用于simhash和keyword分词类型 |
| symbol | 输出是否保留符号,默认为F |
| Lines | 从文件中最大一次读取的行数。默认为1e+05 |
| output | 输出文件,文件名一般时候系统时间。 |
| bylines | 返回输入的文件有多少行 |
| user_weight | 用户词典的词权重,有"min" "max" or "median"三个选项。 |
另外一个函数就是segment,它就好比老板,它有三个参数,code就好比任务,jiebar就是一个worker,但是担心worker对工作的方法不懂,那就用mod参数再告诉worker怎么做,也就是用什么分词引擎分词。作用分别如下。它要用这个工人worker去分词。
| 参数 | 作用 |
| code | 中文句子或者文件 |
| jiebar | 设置分词的引擎,也就是worker函数 |
| mod | 改变默认的分词引擎类型,其中包括以下几个:"mix", "hmm","query","full","level", "mp"
|
了解完这些参数之后,我们现在就来简单的做一个小分词。
结果如下:

在这里,我们除了使用segment之外,还可以使用下面代码分词,效果是一样的。
二、添加用户自定义词或词库
那刚才那个例子来说,“公众号”本来就是一个词,结果被分成两个词,因此我需要添加这个词。另外,我也想要“R语言”也被分成一个词。接下来我们就分别使用这两种方法来实现。
1.使用new_user_word函数;
2.使用worker函数中通过user参数添加词库。
(1)new_user_word函数

▷ 使用user参数添加词库
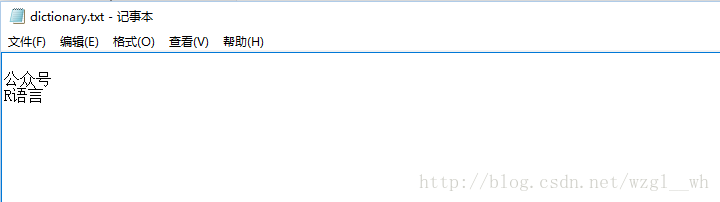
看完使用new_user_word函数添加词之后,你是不是心里就在想,如果我有几十个,甚至几百几千个词的话,如果这样输的话那估计得累死。因此我们可以自定义一个词库,然后从词库里面直接读。我建的词库截图如下:
为了便于比较,我把这两次分词结果图截到一起,如下

需要说明的是,在使用词库的话也可以使用new_user_word函数。第二种方法用也可以用new_user_word写成下面这样,结果是一样的。
三、删除停用词
就拿我们刚才使用的例子,分词之后的“那”,“就”就是停用词,因此我们需要删掉。这里我们需要使用worker函数的stop_word参数。

通过对比,我们发些,“那”,“就”已经被删掉了。
四,计算词频
这个jiebaR这个包的功能很全,它已经提供了一个函数——freq,来自动计算获取词频。
这个函数就自动计算了words分词之后的词频,这下我们就很容易使用wordcloud2包绘制词云。

五、词性标注
jiebaR包,提供了一个qseg函数,它在分词的时候也会加上词性,它有两种使用方法。
结果如下:

其中词性标注也可以使用worker函数的type参数,type默认为mix,仅需将它设置为tag即可。

我自己也找网上找了一些汉语文本词性标注的资料,整理到如下表格。
| 标注 | 词性 | 标注 | 词性 |
| ag | 形容素 | a | 形容词 |
| ad | 副形词 | an | 名形词 |
| b | 区别词 | c | 连词 |
| Dg | 副语素 | d | 副词 |
| e | 叹词 | f | 方位词 |
| g | 语素 | h | 前接成分 |
| i | 成语 | j | 简称略语 |
| k | 后接成分 | l | 习用语 |
| m | 数词 | ng | 名词素 |
| n | 名词 | nr | 人名 |
| nr1 | 汉语姓氏 | nr2 | 日语姓氏 |
| nrj | 日语人名 | nrf | 音译人名 |
| ns | 地名 | nt | 机构团体 |
| nz | 其他专名 | nl | 名词性惯用语 |
| vf | 取向动词 | vx | 形式动词 |
| p | 介词 | q | 量词 |
| r | 代词 | s | 处所词 |
| tg | 时间词性语素(时语素) | t | 时间词 |
| u | 助词 | vg | 动词素 |
| v | 动词 | vd | 副动词 |
| vn | 名动词 | w | 标点符号 |
| y | 语气词 | x | 非语素词 |
| z | 状态词 | o | 拟声词 |
六,提取关键字
















 2581
2581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









