






原论文:Multi-column Deep Neural Networks for Image Classification
作者:Dan Cires, Ueli Meier and Jurgen Schmidhuber
时间:February 2012
本文的大部分观点来自于这篇论文,并且加入了一些自己的理解。该博客纯属读书笔记。
创新点1:Multi-column Deep Neural Networks
文章最大的卖点就是Multi-column,翻译过来叫多柱?还是多列?反正主要意思就是用训练样本去训练多个DNN,在这里可以用相同的样本去训练(实验证明完全没用),或者每个CNN的训练样本都用不同的方法先预处理一遍。训练好了以后,那么现在就有很多个DNN可以用来进行图像分类啦,但是每一个DNN所给出的分类结果都不一样啊,比如现在有2个DNN,都是用来分类对A,B,C进行分类的,最后的输出使用softmax函数,那么假设一个DNN的结果为(0.5,0.2,0.3)说明识别出来的结果为A,另外一个DNN的结果为(0.2,0.6,0.2)说明识别出来的结果为B,这个时候问题就来了,我该相信谁呢?文章里采用的方法是求平均the predictions of all columns are
democratically averaged 虽然实验结果证明这种方法有效,但是拜托能不能解释一下啊?为什么要平均?给每个DNN都加个权值行不行?既然文章不解释,那我就YY一下作者为什么要这么做。
虽然实验结果证明这种方法有效,但是拜托能不能解释一下啊?为什么要平均?给每个DNN都加个权值行不行?既然文章不解释,那我就YY一下作者为什么要这么做。
文章提到这种想法是受到大脑新皮质的启发的Inspired by microcolumns of neurons in the cerebral cortex。没错,大脑的构造是很复杂的,比如我们要识别一个苹果,那么我们就要考虑苹果出现在我们脑海里的图像是什么样的(不同角度,不同颜色,不同。。。别忘了现在只是考虑了视觉,还有书面语,口语呢),假设现在我们脑子里有一个关于苹果的模式识别器,经过很长时间的训练,这个模式识别器已经很厉害了,能够处理各种各样的苹果,但是有一天你发神经,脑袋装墙上了,或者脑子短路了,再或者脑神经自然死亡了 ,恰好伤及你这个模式识别器的神经元,那你不是突然认不出苹果了?不可能嘛!所以我们的大脑很聪明,它搞了一个叫冗余东西来避免这种情况。你不是牛逼嘛,我弄几百个苹果的模式识别器,有种你把所有的都给我撞没了。哎,扯远了啊,回到正题,大脑中的模式识别器的冗余系数很大,难道仅仅是为了备份以防万一吗?当然不是!这么多的模式识别器的成功识别虽然都来自于大脑自身的经验,但是每个模式识别器接受的输入的刺激是不同的,这些不同的模式识别器增加了大脑对不同形态的苹果的识别成功率,这才是冗余带来的最大的好处。这也是为什么Multi-column Deep Neural Networks取得成功的根本原因。但是我们知道大脑最后肯定不是简单的将每个模式识别器的结果取平均值的,可是文章最后为什么还是对每个DNN的分类结果取平均值而没有采用更复杂的操作呢?哎呀,文章作者也不知道大脑最后是怎么操作的啊!所以只能取平均咯。。。哎呦,最后实验结果还不错哦,state-of-the-art啊,单单一个冗余系数就这么厉害,看来我要好好研究我的大脑构造了。。。
,恰好伤及你这个模式识别器的神经元,那你不是突然认不出苹果了?不可能嘛!所以我们的大脑很聪明,它搞了一个叫冗余东西来避免这种情况。你不是牛逼嘛,我弄几百个苹果的模式识别器,有种你把所有的都给我撞没了。哎,扯远了啊,回到正题,大脑中的模式识别器的冗余系数很大,难道仅仅是为了备份以防万一吗?当然不是!这么多的模式识别器的成功识别虽然都来自于大脑自身的经验,但是每个模式识别器接受的输入的刺激是不同的,这些不同的模式识别器增加了大脑对不同形态的苹果的识别成功率,这才是冗余带来的最大的好处。这也是为什么Multi-column Deep Neural Networks取得成功的根本原因。但是我们知道大脑最后肯定不是简单的将每个模式识别器的结果取平均值的,可是文章最后为什么还是对每个DNN的分类结果取平均值而没有采用更复杂的操作呢?哎呀,文章作者也不知道大脑最后是怎么操作的啊!所以只能取平均咯。。。哎呦,最后实验结果还不错哦,state-of-the-art啊,单单一个冗余系数就这么厉害,看来我要好好研究我的大脑构造了。。。
图1就是文章的Multi-column Deep Neural Networks的基本框架。
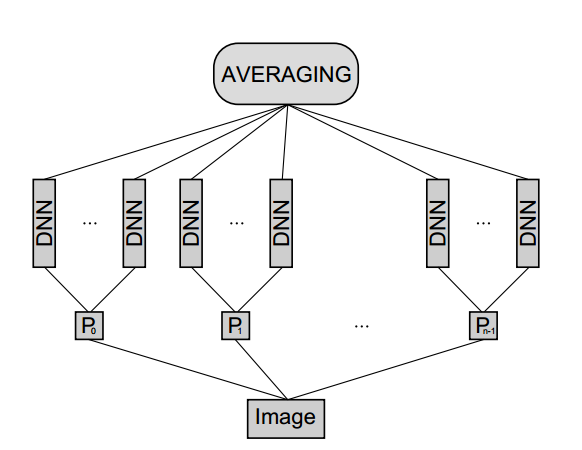
下面咱们来研究一下构成它的每一个DNN的基本结构,简单到爆!三个卷积层加2个全连接层(CIFAR10用的是3个全连接层),没了!我们来看看用于识别交通路标的DNN的结构,如图2。
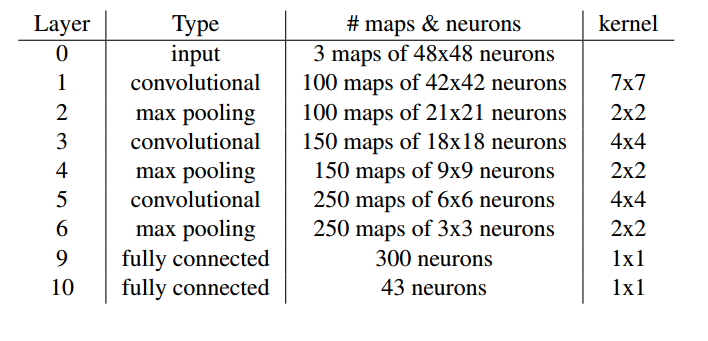
卷积核的神经元一共是:7*7*100*3+4*4*150*100+4*4*250*150=854700
全连接层神经元一共是:250*3*3*300
创新点2:winner-take-all
实验部分















 7394
7394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









