









从这篇博文开始,我将介绍机器学习,深度学习在金融风控这个行业上的应用。其实机器学习,深度学习在一些相关场景上的应用,其解决方法都是大同小异,差不多都是固定的解决套路,但是需要结合这个场景这个行业领域的相关知识来解决。
这篇博文将开始介绍客户流失预警模型,而本篇博文将主要侧重介绍金融数据分析,预处理。
客户流失预警模型的业务意义
-
严格地讲,客户流失指的是客户在该行所有业务终止,并销号。但是具体业务部门可单独定义在该部门的全部或某些业务上,客户的终止行为。
-
对专家及金融业业内人士的走访及调研结果表明,商业银行客户流失较为严重。国内商业银行,客户流失率可达20%甚至更高。而获得新客户的成本,可达维护现有客户的5倍。
-
因此,从海量客户交易记录中挖掘出对流失有影响的信息,建立高效的客户流失预警体系尤为重要。
建立量化模型,合理预测客群的潜在流失风险
• 常用的风险因子
• 客户持有的产品数量、种类
• 客户的年龄、性别
• 受地理区域的影响
• 受产品类别的影响
• 交易的间隔时间
• 营销、促销手段
• 银行的服务方式和态度
数据介绍和描述
本案例搜集了17,241例数据,其中有1,741例流失样本,总流失率达到10.10%
银行自有字段(有效记录占100%)
•账户类信息
•个人类信息
•存款类信息
•消费、交易类信息
•理财、基金类信息
•柜台服务、网银类信息
外部三方数据(可能存在缺失值)
•外呼客服数据
•资产类数据
•其他消费类数据
单因子分析之连续变量
1)有效记录的占比
因为原始数据可能存在大量的缺失值,故我们需要查看这个单因子数据上缺失值占总个数据的比值情况。如果占比特别大,则有可能会不考虑这个因子。
2)整体分布
我们需要看看这个原始数据在这个单因子上的初始分布,有时候因为原始数据在这个单因子上存在极端值,导致看不来这个单因子数据分布情况,这时就需要进行截断,去除一些极端值,看看这个单因子数据的截断分布。
3)按目标变量分布的差异
这里指的是流失的人群数据在这个单因子上分布情况,非流失的人群数据在这个单因子上分布情况。
连续性变量的画图代码:
def NumVarPerf(df,col,target,filepath, truncation=False):
'''
:param df: the dataset containing numerical independent variable and dependent variable
:param col: independent variable with numerical type
:param target: dependent variable, class of 0-1
:param filepath: the location where we save the histogram
:param truncation: indication whether we need to do some truncation for outliers
:return: the descriptive statistics
'''
#extract target variable and specific indepedent variable
validDf = df.loc[df[col] == df[col]][[col,target]]
#the percentage of valid elements
validRcd = validDf.shape[0]*1.0/df.shape[0]
#format the percentage in the form of percent
validRcdFmt = "%.2f%%"%(validRcd*100)
#the descriptive statistics of each numerical column
descStats = validDf[col].describe()
mu = "%.2e" % descStats['mean']
std = "%.2e" % descStats['std']
maxVal = "%.2e" % descStats['max']
minVal = "%.2e" % descStats['min']
#we show the distribution by churn/not churn state
x = validDf.loc[validDf[target]==1][col]
y = validDf.loc[validDf[target]==0][col]
xweights = 100.0 * np.ones_like(x) / x.size
yweights = 100.0 * np.ones_like(y) / y.size
#if need truncation, truncate the numbers in 95th quantile
if truncation == True:
'''
如果选择截断,这里选择把大于0.95的分位点的数值全用0.95的分位点值代替。
'''
pcnt95 = np.percentile(validDf[col],95)
x = x.map(lambda x: min(x,pcnt95))
y = y.map(lambda x: min(x,pcnt95))
fig, ax = pyplot.subplots()
ax.hist(x.values, weights=xweights, alpha=0.5,label='Attrition')
ax.hist(y.values, weights=yweights, alpha=0.5,label='Retained')
titleText = 'Histogram of '+ col +'\n'+'valid pcnt ='+validRcdFmt+', Mean ='+mu + ', Std='+std+'\n max='+maxVal+', min='+minVal
ax.set(title= titleText, ylabel='% of Dataset in Bin')
ax.margins(0.05)
ax.set_ylim(bottom=0)
pyplot.legend(loc='upper right')
figSavePath = filepath+str(col)+'.png'
pyplot.savefig(figSavePath)
pyplot.close(1)
以上这段代码需要注意两点:
①刚开始我在画直方图时用的是这句代码:
ax.hist(x, weights=xweights, alpha=0.5,label='Attrition')
ax.hist(y, weights=yweights, alpha=0.5,label='Retained')
总是出现KeyError:0错误,查了很多资料发现matplotlib.pyplot.hist在画图时,是对数据从0开始检索,即从index为0的数值开始画起,
而我们里面的y开头的index并不为0,所以总是出先keyError:0错误。
②还是这句代码
xweights = 100.0 * np.ones_like(x) / x.size
ax.hist(x, weights=xweights, alpha=0.5,label='Attrition')
这里需要了解hist是如何画图的,以及里面的参数意义
直方图是一种能对值频率进行离散化显示的柱状图。数据点被拆分到离散的,间隔均匀的面元中,绘制的是各种数据点的数量。即是横坐标表示数据的
一个区间划分,纵坐标表示数据点出现在这个区间内,其频率为多少。
设置参数weigths,表示纵坐标不是表示频率,而是表示出现在这个区间内的数据点数量占总的数量的比值。
这里面是100.0 * np.ones_like(x) / x.size表示所占的百分比。
alpha参数表示画出的直方图的透明度为多少。这里设为0.5半透明,那么两个直方图重合在一起的地方就会变色。
我们看看“ASSET_MON_AVG_BAL(资产当前总余额)”这个单因子的初始分布:
NumVarPerf(AllData,'ASSET_MON_AVG_BAL','CHURN_CUST_IND',truncation=False) ##初始分布
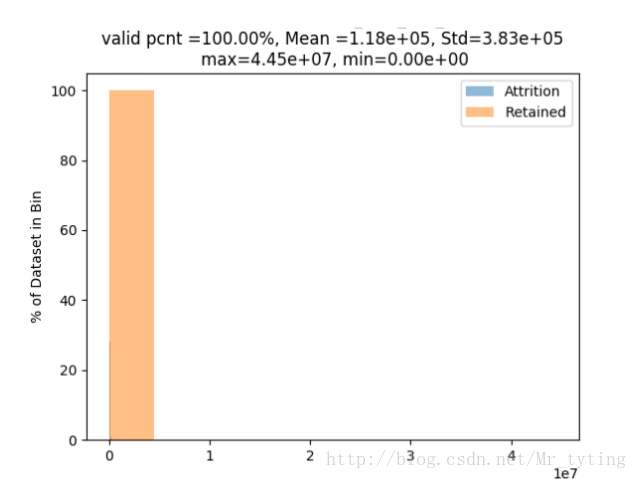
①横坐标表示余额的一些区间,纵坐标表示这个区间内所占总余额的百分比,从图上看,几乎看不出分布情况,为什么呢?
②我们看看这张图的title,valid_pcnt=100.0%:数据的有效记录占比100%,因为资产当前总余额这个字段是银行内部数据。
③这个字段的平均值Mean=1.18e+05,而max=4.45e+07,很明显这个最大值比平均值大了不止一个数量级。明显存在极端值。因为极端值的存在,导致看不出较小数据的分布情况。
那我们试试去掉极端值看看截断分布如何?
当前“ASSET_MON_AVG_BAL(资产当前总余额)”极端分布:095分位点以内的分布情况:
NumVarPerf(AllData,'ASSET_MON_AVG_BAL','CHURN_CUST_IND',truncation=True) ##截断分布
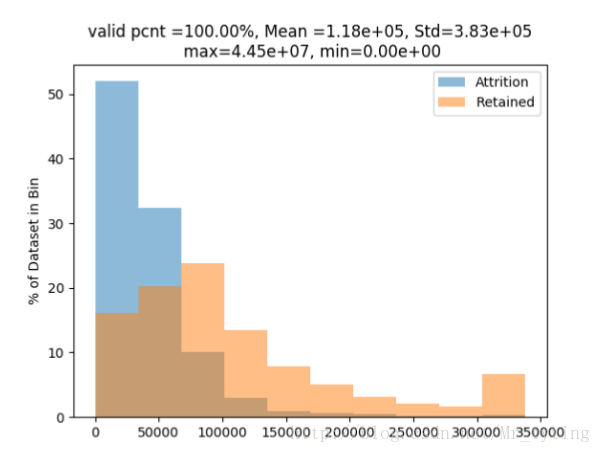
①这个时候从直方图分布就能看出,流失客户的余额基本上小于200000,资产较少,资产越少的客户流失量占总的流失客户数越大。
②高资产的客户流失则比较少。余额大于200000的客户基本上没有流失。
③这就说明了流失和非流失这两类在“ASSET_MON_AVG_BAL(资产当前总余额)”这个单因子上的差异还是比较明显的。
上面我们通过直方图得出流失和非流失这两类在“ASSET_MON_AVG_BAL(资产当前总余额)”这个单因子上的差异还是比较明显。那么这只是在直观上的感觉,现在希望对其差异进行量化的分析。
首先我们得了解下什么是单因子分析:
单因素方差分析:
(一)单因素方差分析概念理解步骤
①是用来研究一个控制变量的不同水平是否对观测变量产生了显著影响。这里,由于仅研究单个因素对观测变量的影响,因此称为单因素方差分析。
②单因素方差分析的第一步是明确观测变量和控制变量。例如,上述问题中的观测变量分别是农作物产量、妇女生育率、工资收入;控制变量
分别为施肥量、地区、学历。
③单因素方差分析的第二步是剖析观测变量的方差。方差分析认为:观测变量值的变动会受控制变量和随机变量两方面的影响。据此,单因素方差
分析将观测变量<<总的离差平方和分解为组间离差平方和和组内离差平方和两部分,用数学形式表述为:SST=SSA+SSE>>。
④单因素方差分析的第三步是通过比较观测变量总离差平方和各部分所占的比例,推断控制变量是否给观测变量带来了显著影响。
(二)单因素方差分析原理总结
容易理解:在观测变量总离差平方和中,如果组间离差平方和所占比例较大,则说明观测变量的变动主要是由控制变量引起的,可以主要由
控制变量来解释,控制变量给观测变量带来了显著影响;反之,如果组间离差平方和所占比例小,则说明观测变量的变动不是主要由控制变
量引起的,不可以主要由控制变量来解释,控制变量的不同水平没有给观测变量带来显著影响,观测变量值的变动是由随机变量因素引起的。
(三)单因素方差分析基本步骤
1、提出原假设:H0——无差异;H1——有显著差异
2、选择检验统计量:方差分析采用的检验统计量是F统计量,即F值检验。
3、计算检验统计量的观测值和概率P值:该步骤的目的就是计算检验统计量的观测值和相应的概率P值。
4、给定显著性水平,并作出决策。
说了这么多,其实就一句话:
总差异=组间差异+组内差异
当组间离差平方和所占比例较大,则说明观测变量的变动主要是由控制变量引起的,可以主要由控制变量来解释,控制变量给观测变量带来了显著影响;反之,如果组间离差平方和所占比例小,则说明观测变量的变动不是主要由控制变量引起的,不可以主要由控制变量来解释,控制变量的不同水平没有给观测变量带来显著影响,观测变量值的变动是由随机变量因素引起的。
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
result=anova_lm(ols('ASSET_MON_AVG_BAL~CHURN_CUST_IND',AllData).fit())
print result
打印结果:

这里得出的PR,p值小于0.05,p值越小,原假设越不成立,这里原假设指的是:在流失和非流失中,客户在“ASSET_MON_AVG_BAL(资产当前总余额)”这个单因子上没有显著性差异。故我们可以通过概率这种量化的方式得出结论:流失和不流失的人群在资产余额这个单因子上有显著性差异。
注:这里我们是用流失状态来得出对应资产状态是不同的,并不是用资产状态去预测是否流失。这是个相关性问题,不是因果性问题。
单因子分析之类别变量
1)有效记录的占比
2) 种类
3)整体分布
4)按目标变量分布的差异
类别性变量画图代码:
def CharVarPerf(df,col,target,filepath):
'''
:param df: the dataset containing numerical independent variable and dependent variable
:param col: independent variable with numerical type
:param target: dependent variable, class of 0-1
:param filepath: the location where we save the histogram
:return: the descriptive statistics
'''
validDf = df.loc[df[col] == df[col]][[col, target]]
validRcd = validDf.shape[0]*1.0/df.shape[0]
recdNum = validDf.shape[0]
validRcdFmt = "%.2f%%"%(validRcd*100)
freqDict = {}
churnRateDict = {}
#for each category in the categorical variable, we count the percentage and churn rate
for v in set(validDf[col]):
vDf = validDf.loc[validDf[col] == v]
freqDict[v] = vDf.shape[0]*1.0/recdNum
churnRateDict[v] = sum(vDf[target])*1.0/vDf.shape[0]
descStats = pd.DataFrame({'percent':freqDict,'churn rate':churnRateDict})
fig = pyplot.figure() # Create matplotlib figure
ax = fig.add_subplot(111) # Create matplotlib axes
ax2 = ax.twinx() # Create another axes that shares the same x-axis as ax.
pyplot.title('The percentage and churn rate for '+col+'\n valid pcnt ='+validRcdFmt)
descStats['churn rate'].plot(kind='line', color='red', ax=ax)
descStats.percent.plot(kind='bar', color='blue', ax=ax2, width=0.2,position = 1)
ax.set_ylabel('churn rate')
ax2.set_ylabel('percentage')
figSavePath = filepath+str(col)+'.png'
pyplot.savefig(figSavePath)
pyplot.close(1)
我们以性别这个类别性变量为例:
CharVarPerf(AllData,'GENDER_CD','CHURN_CUST_IND',filepath)
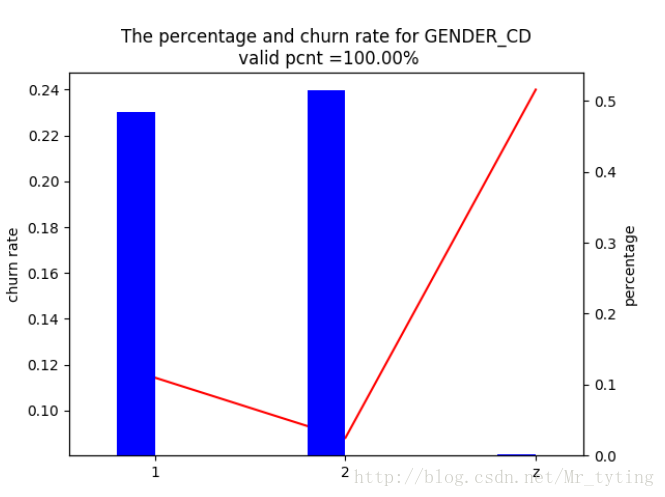
上图中蓝色柱状图,1表示女性,2,表示男性,z表未知,对应右边percentage,表示女性,男性,未知,占总人数的占比情况,未知人数很少
可以忽略不计,红线表示流失占比,对应左边churn_rate。
由上图可知三点:
①:绝大多数性别已知
②:已知性别中,男性占比比较高
③:男性流失率低于女性
④:未知性别的客户流失率显著高于已知性别客户。
那么如何用量化的方式去检验得出这些结论呢?
首先了解卡方检验
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,
越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合。
注意:卡方检验针对分类变量。
(1)提出原假设:
H0:总体X的分布函数为F(x)
如果总体分布为离散型,则假设具体为H0:总体X的分布律为P{X=xi}=pi, i=1,2,...
(2)将总体X的取值范围分成k个互不相交的小区间A1,A2,A3,…,Ak,如可取
A1=(a0,a1],A2=(a1,a2],...,Ak=(ak-1,ak),
其中a0可取-∞,ak可取+∞,区间的划分视具体情况而定,但要使每个小区间所含的样本值个数不小于5,而区间个数k不要太大也不要太小。
(3)把落入第i个小区间的Ai的样本值的个数记作fi,成为组频数(真实值),所有组频数之和f1+f2+...+fk等于样本容量n。
(4)当H0为真时,根据所假设的总体理论分布,可算出总体X的值落入第i 个小区间Ai的概率pi,于是,npi就是落入第i个小区间Ai的样本值的
理论频数(理论值)。
(5)当H0为真时,n次试验中样本值落入第i个小区间Ai的频率fi/n与概率pi应很接近,当H0不真时,则fi/n与pi相差很大。
基于这种思想,皮尔逊引进如下检验统计量(下图公式),在0假设成立的情况下服从自由度为k-1的卡方分布。
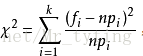
差异的量化:用卡方检验来衡量某因子对目标变量的偏好。
原理:如果某因子跟目标变量独立,(即该因子对目标变量影响较小)则目标变量在该因子上的分布是均匀的,即卡方值应该较小。用来衡量类别性变量分布的差异性。
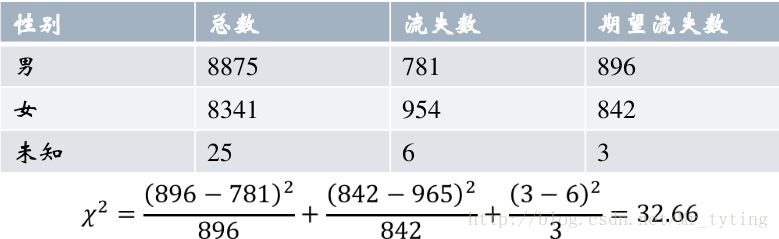
计算卡方值代码:
chisqDf = AllData[['GENDER_CD','CHURN_CUST_IND']]
grouped = chisqDf['CHURN_CUST_IND'].groupby(chisqDf['GENDER_CD'])##以GENDER_CD(性别)对CHURN_CUST_IND(是否流失,0,1)进行分组
count = list(grouped.count()) # 按性别(男,女,未知)分组,计算每组有多少个CHURN_CUST_IND,也就是统计男性人数,女性人数,未知人数
churn = list(grouped.sum()) # 按性别(男,女,未知)分组,对每组内所有的CHURN_CUST_IND求和,也就是统计男性中流失人数,女性中流失人数等
chisqTable = pd.DataFrame({'total':count,'churn':churn})
chisqTable['expected'] = chisqTable['total'].map(lambda x: round(x*0.101))
chisqValList = chisqTable[['churn','expected']].apply(lambda x: (x[0]-x[1])**2/x[1], axis=1)
chisqVal = sum(chisqValList)
print chisqVal
得出同样结果:32.6579
当然可以引入相关的包来计算卡方值:
from scipy.stats import chisquare
print chisquare(chisqTable['churn'],chisqTable['expected'])
首先我们根据之前给出数据总的人群流失率为10.10%,假设性别对目标变量(客户是否流失)没有影响,两者相互独立,那么男性,女性分布的流失率应该也在10.10%左右,即可算出其期望流失数。再根据真实的流失数算出卡方值为32.66,。通过查表,我们得知:在自由度为2,置信度为0.05下的卡方分为点为5.99.其32.66大于5.99,那么可得出结论,性别这个变量对其目标变量差异性显著。
多因子分析
- 变量直接由于业务关系,计算逻辑等因素存在一定的两两共线性(呈正相关或者负相关),需要研究这种共线性并做出适当的处理。
- 信息的冗余(注意只是对于一阶的线性关系,可能会冗余)
- 维护数据的成本(当一个变量可以代替另外一个变量时,我们可以去掉其中一个变量)
- 对某些模型存在一定的影响(在线性回归模型中,我们假设两个变量x1,x2具有很强的相关性,那么在求
中的
很有可能是奇异的,就是不可逆的)
随机选取15个连续性变量,画出其散点矩阵图,得出两两直接的相关性
from pandas.tools.plotting import scatter_matrix
corrCols = random.sample(numericCols,15)
sampleDf = AllData[corrCols]
for col in corrCols:
sampleDf.rename(columns = {col:col_to_index[col]}, inplace = True)
scatter_matrix(sampleDf, alpha=0.2, figsize=(6, 6), diagonal='kde')
其实这篇博文讲的主要是机器学习里面的特征选择部分,在单因子分析中,如果某个变量对目标变量影响不大甚至完全独立,那么可以去掉这个变量。
如果两个变量相关性很高,其中一个变量解释性比较高,另外一个变量解释性比较低时,即使解释性比较低的变量效果更好一些,我们也会将其去掉,保留解释性比较高的那个变量。当然这是在回归模型中(奇异性问题)。其他模型不需要剔除。
在做模型时,首先是做单因素分析,剔除那些缺失度比较高的,对结果影响不大的变量。














 3087
3087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









