









http://blog.csdn.net/pipisorry/article/details/24574293
基础


拐点
若曲线图形在一点由凸转凹,或由凹转凸,则称此点为拐点。直观地说,拐点是使切线穿越曲线的点。
拐点的必要条件:设







拐点的充分条件:设


牛顿法和拟牛顿法(Newton's method & Quasi-Newton Methods)
牛顿法(Newton's method)
又称为牛顿-拉弗森方法(Newton-Raphson method),单变量下又称为切线法。它是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。用牛顿迭代法解非线性方程,是把非线性方程f(x) = 0线性化的一种近似方法。
把f(x)在点x0的某邻域内展开成泰勒级数
取其线性部分(即泰勒展开的前两项),并令其等于0,即,以此作为非线性方程f(x) = 0的近似方程
这样,得到牛顿迭代法的一个迭代关系式
已经证明,如果f ' 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ' (x)不为0, 那么牛顿法将具有平方收敛的性能。粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法的搜索路径(二维情况)如下图所示:
牛顿法搜索动态示例图:

牛顿法应用于最优化
牛顿法求解非线性函数的最优值点。那牛顿法和极值求解有关系?看起来牛顿法只能求零点啊? 一阶导零点不就是函数的极值或者驻点?
1 直接通过求解f(x) = 0的解修改得到
牛顿法是求解f(x) = 0的解而不是求极小值(当然求f'(x) = 0就是求解f(x)极小值了),且f(xn)/f'(xn)不就是x轴移动的距离吗。
牛顿法极值求解迭代公式如下
对于高维函数,用牛顿法求极值也是这个形式,只不过这里的y'和y''都变成了矩阵和向量。而且你也可以想到,高维函数二阶导有多个,写成矩阵的形式Hessian矩阵:
y'就变成了对所有参数的偏导数组成的向量
迭代公式
然而算的可能非常慢,数也可能很大。简单的解决办法,有一种叫做批迭代的方法,不管是在梯度计算极值还是在牛顿计算极值上都是可行的,就是假设失去大部分点对准确度没有太大的影响,比如说3个在一条直线上的点,去掉一个也没什么关系,最后反正还是会拟合成同一个参数。批迭代就是在众多的点中随机抽取一些,进行迭代计算,再随机抽取一些再进行迭代。迭代的路径可能不完美,但是最终还是会找到我们想要的答案。(有点类似mini-batch)
当然还有其他更帅的解决方法,祝如DFP,BFGS,Broyden。
2 f(x)在点x0的某邻域内泰勒级数二阶展开(更严谨)



或者使用统计学习方法里面N>1的方式


牛顿最优化方法

牛顿迭代法评价
关于牛顿法和梯度下降法的效率对比
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
Note: lz梯度下降的改进如moment就考虑更多了。
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。

注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
牛顿迭代法的优缺点
牛顿法优点:二阶收敛,收敛速度快;
牛顿法可以求最优化问题,而且求解精确,一般用牛顿法求得的解成为ground-truth。
牛顿法缺点:
1 牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
二阶方法实践中对高维数据不可行。infeasible to compute in practice for high-dimensional data sets, e.g. second-order methods such as Newton's method.
2 可能发生被零除错误。当函数在它的零点附近,导函数的绝对值非常小时,运算会出现被零除错误。
3 是可能出现死循环。当函数在它的零点有拐点时,可能会使迭代陷入死循环。
Note:f(x) = arctanx, 2阶导产生(拐点) f''(x*) = 0。
4 定步长迭代。改进是阻尼牛顿法。

[最优化问题中,牛顿法为什么比梯度下降法求解需要的迭代次数更少? - 知乎]
牛顿迭代法不成功的反例
1 f(x) = x^3 - 3x + 2 = 0。 | f'(x) |很小,零除错误。
2 达到极小值?

3 死循环


以上反例说明,牛顿迭代法局部收敛性要求初始点要取得合适,否则导致错误结果.
牛顿法收敛性分析
牛顿法为什么能收敛
一个直观解释
H正定(则H^-1亦正定),那么可以保证牛顿法搜索方向-gk是下降方向。

收敛证明
不动点迭代收敛的定理2.5和定理2.4可以证明,具体省略。[最优化方法:非线性方程的求极值方法]
牛顿迭代法局部收敛定理
上面示例提到牛顿法可能不收敛,下面讨论确保牛顿法收敛的条件。

条件(1)保证了根的存在; 条件(2)要求f(x)是单调函数,且f(x)在a,b上是凸向上或凹向下; 条件(3)保证当xn∈a,b时,有xn+1=φ(x)∈a,b.
关于条件(3),取x0∈a,b使得f(x0)f′′(x0)>0的注记如下:
如果f(x)的二阶导数大于零,则函数图形是凹曲线(有时定义不一样,还是看f''(x)吧).根据条件(3),在方程f(x)=0中,如果函数f''(x)>0,则应取牛顿迭代的初始点使得f(x0)>0;否则,应取f(x0)<0!!!
牛顿迭代法的收敛阶
对于牛顿迭代法,其迭代函数为
于是
假定x是f(x)=0的单根,即f(x)=0,f′(x)≠0,则φ′(x)=0,根据[最优化方法:非线性方程的求极值方法]高阶收敛定理2.6可以断定,牛顿迭代法在根*x附近至少平方收敛.

Note: 收敛性质主要用在靠近x*时的收敛速度,其它地方一般因为梯度较大,下降得很快,主要速度在于快到达最优值时的收敛速度。
另一种直观解释

[牛顿法]
牛顿迭代法的变形
牛顿下山法
在牛顿迭代法中,当选取初值有困难时,可改用如下迭代格式,以扩大初值的选取范围,

其中λ称为下山因子,λ选取应满足单调性条件

这样的算法称下山法.将下山法和牛顿法结合起来使用的方法,称为牛顿下山法.
下山因子λ的选择是逐步探索的过程.从λ=1开始反复将λ减半进行试算,如果能定出λ使单调性条件成立则“下山成功”.与此相反,如果找不到使单调性条件成立的λ,则“下山失败”.此时需另选初值x0重算.
弦截法
为了避免计算导数,在牛顿迭代格式(2.8)中,用差商
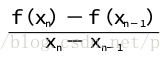
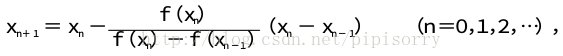
该迭代格式被称为弦截法.
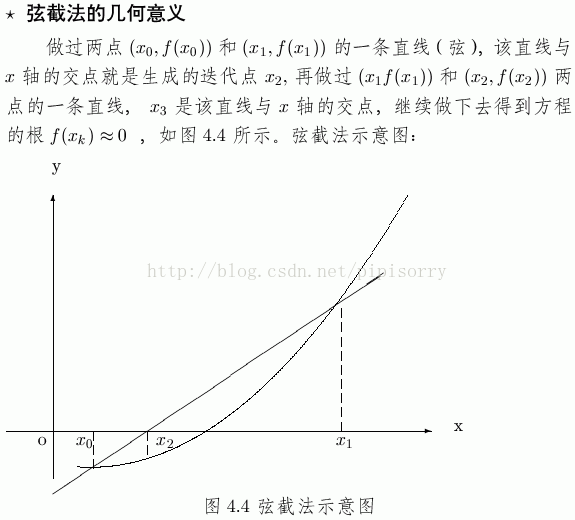
从几何上看,式(2.10)实际上是由曲线上两点(xn-1,f(xn-1))和(xn,f(xn))确定割线,该割线与x轴交点的横坐标即为xn+1,故弦截法又称为割线法.
弦截法和牛顿迭代法都是线性化方法,牛顿迭代法在计算xn+1时只用到前一步的值xn,而弦截法用到前面两步的结果xn和xn-1,因此使用弦截法必须先给出两个初值值x0,x1.
弦截法收敛速度稍慢于牛顿法
设f(x)在x*附近二阶连续可微,且f(x*)=0,f′(x*)≠0,则存在δ>0,当x0,x1∈[x*-δ,x*+δ],由弦截法产生的序列{xn}收敛于x*,且收敛阶至少为1.618.
阻尼牛顿法
虽然Newton法具有二阶局部收敛性,但它要求 F′(x∗) 非奇异。如果矩阵 F′(x∗) 奇异或病态,那么 F′(x(k) 也可能奇异或病态,从而可能导致数值计算失败或产生数值不稳定。这时可使用阻尼牛顿法,即把牛顿法的迭代公式改成,其中的参数 μk 称为阻尼因子, μkI 称为阻尼项。增加阻尼项的目的,是使线性方程的系数矩阵非奇异并良态。当 μk 选得很合适时,阻尼Newton法是线性收敛的。
另一种等价解释
阻尼牛顿法其实就是牛顿法增加了一个沿牛顿方向的一维搜索。


计算重根的牛顿迭代法

该迭代格式具有至少二阶收敛性质.但在实际计算时,往往并不知道重数m,因而并不能直接使用式(2.11).为此定义函数

该迭代格式至少是二阶收敛.
拟牛顿法(Quasi-Newton Methods)
拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度(类似于弦截法,导数 F′(x) 需要近似);而且有时候目标函数的H矩阵无法保证正定。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
这样的迭代与牛顿法类似,区别就在于用近似的Hesse矩阵Bk
拟牛顿条件
亦称拟牛顿方程或者割线条件(割线方程),用于指出近似的矩阵应该满足的条件。


满足拟牛顿条件的几种算法


[ BFGS 算法 ]
[ L-BFGS 算法]
[[原创] 拟牛顿法/Quasi-Newton,DFP算法/Davidon-Fletcher-Powell,及BFGS算法/Broyden-Fletcher-Goldfarb-Shanno]
Wolf条件:步长的一维非精确搜索

from: http://blog.csdn.net/pipisorry/article/details/24574293
ref: [非线性方程(组)的求解 ]
[中科大精品课程: http://www.bb.ustc.edu.cn/jpkc/xiaoji/szjsff/jsffkj/chapt4_1.htm]
[数值分析 电子科大 钟尔杰]
[最优化算法]















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









