










Dataset之diabetes:diabetes数据集的简介、下载、使用方法(比较八种机器学习算法实现二分类预测)之详细攻略
目录
Keras之DNN:利用DNN算法【Input(8)→12+8(relu)→O(sigmoid)】利用糖尿病数据集训练、评估模型(利用糖尿病数据集中的八个参数特征预测一个0或1结果)
Keras之DNN:利用DNN【Input(8)→(12+8)(relu)→O(sigmoid)】模型实现预测新数据(利用糖尿病数据集的八个特征进行二分类预测
Keras之MLP:利用MLP【Input(8)→(12)(relu)→O(sigmoid+二元交叉)】模型实现预测新数据(利用糖尿病数据集的八个特征实现二分类预测
ML之Xgboost:利用Xgboost模型对数据集(比马印第安人糖尿病)进行二分类预测(5年内是否患糖尿病)
ML之Xgboost:利用Xgboost模型(7f-CrVa+网格搜索调参)对数据集(比马印第安人糖尿病)进行二分类预测
ML之分类预测:以六类机器学习算法(kNN、逻辑回归、SVM、决策树、随机森林、提升树、神经网络)对糖尿病数据集(8→1)实现二分类模型评估案例来理解和认知机器学习分类预测的模板流程
ML之LiR&Lasso:基于datasets糖尿病数据集利用LiR和Lasso算法进行(9→1)回归预测(三维图散点图可视化)
ML之LassoR&RidgeR:基于datasets糖尿病数据集利用LassoR和RidgeR算法(alpha调参)进行(9→1)回归预测
diabetes数据集的简介
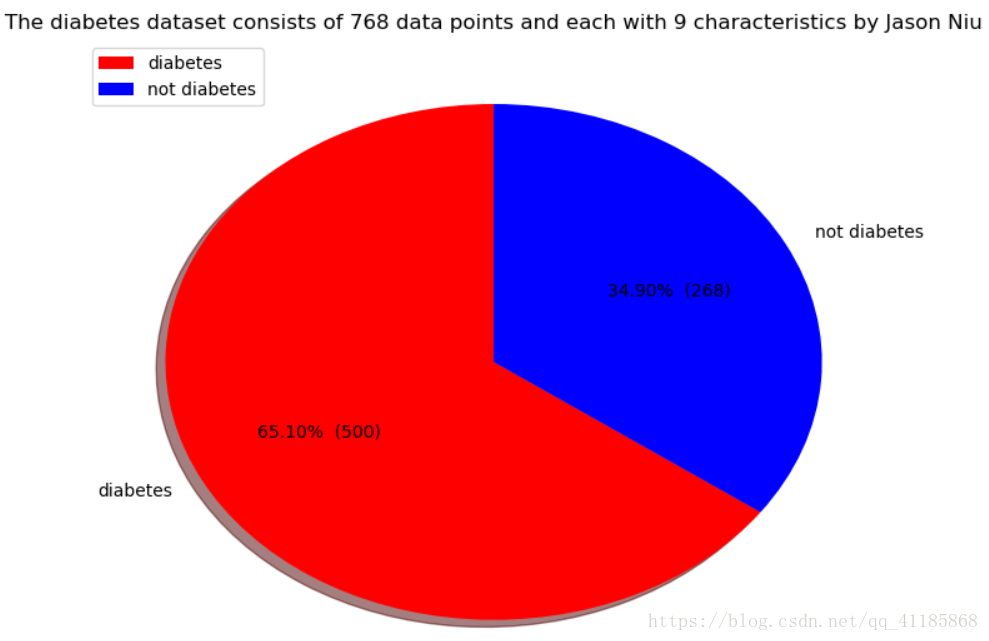
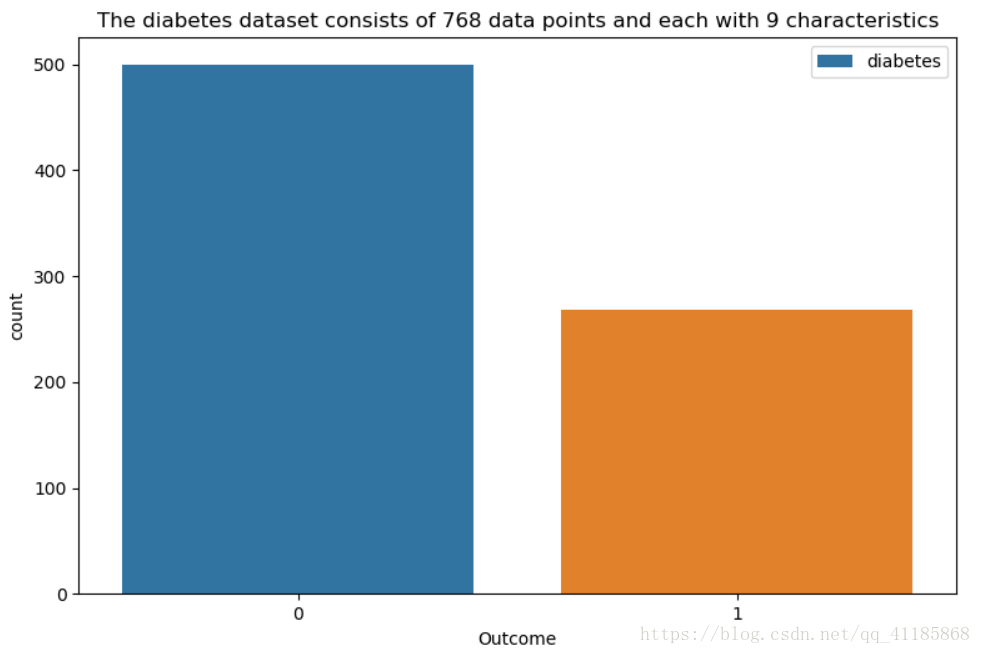
糖尿病数据集由768个数据点组成,各有9个特征。输出表格的列表字段;9个特征(怀孕次数,血糖,血压,皮脂厚度,胰岛素,BMI身体质量指数,糖尿病遗传函数,年龄,结果)。在768个数据点中,500个被标记为0,268个标记为1。将要预测的特征,0意味着未患糖尿病,1意味着患有糖尿病。
1、数据集描述
data.shape: (768, 9)
data.columns:
Index(['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin',
'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'],
dtype='object')
data.head:
Pregnancies Glucose BloodPressure ... DiabetesPedigreeFunction Age Outcome
0 6 148 72 ... 0.627 50 1
1 1 85 66 ... 0.351 31 0
2 8 183 64 ... 0.672 32 1
3 1 89 66 ... 0.167 21 0
4 0 137 40 ... 2.288 33 1
[5 rows x 9 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pregnancies 768 non-null int64
1 Glucose 768 non-null int64
2 BloodPressure 768 non-null int64
3 SkinThickness 768 non-null int64
4 Insulin 768 non-null int64
5 BMI 768 non-null float64
6 DiabetesPedigreeFunction 768 non-null float64
7 Age 768 non-null int64
8 Outcome 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
data.info:
None
8
data_column_X: ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
diabetes数据集的下载
地址:Resources/data_csv_xls/diabetes.csv
diabetes数据集的使用方法
1、基础案例
Keras之DNN:利用DNN算法【Input(8)→12+8(relu)→O(sigmoid)】利用糖尿病数据集训练、评估模型(利用糖尿病数据集中的八个参数特征预测一个0或1结果)
https://yunyaniu.blog.csdn.net/article/details/84252981
Keras之DNN:利用DNN【Input(8)→(12+8)(relu)→O(sigmoid)】模型实现预测新数据(利用糖尿病数据集的八个特征进行二分类预测
https://yunyaniu.blog.csdn.net/article/details/84282510
Keras之MLP:利用MLP【Input(8)→(12)(relu)→O(sigmoid+二元交叉)】模型实现预测新数据(利用糖尿病数据集的八个特征实现二分类预测
https://yunyaniu.blog.csdn.net/article/details/84314548
ML之Xgboost:利用Xgboost模型对数据集(比马印第安人糖尿病)进行二分类预测(5年内是否患糖尿病)
https://yunyaniu.blog.csdn.net/article/details/88360520
ML之Xgboost:利用Xgboost模型(7f-CrVa+网格搜索调参)对数据集(比马印第安人糖尿病)进行二分类预测
https://yunyaniu.blog.csdn.net/article/details/88367398
ML之分类预测:以六类机器学习算法(kNN、逻辑回归、SVM、决策树、随机森林、提升树、神经网络)对糖尿病数据集(8→1)实现二分类模型评估案例来理解和认知机器学习分类预测的模板流程
https://yunyaniu.blog.csdn.net/article/details/108342397
ML之LiR&Lasso:基于datasets糖尿病数据集利用LiR和Lasso算法进行(9→1)回归预测(三维图散点图可视化)
https://yunyaniu.blog.csdn.net/article/details/110100977
ML之LassoR&RidgeR:基于datasets糖尿病数据集利用LassoR和RidgeR算法(alpha调参)进行(9→1)回归预测
https://yunyaniu.blog.csdn.net/article/details/110209313
2、进阶案例:采用七种机器学习模型来进行分类预测
了解了它们的优缺点是什么,以及如何控制其模型复杂度。结果可知,对于许多算法来说,设置正确的参数对于性能良好是非常重要的。
输出结果
1、k-NN
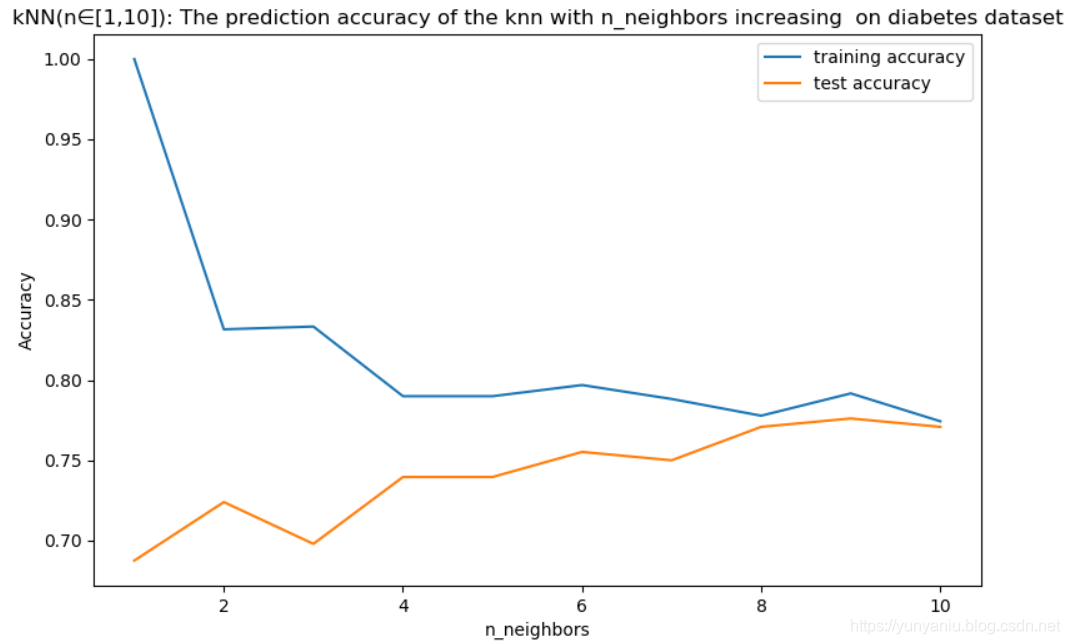
k-NN:Accuracy of K-NN classifier on training set: 0.79
k-NN:Accuracy of K-NN classifier on test set: 0.78
![]()
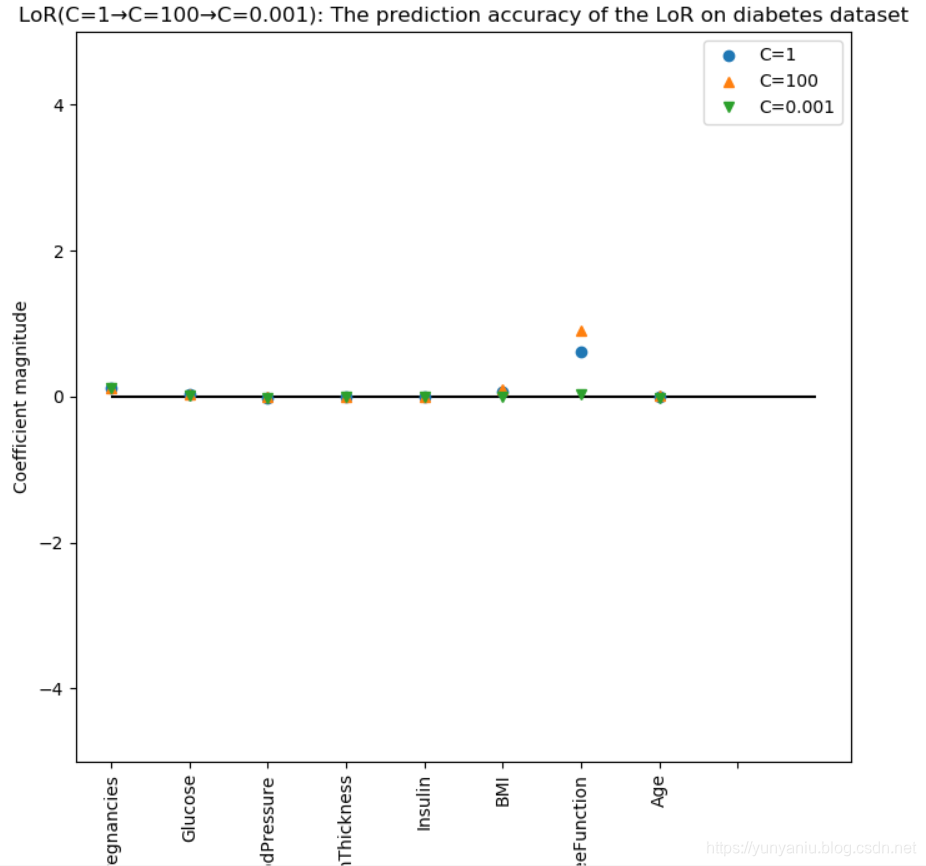
2、LoR
# 
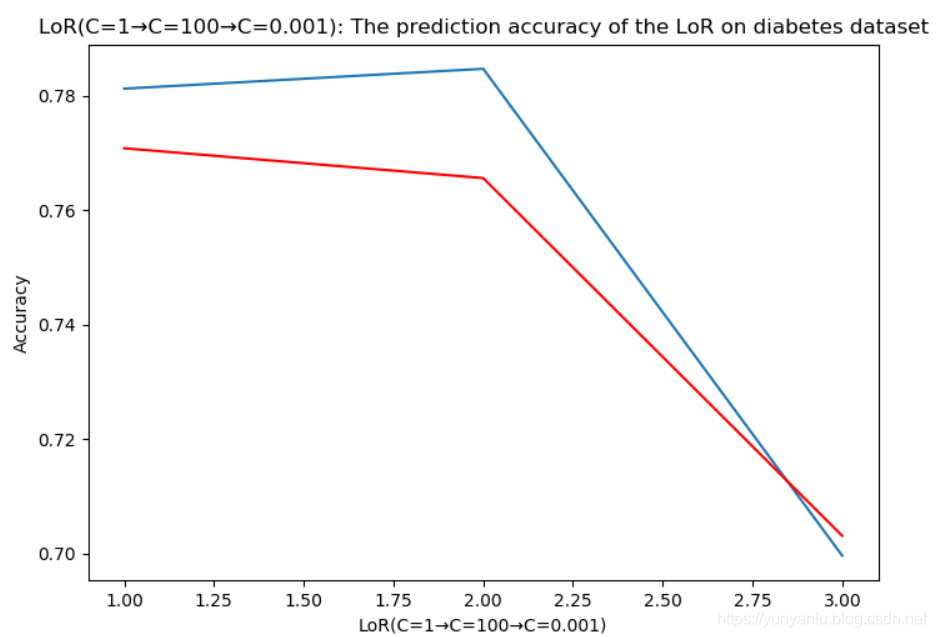
![]()
![]()
![]()
LoR:C1 Training set accuracy: 0.781
LoR:C1 Test set accuracy: 0.771
LoR:C100 Training set accuracy: 0.785
LoR:C100 Test set accuracy: 0.766
LoR:C001 Training set accuracy: 0.700
LoR:C001 Test set accuracy: 0.703
4、DT
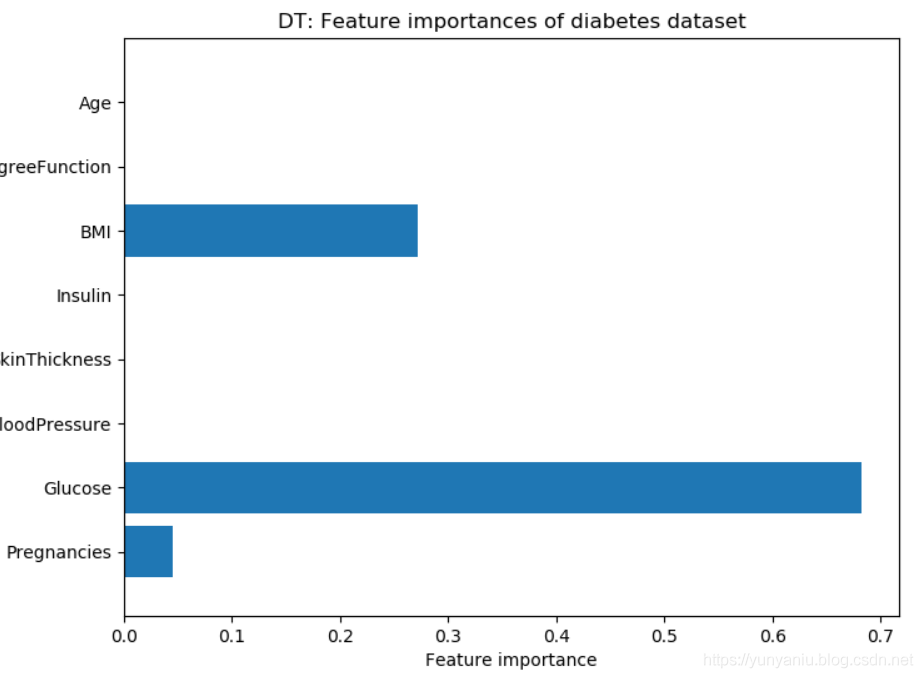
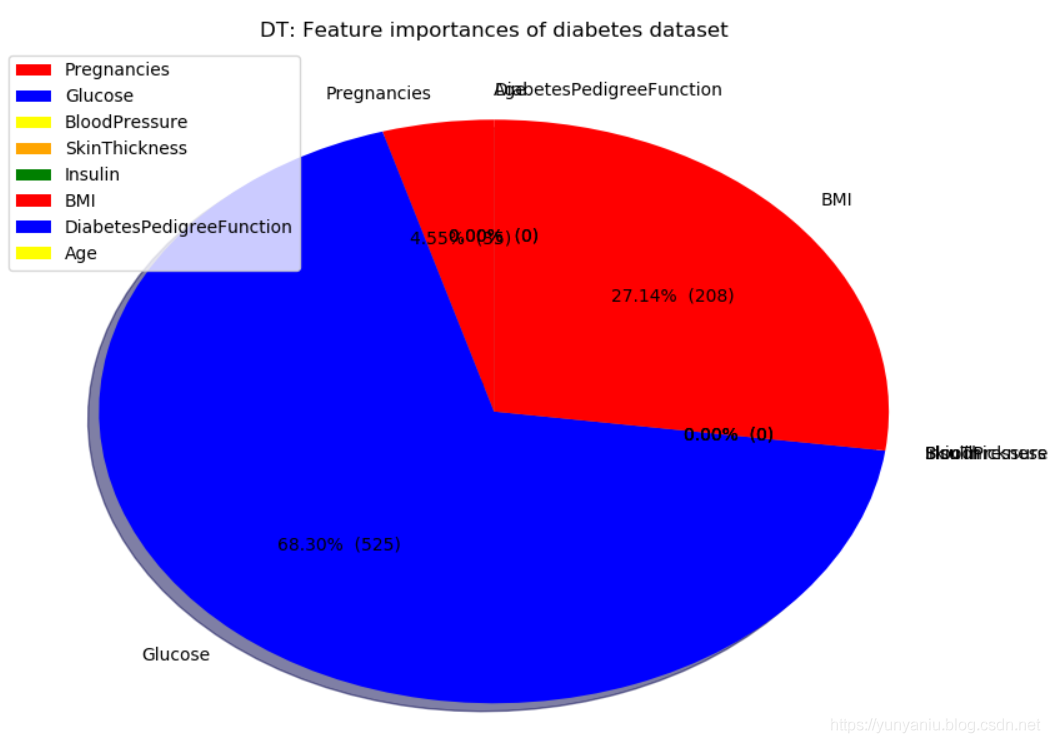
DT:Accuracy on training set: 1.000
DT:Accuracy on test set: 0.714
DT:Accuracy on training set: 0.773
DT:Accuracy on test set: 0.740
5、RF
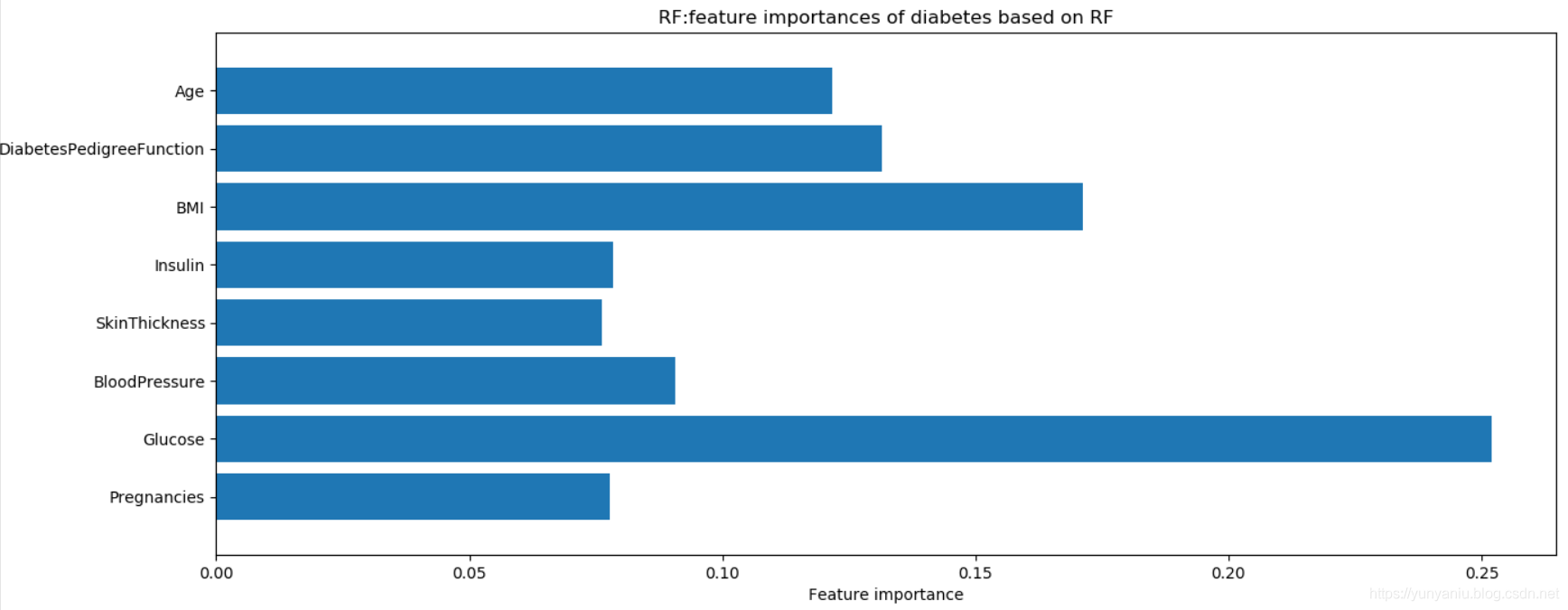
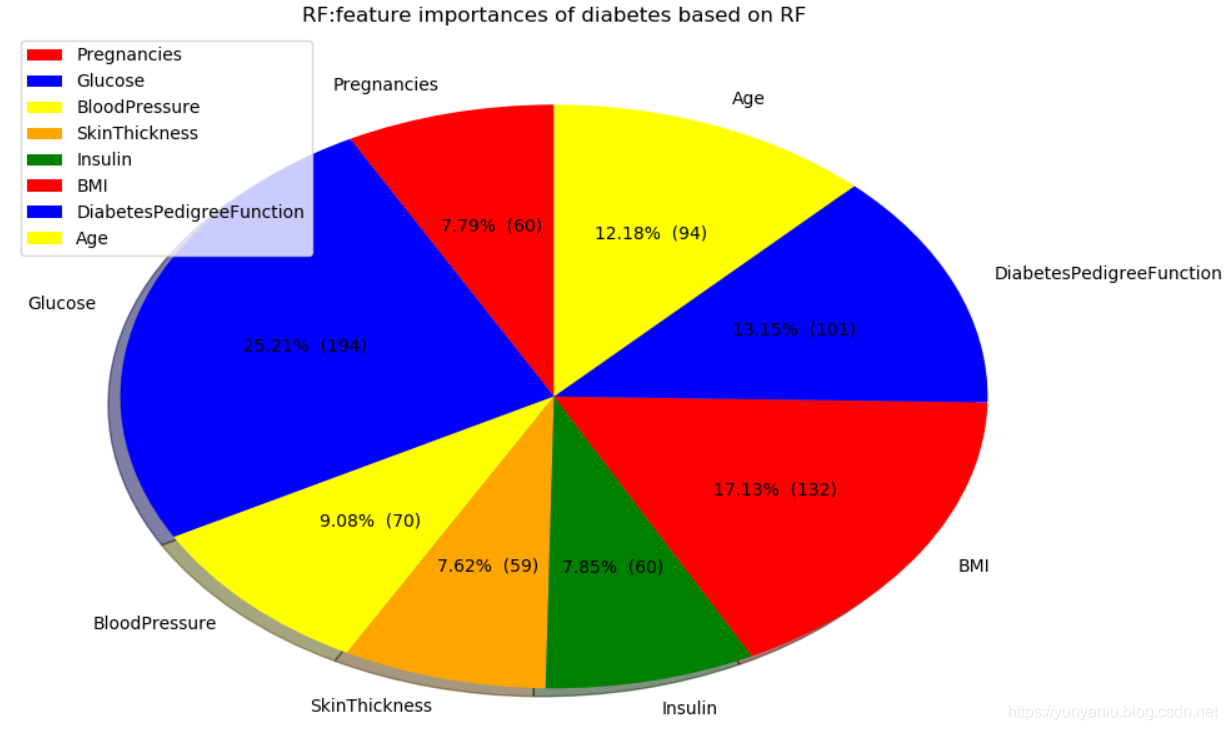
![]()
![]()
RF:Accuracy on training set: 1.000
RF:Accuracy on test set: 0.786
RF:max_depth=3 Accuracy on training set: 0.800
RF:max_depth=3 Accuracy on test set: 0.755
6、GB
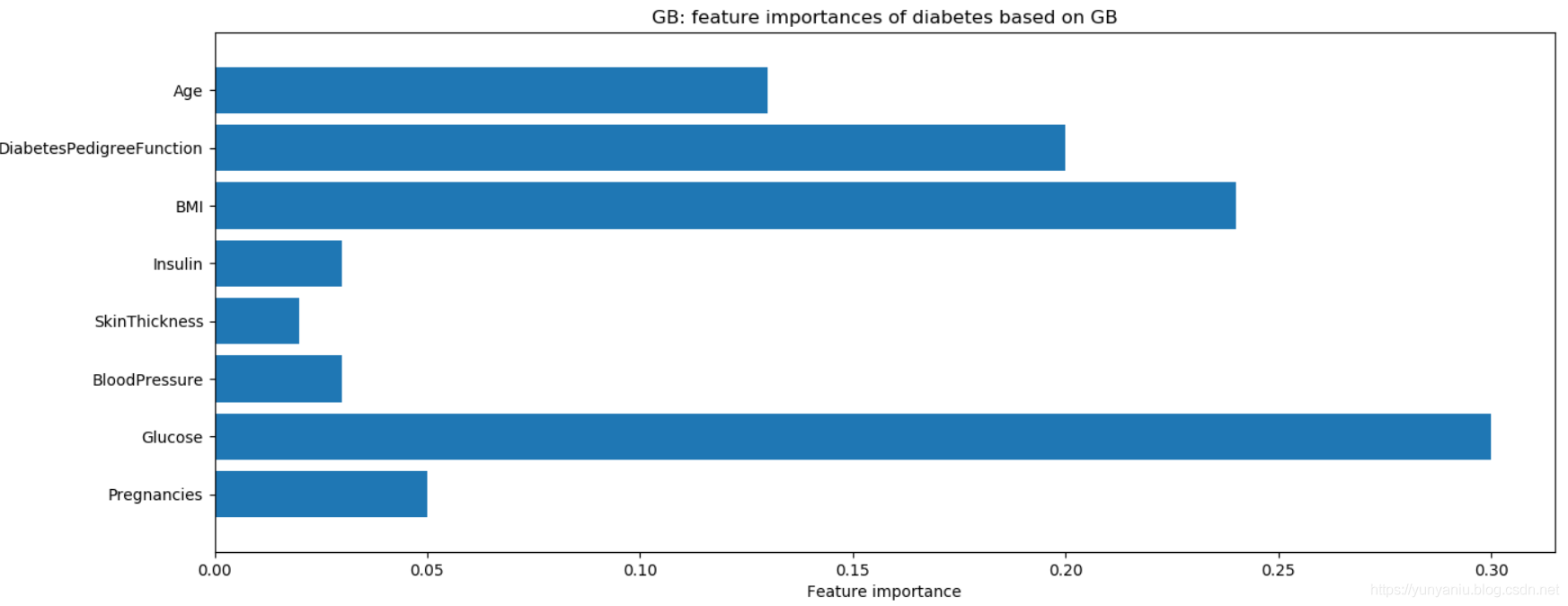
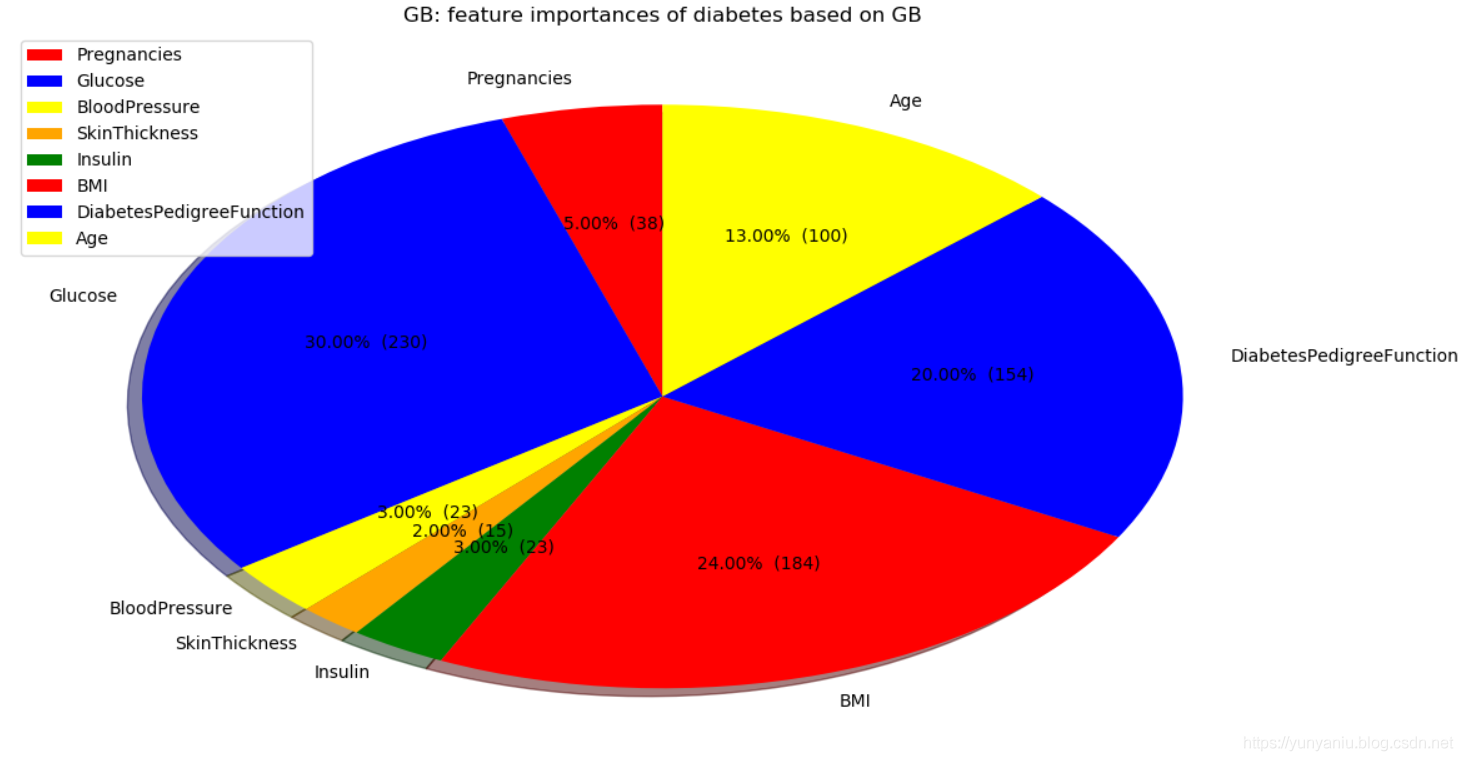
GB:Accuracy on training set: 0.917
GB:Accuracy on test set: 0.792
GB:Accuracy on training set: 0.804
GB:Accuracy on test set: 0.781
GB:Accuracy on training set: 0.802
GB:Accuracy on test set: 0.776
7、SVM
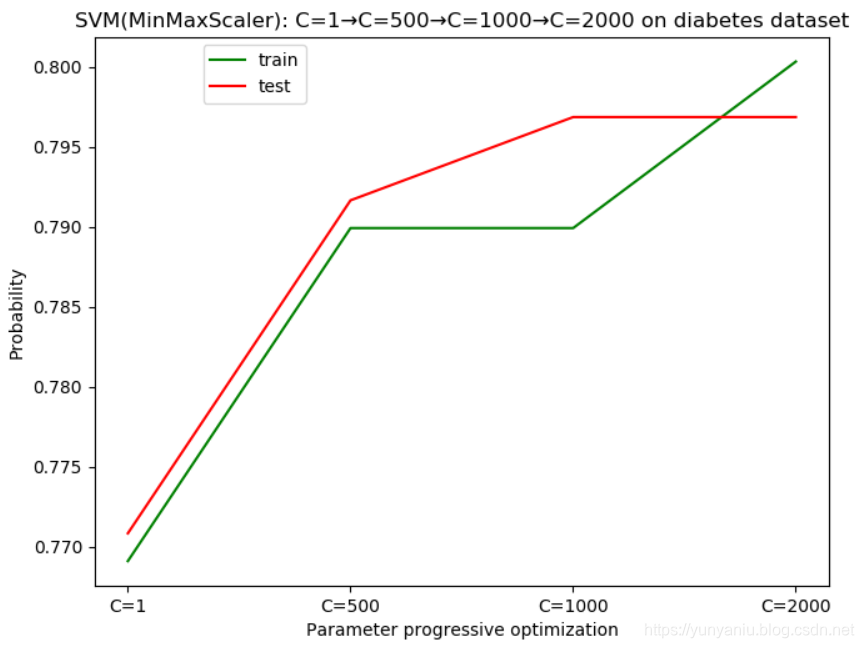
![]()
![]()
![]()
![]()
![]()
SVM:Accuracy on training set: 1.00
SVM:Accuracy on test set: 0.65
SVM:MinMaxScaler Accuracy on training set: 0.77
SVM:MinMaxScaler Accuracy on test set: 0.77
SVM:C=500 Accuracy on training set: 0.790
SVM:C=500 Accuracy on test set: 0.792
SVM:C=1000 Accuracy on training set: 0.790
SVM:C=1000 Accuracy on test set: 0.797
SVM:C=2000 Accuracy on training set: 0.800
SVM:C=2000 Accuracy on test set: 0.797
8、NN
利用多层神经网络
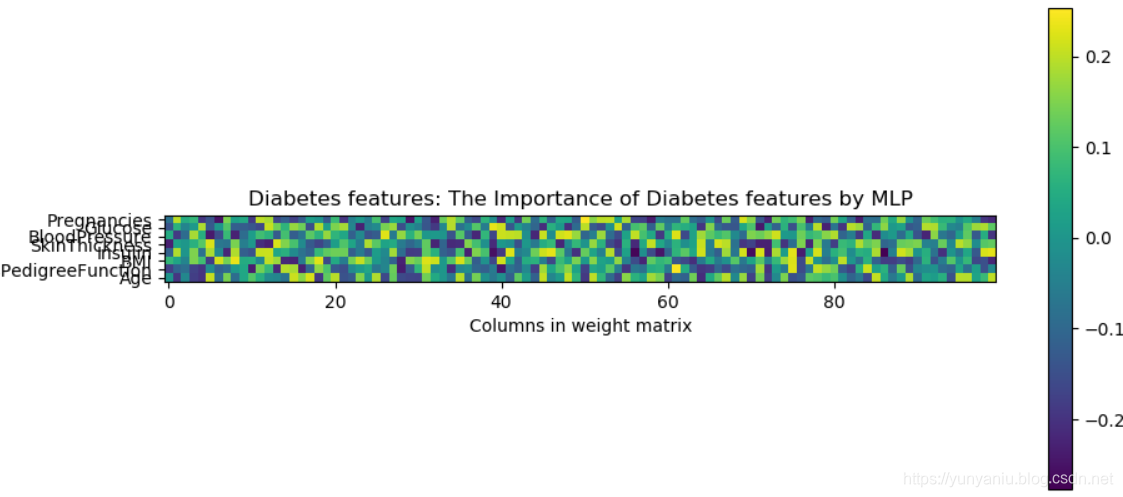
![]()
![]()
![]()
![]()
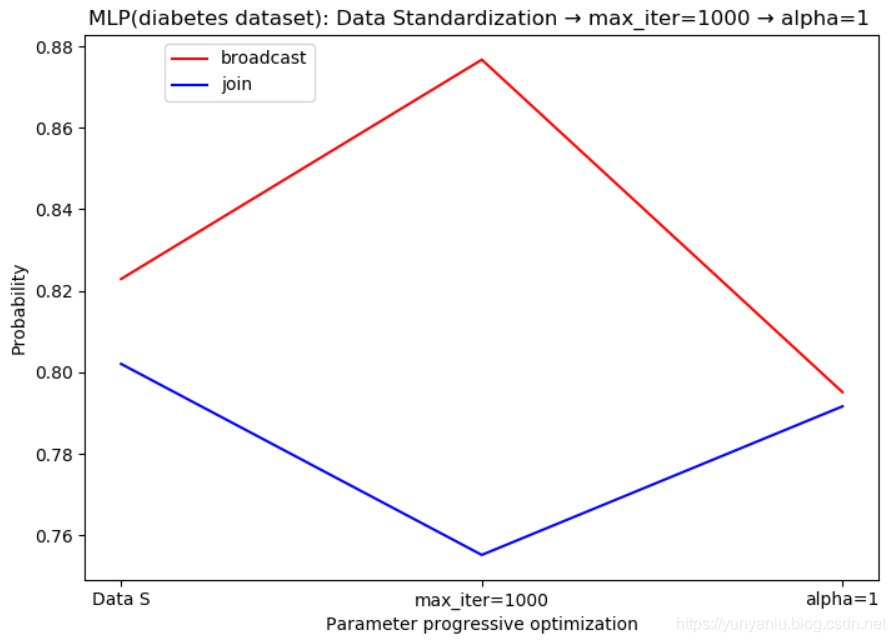
NN:Data standardization—Accuracy on training set: 0.823
NN:Data standardization—Accuracy on test set: 0.802
NN:Data standardization(max_iter=1000)—Accuracy on training set: 0.877
NN:Data standardization(max_iter=1000)—Accuracy on test set: 0.755
NN:Data standardization(max_iter=1000,alpha=1)—Accuracy on training set: 0.795
NN:Data standardization(max_iter=1000,alpha=1)—Accuracy on test set: 0.792
设计思路
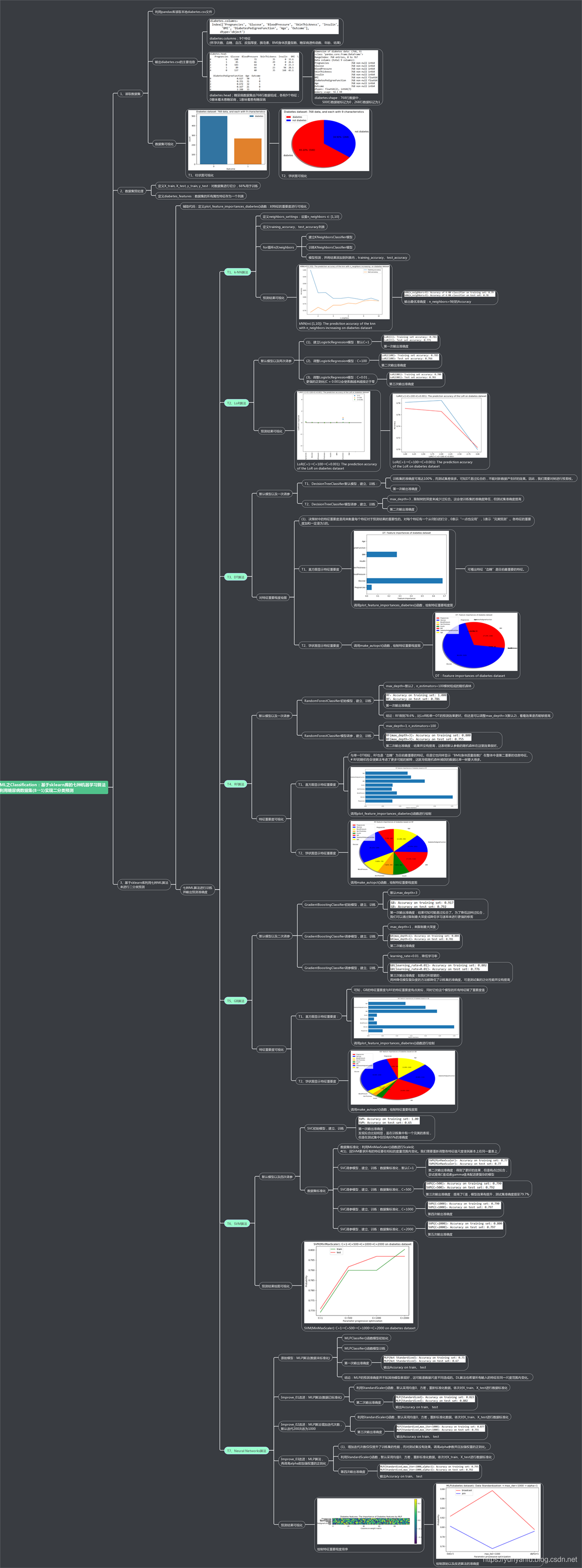
相关文章
ML之Classification:基于sklearn库的七八种机器学习算法利用糖尿病(diabetes)数据集(8→1)实现二分类预测
















 5616
5616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











