







 SPP-net解决了深度学习网络输入尺寸固定的问题,通过空间金字塔池化层,实现任意尺寸输入并输出固定长度特征。在RCNN基础上,SPP-net提高了目标检测速度,降低了计算成本。它将全连接层前移,允许对整幅图像进行一次卷积,随后使用SPP层进行多尺度池化,确保不同尺寸ROI的特征向量长度一致。SPP层包含多个尺度的池化区域,如6x6、3x3、2x2和1x1,使得网络能够处理不同尺度的输入图像。在训练时,采用多尺度输入,而在测试时可直接应用SPP-net于任意尺寸的图像。
SPP-net解决了深度学习网络输入尺寸固定的问题,通过空间金字塔池化层,实现任意尺寸输入并输出固定长度特征。在RCNN基础上,SPP-net提高了目标检测速度,降低了计算成本。它将全连接层前移,允许对整幅图像进行一次卷积,随后使用SPP层进行多尺度池化,确保不同尺寸ROI的特征向量长度一致。SPP层包含多个尺度的池化区域,如6x6、3x3、2x2和1x1,使得网络能够处理不同尺度的输入图像。在训练时,采用多尺度输入,而在测试时可直接应用SPP-net于任意尺寸的图像。
基础框架:
CNN网络需要固定尺寸的图像输入,SPPNet将任意大小的图像池化生成固定长度的图像表示,提升R-CNN检测的速度24-102倍。
固定图像尺寸输入的问题,截取的区域未涵盖整个目标或者缩放带来图像的扭曲。
事实上,CNN的卷积层不需要固定尺寸的图像,全连接层是需要固定大小输入的,因此提出了SPP层放到卷积层的后面,改进后的网络如下图所示:
SPP是BOW的扩展,将图像从精细空间划分到粗糙空间,之后将局部特征聚集。在CNN成为主流之前,SPP在检测和分类的应用比较广泛。
SPP的优点:
1)任意尺寸输入,固定大小输出
2)层多
3)可对任意尺度提取的特征进行池化。
理解池化:
说下池化,其实池化很容易理解,先看图:
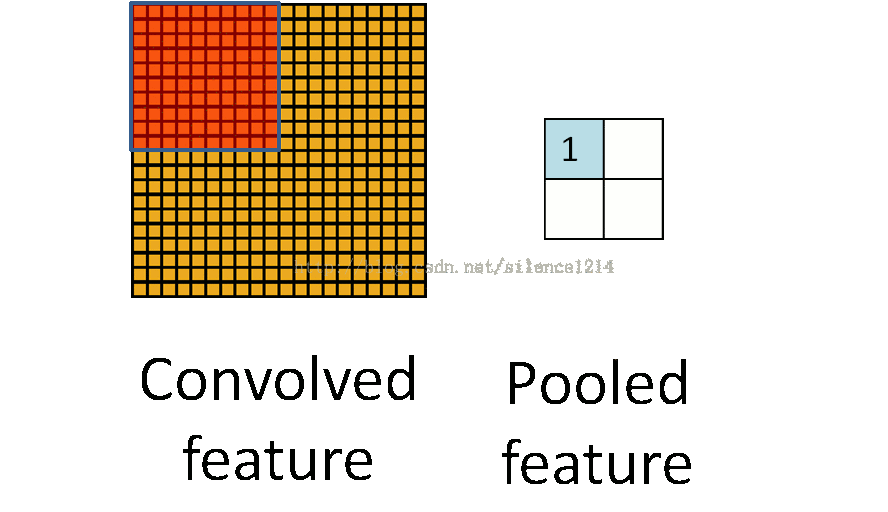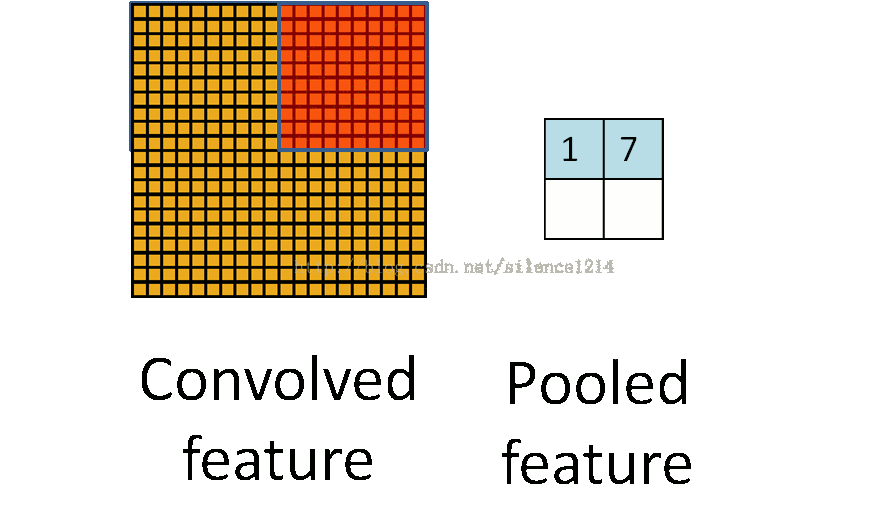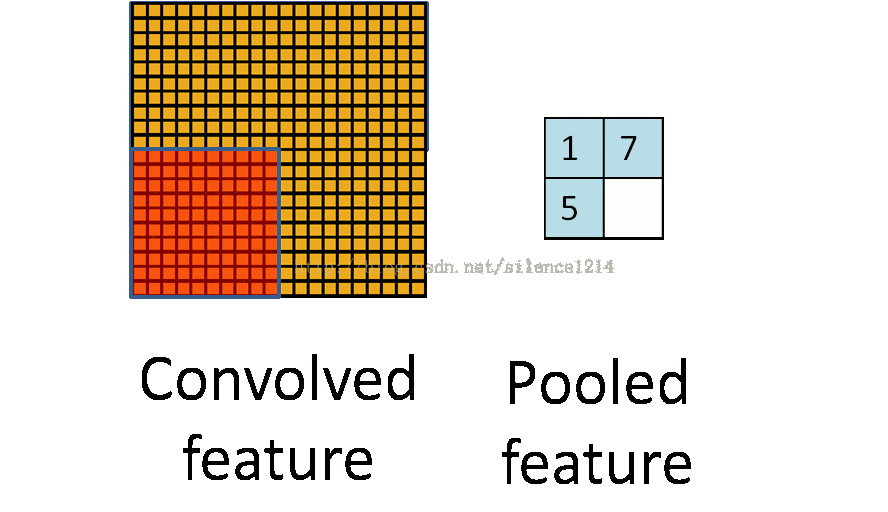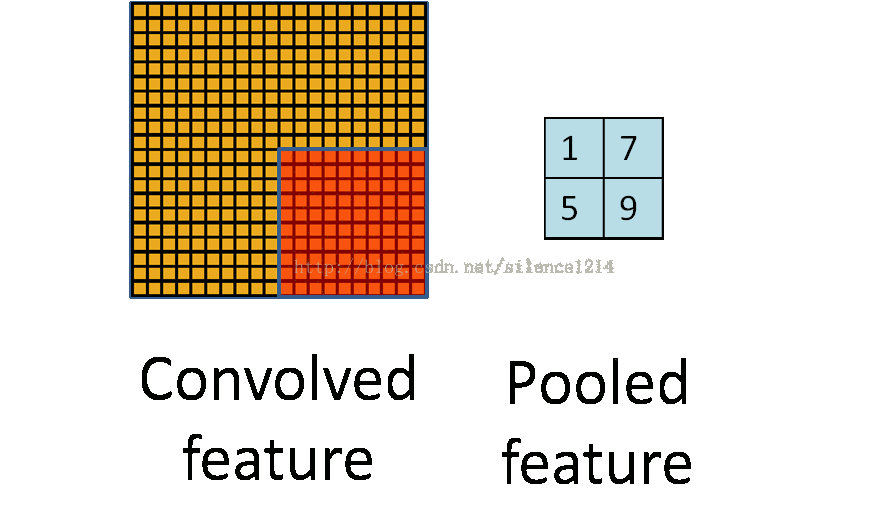
R-CNN提取特征比较耗时,需要对每个warp的区域进行学习,而SPPNet只对图像进行一次卷积,之后使用SPPNet在特征图上提取特征。结合EdgeBoxes提取的proposal,系统处理一幅图像需要0.5s。
SPP层的结构如下,将紧跟最后一个卷积层的池化层使用SPP代替,输出向量大小为kM,k=#filters,M=#bins,作为全连接层的输入。至此,网络不仅可对任意长宽比的图像进行处理,而且可对任意尺度的图像进行处理。尺度在深层网络学习中也很重要。
网络训练:
1.multi-size训练,输入尺寸在[180,224]之间,假设最后一个卷积层的输出大小为 a×a ,若给定金字塔层有 n×n 个bins,进行滑动窗池化,窗口尺寸为 wi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









