







Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
用于视觉识别的深度卷积网络中的空间金字塔池化

0.论文摘要和作者信息
摘要
现有的深度卷积神经网络(CNN)需要固定大小(例如224 × 224)的输入图像。这种要求是“人为的”,可能会损害任意大小/尺度的图像或子图像的识别精度。在这项工作中,我们为网络配备了一个更有原则的池化策略,“空间金字塔池化”,以消除上述要求。新的网络结构称为SPP-net,可以生成固定长度的表示,而不管图像大小/比例。通过消除固定大小的限制,我们可以改进所有基于CNN的图像分类方法。我们的SPP-net在ImageNet 2012、Pascal VOC 2007和Caltech101的数据集上实现了最先进的准确性。
SPP-net的能力在目标检测中更为重要。使用SPP-net,我们只从整个图像计算一次特征图,然后汇集任意区域(子图像)中的特征,以生成固定长度的表示来训练检测器。该方法避免了重复计算卷积特征。在处理测试图像时,我们的方法计算卷积特征的速度比最近的领先方法R-CNN快30-170倍(总体速度快24-64倍),同时在Pascal VOC 2007上实现了更好或相当的精度。
作者信息
Kaiming He 1
Xiangyu Zhang 2
Shaoqing Ren 3
Jian Sun 1
1 Microsoft Research, China
2 Xi’an Jiaotong University, China
3 University of Science and Technology of China
1.研究背景
我们正在见证我们的视觉社区发生快速、革命性的变化,这主要是由深度卷积神经网络(CNN)[18]和大规模训练数据的可用性[6]引起的。基于深度网络的方法最近在图像分类[16,31,24]、目标检测[12,33,24]、许多其他识别任务[22,27,32,13]甚至非识别任务的基础上有了实质性的改进。
然而,在CNN的训练和测试中存在一个技术问题:流行的CNN需要固定的输入图像大小(例如,224 × 224),这限制了输入图像的纵横比和比例。当应用于任意大小的图像时,现有的方法大多将输入图像拟合为固定的尺寸,通过裁剪[16,31]或通过形变[7,12],如图1(顶部)所示。但是裁剪区域可能不包含整个对象,而形变的内容可能导致不希望的几何扭曲。由于内容丢失或失真,识别准确性可能会受到影响。此外,当对象比例变化时,预定义的比例(例如,224)可能不合适。固定输入大小会忽略涉及比例的问题。
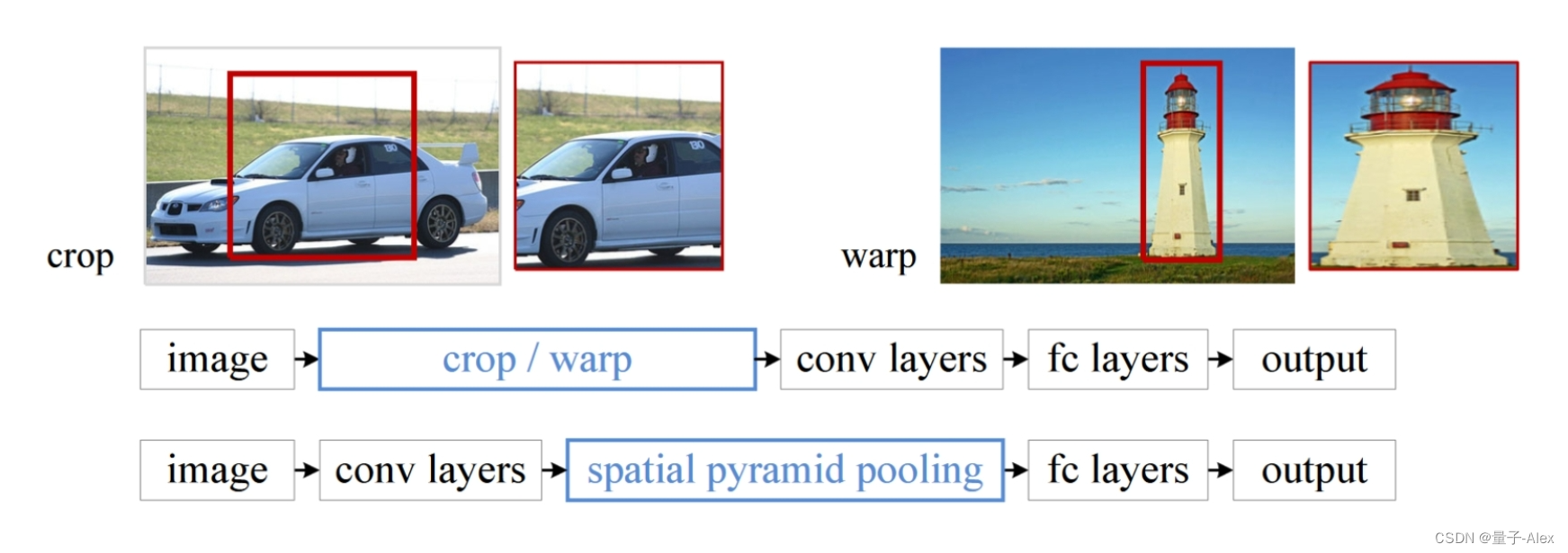
图1。顶部:裁剪或拉伸以适应固定尺寸。中间:传统的深度卷积网络结构。下图:我们的空间金字塔池化网络结构。
那么为什么CNN需要固定的输入大小呢?CNN主要由两部分组成:卷积层和随后的全连接层。卷积层以滑动窗口方式操作,并输出表示激活的空间排列的特征图(图2)。事实上,卷积图层不需要固定的图像大小,可以生成任何大小的特征图。另一方面,全连接层需要根据其定义具有固定的大小/长度输入。因此,固定大小约束仅来自全连接层,它们存在于网络的更深阶段。
 图二。特征图的可视化。(a)Pascal VOC 2007中的两幅图像。(b)一些conv5(第五卷积层)滤波器的特征图。箭头表示最强的响应及其在图像中的相应位置。(c)具有相应过滤器的最强响应的ImageNet图像。绿色矩形标志着最强烈反应的感受野。
图二。特征图的可视化。(a)Pascal VOC 2007中的两幅图像。(b)一些conv5(第五卷积层)滤波器的特征图。箭头表示最强的响应及其在图像中的相应位置。(c)具有相应过滤器的最强响应的ImageNet图像。绿色矩形标志着最强烈反应的感受野。
在本文中,我们引入了一个空间金字塔池化(SPP)[14,17]层来消除网络的固定大小约束。具体来说,我们在最后一个卷积层的顶部添加了一个SPP层。SPP层汇集特征并生成固定长度的输出,然后将其馈送到全连接层(或其他分类器)。换句话说,我们在网络层次结构的更深阶段(卷积层和全连接层之间)执行一些信息“聚合”,以避免在开始时需要裁剪或拉伸。图1(下图)示出了通过引入SPP层而改变的网络架构。我们称这种新的网络结构为SPP-net。
我们认为,更深层次的聚合在生理上更合理,也更符合我们大脑中的分层信息处理。当一个物体进入我们的视野时,我们的大脑把它作为一个整体来考虑,而不是一开始就把它裁剪成几个“视图”,这更合理。同样,我们的大脑也不太可能将所有候选物体扭曲成固定大小的区域来检测/定位它们。更有可能的是,我们的大脑在一些更深的层处理任意形状的物体,通过聚合来自前几层的已经深度处理的信息。
空间金字塔池化[14,17](俗称空间金字塔匹配或SPM[17]),作为词袋(BoW)模型[25]的扩展,是计算机视觉中最成功的方法之一。它将图像从精细到粗糙划分,并在其中聚合局部特征。SPP长期以来一直是CNN最近流行之前的用于分类(例如[30,28,21])和检测(例如[23])的领先和竞赛赢家系统的关键组成部分。然而,SPP还没有在CNN的背景下被考虑。我们注意到,SPP对于深度CNN具有几个显著的特性:1)SPP能够产生固定长度的输出,而不管输入大小如何,而以前深度网络中使用的滑动窗口池化[16]不能;2)SPP使用多级空间箱,而滑动窗口池化仅使用单一窗口大小。多级池化已被证明对物体变形具有鲁棒性[17];3)由于输入尺度的灵活性,SPP可以池化在可变尺度下提取的特征。通过实验,我们表明所有这些因素都提高了深度网络的识别精度。
SPP-net的灵活性使得生成用于测试的完整图像表示成为可能。此外,它还允许我们在训练期间提供不同大小或比例的图像,这增加了比例不变性,降低了过度拟合的风险。我们开发了一种简单的多规模训练方法来利用SPP-net的特性。通过一系列受控实验,我们展示了使用多级池化、全图像表示和可变比例的收益。在ImageNet 2012数据集上,与没有SPP的网络相比,我们的网络将前1名误差减少了1.8%。由该预训练网络给出的固定长度表示也用于在其他数据集上训练SVM分类器。我们的方法仅使用单个全图像表示(单视图测试)在Caltech101[9]上实现了91.4%的准确度,在Pascal VOC 2007[8]上实现了80.1%的平均精度(mAP)。
SPP-net在目标检测方面表现出更强的实力。在领先的对象检测方法R-CNN[12]中,候选窗口的特征通过深度卷积网络提取。该方法在VOC和ImageNet数据集上都显示出显著的检测精度。但是R-CNN中的特征计算非常耗时,因为它将深度卷积网络重复应用于每张图像数千个变形后的区域的原始像素。在本文中,我们表明我们可以在整个图像上只运行一次卷积层(不考虑窗口的数量),然后通过SPP-net在特征图上提取特征。这种方法可以提高速度超过R-CNN的一百倍。请注意,在特征图(而不是图像区域)上训练/运行检测器实际上是一个更流行的想法[10,5,23,24]。但是SPP-net继承了深度CNN特征图的能力以及SPP在任意窗口大小上的灵活性,这导致了出色的准确性和效率。在我们的实验中,基于SPP-net的系统(建立在R-CNN流水线上)计算卷积特征的速度比R-CNN快30-170倍,总体速度快24-64倍,同时具有更好或相当的精度。我们进一步提出了一种简单的模型组合方法,以在Pascal VOC 2007检测任务上实现新的最先进的结果(mAP 60.9%)。
2.具有空间金字塔池化的深度网络
2.1 卷积层与特征图
考虑流行的七层架构[16,31]。前五层是卷积层,其中一些层后面是池化层。这些池化层也可以被认为是“卷积的”,因为它们使用滑动窗口。最后两层完全连接,以N路softmax作为输出,其中N是类别的数量。上述深度网络需要固定的图像大小。然而,我们注意到固定大小的要求仅仅是由于全连接层需要固定长度的向量作为输入。另一方面,卷积层接受任意大小的输入。卷积层使用滑动滤波器,其输出与输入具有大致相同的纵横比。这些输出被称为特征图[18]——它们不仅涉及响应的强度,还涉及它们的空间位置。在图2中,我们可视化一些特征图。它们是由conv5层的一些滤波器生成的。
值得注意的是,我们在没有固定输入大小的情况下生成了图2中的特征图。这些由深卷积层生成的特征图类似于传统方法中的特征图[2,4]。在这些方法中,密集提取SIFT向量[2]或图像块[4],然后编码,例如通过矢量量化[25,17,11]、稀疏编码[30,28]或Fisher核[21]。这些编码特征由特征图组成,然后由词袋(BoW)[25]或空间金字塔[14,17]池化。类似地,深度卷积特征可以以类似的方式汇集。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











