








这是Ross Girshick大神在fast rcnn之后的又一力作,不过这篇论文似乎推翻了rbg大神在rcnn那篇论文中结论,即可以把检测任务归并为分类任务,而是又把检测任务归为回归任务去解。下面说一下这篇文章的主要思想:
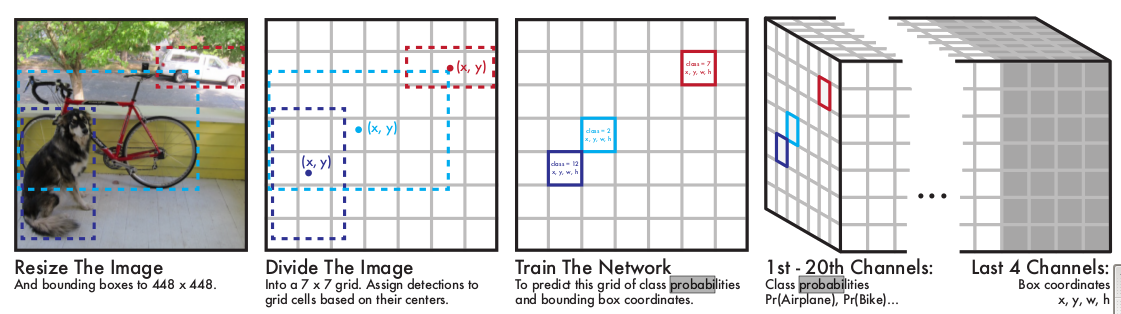
上图是YOLO的主要流程,首先把整幅图片划分为7x7个块,然后根据ground truth 找到中心点,并把物体所在的中心点归为某个块中。网络的后端两个全链接层,这里需要看一下最后一层,它7x7x24的输出,表示图片7x7的区域里是什么(回归),以及物体在哪里(回归)。
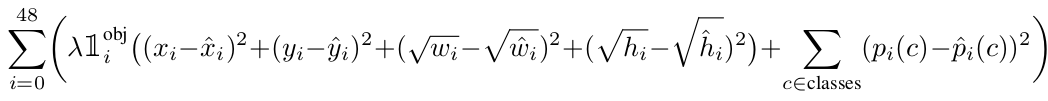
从目标函数可以看出,是什么问题原本是分类问题,不过也可以通过是某种物体的概率与ground truth概率差的二范数之和(也是回归)得到。整个网络的学习是通过整幅图像进行学习,而不像以前的检测模型,先学出一个分类模型,再在整张图像进行滑窗判断。通过把整个图片划分为49个区域,然后对每个区域进行判断,这种思想和faster rcnn类似,都是为了减少任务复杂度,一个是从前切分,一个是从后切分。不过这个与faster rcnn相比,有更加明显的优势,首先faster rcnn需要一个rpn网络代替selective search来找出候选区域,而yolo则直接将7x7这49个区域作为候选区域。与yolo思想不同,faster rcnn在conv5层滑窗,conv5feature map 与原图只能进行点对点的一一映射,在尺度和宽高比上没办法直接确定,故需要设置9个anchor,然后从这9个anchor来衍生真正的候选区域。
了解卷积神经网络的都知道,卷积神经网络在卷积层上保留了二位空间信息,而全链接层则没有空间信息,故最后一层虽然是二维的,但是之间没有空间关联,而是根据给的labels来学习这样的伪空间信息,为什么说是伪空间信息呢,因为虽然神经元本身没有空间信息,但是要学习的labels是根据原图块的信息判断的,而原图的块与块之间是有空间信息的。故在我看来,最后一层的二维图直接拉成一个列向量,也是可以处理的。
以上就是我对yolo的见解,最后在给一幅他的示意图,这是唯一的一张我看示意图却不知道到底想干啥的示意图了:
You Only Look Once: Unified, Real-Time Object Detection
最新推荐文章于 2022-09-27 09:44:11 发布
















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









