







Author
Joseph Redmon, Santosh Divvalay, Ross Girshick{, Ali Farhadiy

Joseph Redmon(How do you like this hairstly? YOLO is really fast!)
Abstract
We frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilites directly from full images in one evaluation.
It has the following characteristics:
1. extremely fast 45 frames /s (base version )
2. more localization errors, but less false positives.
3. Learns very general repressentations of objects.
1 Introduction
Current detection systems repurpose classifiers to perform detection. To detect an object, these systems take a classifier for that object and evaluate it at various locations and scales in a test image.
YOLO is refreshingly simple: A single convolutional network simulaneously predicts multiple bounding boxes and class probablities for those boxes.
It’s benefits over traditional methods:
1. Faster. We frame detection as a regression problem ,we simpley run nn on a new image to predict detections.
2. YOLO reasions globally about the image when making predictions. It implicitly encodes contextual information about classes as well as their appearance. Fast R-CNN mistakes background patches in an image for objects because it can’t see the larger context.
3. generalizable representaions of objects: trained on natural images and tested on artwork!
BUT, it struggles to precisely localize some objects, especially small ones.
2 Unified Detection
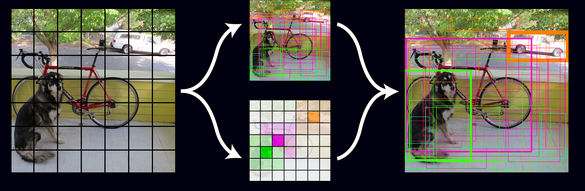
The system(yolo) divide the input image into a sxs grid. if the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an objects. we difine confidence as
Pr(object)×IOUtruthpred
.
Each bounding box consists of 5 predictions : x,y,w,h,confidence. (x,y)represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image.
Each grid cell aso predicts C conditional class probabilities,
Pr(Classi|Object)
. These probablities are conditioned on the grid cell containing an object, we only predict one set of class probabilities per grid cell, regardless of the number of boxes B.
Class-specific confidencee scores for each box:
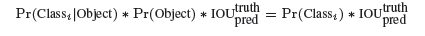
These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.
These preditions are encoded as an
s×s×(B×5+C)
tensor.
2.1 network design
The initial convolutional layers extract features from the image; the fc layers predict the output probabilities.

The final output of our network is the 7x7x30 tensor
2.2 Training
- Pretrain: 20 convs+average-pooling layer+ fc layer.
- Convert: Ren et al.: adding both convolutional and connected layers to pretrained networks can improve performance. So +4 convs+2 fc . increase the input resolution from 224x224–>448x448
we normalize the bounding box width and height by the image width and height sothat they fell between 0 and 1. We parametrize the bounding box (x,y) to be offsets of a particular grid cell location so they are also bounded between 0 and 1.
We use a linear activeion function for the final layer and all other layers use the leaky rectified linear activation:
multi-part loss function:
our learning rate schedule is as follows: For the first epochs we slowly raise the learning rate from 1e-3 to 1e-2, if we start at a high learning rate our model often diverges due to unstable gradients. We continue training with 1e-2 for 75 epochs, then 1e-3 for 30 epochs, and finally 1e-4 for 30 epochs.


2.3 Inference
On pascal voc the network predicts 98 bounding boxes per image and classprobablities.
Some large objects or objects near the border of multiple cells can be well localized by multiple cells. No-maximal suppression canbe used to fix these multiple detection. This can add 2-3 mAP
2.4 Limitations of YOLO
- This model struggles with small objects that appear in groups, such as flocks of birds.
- It struggles to generalize to objects in new or unusual aspect ratios or configurations. Also uses relatively coarse features for predicting bounding boxes.
- Our loss function treats errors the same in small bounding boxes versus large bounding boxes.
3 Comparison
- DPM
- RCNN Fast/Faster rcnn
- Deep multiBox
- OverFeat
- MultiGrasp:Our grid approach to bounding box prediction is based on the multigrasp system for regression to grasps!
4 Experiments
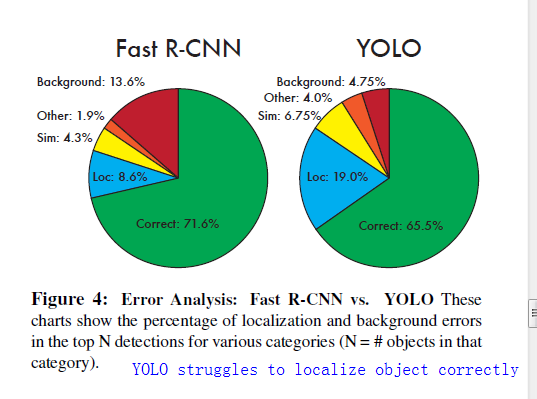
on the VOC 2012 test set,YOLO, secores 57.9% mAP, this is lower than the current state of the art.















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









