







最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结链接如下:
喜欢本文记得收藏、关注、点赞。
本文主要分享我们近期在Embedding模型训练上的工作「Conan-Embedding」。目前,Conan-Embedding已在最全面、最大规模的中文语义向量评测榜单C-MTEB上达到SOTA,超越了阿里、百川、OpenAI等众多Embedding模型。

引言
概述
随着大模型时代的爆发,检索增强生成技术(RAG)在大语言模型中广泛应用。RAG是一种性价比极高的方案,在大语言模型中占据重要地位。Embedding模型作为RAG中检索召回的重要一环,扮演着极其关键的角色。更加准确的Embedding模型在抑制模型幻觉、增强新热知识表现、提升封闭领域回答能力等方面都能发挥优势。
为了提升RAG系统的性能表现,我们近期针对如何训练更强的Embedding模型进行探索,训练得到了目前最强中文Embedding模型「Conan-Embedding」,该模型已在C-MTEB上达到SOTA。
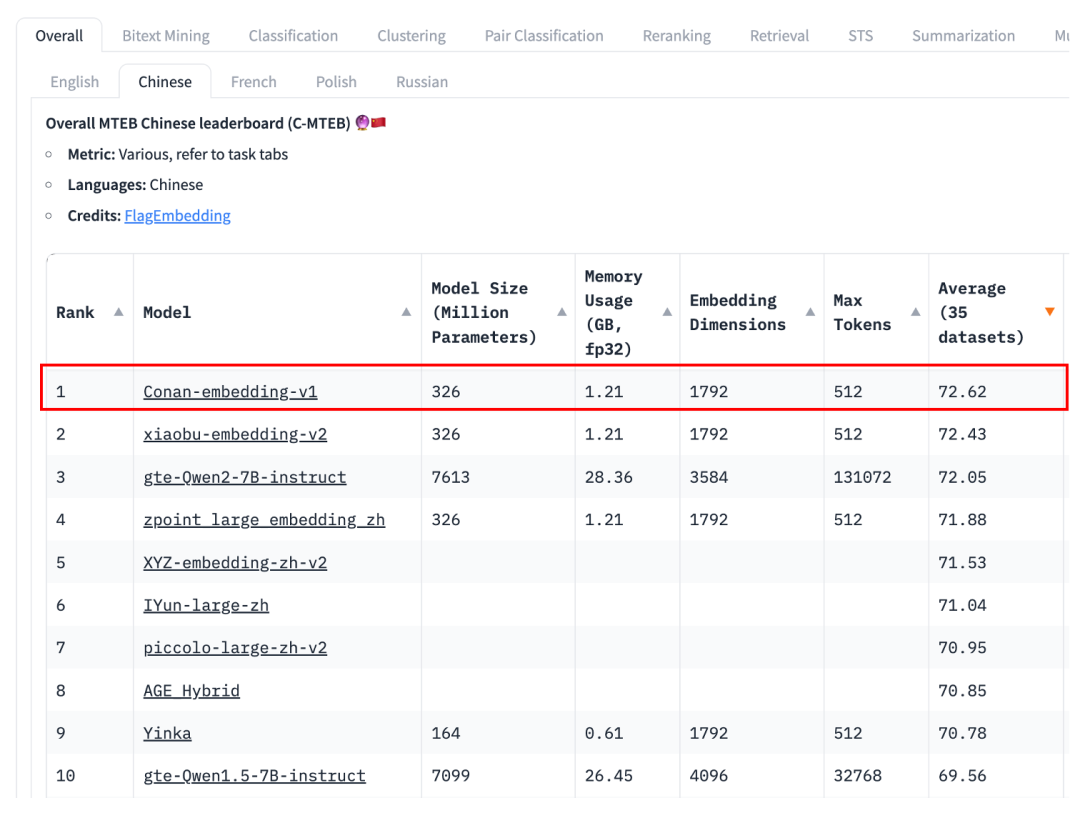
图1 C-MTEB榜单结果
模型链接:TencentBAC/Conan-embedding-v1 · Hugging Face (模型已上传开源,欢迎试用)
评测榜单:MTEB Leaderboard - a Hugging Face Space by mteb
背景介绍
Embedding是一种将高维数据转换为低维向量表示的技术,它在自然语言处理、计算机视觉等领域有广泛应用。例如,在文本中,一个词或短语会被转换成一个固定长度的向量,这个向量能够捕捉词义和上下文信息。通过 Embedding 模型,可以计算句子间的相似度,应用于检索,分类,召回,排序等诸多任务。
目前,Embedding模型已经取得了显著进展。例如,Word2Vec、GloVe 等模型能够生成高质量的词嵌入向量。Transformer架构的出现,进一步推动了Embedding模型的进步。BERT、GPT等预训练语言模型通过大规模数据集训练,生成了更加丰富和精确的词嵌入表示。
通常,Embedding模型是通过对比学习来训练的,而负样本的质量对模型性能至关重要。难负例挖掘就是利用 Teacher 模型,来找到与Query有一定相关性但不如正样本相关的段落,从而使对比损失更难区分正例和负例。尽管难负例挖掘非常重要,但在Embedding工作中,这些方法往往被忽视,研究通常集中在模型架构、微调方法和数据选择上。
主要方法
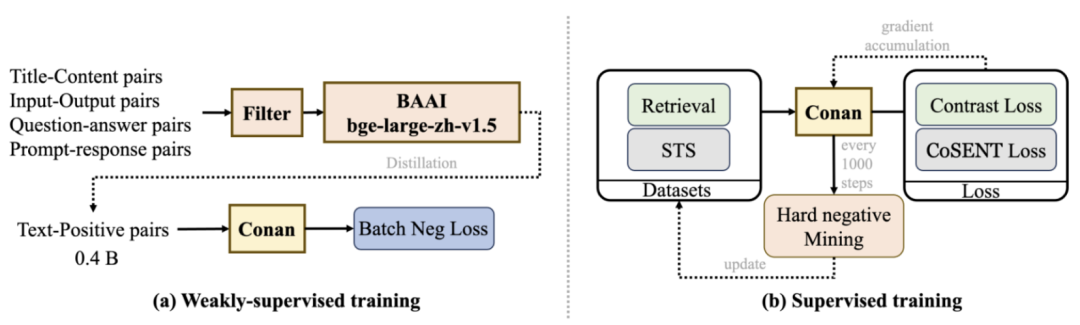
图2 训练方法概览
在弱监督训练阶段,我们收集了 7.5 亿对数据集,并从中挑选出 4 亿对。在有监督训练阶段,使用动态难负例挖掘策略来更精确地微调模型。
Language Embedding模型训练通常采用多阶段方案,分为弱监督的预训练以及有监督的精调训练。我们遵循这种训练方式,将训练分为预训练和微调两个阶段。以下介绍了我们的详细训练流程和主要的方法,包含了动态的难负例挖掘和跨GPU的多任务均衡训练方式。
训练流程
预训练
如图2(a)所示,在预训练阶段,我们首先使用Internlm2.5中描述的标准数据过滤方法。首先,通过文档提取和语言识别进行格式化处理;接着,在基于规则的阶段,文本会经过规范化和启发式过滤;然后,通过MinHash方法进行去重;在安全过滤阶段,执行域名阻止、毒性分类和色情内容分类;最后,在质量过滤阶段,文本会经过广告分类和流畅度分类,以确保输出文本的高质量。通过过滤,我们筛选了约 4.5 亿对数据,留存率约60%。
bge-large-zh-v1.5 是由智源发布的广泛使用的基础embedding 模型。我们认为,该模型在对数据进行评分时,能够有效地识别并保留高质量数据。在数据经过标准过滤后,我们使用bge-large-zh-v1.5模型对每一条数据进行评分,丢弃所有得分低于0.4的数据。通过评分,我们筛选了约 4 亿对数据,留存率约 89%。
在预训练阶段,为了高效且充分地利用数据,我们使用InfoNCE Loss with In-Batch Negative:
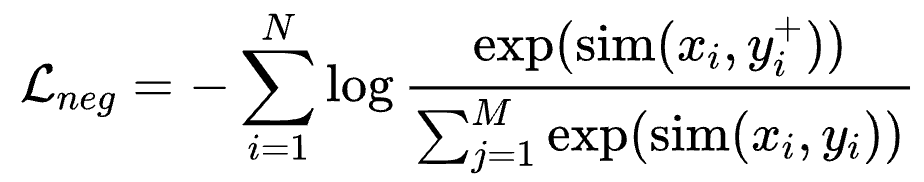
其中是title,input,question,prompt等,是对应的 content,output,answer,response等,认为是正样本;是同 batch 其他样本的content,output,answer,response,认为是负样本。In-Batch Negative InfoNCE Loss 是一种用于对比学习的损失函数,它利用了 mini-batch 中的其他样本作为负样本来优化模型。具体来说,在每个 mini-batch 中,除了目标样本的正样本对外,其余样本都被视为负样本。通过最大化正样本对的相似度并最小化负样本对的相似度,In-Batch Negative InfoNCE Loss 能够有效地提高模型的判别能力和表征学习效果。这种方法通过充分利用 mini-batch 中的样本,提升了训练效率并减少了对额外负样本生成的需求。
有监督精调
微调阶段,我们针对不同的下游任务进行特定任务的微调。如图2(b)所示,我们参考以往的工作,并在其基础上移除了分类(CLS)任务,将任务分为两类:检索(Retrieval)和语义文本相似性(STS)。检索任务包括查询、正样本和负样本,经典的损失函数是InfoNCE Loss。STS任务涉及区分两段文本之间的相似性,经典的损失函数是交叉熵损失。在STS任务上,根据以往工作的结论,CoSENT损失略优于交叉熵损失。因此,我们也采用CoSENT损失来优化STS任务:
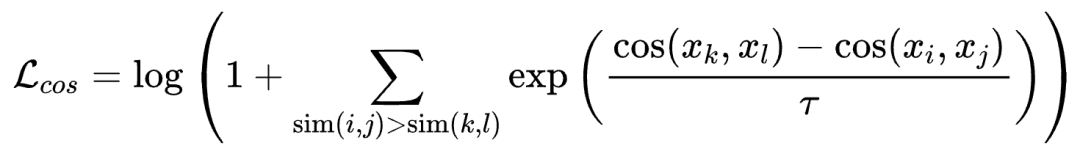
其中是缩放温度,是余弦相似度函数,是 和之间的相似性。
动态难负例挖掘训练
在embedding模型准备数据时,难负例挖掘用于为query选择负样本。其思想是使用一个 teacher模型来找到与query有一定相关性但不如正样本相关的段落,从而使对比损失更难区分正例和负例。这些难负例应该比随机负例更难与正例区分,从而带来更高效和更有效的微调。
先前的工作基本都在数据预处理阶段进行难负例挖掘。对于Embedding模型来说,一个既定的权重状态下的模型,难负例是一定的。然而,随着训练的进行,每当模型权重更新时,当前权重下的模型对应的难负例就会变化。在数据预处理阶段挖掘的难负例在经过训练迭代后,就会变得不那么难了。基于这一观点,我们提出了一种动态难负例挖掘方法。对于每个数据,我们记录当前难先前的工作基本都在数据预处理阶段进行难负例挖掘。对于Embedding模型来说,一个既定的权重状态下的模型,难负例是一定的。然而,随着训练的进行,每当模型权重更新时,当前权重下的模型对应的难负例就会变化。在数据预处理阶段挖掘的难负例在经过训练迭代后,就会变得不那么难了。
基于这一观点,我们提出了一种动态难负例挖掘方法。对于每个数据,我们记录当前难负例与Query的平均分数。每 100 次迭代后,如果分数的 1.15 倍小于初始分数且分数绝对值小于 0.8时,我们就认为该负例不再困难,并进行新一轮的难负例挖掘。每次进行动态难负例挖掘时,如果需要替换难负例,我们使用到个案例作为负样本,其中表示第次替换,表示每次使用的难负例数。整个过程产生的成本仅相当于一个 step迭代。相比于In-Batch Negative InfoNCE Loss,我们认为更高质量(更符合当前模型权重下)的难负例更为重要。图3 展示了动态难负例挖掘与标准难负例挖掘的样本正负例Score - Steps 变化曲线。可以看到,随着步数的增加,Standard-HNM的负例评分不再下降,而是出现震荡,这表明模型对该批负例的学习已完成。而Dynamic-HDM在检测到负例学习完毕后,会进行难负例的替换。。
图3 展示了动态难负例挖掘与标准难负例挖掘的样本正负例Score - Steps 变化曲线。可以看到,随着步数的增加,Standard-HNM的负例评分不再下降,而是出现震荡,这表明模型对该批负例的学习已完成。而Dynamic-HDM在检测到负例学习完毕后,会进行难负例的替换。
在训练过程中,每 100steps 检查一次难负例。当分数的 1.15 倍小于初始得分,且分数绝对值小于 0.8 时,我们认为该负例不再困难,并替换成新的难负例。
跨GPU的Batch均衡训练
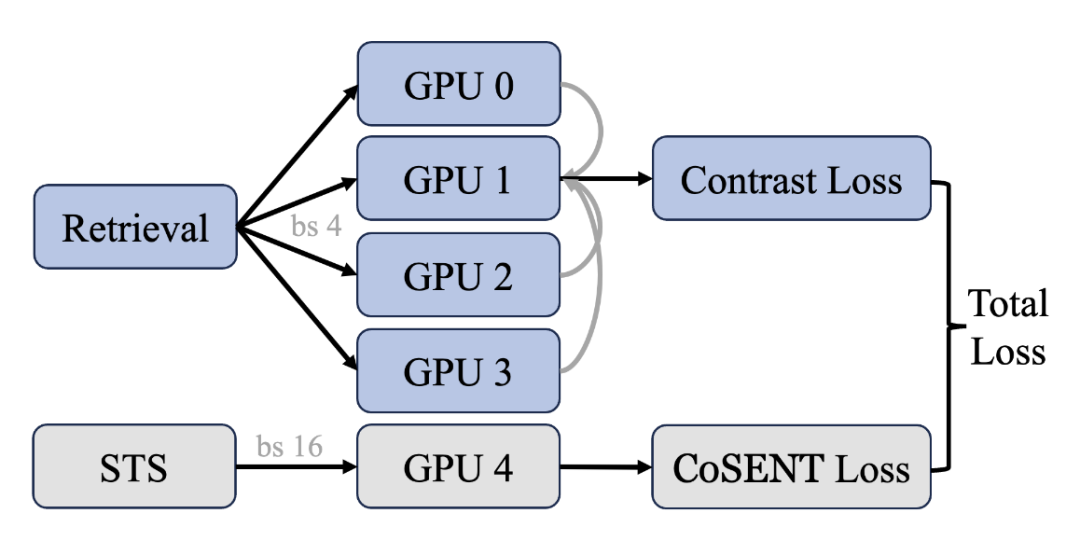
图4 跨 GPU 的Batch均衡训练的示意图。
对于Retri任务,我们利用多个 GPU 来合并更多难负例。对于 STS 任务,我们增加BatchSize以包含更多样本进行学习,以获得更鲁棒的排名关系。
为了更好地利用难样本,我们采用了跨 GPU 批次平衡损失 (CBB)。之前的方案通常在训练流程中随机的在每个Batch中分配一个任务。例如:在iter0中采样STS的样本,并使用STS对应Loss进行反向传播获取梯度并更新权重,而iter1中分配了Retri任务或者CLS任务,我们称之为顺序随机任务训练。这样训练几乎一定会导致单次的优化搜索空间与Embedding模型的全局优化搜索空间不一致,从而导致训练过程的震荡以及无法求得全局最优解。我们在之后的分析中展现了这一现象。
为此,我们考虑在每次的Forward-Loss-Backward-Update的更新过程中都均衡的引入每一个任务,以此来获得稳定的搜索空间,并尽可能的缩小单次模型更新方向和全局最优解的一致性。因此,CBB策略不仅考虑了不同 GPU 之间的通信,还考虑了不同任务之间的通信,从而实现了更好的Batch均衡。如图4所示,为了在检索任务中利用更多难样本,我们确保 GPU(gpu0、gpu1、gpu2、gpu3)各自具有不同的负样本,同时共享相同的查询和相同的正样本。对于Retri任务,每个 GPU 计算对应Batch的Loss,然后将结果汇总到 gpu1 上。对于STS任务,在gpu4上,运行STS任务并获得对应Loss。最终汇总并计算当前Iter的合并 CBB Loss。对应公式如下:
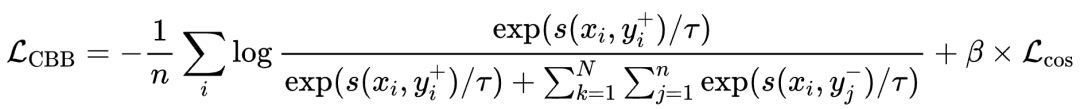
其中是 Query 和正样本段落之间的评分函数,通常定义为余弦相似度,是查询和正样本段落共享的GPU数量,是缩放温度。根据经验,我们将设置为 0.8。
实验
实验细节
与大多数Embedding模型一样,Conan-Embedding也采用BERT模型作为基础模型,并使用FC Layer将输出维度从1024扩展到1792。模型的参数量为326M。Conan-Embedding的最大输入长度为 512 个 token。此外,受到 OpenAI的text-embedding-v3的启发,我们还利用了多尺度表征学习(Matryoshka Representation Learning, MRL)技术来实现灵活的输出维度长度,提升模型表征性能和鲁棒性。对于 MRL 训练,表示维度配置为256、 512、 768、1024、1536 和 1792。
为了提高效率,我们使用了混合精度训练和 DeepSpeed ZERO-Stage 1。
弱监督预训练阶段,我们使用 AdamW优化器,初始学习率为 1e-5,Warmup设置为 0.05,Decay设置为 0.001。整个预训练过程使用了 64张华为Ascend 910B GPU,单次精调训练约消耗138 个小时。
有监督精调阶段,检索任务的BatchSize设置为 4,STS 任务的BatchSize设置为32。我们使用了与预训练阶段相同的优化器参数和学习率。整个微调过程使用了 16 张华为Ascend 910B GPU,单次精调训练约消耗13 个小时。
数据情况
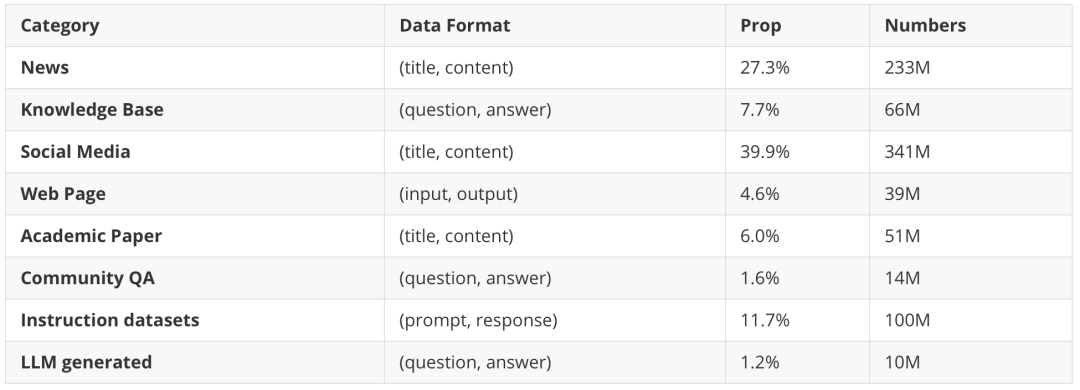
在预训练阶段,我们收集了约7.5 亿个文本对,包含Wudao、Zhihu-KOL、SimCLUE等,数据分为标题-内容对、输入-输出对和问答对等。我们还发现,高质量的 LLM 指令调优数据(例如:提示-响应对)经过规则过滤和筛选后,可以提升 Embedding 模型的性能。此外,我们利用现有的文本语料库,使用 LLM 生成了一批数据。详细的数据描述可以在下表中展示:
表1 预训练数据概览
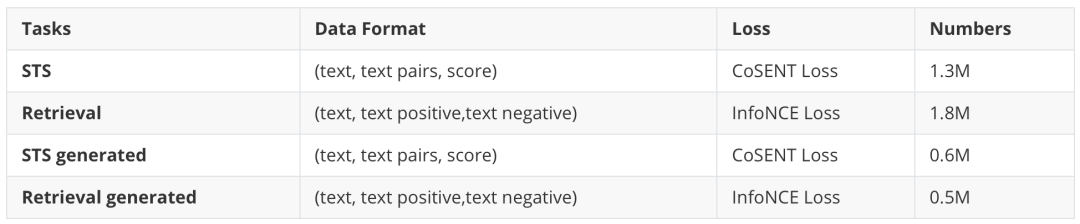
在精调阶段,为了让模型更适应各种任务,我们选择了常见的Retri、CLS和 STS数据集。对于CLS任务,我们将它与Retri合并,将同一类别的数据视为文本正例,将不同类别的数据视为文本负例。微调阶段使用的数据量如下表所示:
表2 精调训练数据概览
结果
消融实验结果
为了证明我们方法的有效性,我们在 CMTEB 基准上进行了全面的消融研究。如下表所示,动态难负样本挖掘(DHNM)和跨 GPU 批次平衡(CBB)都明显优于直接微调模型的Vanilla方法。除此之外,Conan-Embedding在Retri和Rerank任务中表现出显着的改进,这表明随着负样本数量的增加和质量的提高,模型能够看到更具有学习价值的难负样本,从而增强了其召回能力。
表3 消融实验结果
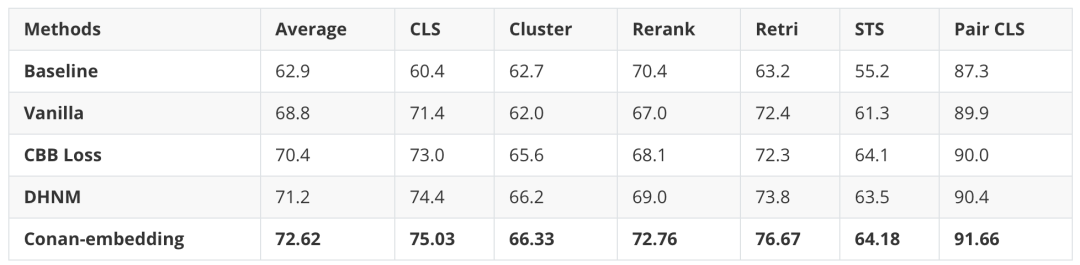 Baseline 表示我们在预训练阶段之后的结果;Vanilla 表示直接使用标准对比和 CoSENT 损失进行微调;
Baseline 表示我们在预训练阶段之后的结果;Vanilla 表示直接使用标准对比和 CoSENT 损失进行微调;
DHNM 表示仅使用动态硬负挖掘方法;CBB Loss 表示仅使用跨 GPU 批次平衡损失。
C-MTEB结果
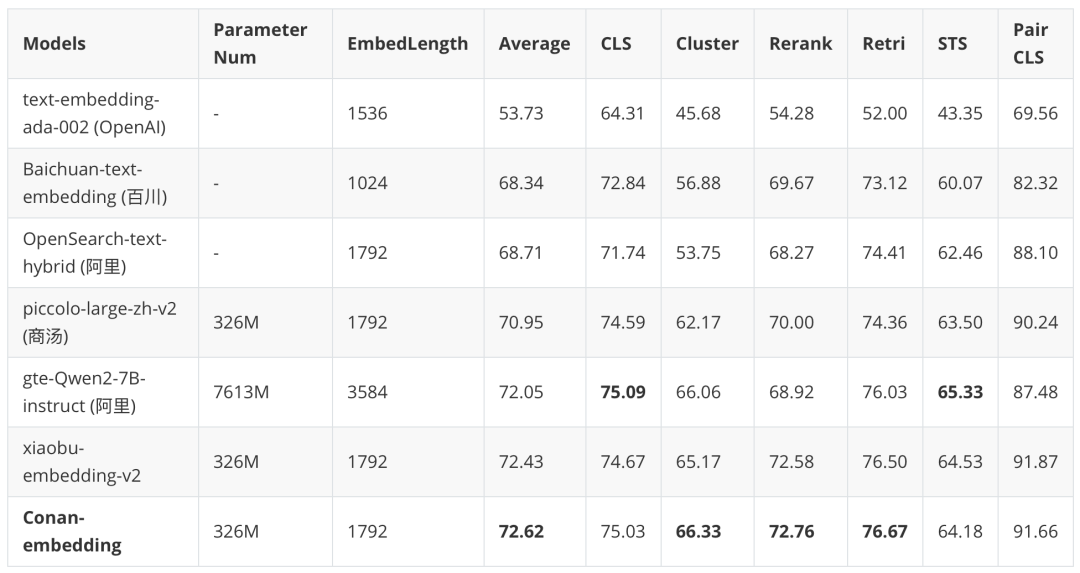
MTEB(Massive Text Embedding Benchmark)是评估大规模文本Embedding模型的最权威和最流行的基准。MTEB创建了一个中文 Embedding评估Benchmark,称为 C-MTEB。C-MTEB 有 35 个数据集,涵盖 6 个类别:分类、聚类、文本对分类、重排序、检索和 STS。下表展示了我们的模型与 C-MTEB 基准上其他模型的比较。我们的模型在几乎所有任务上都超越了之前最先进的模型,包含参数量更大的Decoder-Only模型。
表4 C-MTEB结果
分析
为了更好地评估跨GPU多任务批次均衡的效果,我们在图5展示了使用CBB策略前后的Loss-Iter曲线。loss_retri和loss_STS代表在不启用CBB策略时,多个任务随机按Iter进行训练时,两个任务的独立Loss。可以观察到,在不启用CBB策略时,每个独立任务的Loss震荡都比较严重,并且下降缓慢,且不同步。以上现象说明,不同的任务之间优化目标存在GAP,优化方向不一致,且每个单一优化目标和全局优化目标不一致。因此,顺序随机任务训练不能在优化中取得近似的全局最优结果。loss_cross代表启用CBB策略时训练过程中的Loss-Iter曲线,可以看到,随着训练的进行,Loss在几乎在非常平稳地持续的下降,最终的Loss(0.08)远小于Retri和STS Loss之和(0.38)。CBB策略可以看作是一种正则化策略。
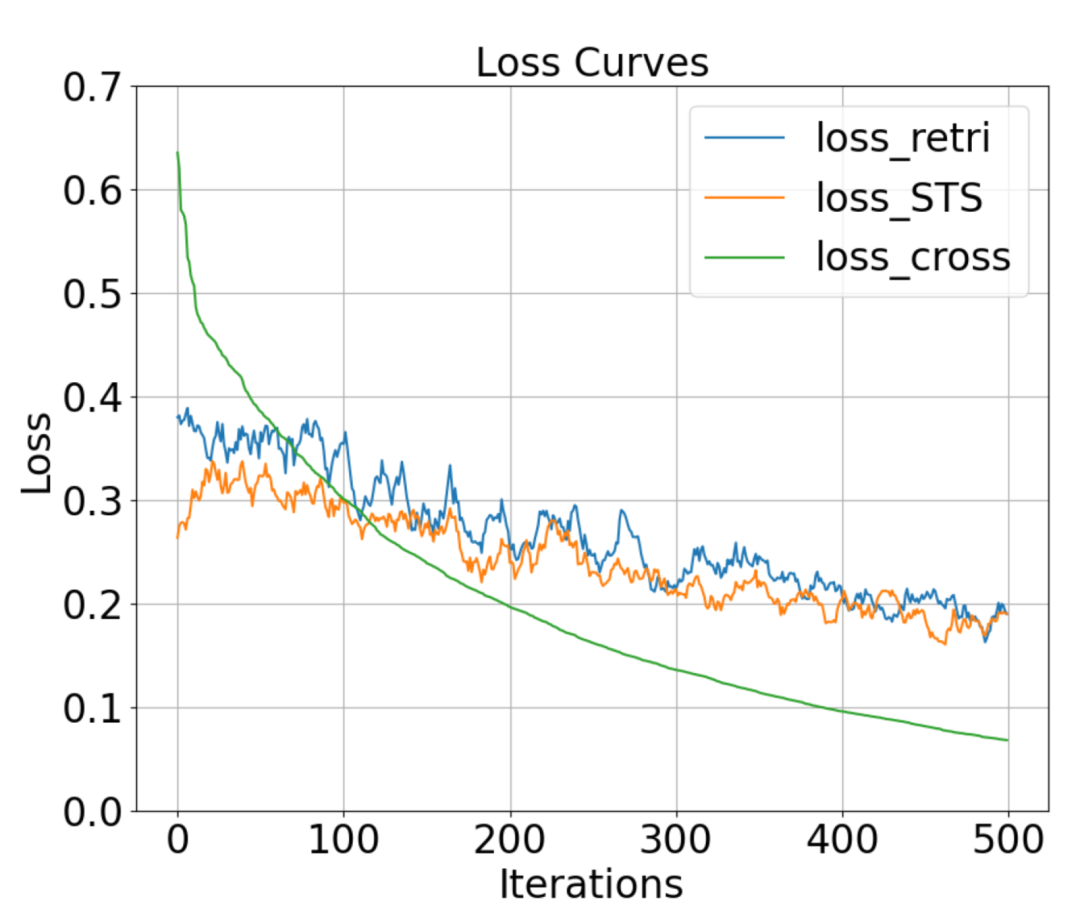
图5 使用跨GPU多任务批次均衡(CBB)方法前后的损失曲线比较
展望
在实际业务中,由于业务体系庞大、业务标准灵活多变、不同业务标准不一,运用Embedding模型配合RAG技术来提升实际业务的召回性能、快速适应标准变化、降低模型训练开销,是优化成本与精度的不错选择。
另外,Embedding模型也可以在多业务场景下独立提供召回服务,目前我们已有Conan- Embedding推理服务上线提供给业务方使用,并能适配多种特征长度的需求。我们正在推进Conan-Embedding在实际业务中的落地,例如:不同体系标准的标签业务、推荐系统相似样本召回、以及通用RAG系统等等。
最后,欢迎大家联系我们使用Conan-Embedding,并提出宝贵意见。当前训练数据可能仍存在短板,不能直接在所有类型业务上都取得最佳表现,其中还面临一些有待解决问题和算法挑战,非常欢迎大家与我们进行合作,推进Conan-Embedding技术探索和迭代,共同解决业务落地中的各种问题。















 1309
1309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









