






欲实现:口型能和AI语音内容对齐的英语对话人物
模型选择:
Blender官方开源项目角色Ellie,节省模型制作、收集时间。
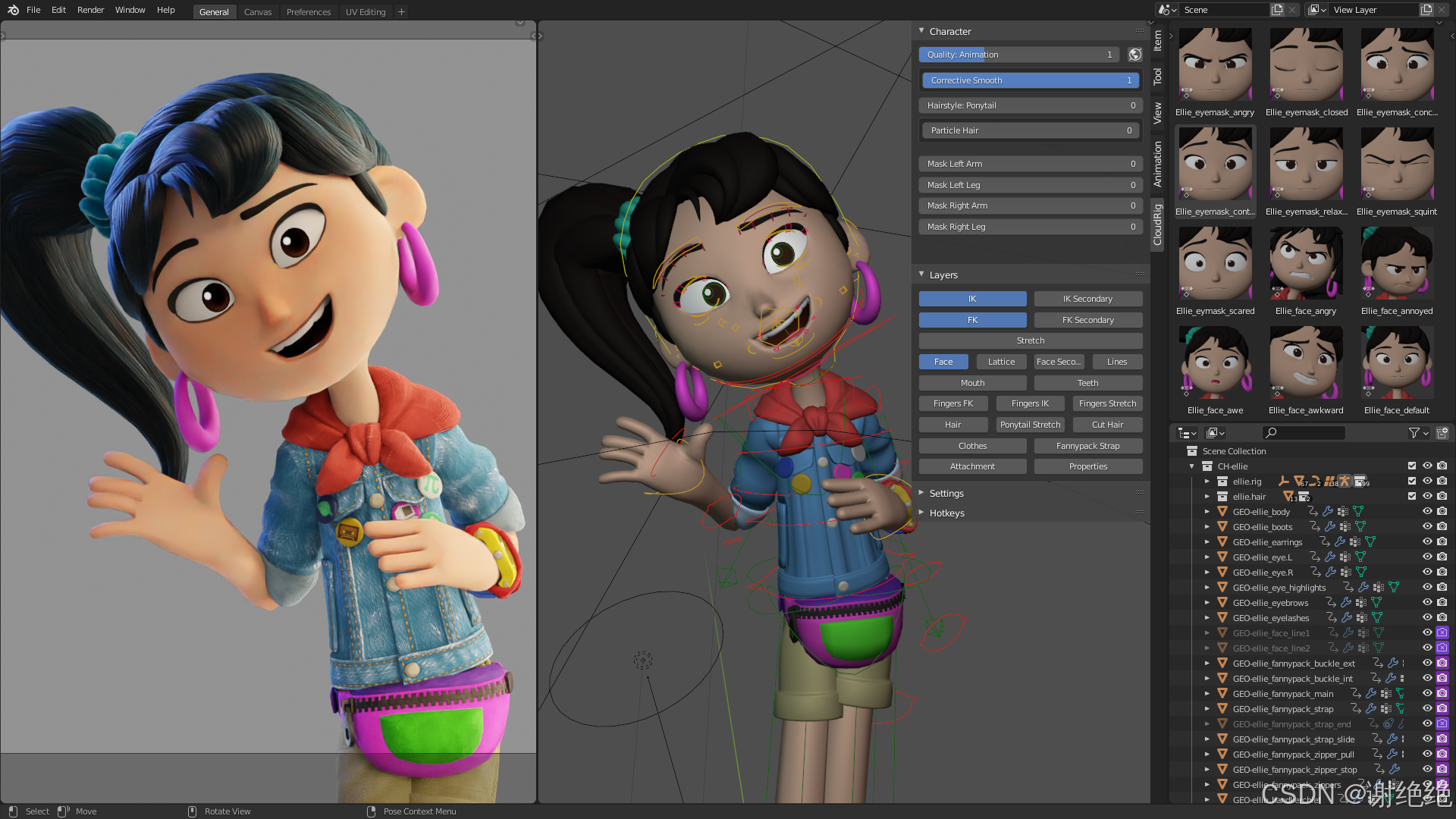
根据介绍,Ellie具有CC-BY license:

SALSA LipSync Suite实时口型生成方案:
1. 核心功能
- 实时驱动:支持通过语音数据或实时音频流动态生成口型动画,无需预生成数据。
- 表情融合:除了口型,可结合情感参数驱动眉毛、眼睛等表情。
2. 实现步骤
1. 插件获取:SALSA LipSync Suite
2. 角色配置:
- Blender内添加角色特定口型、表情的blend keys,也就是形态键
- 导入Blender角色到Unity,在角色面部模型上添加组件“SkinnedMeshRenderer”,并确保已定义口型相关的Blendshapes(比如“Ah”、“Ee”、“Oh”),材质暂定为Unlit-Color,呈现不受光照影响的卡通纯色形象,切合App设计和定位。
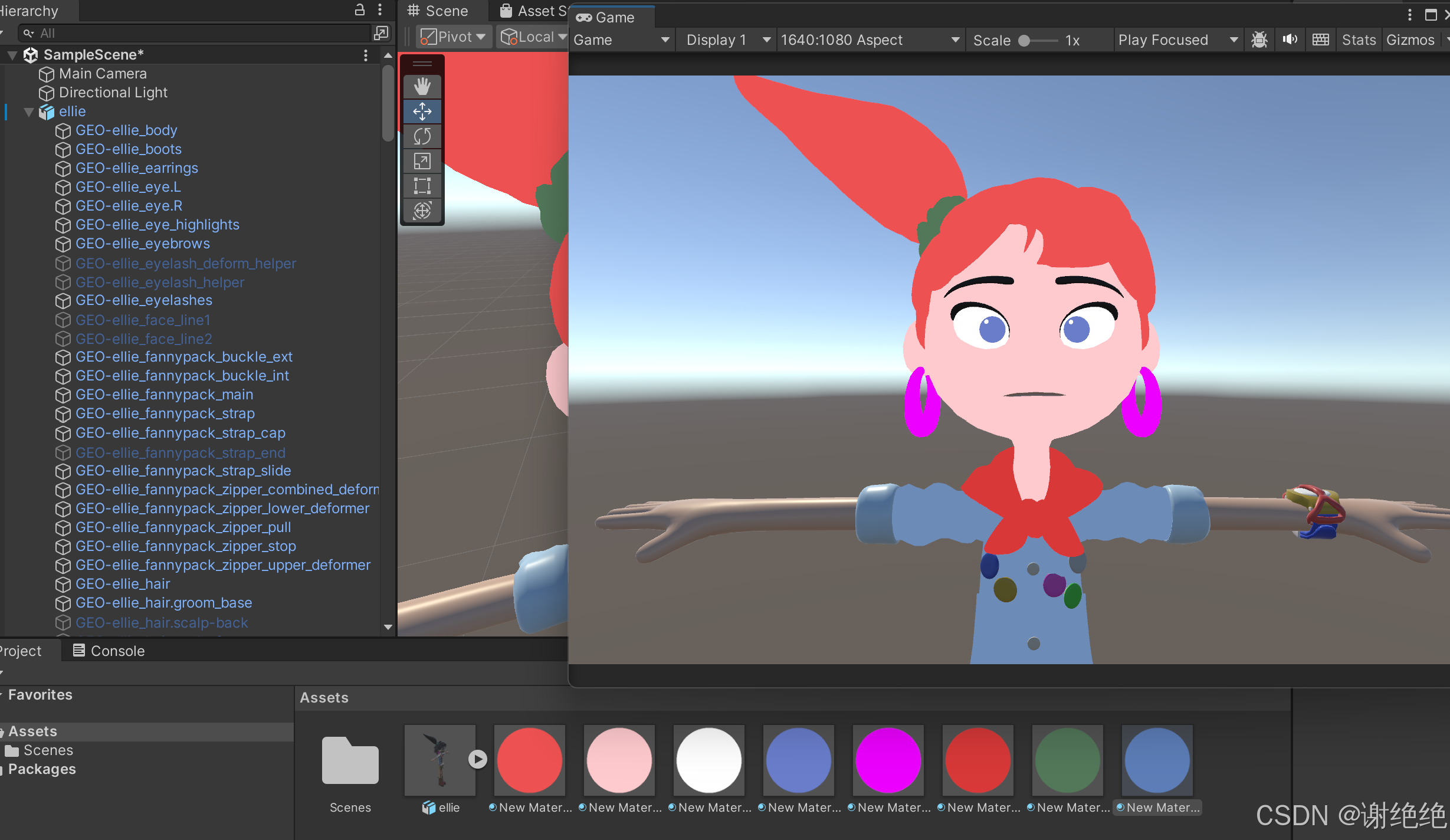
- 将SALSA组件挂载到角色,绑定对应的Blendshapes。
3. 音频输入设置:
- 使用麦克风输入(用以测试):调用`Microphone.Start()`捕获实时音频,传入SALSA的AudioSource。
- 使用TTS语音流:将AI生成的语音实时传输到SALSA组件。
4. 参数调整:
- 在SALSA的Inspector面板中调整音素灵敏度和动画平滑度。
工作流展示:
1. 角色准备:
- 在Blender中创建角色,设置英语基础音素的Blendshapes
2. 集成SALSA:
- 将模型导入Unity,通过SALSA绑定Blendshapes,配置实时音频输入用于测试口型配对效果(目前我的工作内还未接入AI语音,无法获取实时AI语音数据,故先用此方法测试)。
3. AI对话接入(后期未定):
- 使用Google Speech-to-Text识别用户语音,Deepseek生成回复,通过RT-Voice PRO播放语音并驱动SALSA/根据实际性能会调整对语音数据的处理方法
4. 优化:
- 在真机测试中调整音素敏感度,确保音素口型准确。
- 表情融合:除了口型,可结合情感、idle参数驱动眉毛、眼睛等运动

















 2838
2838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









