






1.1 微积分
我们首先讨论导数的计算,这是几乎所有深度学习优化算法的关键步骤。 在深度学习中,我们通常选择对于模型参数可微的损失函数。 简而言之,对于每个参数, 如果我们把这个参数增加或减少一个无穷小的量,可以知道损失会以多快的速度增加或减少。
假设我们有一个函数f(x),其输入和输出都是标量。 如果f(x)导数存在,这个极限被定义为:
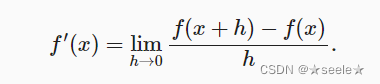
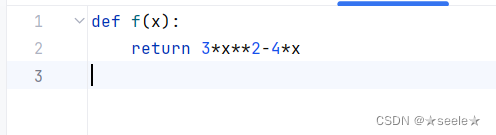
为了更好地解释导数,让我们做一个实验。 定义f(x)=3x²–4x如下:
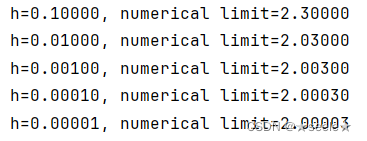
通过令x=1并让h趋近0,f'(x)的数值结果趋近于2,虽然这个实验不是一个数学证明,但稍后会看到,当x=1时,导数f'(x)是2。
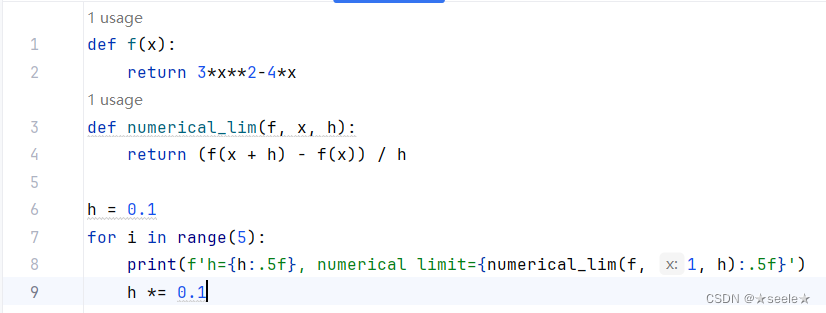
结果:
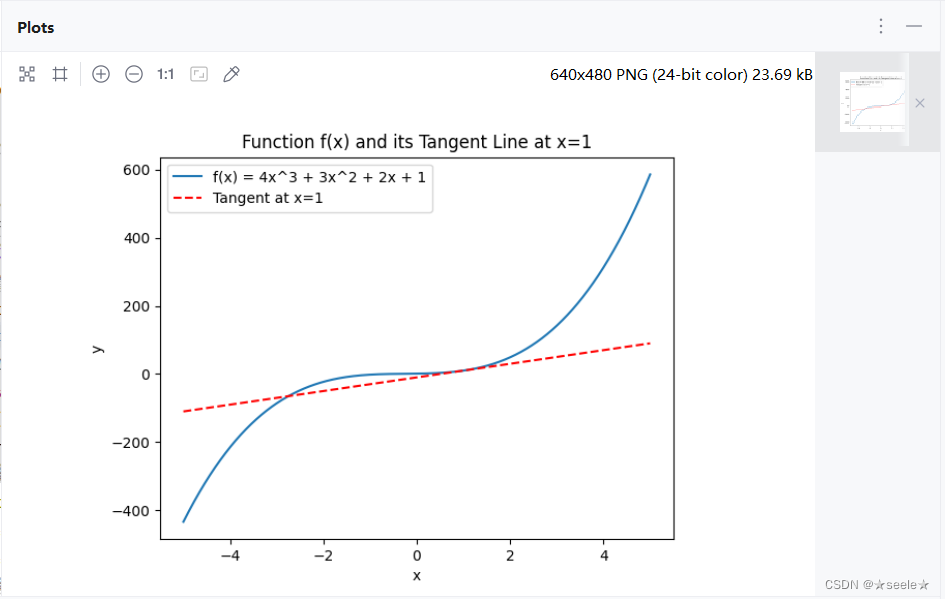
 掌握了导数的计算方法,接下来可以求曲线的切线方程并且绘制图像:
掌握了导数的计算方法,接下来可以求曲线的切线方程并且绘制图像:
结果:
 1.2 概率论
1.2 概率论
简单地说,机器学习就是做出预测。根据病人的临床病史,我们可能想预测他们在下一年心脏病发作的概率。 在飞机喷气发动机的异常检测中,我们想要评估一组发动机读数为正常运行情况的概率有多大。 在强化学习中,我们希望智能体(agent)能在一个环境中智能地行动。 这意味着我们需要考虑在每种可行的行为下获得高奖励的概率。 当我们建立推荐系统时,我们也需要考虑概率。 例如,假设我们为一家大型在线书店工作,我们可能希望估计某些用户购买特定图书的概率。 为此,我们需要使用概率学。
假设我们掷骰子,想知道看到1的几率有多大,而不是看到另一个数字。 如果骰子是公平的,那么所有六个结果都有相同的可能发生, 因此我们可以说1发生的概率为1/6。
然而现实生活中,对于我们从工厂收到的真实骰子,我们需要检查它是否有瑕疵。 检查骰子的唯一方法是多次投掷并记录结果。 对于每个骰子,我们将观察到1到6中的一个值。 对于每个值,一种自然的方法是将它出现的次数除以投掷的总次数, 即此事件(event)概率的估计值。 大数定律(law of large numbers)告诉我们: 随着投掷次数的增加,这个估计值会越来越接近真实的潜在概率。 让我们用代码试一试。
首先,我们导入必要的软件包。

在统计学中,我们把从概率分布中抽取样本的过程称为抽样(sampling)。 笼统来说,可以把分布(distribution)看作对事件的概率分配, 稍后我们将给出的更正式定义。 将概率分配给一些离散选择的分布称为多项分布(multinomial distribution)。
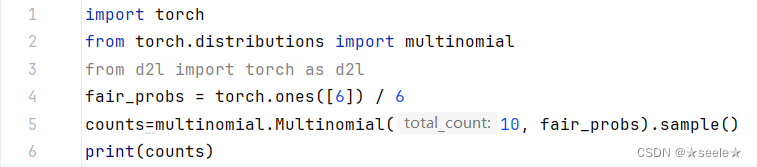
为了抽取一个样本,即掷骰子,我们只需传入一个概率向量。 输出是另一个相同长度的向量:它在索引处的值是采样结果中i出现的次数。
在估计一个骰子的公平性时,我们希望从同一分布中生成多个样本。 如果用Python的for循环来完成这个任务,速度会慢得惊人。 因此我们使用深度学习框架的函数同时抽取多个样本,得到我们想要的任意形状的独立样本数组
结果:
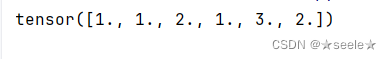 现在我们知道如何对骰子进行采样,我们可以模拟1000次投掷。 然后,我们可以统计1000次投掷后,每个数字被投中了多少次。 具体来说,我们计算相对频率,以作为真实概率的估计。
现在我们知道如何对骰子进行采样,我们可以模拟1000次投掷。 然后,我们可以统计1000次投掷后,每个数字被投中了多少次。 具体来说,我们计算相对频率,以作为真实概率的估计。
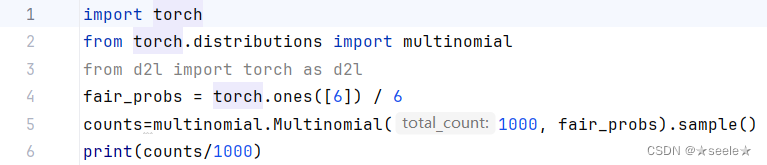
结果:

因为我们是从一个公平的骰子中生成的数据,我们知道每个结果都有真实的概率1/6,大约是
0.167,所以上面输出的估计值看起来不错。
我们也可以看到这些概率如何随着时间的推移收敛到真实概率。 让我们进行500组实验,每组抽取10个样本
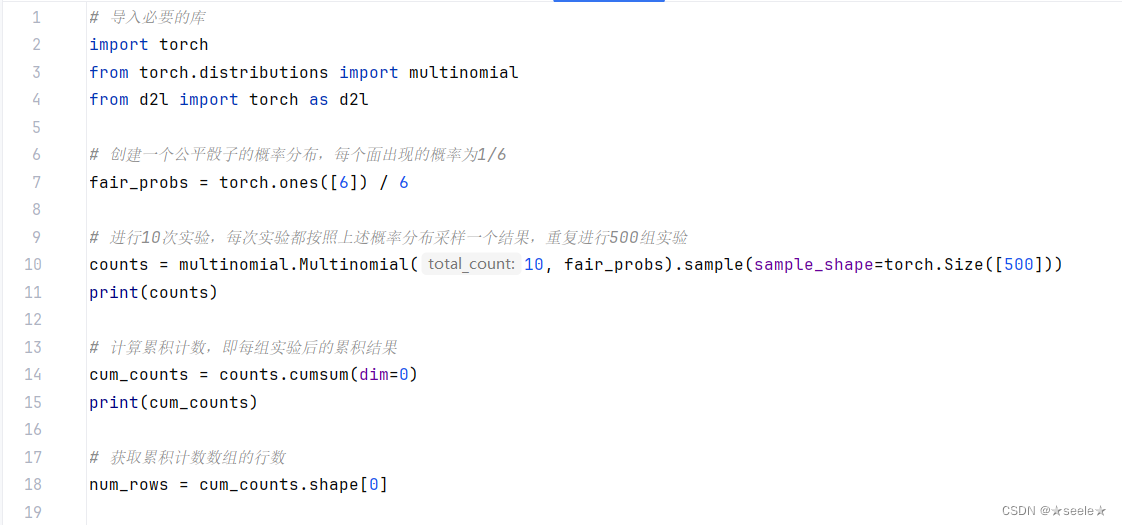
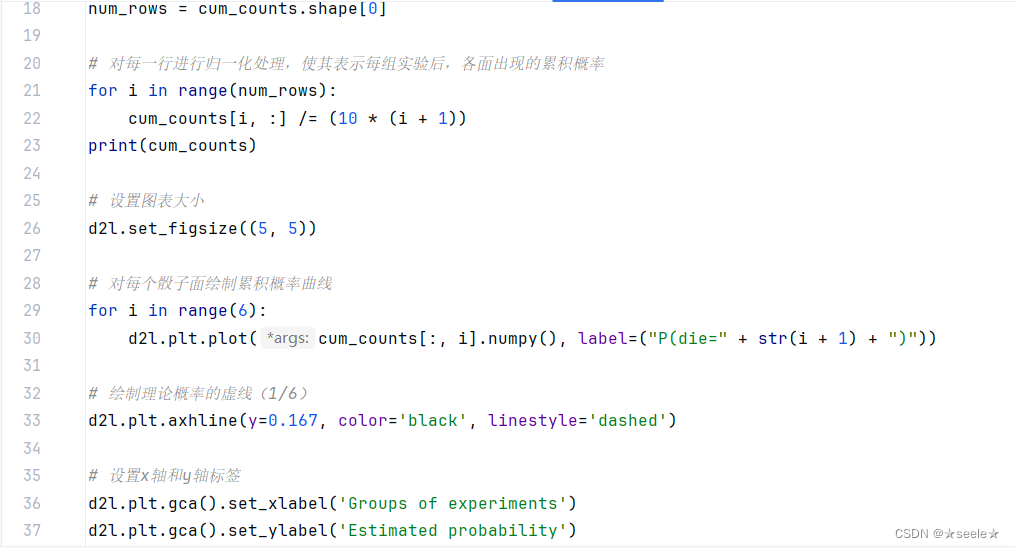
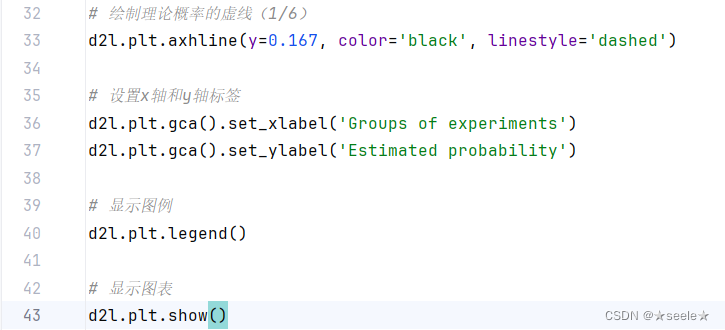
结果: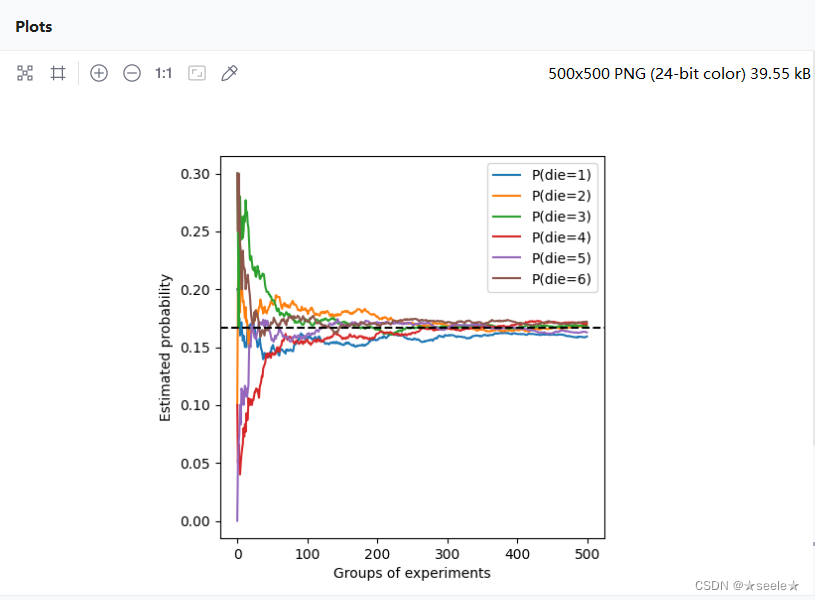
1.3 查阅文档
为了知道模块中可以调用哪些函数和类,可以调用dir函数。 例如,我们可以查询随机数生成模块中的所有属性:

有关如何使用给定函数或类的更具体说明,可以调用help函数。 例如,我们来查看张量ones函数的用法。















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









