






论文简介
空间红外微小舰船检测旨在从地球轨道卫星所拍摄的图像中识别并分离出微小舰船。由于图像覆盖面积极其广大(如数千平方公里),这些图像中的候选目标相比空中或地面成像设备观测到的目标,尺寸更小、亮度更低且变化更多。现有的基于短距离成像的红外数据集和目标检测方法难以很好地适应空间监视任务的需求。为了解决这些问题,作者创建了一个空间红外微小舰船检测数据集(命名为NUDT-SIRST-Sea),包含48幅空间红外图像及17,598个像素级的微小舰船标注。每幅图像覆盖约10,000平方公里的区域,分辨率为10,000×10,000像素。鉴于在这种极具挑战性场景中微小舰船的极端特性(如小、暗、多变),作者在此文中提出了一种多级TransUNet(MTU-Net)模型。具体而言,作者设计了一个视觉Transformer(ViT)与卷积神经网络(CNN)混合编码器来提取多层次特征。首先利用几个卷积层提取局部特征图,随后输入到多层次特征提取模块(MVTM)中,以捕捉远距离依赖关系。此外,作者进一步提出了复制-旋转-缩放-粘贴(CRRP)数据增强策略,加速训练过程,有效缓解了目标与背景样本不平衡的问题。同时,作者设计了FocalIoU损失函数,以同时实现目标定位和形状描述。在NUDT-SIRST-Sea数据集上的实验结果显示,作者的MTU-Net在检测概率、虚警率及交并比等关键指标上,超越了传统方法及现有的基于深度学习的单帧红外小目标(SIRST)检测技术,彰显了其在空间红外微小舰船检测领域的优越性能。
方法介绍
工作贡献可以概括如下:
NUDT-SIRST-Sea是目前最大的带有广泛类别标签的手动注释数据集,专为空间红外检测领域设计。该数据集包含17,598个高精度边界框及像素级注释,旨在支持和评估多种空间红外图像中目标检测器的研发与性能评估。
作者提出了一种新颖的Transformer-CNN混合架构——多级TransUNet(MTU-Net),专为空间红外微小舰船检测设计。借助多级ViT-CNN混合编码器,该架构能有效整合并充分利用微小舰船的远距离依赖关系,通过粗到细的特征提取及多层次特征融合策略,实现特征的全面挖掘。
作者创新性地提出了一种复制-旋转-缩放-粘贴(CRRP)数据增强技术和FocalIoU损失函数,用以缓解前景-背景不平衡问题,并在目标定位与形状描述上实现双赢。
实验结果证实,空间红外微小舰船检测是一项具有挑战性的任务,以往基于地面或空中的SIRST方法难以妥善应对由该任务引入的诸多挑战(如目标极小、亮度极低等)。作者的方法在三项关键评价指标上达到了当前最优水平:检测概率(Pd)、虚警率(Fa)和交并比(IoU),彰显了其在该领域的先进性与实用性。
| NUDT-SIRST-Sea数据集
远大于常规的图像尺寸:与表I中列出的现有SIRST数据集相比,NUDT-SIRST-Sea中的每幅图像覆盖约10,000平方公里的区域,分辨率为10,000×10,000像素,其图像尺寸是NUDT-SIRST、NUST-SIRST和NUAA-SIRST的数千倍之大。如图2(a)所示,如此大幅面的图像包含了更多不同的场景(例如港口、陆地、云层和海洋等)。此外,如此巨大的图像尺寸也带来了更高的计算难度。
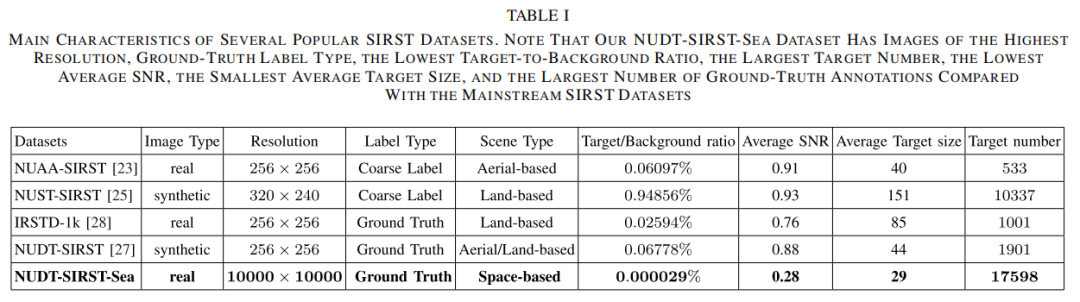
更为复杂的背景环境:如图1所示,相比空间红外图像,基于空中或地面的红外图像因覆盖面积有限而显得更为简单。如图2(b)所示,不同的场景(如云朵、微小舰船、港口、陆地以及海面)可以构成更多种类的复杂场景组合。在NUDT-SIRST-Sea数据集中,几种特定场景被视为检测难点,包括:城市内河、云块遮挡、密集目标群以及港口内的目标。这些复杂的场景对检测方法捕捉远距离上下文信息的能力构成了严峻挑战。

多类型疑似目标:如图2(c)所示,作者的NUDT-SIRST-Sea数据集含有丰富多样的疑似目标,包括微小云团、港口集装箱、礁石以及陆地光点等。这些疑似目标在形状与亮度上极易与真实的舰船目标混淆,从而可能引发误报。
极小目标尺寸:如表I所示,NUDT-SIRST-Sea数据集的平均目标尺寸仅为29像素,远小于其他主流SIRST数据集图像中的平均目标尺寸。NUDT-SIRST-Sea数据集的目标与背景比为0.000029%,相比NUDT-SIRST、NUST-SIRST及NUAA-SIRST的目标与背景比,小数百倍。如图2(d)所示,76%的目标在空间图像中所占面积不到0.005%;而其他数据集中的目标在空间图像中所占面积大多超过0.05%。因此,NUDT-SIRST-Sea中极小的目标尺寸使得该数据集比其他数据集更具挑战性。
更暗淡的目标:如表I所示,NUDT-SIRST-Sea数据集相比于其他数据集,目标的平均信噪比(SNR)要低得多。这些现有数据集之间的详细比较如图2(e)所示。像NUDT-SIRST、NUST-SIRST和NUAA-SIRST这样的数据集主要集中在亮度较高的目标上。然而,在NUDT-SIRST-Sea中,超过20%的目标亮度低于0.5。相比之下,在其他基于空中和地面的数据集中,亮度低于0.5的目标占比不足5%。因此,与其它数据集相比,NUDT-SIRST-Sea在检测暗淡目标方面更具挑战性。
多尺度目标:如图2(f)所示,不同类型船只(如大型游轮、中型采油井架和小型游艇)的尺寸变化极大,范围从2像素至500像素不等。鉴于空间红外图像覆盖的广阔区域,不同尺度的目标常在同一场景中同时出现。在同一个场景中检测不同尺度的目标是一项相当具有挑战性的任务。
| MTU-Net
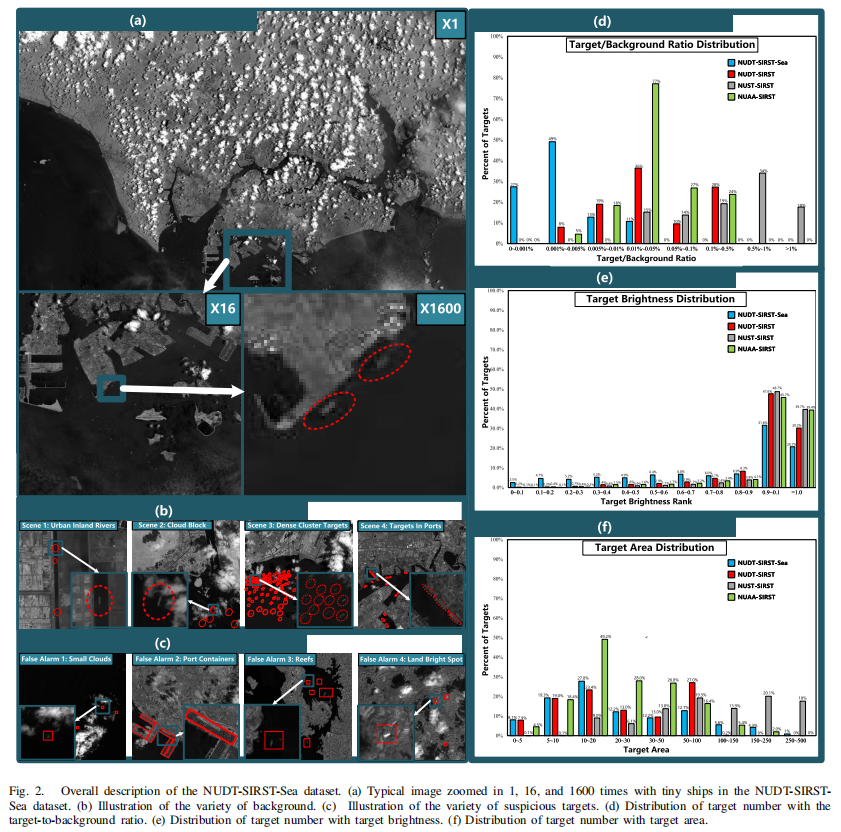
如图3所示,作者的MTU-Net以单幅图像作为输入,依次包含了一个多层次ViT-CNN混合编码器(第四章B节)、一个U形解码器(第四章C节)以及一个八邻域聚类模块(第四章D节),共同作用以生成像素级别的定位与分类结果。

数据增强方法
在NUDT-SIRST-Sea数据集中,前景目标与背景的分布极不平衡。这种前景与背景的不平衡问题导致网络更多地关注那些信息量不大的背景区域,从而阻碍了网络的快速收敛。复制粘贴(Copy-Paste, CP)是一种用于实例分割的强大数据增强方法。在此基础上,作者进一步提出了CRRP数据增强方法(即,Copy with Relative and Regional Preservation, CRRP),旨在训练阶段手动增加候选目标的比例,从而加速网络的收敛速度。
相较于仅复制目标本身的CP方法,CRRP数据增强方法不仅复制目标,还复制目标周围的背景区域。这一方式使得CRRP方法能够很好地保留目标自身的信息以及目标与其背景之间的上下文信息。否则,没有上下文依赖关系的支持,一些可疑目标(例如,微小的云朵、港口集装箱、礁石和陆地亮点)可能被错误地识别为目标。因此,相比于CP方法,CRRP在针对基于空间的SIRST检测任务中是一种更合适的数据增强策略,因为它能更准确地模拟和保留实际场景中的目标与背景关系。
如图4(a)所示,作者首先收集目标周边的图像,并随机选取一个目标进行复制。接着,对选中的目标进行随机旋转。之后,将目标随机缩放至作为候选目标的大小。最后,将此候选目标粘贴到图像背景区域中的某个位置。如图4(b)所示,通过这一过程,前景目标与背景的分布不均衡问题得到缓解,并且与先前简单的数据增强方法(如旋转、平移和色彩抖动)相比,训练时间也大大缩短。这种方法通过增加目标实例的数量和多样性,提高了模型对微小舰船这类稀疏且易混淆目标的识别能力,从而促进了模型学习过程的高效性和准确性。

| Focal Loss
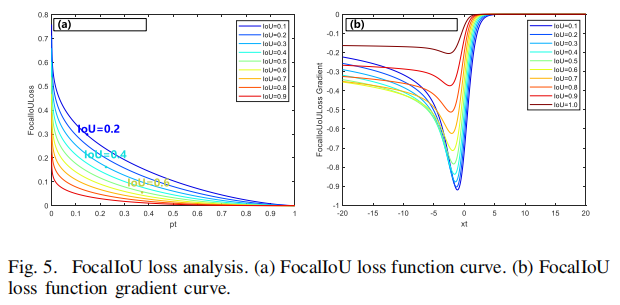
Focal Loss专注于难例样本(如小尺度目标、目标边缘及疑似目标),有助于目标定位的精确性。然而,由于在背景中的疑似区域响应过高,Focal Loss可能导致较多的虚警。SoftIoU Loss则侧重于大尺度目标,却忽视了小尺度目标。这是因为相比于小尺度目标,大尺度目标在IoU计算中的贡献更大,这无意中导致了小尺度目标信息的丢失。为了在目标定位与形状描述上实现“双赢”,作者结合了SoftIoU Loss与Focal Loss的优点,提出了FocalIoU Loss。FocalIoU Loss融合了Focal Loss与SoftIoU Loss的优势,既能在背景区域保持较低响应,又专注于小尺度目标。作者提出的FocalIoU损失函数公式如下:
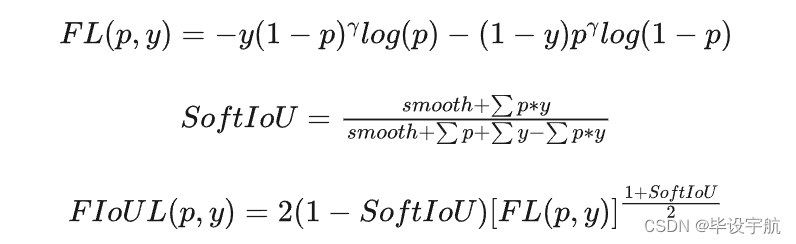
如图5(a)所示,低IoU输出的样本会导致FocalIoU损失较高,并使FocalIoU损失急剧下降。当IoU值较小时,表明该图像的整体分割性能较差,此时FocalIoU损失侧重于改善较难但相对简单的样本(例如大尺度目标),而非极度困难的样本,从而促使虚警率(Fa)降低,同时交并比(IoU)有所提升。相反,当IoU值较大时,FocalIoU损失的表现类似于标准的focal loss,更多地聚焦于真正的难题样本,这有助于提高检测概率(Pd)。因此,FocalIoU损失机制通过动态调整对不同类型样本的关注度,实现了在提高检测精度(Pd)和减少误报(Fa)的同时,优化目标轮廓匹配度(IoU),体现了在目标定位与形状描述上的双重优化效果。
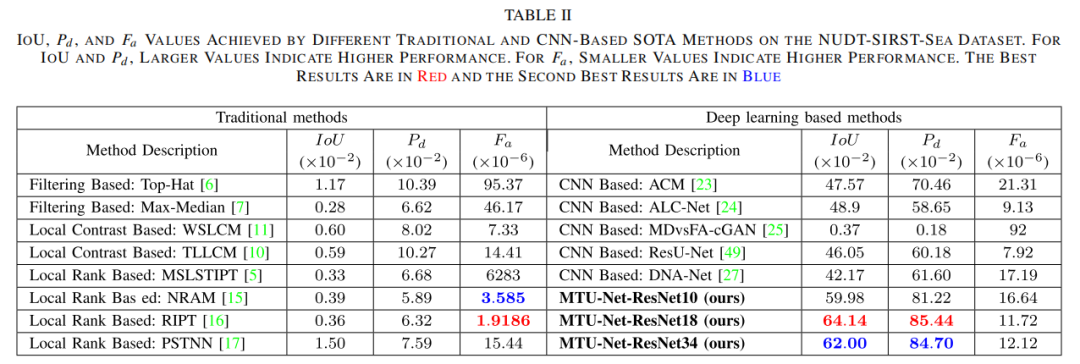
实验结果
| 定量分析
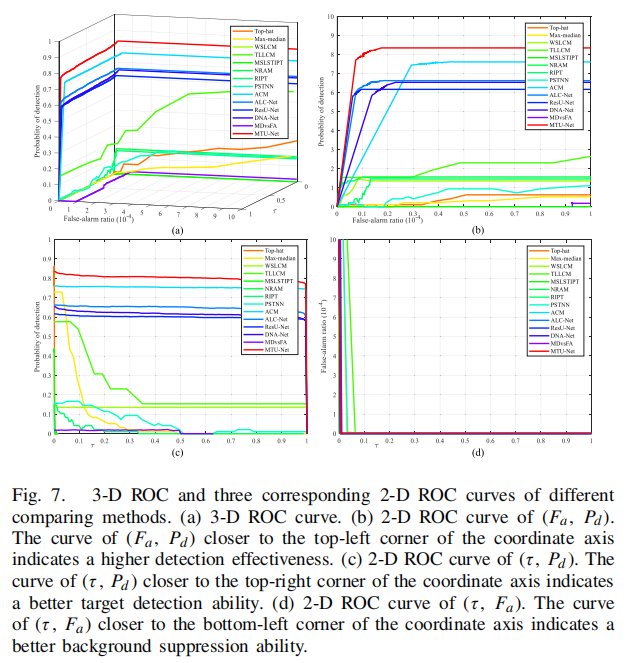
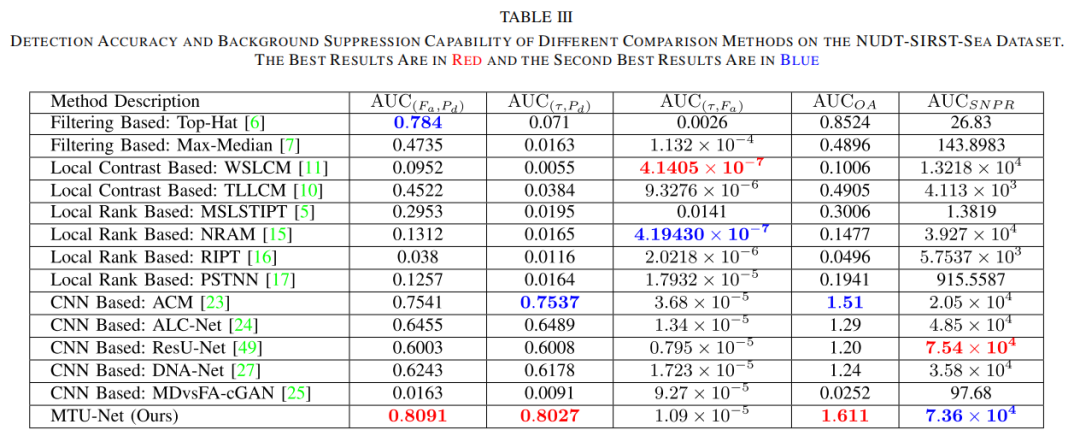
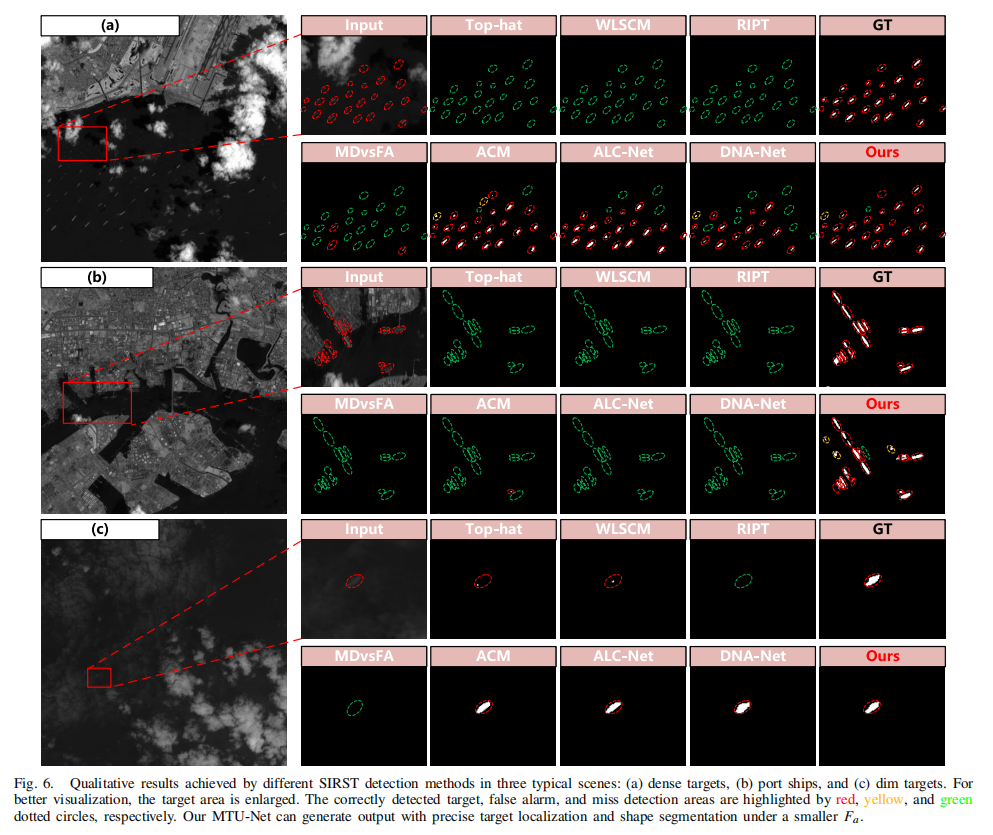
| 定性分析

















 1683
1683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









