







最近这一两周看到不少互联网公司都已经开始秋招提前批了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们星球
Efficient fine-tuning对于将大型语言模型(LLMs)调整到下游任务中至关重要。然而要在不同模型上实现这些方法需要付出相当大的努力。LLaMA-Factory是一个统一的框架,集成了一套先进的高效训练方法。它允许用户通过内置的Web UI灵活定制100多个LLMs的微调,而无需编写代码。

> https://arxiv.org/pdf/2403.13372.pdf
> https://github.com/hiyouga/LLaMA-Factory
-
多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
-
先进算法:GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ 和 Agent 微调。
-
实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
unsetunsetLLaMA-Factory的起源unsetunset
大型语言模型(LLMs)展示了卓越的推理能力,并赋予了各种应用程序以动力,随后大量的LLMs通过开源社区开发并可供使用。例如,Hugging Face的开源LLM排行榜拥有超过5,000个模型,为希望利用LLMs强大功能的个人提供了便利。
使用有限资源对极大数量的参数进行微调成为将LLM调整到下游任务的主要挑战。一个流行的解决方案是高效微调它在适应各种任务时降低了LLMs的训练成本。然而社区提出了各种高效微调LLMs的方法,缺乏一个系统的框架来将这些方法适应和统一到不同的LLMs,并为用户提供友好的界面进行定制。
为解决上述问题,LLaMA-Factory是一个LLMs微调的框架。它通过可伸缩模块统一了各种高效微调方法,实现了使用最小资源和高吞吐量微调数百个LLMs。此外,它简化了常用的训练方法,包括生成式预训练、监督微调、基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO)。用户可以利用命令行或Web界面定制和微调他们的LLMs,几乎不需要编写代码。
unsetunset高效微调技术unsetunset
高效LLM微调技术可以分为两大类:一类侧重于优化,另一类旨在计算。高效优化技术的主要目标是在保持成本最低的同时调整LLMs的参数。另一方面,高效计算方法旨在减少LLMs中所需计算的时间或空间。

高效优化
-
冻结微调方法涉及在微调少部分解码器层的同时冻结大部分参数。
-
梯度低秩投影将梯度投影到一个低维空间中,以一种内存高效的方式进行全参数学习。
-
低秩适应(LoRA)方法冻结所有预训练权重,并在指定的层引入一对可训练的低秩矩阵。
-
当与量化结合时,这种方法被称为QLoRA,它额外降低了内存使用。
高效计算
用的技术包括混合精度训练和激活检查点。通过对注意力层的输入输出(IO)开销进行检查,Flash Attention引入了一种硬件友好的方法来增强注意力计算。S2 Attention解决了在块稀疏注意力中扩展上下文的挑战,从而减少了在微调长上下文LLMs中的内存使用。各种量化策略通过使用更低精度的权重表示减少了大型语言模型(LLMs)的内存需求。
LLaMA-Factory有效地将这些技术结合到一个统一的结构中,大大提高了LLM微调的效率。这将导致内存占用从混合精度训练中的每个参数18字节,或者bfloat16训练中的每个参数8字节,减少到仅0.6字节每个参数。
unsetunsetLLaMA-Factory模块划分unsetunset
LLaMA-Factory由三个主要模块组成:模型加载器(Model Loader)、数据处理器(Data Worker)和训练器(Trainer)。

-
模型加载器准备了各种架构用于微调,支持超过100个LLMs。数据处理器通过一个设计良好的管道处理来自不同任务的数据,支持超过50个数据集。
-
训练器统一了高效微调方法,使这些模型适应不同的任务和数据集,提供了四种训练方法。
-
LLaMA Board为上述模块提供了友好的可视化界面,使用户能够以无需编写代码的方式配置和启动单个LLM微调过程,并实时监控训练状态。
unsetunsetLLaMA-Factory微调对比unsetunset
比较了完全微调、冻结微调、GaLore、LoRA和4位QLoRA的结果。微调后,我们计算训练样本上的困惑度,以评估不同方法的效率。

我们观察到,QLoRA始终具有最低的内存占用,因为预训练权重采用了更低的精度表示。LoRA通过Unsloth在LoRA层中的优化,实现了更高的吞吐量。
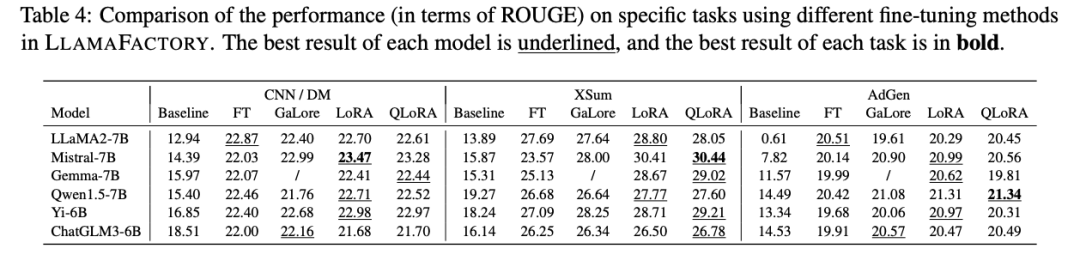
Mistral-7B模型在英文数据集上表现更好,而Qwen1.5-7B模型在中文数据集上获得了更高的分数。这些结果表明,微调模型的性能也与它们在特定语言上的固有能力相关联。
技术交流

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









