







1 目标检测发展脉络
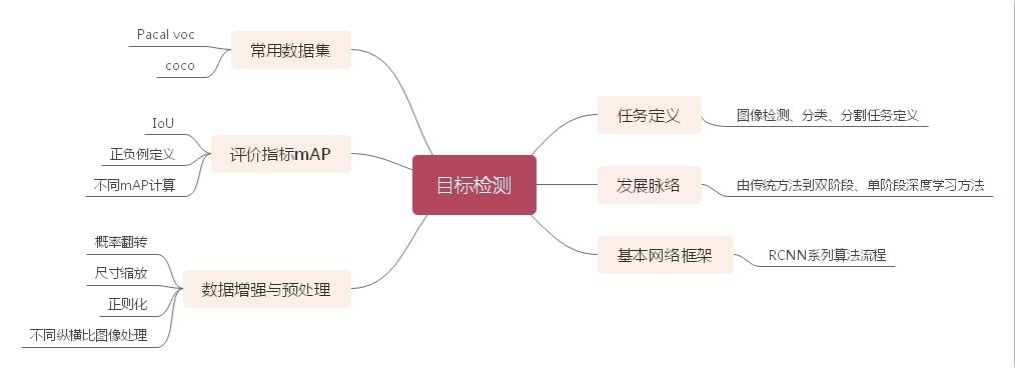
1.1目标检测任务及发展脉络 Object detection task and its development
- 图 像 处 理 三 大 任 务 :物 体 识 别 、 目 标 检 测 、 图 像 分 割
- 目 标 检 测 : 给 定 一 张 图 像 , 判 断 图 像 中 是否 存 在 指 定 类 别 的 目 标 , 若 存 在 , 则 输 出 目标 位 置 、 类 别 及 置 信 度 。
目 标 检 测 属 于 多 任 务 , 一 个 任 务 是 目 标 分类 , 另 一 个 是 目 标 位 置 的 确 定 , 即 分 类 与 回归
-
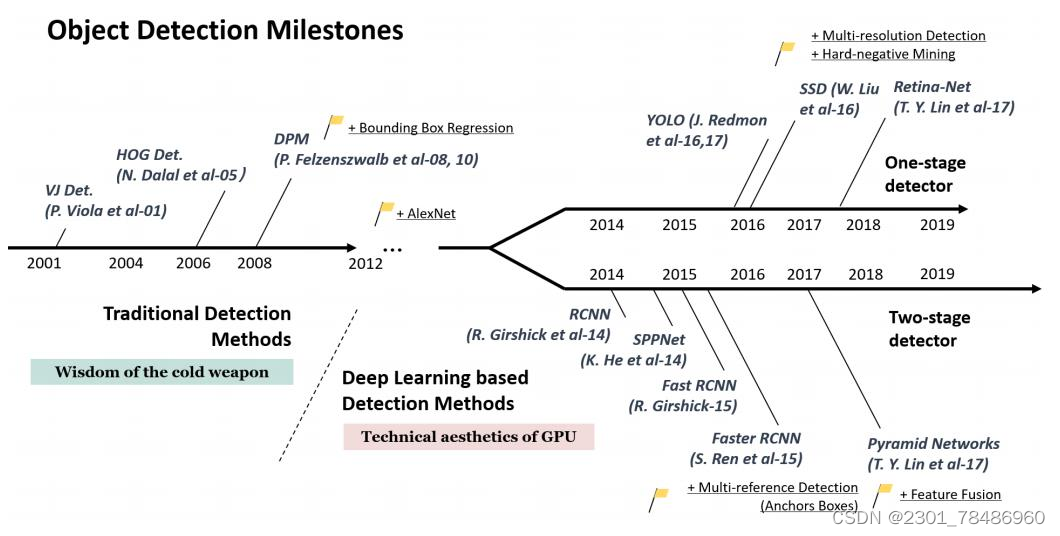
基于深层神经网络的目标检测
- 双阶段(two-stage):第一级网络用于候选区域提取;第二级网络对提取的候选区域进行分类和精确坐标回归,例如RCNN系列。
- 单阶段(one-stage):掘弃了候选区域提取这一步骤,只用一级网络就完成了分类和回归两个任务,例如YOLO和SSD等。
-
单 阶 段 网 络 的 准 确 度 为 何 不 如 双 阶 段 网 络 ,训 练 中 的 不 均 衡
- 负例过多,正例过少,负 例 产 生 的 损 失 完全淹没了正例 ;
- 大多数负例十分容易区分,网 络 无 法 学 习 到有 用 信 息 。 如 果 训 练 数 据 中 存 在 大 量 这 样的 样 本 , 将 导 致 网 络 难 以 收 敛 。
-
双 阶 段 网 络 如 何 解 决 训 练 中 的 不 均 衡
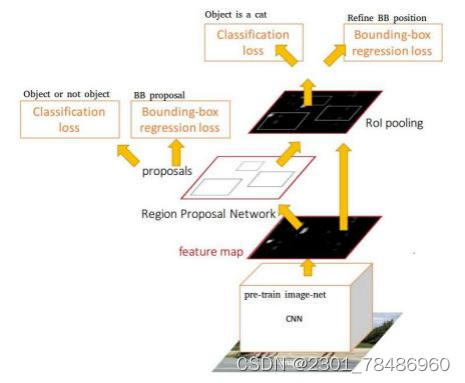
- 在 R P N 网 络(RPN全称是Region Proposal Network,Region Proposal的中文意思是“区域选取”,也就是“提取候选框”的意思,所以RPN就是用来提取候选框的网络。) 中 , 根 据 前 景 置 信 度 的 高 度 选 择最 有 可 能 的 候 选 区 域 , 从 而 避 免 大 量 容 易 区 分的 负 例 ;
- 训 练 过 程 中 根 据 交 并 比 进 行 采 样 , 将 正 负 样本 比 例 设 为 1 : 3 , 防 止 过 多 负 例 出 现 。
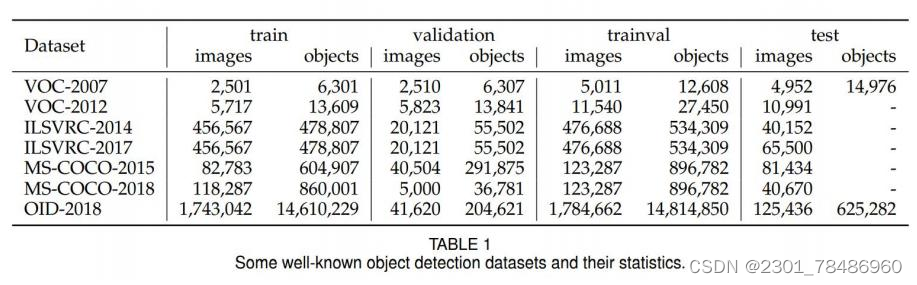
2 常用数据集介绍及数据交互
- Pascal Voc

下载地址: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
P a s c a l v o c , 分 为 2 0 0 7 和 2 0 1 2 两 个 版 本,其 提 供 的 数 据 集 里 包 含 了 2 0 类 的 物 体 。
P A S C A L V O C 的 主 要 2 个 任 务 是 ( 按 照 其 官 方 网 站 所 述 , 实 际 上 是 5 个 ):
① 分 类 : 对 于 每 一 个 分 类 , 判 断 该 分 类 是 否 在 测 试 照 片 上 存 在 ( 共 2 0 类 ) ;
② 检 测 : 检 测 目 标 对 象 在 待 测 试 图 片 中 的 位 置 并 给 出 矩 形 框 坐 标 ( b o u n d i n g b o x ) ;
③ 分 割 : 对 于 待 测 照 片 中 的 任 何 一 个 像 素 , 判 断 哪 一 个 分 类 包 含 该 像 素 ( 如 果 2 0 个 分 类没 有 一 个 包 含 该 像 素 , 那 么 该 像 素 属 于 背 景 ) ;
④ ( 在 给 定 矩 形 框 位 置 的 情 况 下 ) 人 体 动 作 识 别 ;
⑤ L a r g e S c a l e R e c o g n i t i o n ( 由 I m a g e N e t 主 办 ) 。
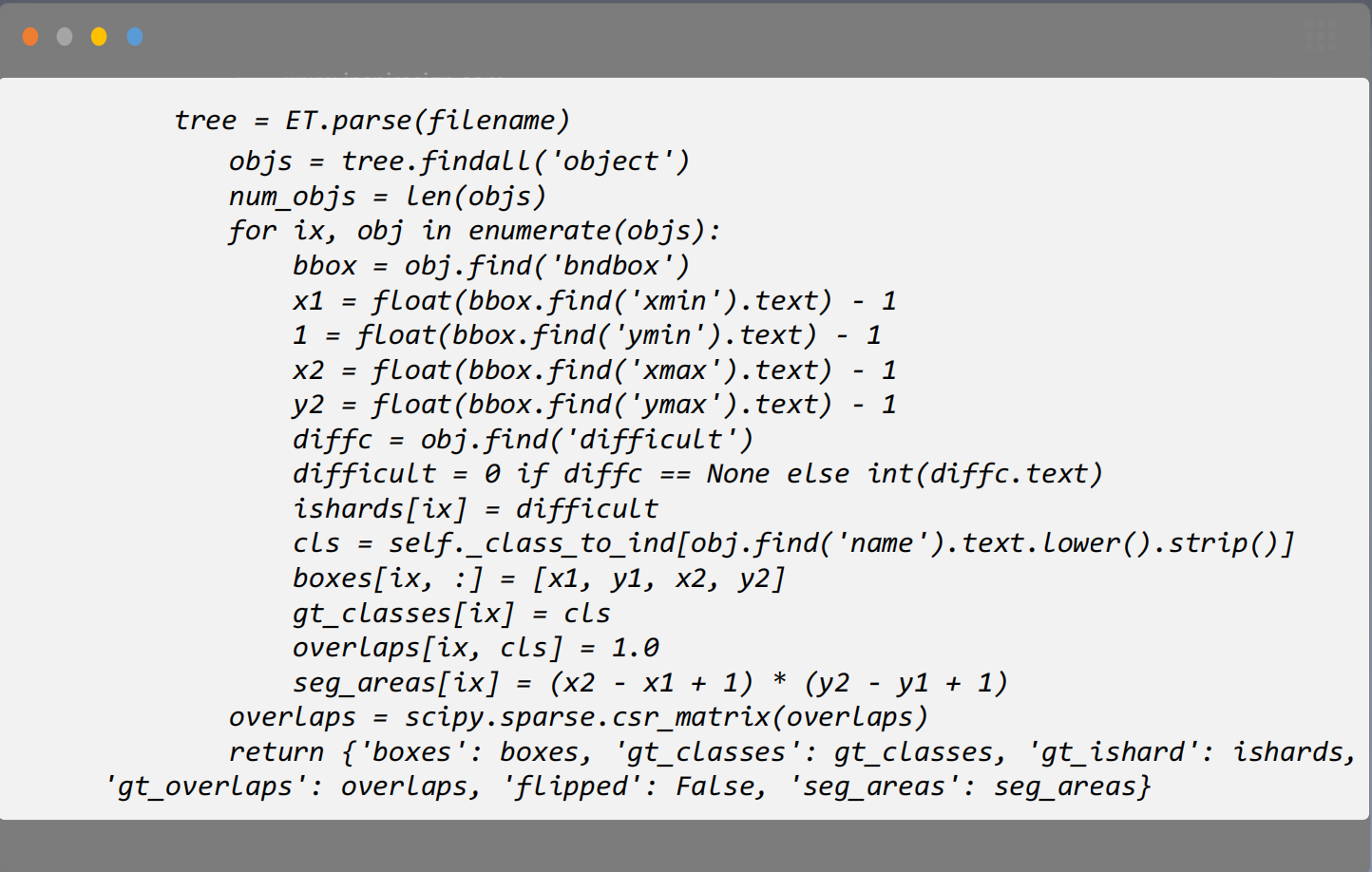
-
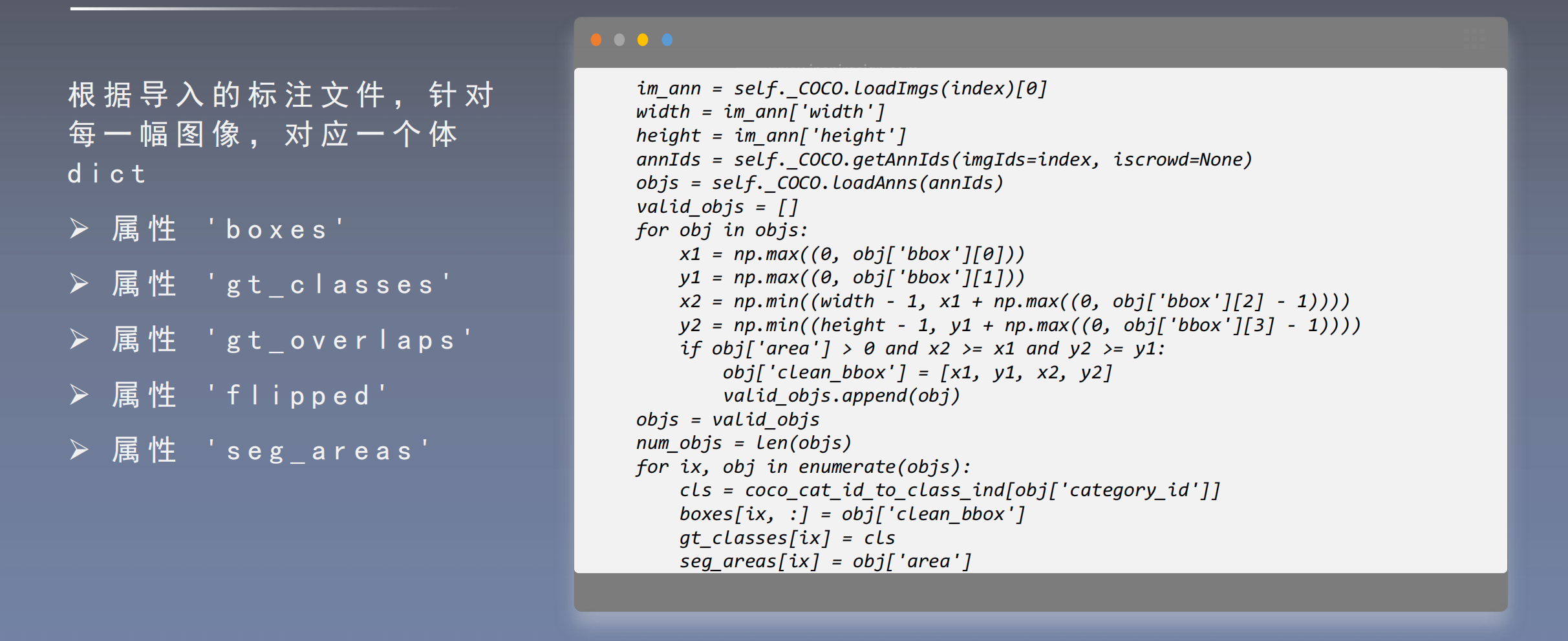
导 入 图 像 对 应 的 . x m l 文 件 ,针 对 每 一 幅 图 像 , 对 应 一个 体 d i c t
- 属 性 ’ b o x e s ’ , ’ g t _ c l a s s e s ’ ,’ g t _ o v e r l a p s ’ , ’ f l i p p e d ’ , ’ s e g _ a r e a s ’
-
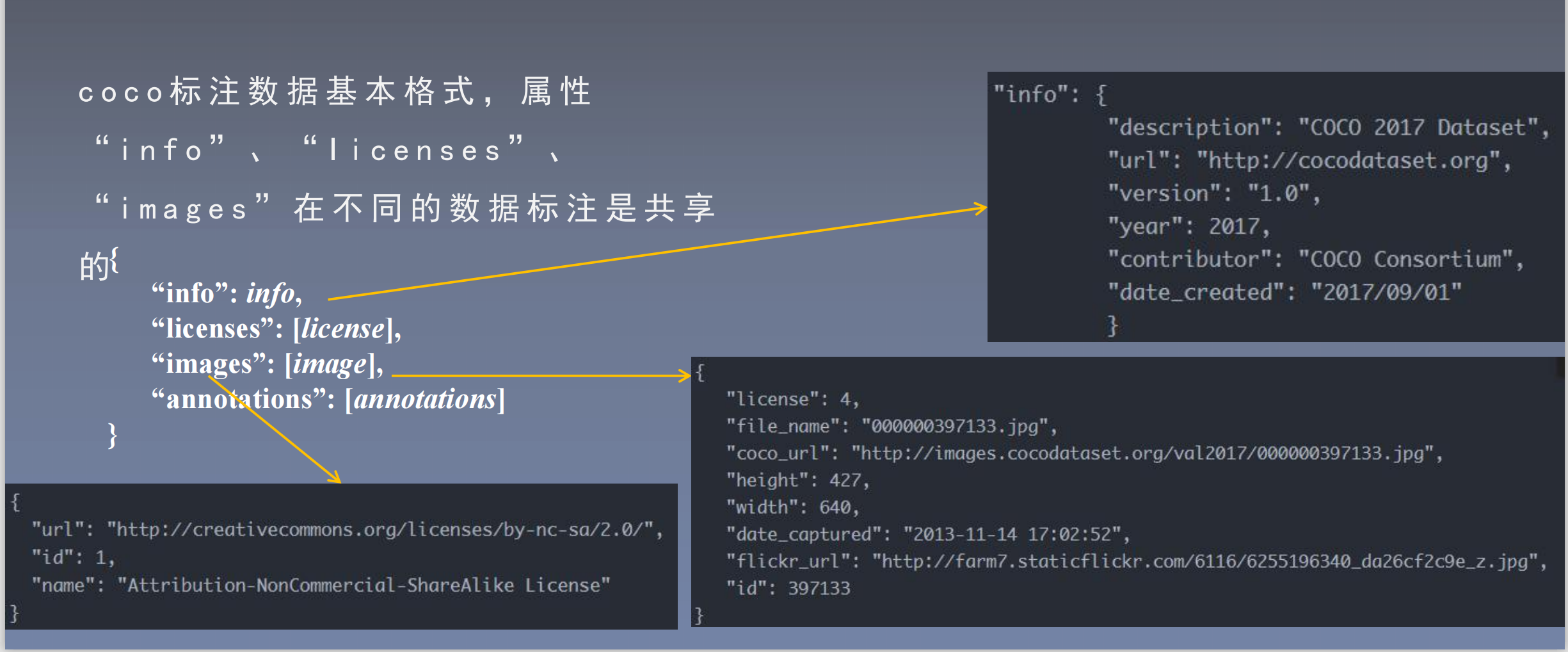
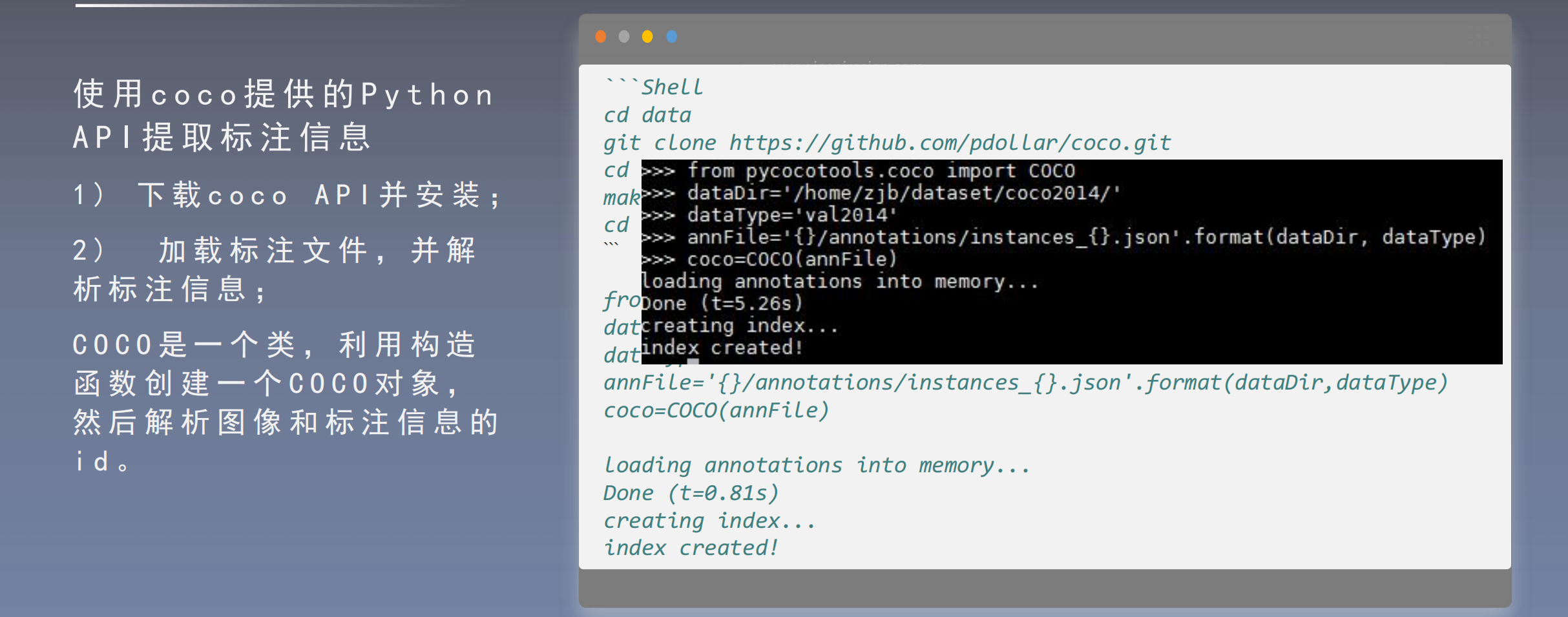
COCO
- C O C O , 分 为 2 0 1 4 、 2 0 1 5 和 2 0 1 7 版 本

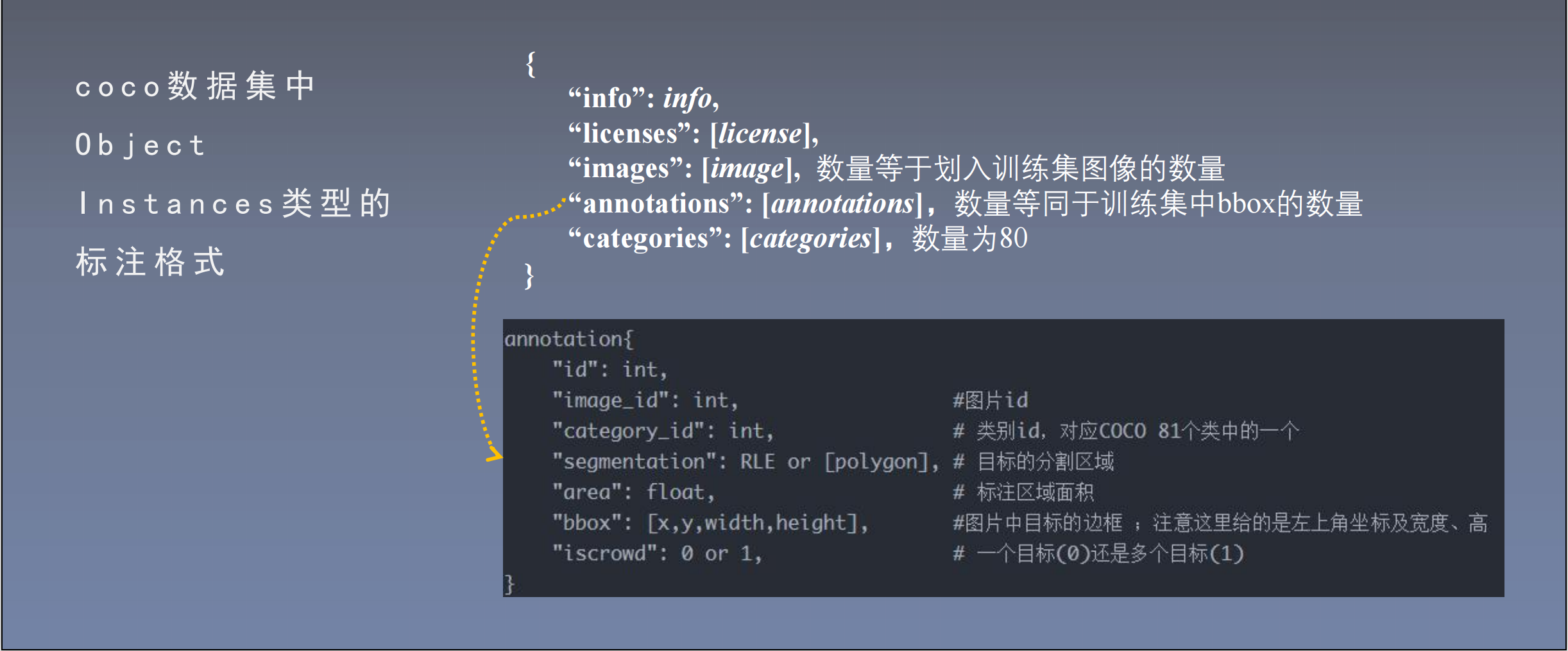
在 a n n o t a t i o n s 文 件 夹 中 对 数 据 标 注 信 息 进 行 统 一 管 理 。 例 如 , t r a i n 2 0 1 4 的 检 测 与 分割 标 注 文 件 为 i n s t a n c e s _ t r a i n 2 0 1 4 . j s o n
o b j e c t i n s t a n c e s ( 目 标实 例 ) 、 o b j e c t k e y p o i n t s ( 目 标关 键 点 ) 、 i m a g e c a p t i o n s ( 看 图 说话 ) 三 种 类 型 的 标 注

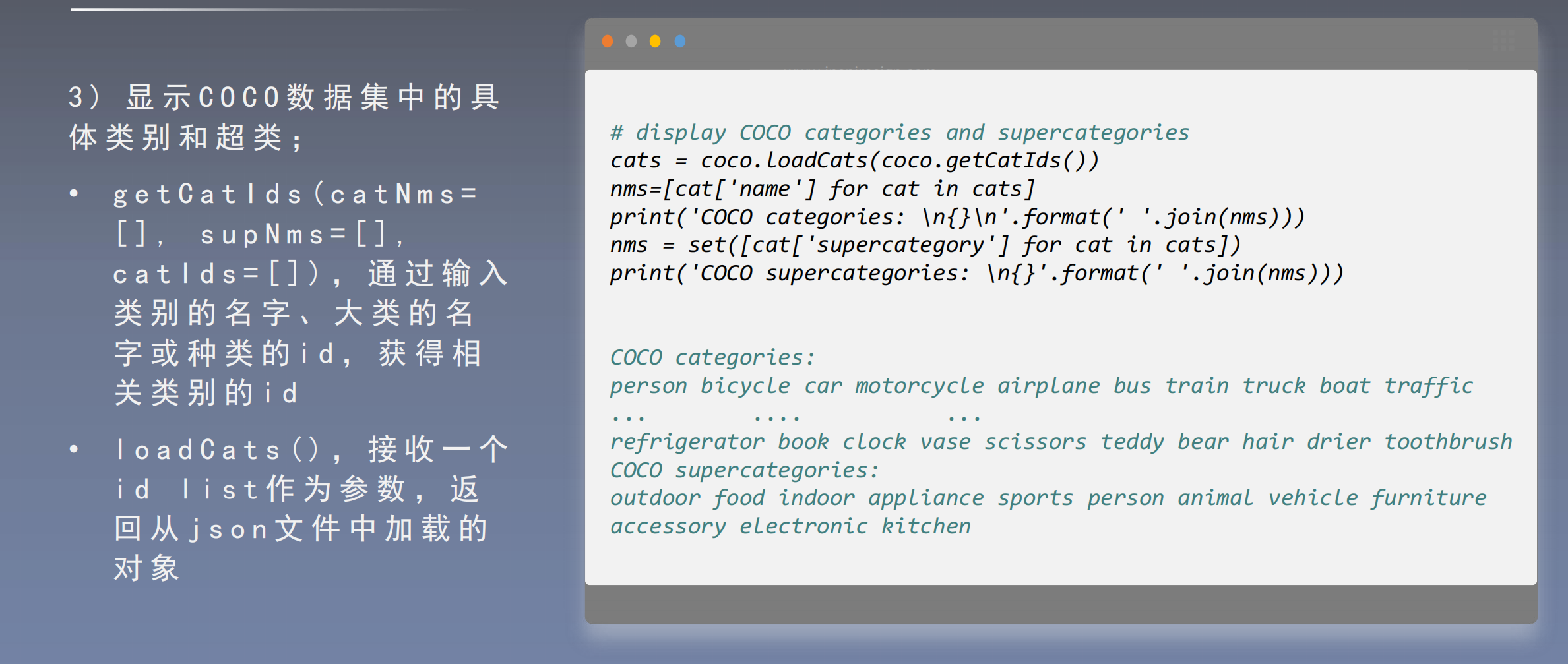
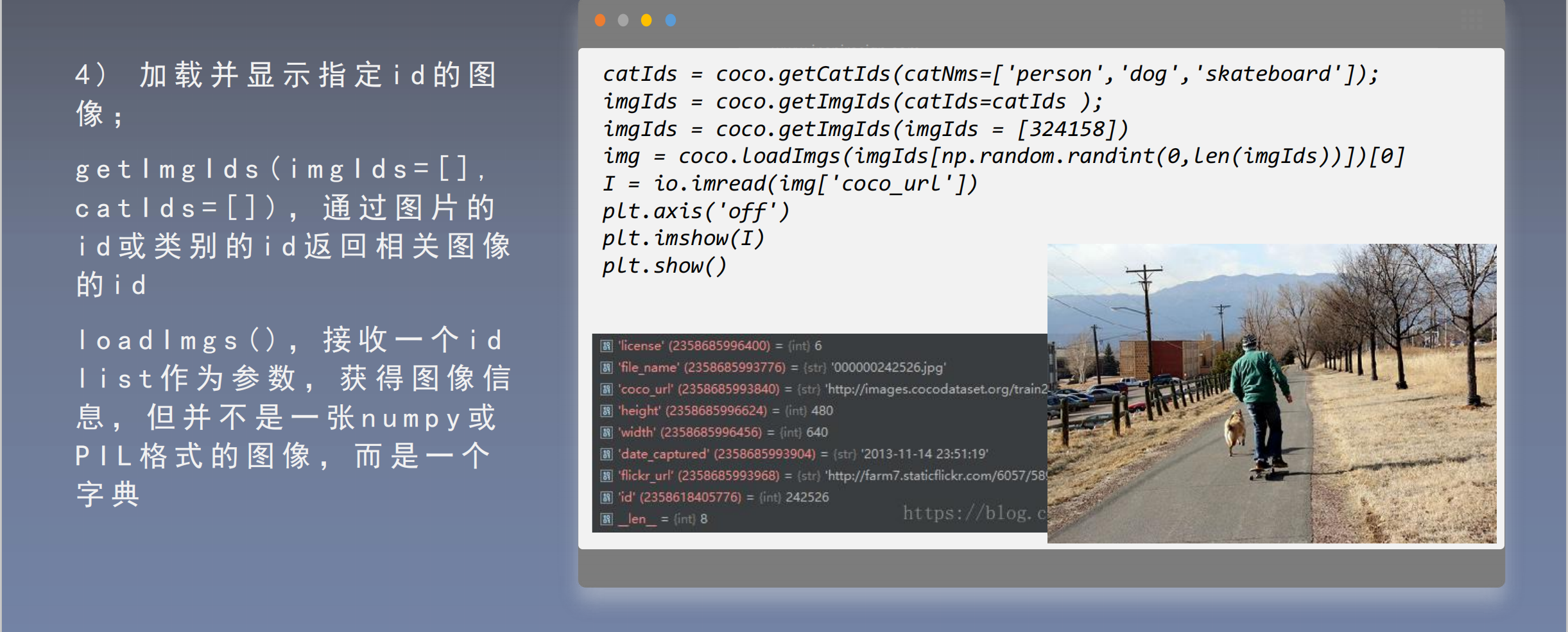
3 评价指标及计算方法介绍
- 常见的评价指标
True positives (TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
False positives (FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
False negatives (FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
True negatives (TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
精准率:Precision = TP / (TP + FP) = TP / 所有被模型预测为正样本的数据的数量
召回率:Recall = TP / (TP + FN) = TP / 所有真实类别为正样本的数据的数量
- PR曲线
我们当然希望检测的结果P越高越好,R也越高越好,但事实上这两者在某些情况下
是矛盾的。所以我们需要做的是找到一种精确率与召回率之间的平衡。其中一个方法就是画出PR曲线,然后用PR曲线下方的面积AUC(Area under Curve)去判断模型的好坏。
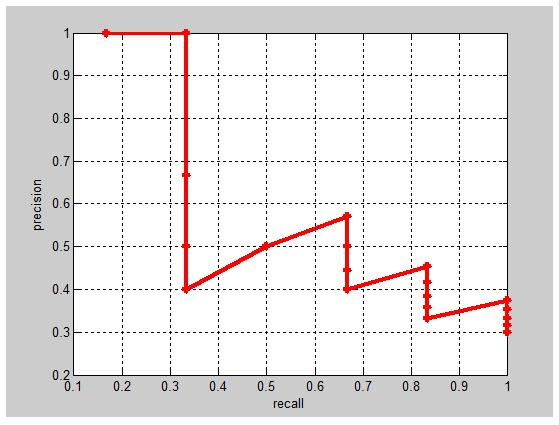
- IoU指标 Intersection over Union


训练好的目标检测模型会给出大量的预测结果,但是其中大多数的预测值都会有非
常低的置信度(confidence score),因此我们只考虑那些置信度高于某个阈值的预测结果。
将原始图片送入训练好的模型,在经过置信度阈值筛选之后,目标检测算法给出带有边界框的预测结果:

IoU是预测框与ground truth的交集和并集的比值。对于每个类,预测框和ground
truth重叠的区域是交集,而横跨的总区域就是并集。

-
目标检测中的PRPR in Object Detection
TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)
FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
FN: 没有检测到的GT的数量
由于图片中我们没有预测到物体的每个部分都被视为Negative,因此计算True
Negatives比较难办。
Precision = TP / (TP + FP) = TP / 所有被模型预测为正样本的数据的数量
Recall = TP / (TP + FN) = TP / 所有真实类别为正样本的数据的数量
在PASCAL VOC数据集中标注为difficult的数据不计入计算 -
mAP的计算方式 PR in Object Detection
通过PR曲线,我们可以得到对应的AP值:
- 在2010年以前,PASCAL VOC竞赛中AP是这么定义的:
首先要对模型预测结果进行排序(ranked output,按照各个预测值置信度降序排列。
我们把recall的值从0到1划分为11份:0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0。
在每个recall区间(0-0.1, 0.1-0.2,0.2-0.3,…,0.9-1.0)上我们计算精确率的最大值,然后再计算这些精确率最大值的总和并平均,就是AP值。 - 从2010年之后,PASCAL VOC竞赛把这11份recall点换成了PR曲线中的所有recall数据点。
对于某个recall值r,precision值取所有recall>=r中的最大值(这样保证了p-r曲线是单调递减的,避免曲线出现摇摆)这种方法叫做all-points-interpolation。这个AP值也就是PR曲线下的面积值。
- COCO中mAP的计算方法 mAP in COCO
C O C O 中 m A P 的 计 算 方 法 :
采 用 的 是 I O U ( 用 于 决 定 是 否 为 T P ) 在 [ 0 . 5 : 0 . 0 5 : 0 . 9 5 ] 计 算 1 0次 A P , 然 后 求 均 值 的 方 法 计 算 A P 。
4 数据增强及预处理方法
-
深 层 神 经 网 络 的 训 练 过 程 , 数 据 的 预 处 理 十 分 关 键 。 常 用 的 预 处 理 步 骤 包 括 :
图 像 归 一 化
图 像 增 强 , 包 括 翻 转 、 裁 剪 、 饱 合 度 亮 度 变 换 、 噪 声
图 像 的 纵 横 比 处 理 -
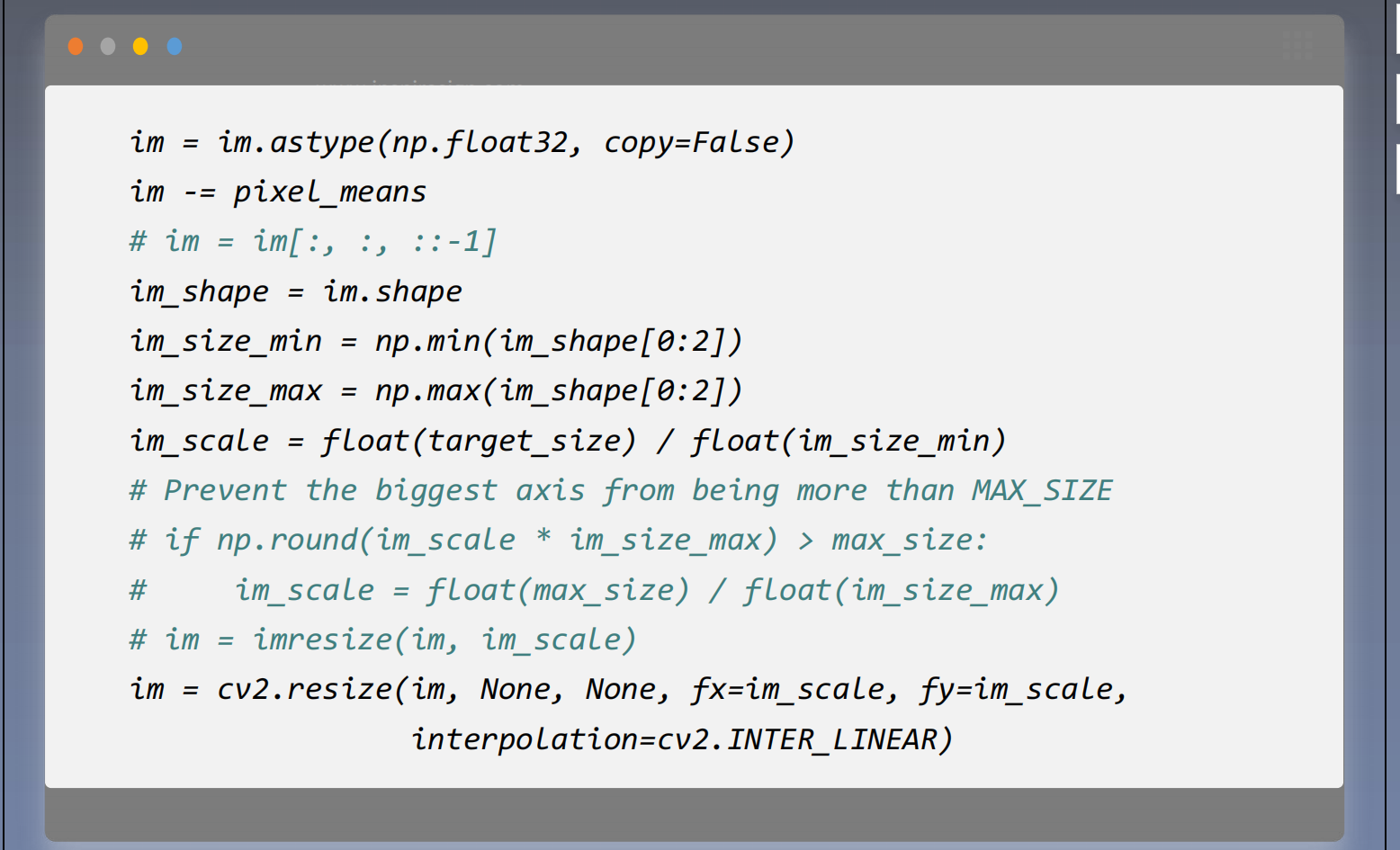
图 像 的 归 一 化 处 理
常 见 的 图 像 操 作 , 一 般灰度归 一 化 , 即 减 去 均 值 ; 保持纵横 比 , 将 图 像 的 短 边 缩 放至 同 一 大 小 。
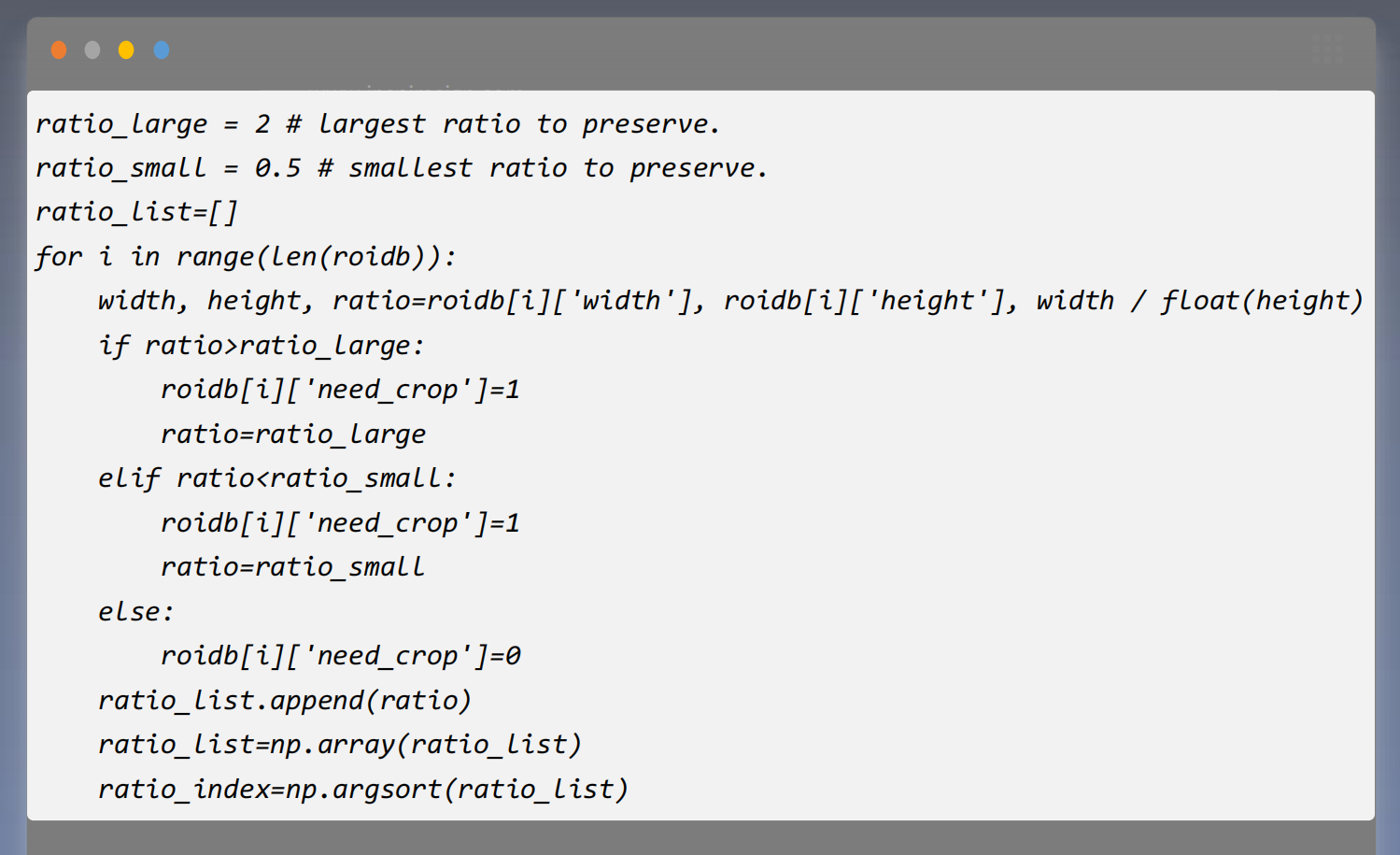
- 图 像 纵 横 比 的 计 算 和 排 序
选 定 图 像 纵 横 比 的 上 下 限 ,分 别 为 0 . 5 和 2 , 纵 横 比 超过 此 范 围 的 需 要 进 行 截 取操 作 。
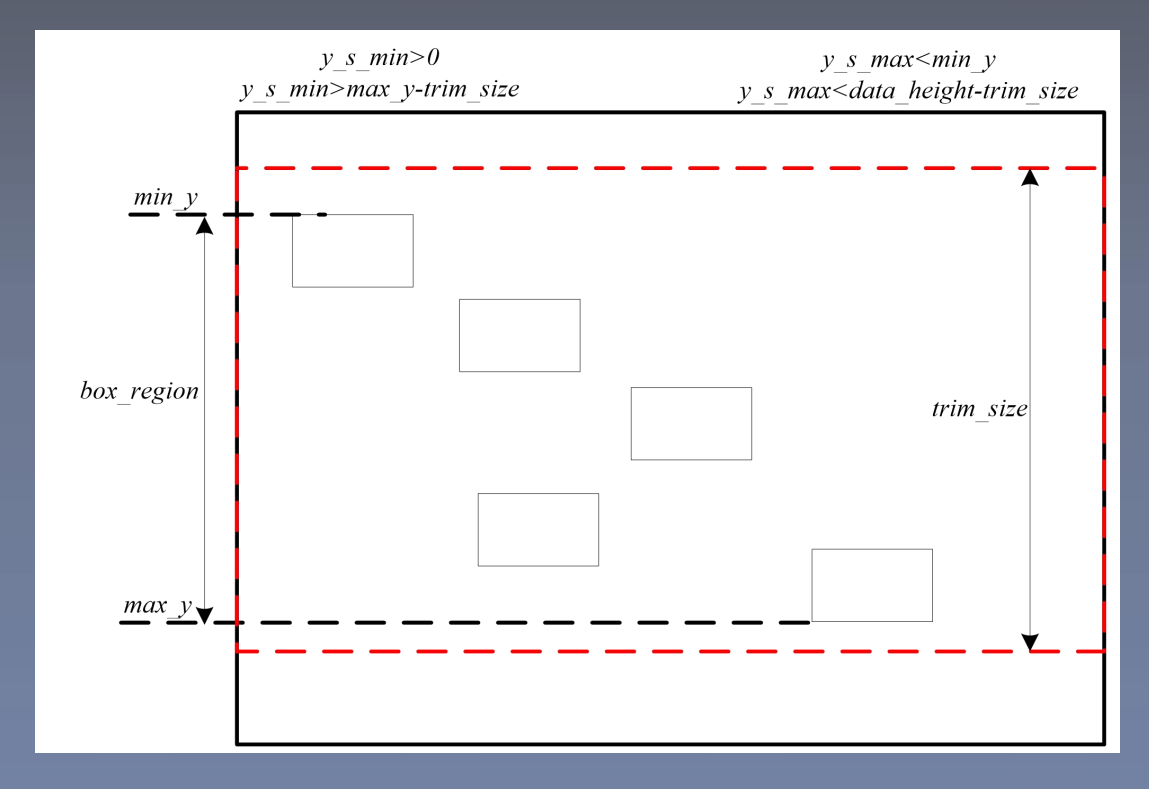
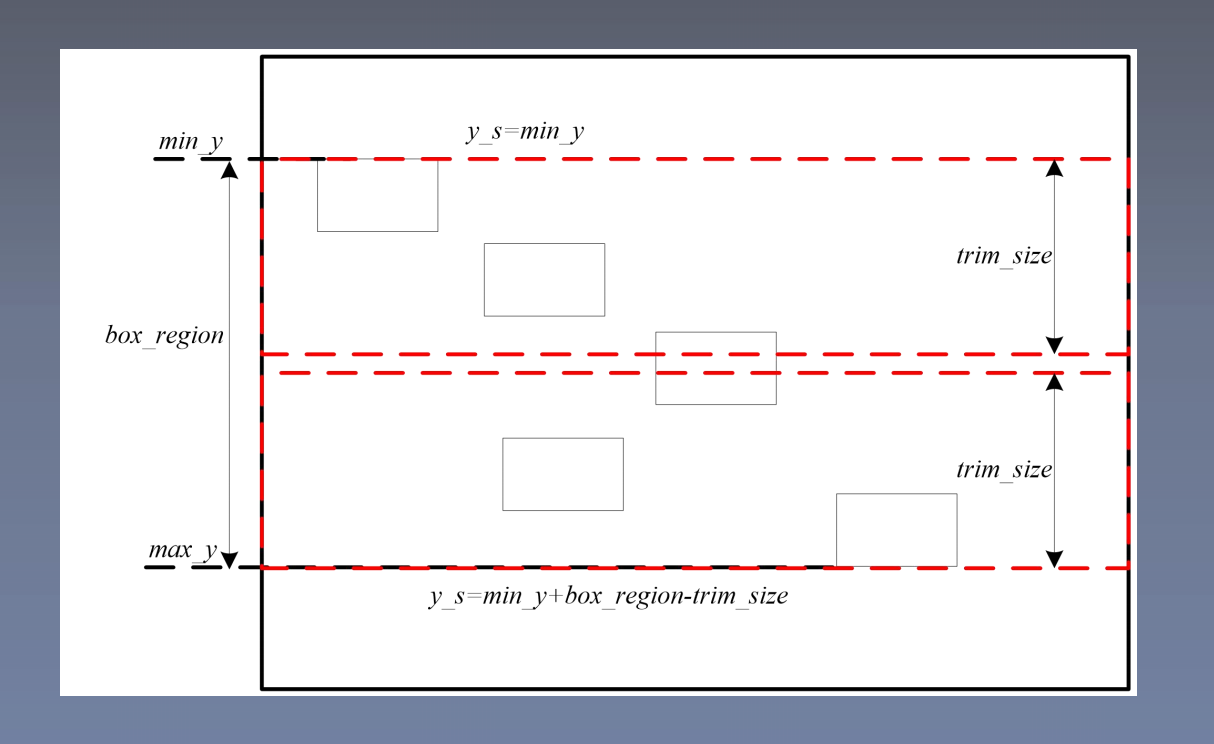
- 图 像 裁 剪
覆 盖 尽 可 能 多 的 b b o x , 同 时 考 虑区 域 差 异 化
以 纵 横 比 < 1 为 例 , 需 要 对 图 像 的 高度 进 行 裁 剪 , 以 图 像 裁 剪 能 否 覆 盖全 部 b b o x 分 开 考 虑
5 非极大值抑制 Non-Maximum Suppression (NMS)
NMS算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,
具体的实现思路如下:
- 选取这类box中scores最大的哪一个,记为box_best,并保留它
- 计算box_best与其余的box的IOU
- 如果其IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保
留分数高的哪一个) - 从最后剩余的boxes中,再找出最大scores的哪一个,如此循环往复
















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









