







百日筑基篇—— 统计函数简介一(R语言初识八)
前言
在R语言中,各种各样的统计函数在帮助我们在数据分析中起到了十分重要的作用。下面我就简单介绍一下统计函数。
一、数学统计函数
这些函数可以帮助进行基本的数学统计计算,例如计算中心趋势、离散程度、相关性以及数字转换等。
以下是一些数学统计函数的简介:
mean():计算向量或数据框的平均值。
median():计算向量或数据框的中位数。
mode():用于计算对象的数据类型。
var():计算向量或数据框的方差。
sd():计算向量或数据框的标准差。
cov():计算向量或数据框的协方差矩阵。
cor():计算向量或数据框的相关系数。
quantile():计算向量或数据框的分位数。
range():计算向量或数据框的极差。
diff():计算向量的差分。
log():计算向量的自然对数。
exp():计算向量的指数函数。
abs():计算向量的绝对值。
sum():计算向量或数据框的总和。
prod():计算向量或数据框的乘积。
#创建一个矩阵
Q <- c(4:19)
dim(Q) <- c(4,4)
> Q
[,1] [,2] [,3] [,4]
[1,] 4 8 12 16
[2,] 5 9 13 17
[3,] 6 10 14 18
[4,] 7 11 15 19
#计算每列的平均值
> apply(Q,2,mean)
[1] 5.5 9.5 13.5 17.5
#计算每列的方差
> apply(Q,2,var)
[1] 1.666667 1.666667 1.666667 1.666667
#计算对象的数据类型
> apply(Q,2,mode)
[1] "numeric" "numeric" "numeric" "numeric"
#计算每列的分位数
> apply(Q,2,quantile)
[,1] [,2] [,3] [,4]
0% 4.00 8.00 12.00 16.00
25% 4.75 8.75 12.75 16.75
50% 5.50 9.50 13.50 17.50
75% 6.25 10.25 14.25 18.25
100% 7.00 11.00 15.00 19.00
#计算极差
> apply(Q,2,range)
[,1] [,2] [,3] [,4]
[1,] 4 8 12 16
[2,] 7 11 15 19
#计算向量或数据框的乘积
> prod(Q[,1])
[1] 840
#计算总和
> apply(Q,2,sum)
[1] 22 38 54 70
#创建一个数据框
#state.x77 %>% class()
state <- as.data.frame(state.x77[,c(5,1,3,2,7)])
state1 <- head(state,4)
> state1
Murder Population Illiteracy Income Frost
Alabama 15.1 3615 2.1 3624 20
Alaska 11.3 365 1.5 6315 152
Arizona 7.8 2212 1.8 4530 15
Arkansas 10.1 2110 1.9 3378 65
#计算协方差矩阵
> cov(state1)
Murder Population Illiteracy Income Frost
Murder 9.3091667 1776.983 0.34750 -707.275 7.333333e-01
Population 1776.9833333 1771897.667 326.15000 -1495924.500 -7.497200e+04
Illiteracy 0.3475000 326.150 0.06250 -305.225 -1.313333e+01
Income -707.2750000 -1495924.500 -305.22500 1771844.250 6.517300e+04
Frost 0.7333333 -74972.000 -13.13333 65173.000 4.026000e+03
#计算相关系数
> cor(state1)
Murder Population Illiteracy Income Frost
Murder 1.000000000 0.4375308 0.4555745 -0.1741487 0.003787993
Population 0.437530803 1.0000000 0.9800722 -0.8442627 -0.887652321
Illiteracy 0.455574490 0.9800722 1.0000000 -0.9172069 -0.827938490
Income -0.174148658 -0.8442627 -0.9172069 1.0000000 0.771645905
Frost 0.003787993 -0.8876523 -0.8279385 0.7716459 1.000000000
#计算向量的差分
> apply(state1,2,function(x) diff(x,lag=1,differences = 2))
Murder Population Illiteracy Income Frost
Arizona 0.3 5097 0.9 -4476 -269
Arkansas 5.8 -1949 -0.2 633 187
# 计算向量的自然对数以及指数函数
> log(state1,base = exp(2))
Murder Population Illiteracy Income Frost
Alabama 1.357347 4.096424 0.3709687 4.097667 1.497866
Alaska 1.212401 2.949949 0.2027326 4.375342 2.511940
Arizona 1.027062 3.850826 0.2938933 4.209239 1.354025
Arkansas 1.156268 3.827222 0.3209269 4.062520 2.087194
二、概率密度函数
概率密度函数是用于描述随机变量的概率分布的函数。它描述了随机变量在不同取值处的概率密度。
可以将概率密度函数看作是描述概率分布形状的曲线
正态分布也是一种概率密度函数,是最常见的连续型概率分布之一。
# 正态分布
?Normal
x <- seq(-4, 4, 0.01)
y <- dnorm(x, mean = 0, sd = 1) # 计算每个x值对应的概率密度函数值
plot(x, y, type = "l", lwd = 2, main = "标准正态分布曲线", xlab = "x", ylab = "密度")
library(dplyr)
#计算给定值在正态分布中的概率密度函数的值
> dnorm(2,mean=0,sd=1,log=FALSE)
[1] 0.05399097
#计算给定值在正态分布中的累积概率分布函数的值
> pnorm(2,mean = 0,sd = 1,lower.tail = TRUE,log.p = FALSE)
[1] 0.9772499
#计算给定概率在正态分布中对应的值
> qnorm(0.999999999999, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
[1] 7.034487
#生成一组符合正态分布的随机数
> rnorm(n=10,mean=12,sd=2) %>% round()
[1] 12 12 9 11 16 15 13 14 13 11
#绘制正态分布图
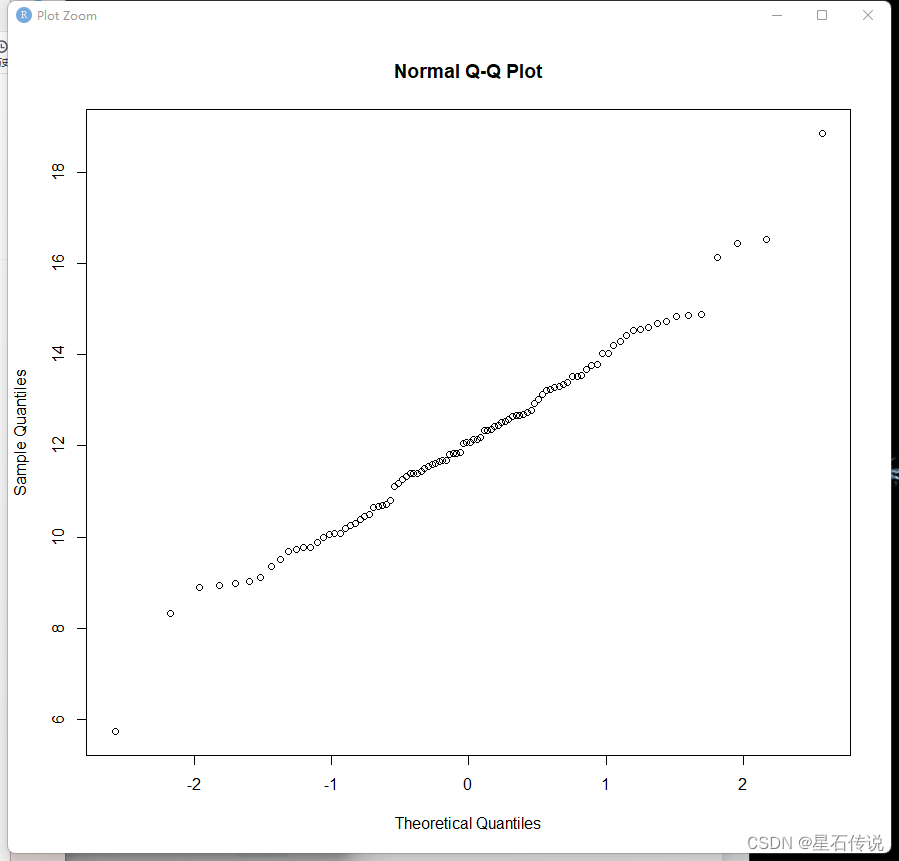
qqnorm(rnorm(n=100,mean=12,sd=2))
#生成随机数
set.seed(555)
> runif(10,min = 1,max = 100) %>% round()
[1] 23 95 46 34 53 44 71 32 55 65
#随机生成的gamma分布的概率密度
> dgamma(c(1:9),shape = 2,rate=1)
[1] 0.367879441 0.270670566 0.149361205 0.073262556 0.033689735 0.014872513
[7] 0.006383174 0.002683701 0.001110688
补充:
概率密度函数表示了随机变量取某个值的概率密度,通过计算给定值在概率密度函数上的值,我们可以了解到该值在正态分布中的相对密度
累积概率是指给定随机变量小于或等于某个特定值的概率。
在正态分布中,累积概率分布函数给出了随机变量落在一个给定值及其左侧的概率
使用qqnorm()函数来绘制正态概率图(Q-Q plot)。是一种用于评估数据是否近似服从正态分布的图形方法。
如果数据近似正态分布,那么QQ图上的点将大致位于一条直线上。
Gamma分布是一种连续概率分布,通常用于描述正数值的随机变量。
具有不对称的形状,它是由两个参数控制的。其中,形状参数决定了分布的形状,速率参数控制了分布的变化程度.
dgamma()函数用于计算给定值在Gamma分布中的概率密度函数的值
三、描述性统计函数
myvars <- mtcars[c("mpg","hp","wt","am")]
#结果返回变量数据的min,max,mean,median ,quantites
> summary(myvars)
mpg hp wt am
Min. :10.40 Min. : 52.0 Min. :1.513 Min. :0.0000
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581 1st Qu.:0.0000
Median :19.20 Median :123.0 Median :3.325 Median :0.0000
Mean :20.09 Mean :146.7 Mean :3.217 Mean :0.4062
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610 3rd Qu.:1.0000
Max. :33.90 Max. :335.0 Max. :5.424 Max. :1.0000
#计算五数概括
> fivenum(myvars$mpg)
[1] 10.40 15.35 19.20 22.80 33.90
#返回变量和观测的数量、缺失值和唯一值的数目、以及平均值、分位数、已经五个最大的值和五个最小的值
library(Hmisc)
describe(myvars)
library(pastecs)
stat.desc(myvars)
stat.desc(myvars,norm = TRUE)
#如果设置norm为T,那么就会计算一些统计值,包括正态分布统计量、偏度和峰度等。
#trim = 0.1 表示在计算均值时将忽略最小和最大的各10%的极端值
library(psych)
psych::describe(myvars,trim = 0.1)
psych::describeBy(myvars,list(am=myvars$am,hp=myvars$hp))
#aggregate()函数可对数据进行分组描述,能够对数据按照指定的分组信息进行统计,将分组信息通过一个列表指定出来即可
library(MASS)
aggregate(Cars93[c("Min.Price","Max.Price","MPG.city")],by=list(Manufacturer=Cars93$Manufacturer,Origin=Cars93$Origin),mean)
library(doBy)
summaryBy(mpg+hp+wt~am+cyl,data=myvars,FUN = c(mean,sd,sum))
#左侧是需要分析的数值型变量,右侧的变量是类别型的分组变量
四、频数统计函数
频数统计函数是指通过对一组数据进行统计分析,求出每个数据出现的次数。
在R语言中,一般使用table函数来进行频数统计,table函数会返回一个统计结果的频数表。
cylfactors <- as.factor(mtcars$cyl)
#使用mutate函数在myvars数据集中添加一个新的列
myvars <- dplyr::mutate(myvars,cylfactors1=cylfactors)
#使用split()函数对数据根据因子进行分组
split(myvars,myvars$cylfactors1)
#使用cut()函数进行分组
cut(myvars$mpg,seq(10,50,10)) %>% class()#因子
split(myvars,cut(myvars$mpg,seq(10,50,10)))
#prop.table()函数计算频率值
> cut(myvars$mpg,seq(10,50,10)) %>% table() %>% prop.table()
.
(10,20] (20,30] (30,40] (40,50]
0.5625 0.3125 0.1250 0.0000
library(vcd)
Arthritis
#返回一个包含Treatment和Improved两个变量的交叉频数表
> table(Arthritis$Treatment,Arthritis$Improved)
None Some Marked
Placebo 29 7 7
Treated 13 7 21
#如果变量太多,我们也可以使用with()
with(data = Arthritis,table(Treatment,Improved))
#处理二维列联表还可以使用xtabs()函数,这个函数的好处是它的选项参数使用的是formula参数,
x <- xtabs(~Treatment+Improved, data = Arthritis)
#使用margin.table()和prop.table()函数分别计算边际频数与比例(边际频率)
> margin.table(x)
[1] 84
#1代表行,2代表列
> margin.table(x,1)
Treatment
Placebo Treated
43 41
> prop.table(x,2)
Improved
Treatment None Some Marked
Placebo 0.6904762 0.5000000 0.2500000
Treated 0.3095238 0.5000000 0.7500000
#可以直接将边际的和添加到频数表中
> addmargins(x)
Improved
Treatment None Some Marked Sum
Placebo 29 7 7 43
Treated 13 7 21 41
Sum 42 14 28 84
#使用ftable()函数,它能将结果转换为一个平铺式的列联表
> xtabs(~ Treatment+Improved+Sex,data = Arthritis) %>% ftable()
Sex Female Male
Treatment Improved
Placebo None 19 10
Some 7 0
Marked 6 1
Treated None 6 7
Some 5 2
Marked 16 5
总结
今天,简单介绍了一下在R语言函数中的统计函数的一部分,有数学统计函数、概率密度函数、描述性统计函数以及频数统计函数。认识并合理运用这些函数有助于我们对数据进行分析,好了,就总结到这里了。
秦时明月汉时关,万里长征人未还。
–2023-7-25 筑基篇
















 3045
3045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











