







 本文介绍了亚细胞定位的在线工具,如UniProt、WoLFPSORT、BUSCA和TargetP-2.0,以及如何使用Python爬虫实现基于WoLFPSORT的结果整理。作者强调了WoLFPSORT的易用性。然而,爬虫部分遇到挑战,需进一步学习爬虫技术才能改进。
本文介绍了亚细胞定位的在线工具,如UniProt、WoLFPSORT、BUSCA和TargetP-2.0,以及如何使用Python爬虫实现基于WoLFPSORT的结果整理。作者强调了WoLFPSORT的易用性。然而,爬虫部分遇到挑战,需进一步学习爬虫技术才能改进。
实验篇——亚细胞定位
文章目录
前言
有关亚细胞定位的详细信息,请参考另一篇文章:
理化性质与亚细胞定位
一、亚细胞定位的在线网站
1. UniProt
网址:https://www.uniprot.org/
在这个网站中有一个关键的概念——ID映射(若AA序列文件不是在该官网中下载的,而是从外界导入的,那么要先将AA序列的ID转变为UniProt ID)
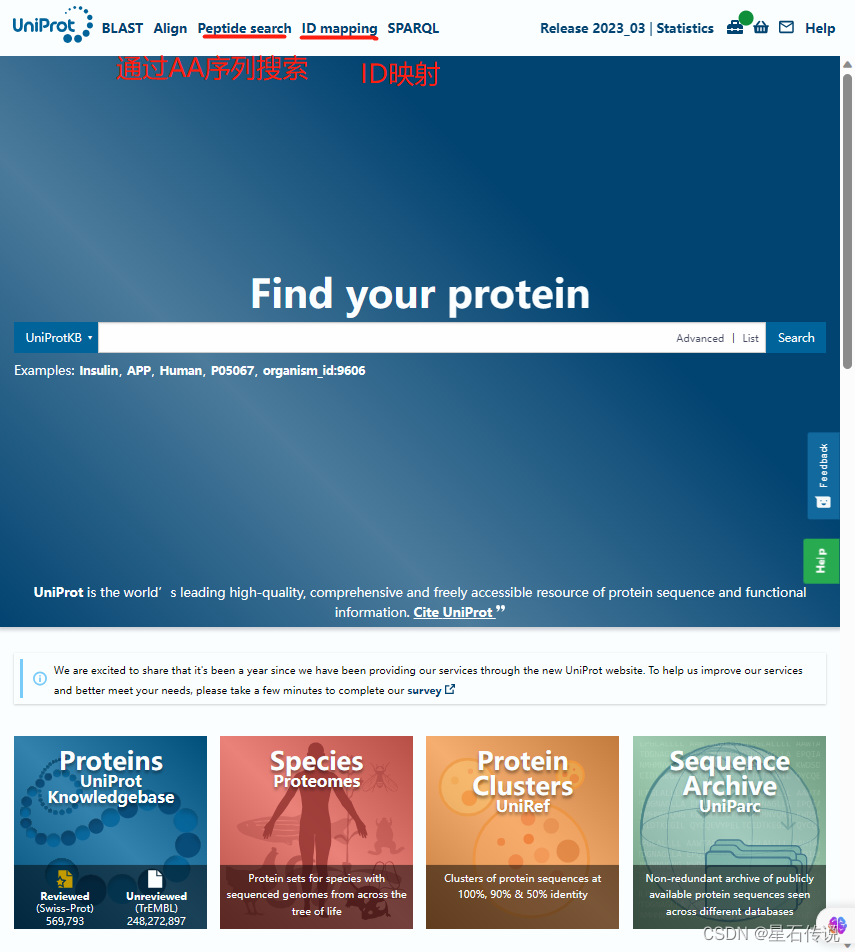
注意:首先要清楚待转换的AA序列的ID标识符来源于哪个数据库
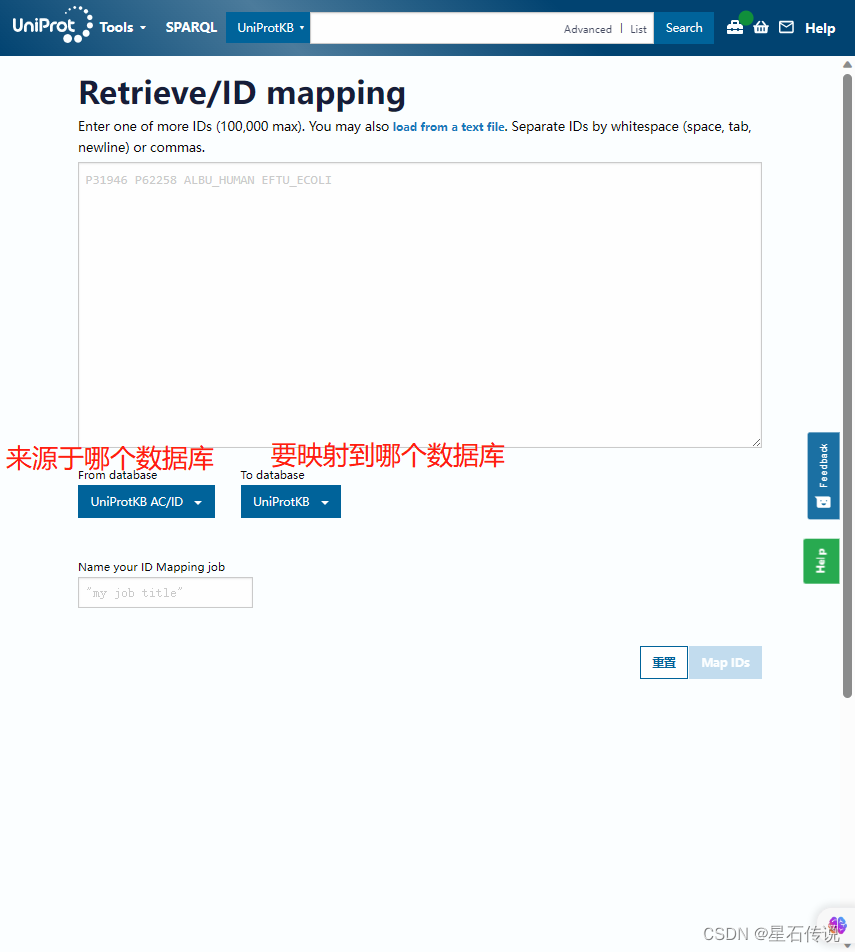
我输入了“sp|Q9FIK7.1|AACT1_ARATH”,这是某个AA序列的ID,得到如下结果,可知道它对应的UniProt ID 为 “Q8S4Y1”
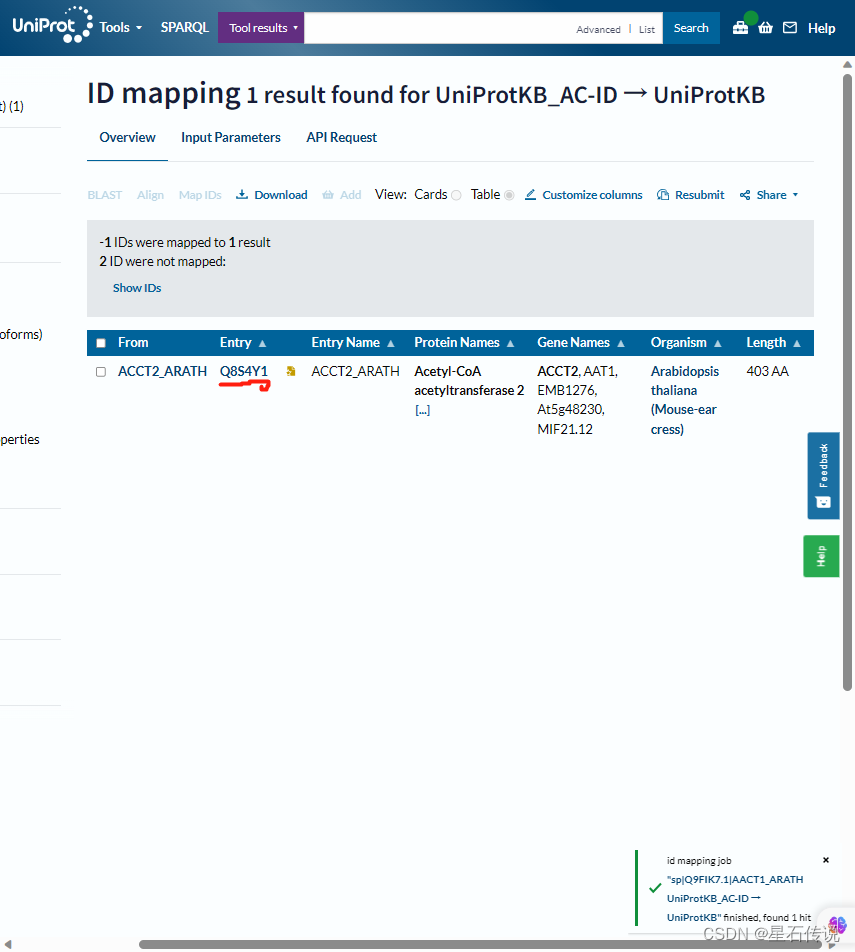
然后在搜索栏中输入该名称,得到
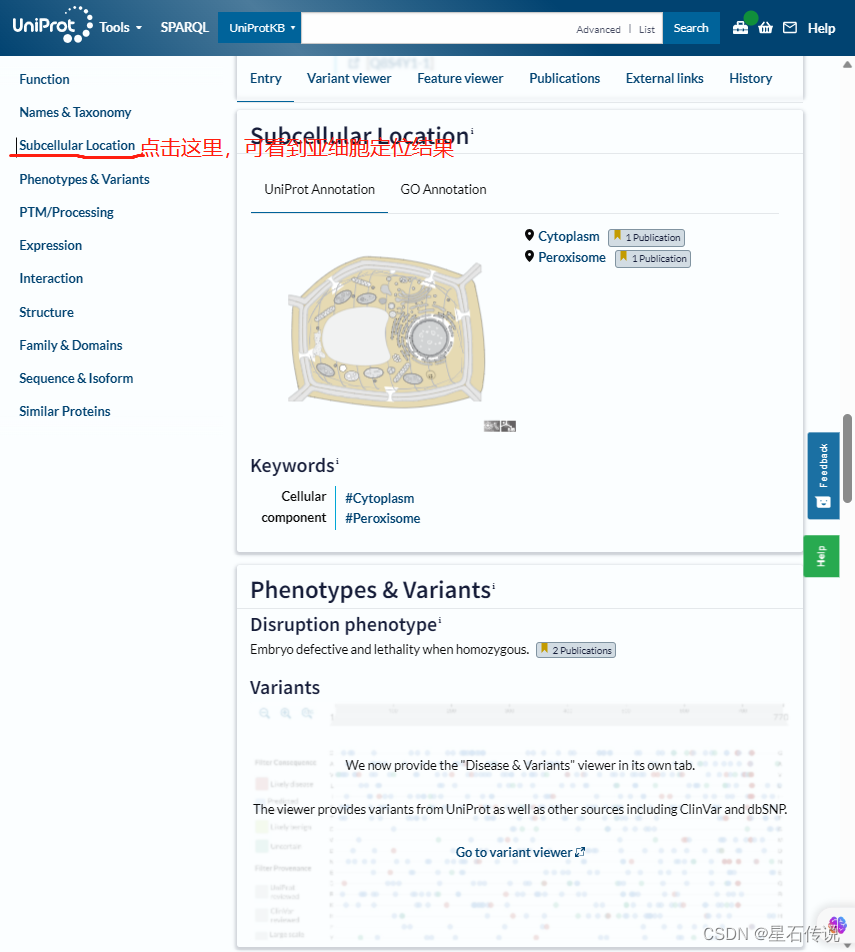
2. WoLFPSORT
网址:https://wolfpsort.hgc.jp/
这个网站可以批量处理小量的AA序列,允许的大小(200K),根据实际情况,一般可以容纳几百到几千个氨基酸序列。
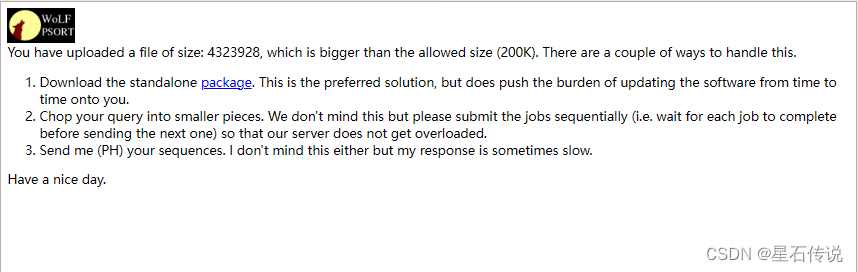
结果查看:

示例:
LaggChr1G00000010.1 details chlo: 5, nucl: 3.5, mito: 3, cyto_nucl: 3, cyto: 1.5, cysk: 1
LaggChr1G00000010.1这个蛋白质的亚细胞定位信息如下:
叶绿体(chlo)得分:5
细胞核(nucl)得分:3.5
线粒体(mito)得分:3
细胞质-细胞核(cyto-nucl)得分:3
细胞质(cyto)得分:1.5
细胞骨架(cysk)得分:1
这些得分表示蛋白质在各个亚细胞定位的可能性,较高的得分表示较高的概率。
他们是按得分排列的,故取第一个就行。
3. BUSCA
url: http://busca.biocomp.unibo.it/
最多可以输入500个序列
可以下载结果表格(还挺方便)
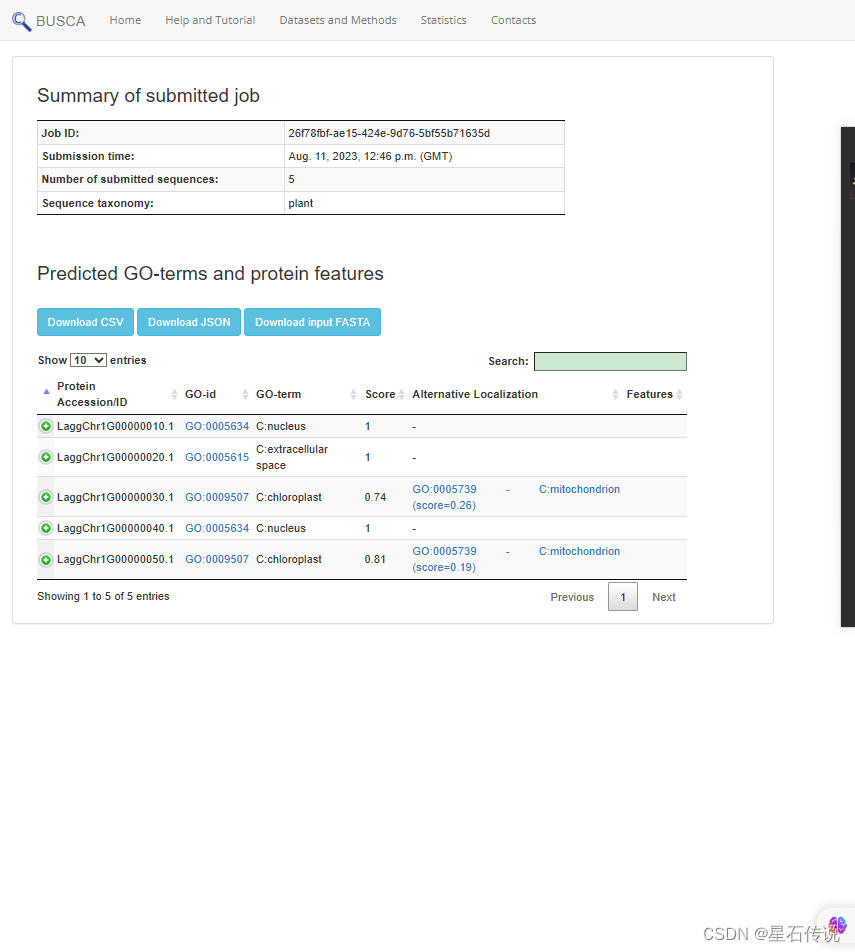
结果查看:
4. TargetP-2.0
TargetP-2.0
url = http://www.cbs.dtu.dk/services/TargetP/
我看了一下,它介绍中说能处理5000个AA序列,但是要得到结果文件是要下载这个软件,在网页上看不到结果(我没下载,因为下载它好像要填一些信息什么的)
二、代码实现
1. 基于UniProt(不会)
推荐:这是一篇有关于用R语言实现“根据uniprot ID 批量检测基因的亚细胞定位“
这篇文章是在已知道Uniprot ID的情况下实现的爬取
我最开始也是看的这篇文章,所以想要基于uniProt官网来通过爬虫爬取。但是我弄了好久才有点搞懂这个网站(它的功能太多了,太繁杂)。最主要是那个ID映射(我完全卡在这第一步了),因为我并不知道我的AA序列的ID来自哪个数据库 ,而且全是英文,就相当于我用之前还要了解好多数据库。我也看了许多关于这个官网介绍的教程,也是有点…
2. 基于WoLFPSORT
主要是对结果的整理
从前文可知,它返回的结果是一堆的,要想从中提取出来蛋白质的亚细胞定位,可以用代码实现
import requests
url = "https://wolfpsort.hgc.jp/results/pLAcbca22a5a0ccf7d913a9fc0fb140c3f4.html"
r = requests.get(url)
print(r.status_code)
# print(r.encoding)
text = r.text
# print(text)
lines = text.split("<BR>")
AA_ID_list = []
yaxibao_list =[]
for i in lines:
if "details" in i:
AA_ID = i.split("<A")[0].strip().split()[-1]
yaxibao = i.split("details")[1].strip().split()[1][:-1]
AA_ID_list.append(AA_ID)
yaxibao_list.append(yaxibao)
with open("yaxibao.csv","w",encoding="utf-8") as f:
f.write("AA_ID, yaxibao\n") # 写入列名
for j in range(len(AA_ID_list)):
f.write(f"{AA_ID_list[j]}, {yaxibao_list[j]}\n")
text:

yaxibao.csv:
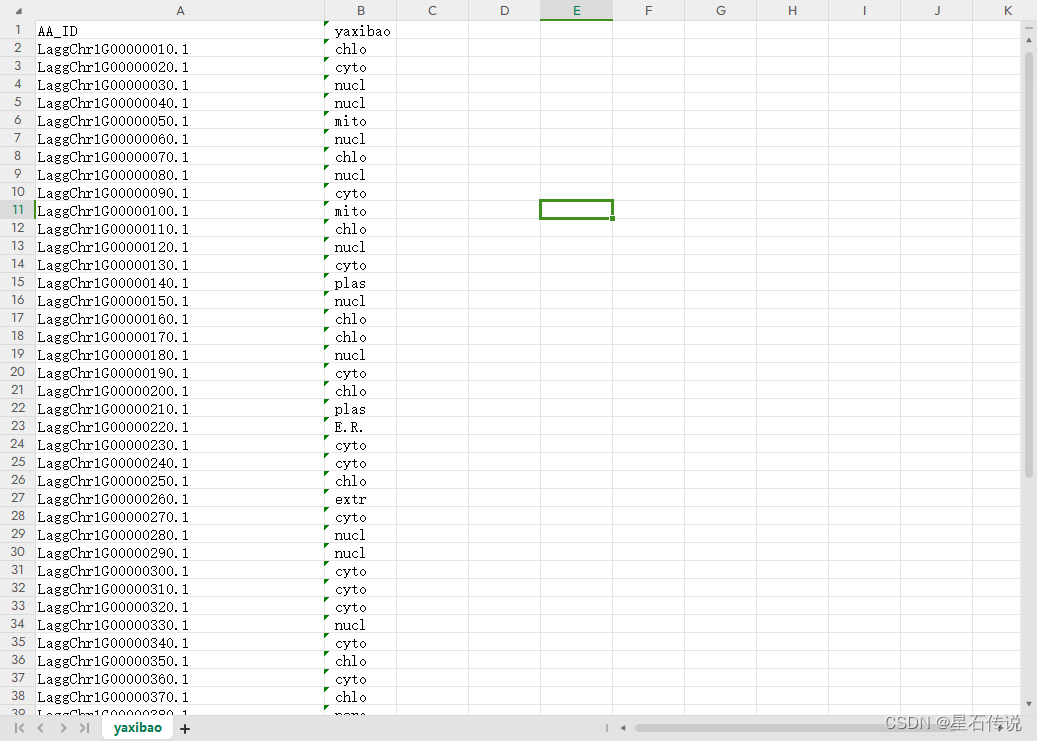
后续(已完善,有关代码放置于python爬虫学习(一)):
因为在WoLF PSORT官网中一次提交的数据大小最多200kb,那 我可以试着将原来几万kb大小的AA序列的大文件分为小文件,(之前说错了,之前的那个划分文件的函数是根据文件的行数划分的,而不是AA序列的ID数。我要将大的AA序列文件划分为小的AA序列文件,是要根据AA序列的ID划分,不然就会导致AA的ID 与AA的序列不连贯这种情况。故我又重新修改了一下)。
所以根据估算,这个WoLF PSORT官网中一次提交的AA序列最多也是差不多500左右。与那个BUSCA网站的差不多。
若是一定要批量处理大量的AA序列,可以尝试运用爬虫:
(一个思路,其中结果页面的url无法获得)
import requests
import os
import pandas as pd
from bs4 import BeautifulSoup
def split_gene_file(source_file, output_folder, ids_per_file):
os.makedirs(output_folder, exist_ok=True)
current_file = None
count = 0
with open(source_file, "r") as f:
for line in f:
if line.startswith(">"):
count += 1
if count % ids_per_file == 1:
if current_file:
current_file.close()
output_file = f"{output_folder}/gene_file_{count // ids_per_file + 1}.csv"
current_file = open(output_file, "w", encoding='utf-8')
current_file.write(line)
else:
current_file.write(line)
if current_file:
current_file.close()
split_gene_file("D:\yuceji\Lindera_aggregata.gene.pep", "gene1", 500)
files = os.listdir("D:\python\PycharmProjects\pythonProject1\爬虫\gene1")
base_url = "https://wolfpsort.hgc.jp/"
new_url = []
for i in range(len(files)):
with open(f"D:\python\PycharmProjects\pythonProject1\爬虫\gene1\gene_file_{i + 1}.csv", "r") as f:
aa_sequence = f.read()
# 构建WoLFPSORT请求的数据
data = {
"seq": aa_sequence
}
# 发送POST请求到WoLFPSORT官网
response = requests.post(base_url, data=data)
print(response.status_code)
print(response.text)
# 检查请求是否成功
if response.status_code == 200:
# 解析结果页面的URL
soup = BeautifulSoup(response.content, "html.parser")
result_links = soup.find_all("a", href=True)
print(result_links)
result_url = None
# 遍历所有的链接
for link in result_links:
href = link.get("href", "")
# 判断链接是否包含 "results"
if "results" in href:
result_url = base_url + href
break
if result_url:
print(result_url)
new_url.append(result_url)
else:
print("无法找到亚细胞定位结果页面的URL")
for i in range(len(new_url)):
# url = "https://wolfpsort.hgc.jp/results/pLAcbca22a5a0ccf7d913a9fc0fb140c3f4.html"
r = requests.get(new_url[i])
print(r.status_code)
# print(r.encoding)
text = r.text
# print(text)
lines = text.split("<BR>")
AA_ID_list = []
yaxibao_list = []
for i in lines:
if "details" in i:
AA_ID = i.split("<A")[0].strip().split()[-1]
yaxibao = i.split("details")[1].strip().split()[1][:-1]
AA_ID_list.append(AA_ID)
yaxibao_list.append(yaxibao)
with open(f"yaxiba{i}o.csv", "w", encoding="utf-8") as f:
f.write("AA_ID, yaxibao\n") # 写入列名
for j in range(len(AA_ID_list)):
f.write(f"{AA_ID_list[j]}, {yaxibao_list[j]}\n")
这个爬虫代码中返回的url并不是我要的那种,例如:https://wolfpsort.hgc.jp/results/pLA2dbb41dafad4afb342b5000abcb263b1.html
而是:(如图所示)

我点进这个链接是这样的:

我也不知道为什么,只能等我再学学爬虫,希望之后能解决这个问题吧!(当然也希望有大佬能帮忙指教一下)
我还看了看结果页面的源代码(HTML语言):
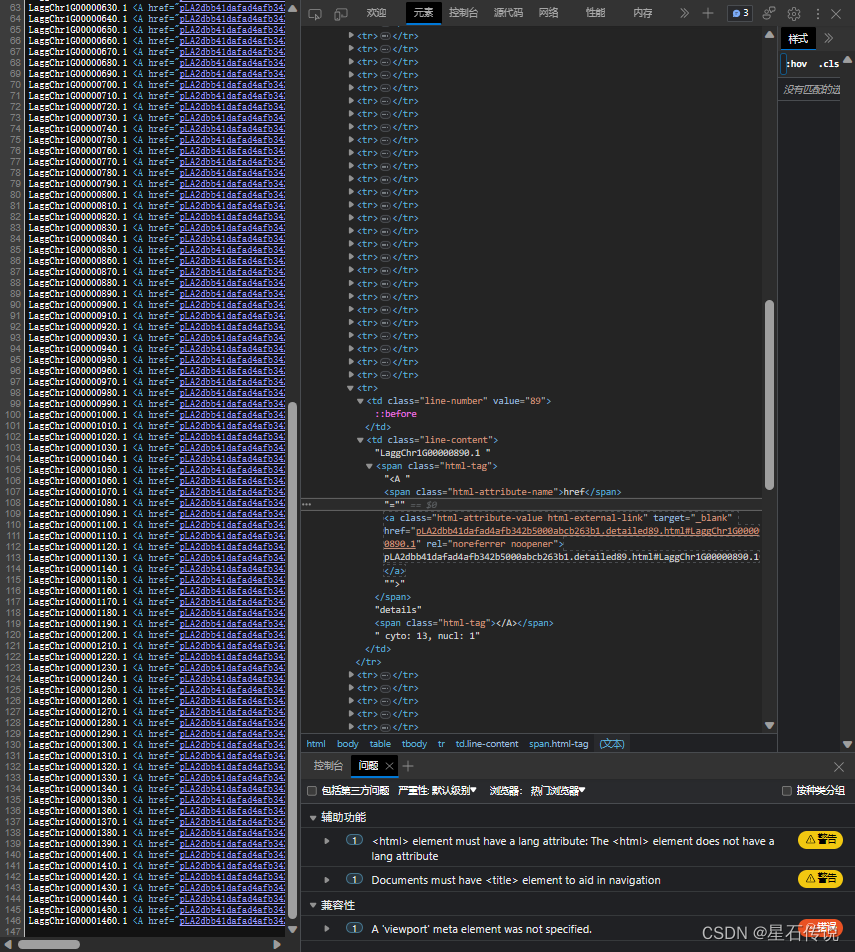
怎么说呢,既然我不能爬取到结果页面的url,那我只能将结果页面url的获得的步骤放在官网中实现,而后面的结果整理则用代码实现。
总结
本章详细介绍了许多用于亚细胞定位的网站,其中,我还是比较推荐 WoLFPSORT这个网站的(简单易懂,十分好上手)。至于后续的代码实现我也是基于这个网站,但是因为爬虫学习还不到位(无法爬取到结果页面的url)。只能等以后在学习爬虫时,再修改。
羌笛何须怨杨柳,春风不度玉门关。
–2023-8-12 实验篇


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











