







 本文介绍了一种基于深度学习的苹果识别系统,使用Yolov5算法进行实现,详细阐述了课题背景、算法原理、数据集建设、实验环境搭建以及实验结果分析,包括模型性能指标和优化策略。
本文介绍了一种基于深度学习的苹果识别系统,使用Yolov5算法进行实现,详细阐述了课题背景、算法原理、数据集建设、实验环境搭建以及实验结果分析,包括模型性能指标和优化策略。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的苹果识别算法系统
设计思路
一、课题背景与意义
随着农业信息化和智能化的快速发展,果实识别技术在果园管理中扮演着越来越重要的角色。苹果作为我国的主要水果之一,其识别技术对于果园自动化、精准化管理和果实品质控制具有重要意义。然而,由于苹果形状多样、颜色多变,以及果园环境复杂多变,传统的苹果识别方法往往难以取得理想的效果。因此,研究基于深度学习的苹果识别算法系统,旨在提高果园管理的智能化水平,实现苹果的高效、准确识别,对于推动果园智能化管理、提高果实品质和市场竞争力具有重要的现实意义和应用价值。
二、算法理论原理
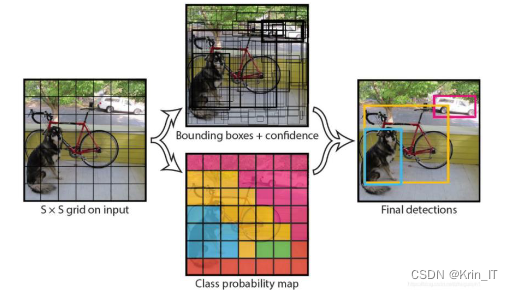
Yolo是一种基于单阶段检测的算法,具有快速检测速度和较高的准确性,可以实现实时目标检测和定位。它将输入图像缩放为448×448尺寸,并将其划分为7×7的网格单元。每个网格单元负责预测其区域内的目标。如果物体的中心位于网格单元内,该网格单元负责预测该物体。每个网格单元可以检测2个边界框和30个维度的特征向量,其中10个维度用于预测边界框的坐标,其余用于预测目标的类别概率。通过将每个网格预测的类别信息与边界框预测的置信度相乘,可以得到类别评分。最终,通过非极大值抑制(NMS)过滤,得到最终的检测框。
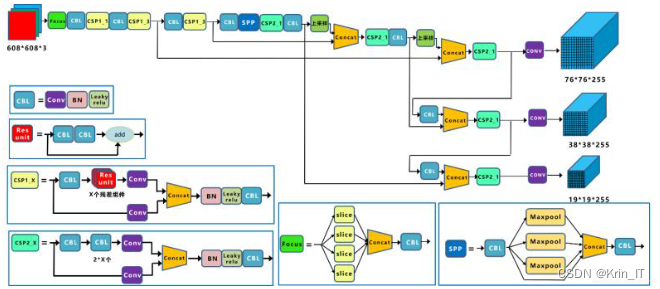
Yolo v5是由Backbone、Neck和Head三个部分构成的网络。它包括Yolo v5s、Yolo v5m、Yolo v5l和Yolo v5x四个不同的网络版本,区别在于网络的深度和宽度。Yolo v5在之前算法的基础上保留了优点,并对不足之处进行了优化。Yolo v5采用了Mosaic数据增强方式,引入了CutMix的思想,将四张图片进行随机缩放、裁剪和排列。Mosaic数据增强丰富了数据集,特别是对于小目标的检测效果有所提升。另外,Mosaic增强训练可以同时处理四张图片的数据,减少了硬件条件和算力的压力。
在Backbone部分,Yolo v5引入了Focus结构,将特征图切片成四份并在通道维度进行拼接。此外,Yolo v5的作者设计了CSPDarknet53,通过整合梯度的变化过程到特征图中,解决了其他大型卷积神经网络中梯度信息重复的问题,从而减少了参数量和浮点运算量,实现了轻量化模型同时满足精度和速度的要求。
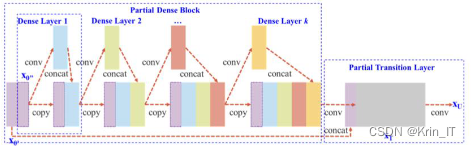
CSPNet在设计上参考了DenseNet,并通过复制基础层特征图并使用Dense模块将特征传递到下一部分。基础层特征图被分成两部分,一部分直接传递到尾部进行拼接,另一部分由Dense模块传递。这种方式一定程度上解决了梯度消失的问题,减少了网络参数,使模型更加精简。这种方法增强了网络的学习能力,同时在减小模型体积的同时保持较高的准确度,降低了内存成本。
在Neck部分,Yolo v5使用了FPN(特征金字塔网络)和PAN(金字塔注意力网络)的复合结构。FPN的目的是在精度和速度之间找到最佳平衡,获取更加通用的语义信息。由于图像中存在不同尺寸的目标,并且不同目标之间的特征差异也很大,因此选择FPN浅层特征用于简单目标的判别,而通过深层特征来区分复杂目标。通过从宏观到微观和从微观到宏观的特征融合方法,可以获得强大的语义信息,从而提升目标的检测和分割效果。因此,FPN在目标检测和图像分割领域得到广泛应用。
相关代码示例:
# FPN模块定义
class FPN(nn.Module):
def __init__(self, in_channels, out_channels):
super(FPN, self).__init__()
# 上采样层
self.up = nn.Upsample(scale_factor=2, mode='nearest')
# Lateral连接层
self.lat1 = nn.Conv2d(in_channels[0], out_channels, kernel_size=1)
self.lat2 = nn.Conv2d(in_channels[1], out_channels, kernel_size=1)
self.lat3 = nn.Conv2d(in_channels[2], out_channels, kernel_size=1)
# 输出层
self.out = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
def forward(self, x):
c3, c4, c5 = x
# 上采样
p5 = self.lat3(c5)
p4 = self.lat2(c4) + self.up(p5)
p3 = self.lat1(c3) + self.up(p4)
# 输出特征图
p3 = self.out(p3)
p4 = self.out(p4)
p5 = self.out(p5)
return p3, p4, p5三、检测的实现
3.1 数据集
为了训练和验证基于深度学习的苹果识别算法系统,一个丰富且多样化的苹果图像数据集是必不可少的。然而,现有的公开数据集往往局限于特定品种或环境下的苹果图像,无法满足我们对多品种、多环境下苹果识别的需求。因此,我们决定自制一个更贴近实际应用的苹果图像数据集。在数据采集过程中,我们还特别关注了苹果的外观特征和细节,如颜色、纹理、形状和缺陷等。为了确保数据的多样性和可靠性,我们还对苹果进行了多角度、多尺度的拍摄,并记录了每张图像的拍摄环境和条件。

为了提高模型的泛化能力和鲁棒性,我们对自制的苹果图像数据集进行了数据扩充操作。数据扩充是一种通过变换原始数据来生成新数据的技术,可以有效增加数据集的多样性和规模。在本文中,我们采用了多种数据扩充方法,包括旋转、缩放、平移、亮度调整、对比度调整等,对原始苹果图像进行了变换。通过这些变换,我们生成了大量新的苹果图像,为模型的训练提供了更多的有效数据。
3.2 实验环境搭建
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试基于深度学习的交通灯识别算法系统。
3.3 实验及结果分析
使用标准的评估指标对改进后的模型进行全面评估,包括平均准确率(mAP)、损失值(Loss)、精准率(Precision)、召回率(Recall)、模型大小、参数量和检测帧率(FPS)等指标,以进行与基准模型的对比分析。
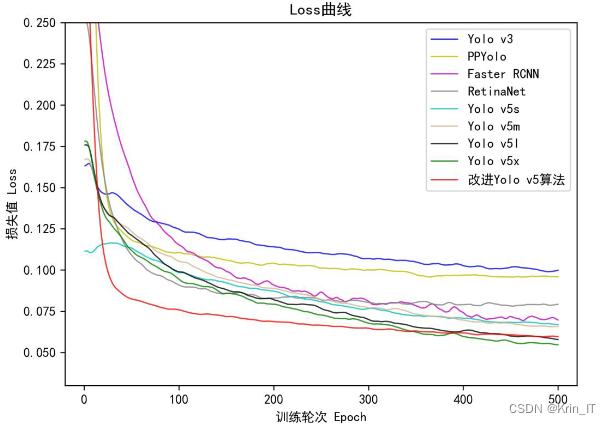
Loss曲线是在模型训练过程中绘制的,它表示了每一轮Epoch后的损失值。将所有损失值连接起来形成Loss曲线,可以观察模型的收敛速度。损失函数在模型训练中起到约束作用,一个好的损失函数能够加快模型的收敛速度并提升检测效果。通过分析Loss曲线,可以了解模型训练的进展情况,判断模型是否正常收敛并调整训练策略。
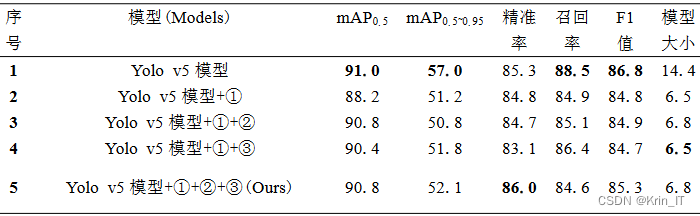
消融实验是在机器学习和深度学习研究中常用的实验方法之一,用于评估模型的组成部分对整体性能的影响。它通过逐步削减或修改模型的某些组件,观察模型性能的变化,以便理解和分析模型的关键因素。消融实验的目的是深入了解模型的工作原理和关键因素,以及它们在解决特定任务或问题时的作用。这种实验方法能够帮助研究人员识别和优化模型的薄弱环节,改进模型的性能,并提供对模型设计的指导和解释。
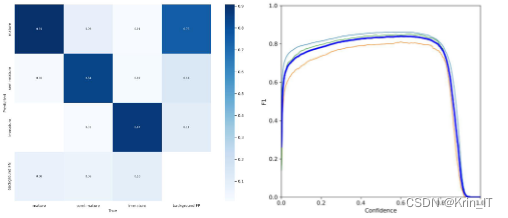
相关代码示例:
# 定义不同学习率下的模型训练和评估
def experiment(learning_rates):
results = [] # 存储每个实验组的结果
for lr in learning_rates:
model, mAP = train_model(lr)
results.append((lr, mAP))
return results
# 设置不同学习率的列表
learning_rates = [0.1, 0.01, 0.001]
# 执行实验
experiment_results = experiment(learning_rates)
# 输出实验结果
for lr, mAP in experiment_results:
print(f"学习率 {lr} 下的模型 mAP: {mAP}")实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









