






1. 使用ollama拉取模型;
2. AI界面使用:
① Page Assist(Edge插件,无需安装,下载即用,室友fty推荐);
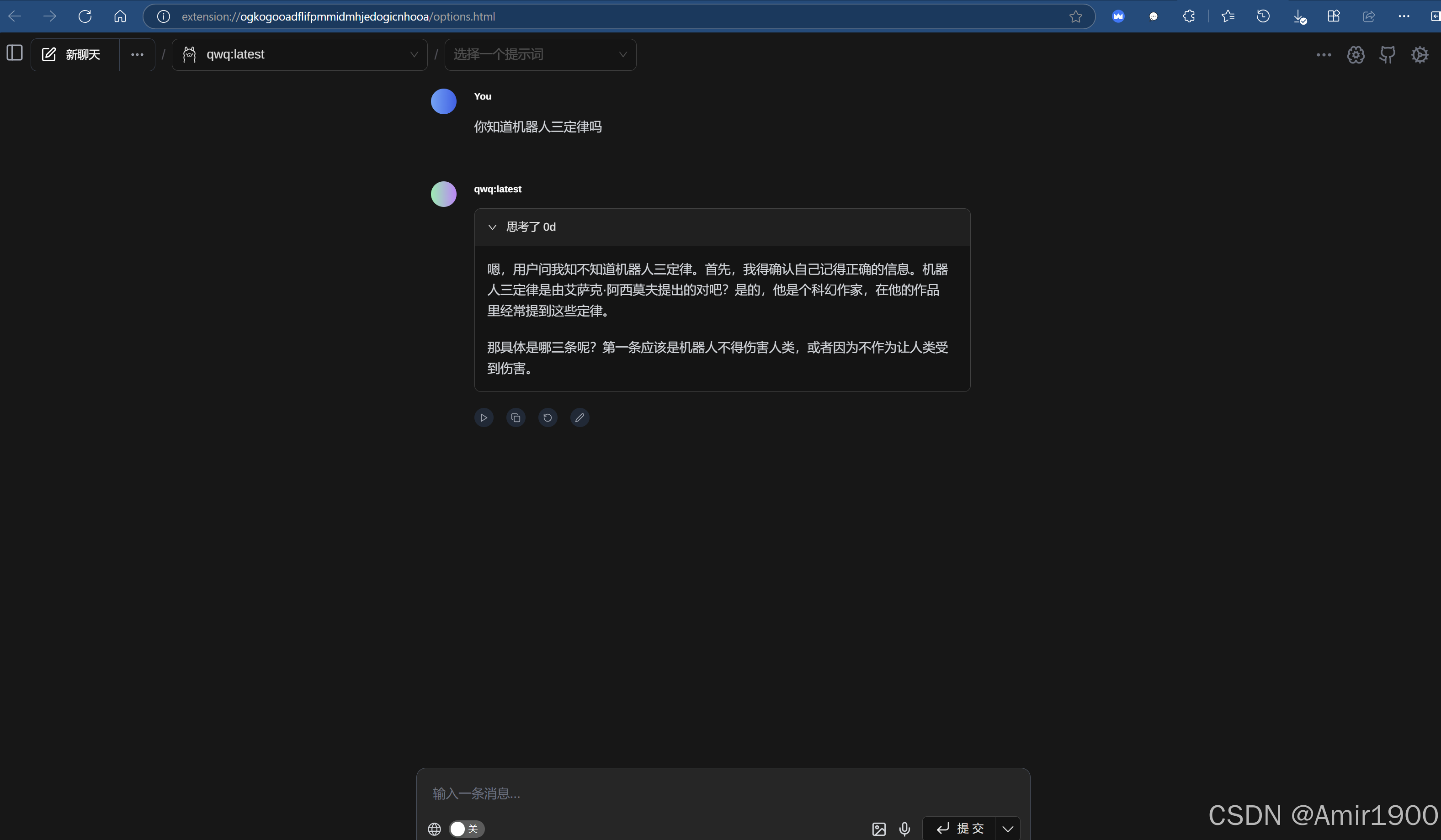
② 使用Chatbox应用,模型提供方选择ollama,即可使用多个本地模型,(好用推荐,有多种内置语境,思考过程和最后结果分明)
③ 使用海鹦OfficeAI助手(为了WPS内使用下载的,不使用WPS不建议用);
3. 模型性能测试:
测试环境:联想Thinkbook16p2023版,64G内存,模型都在D盘,Nvidia Laptop4050显卡,6GB显存(专用),32GB共享内存(给集显使用),intel-i5-13500H CPU,插电测试
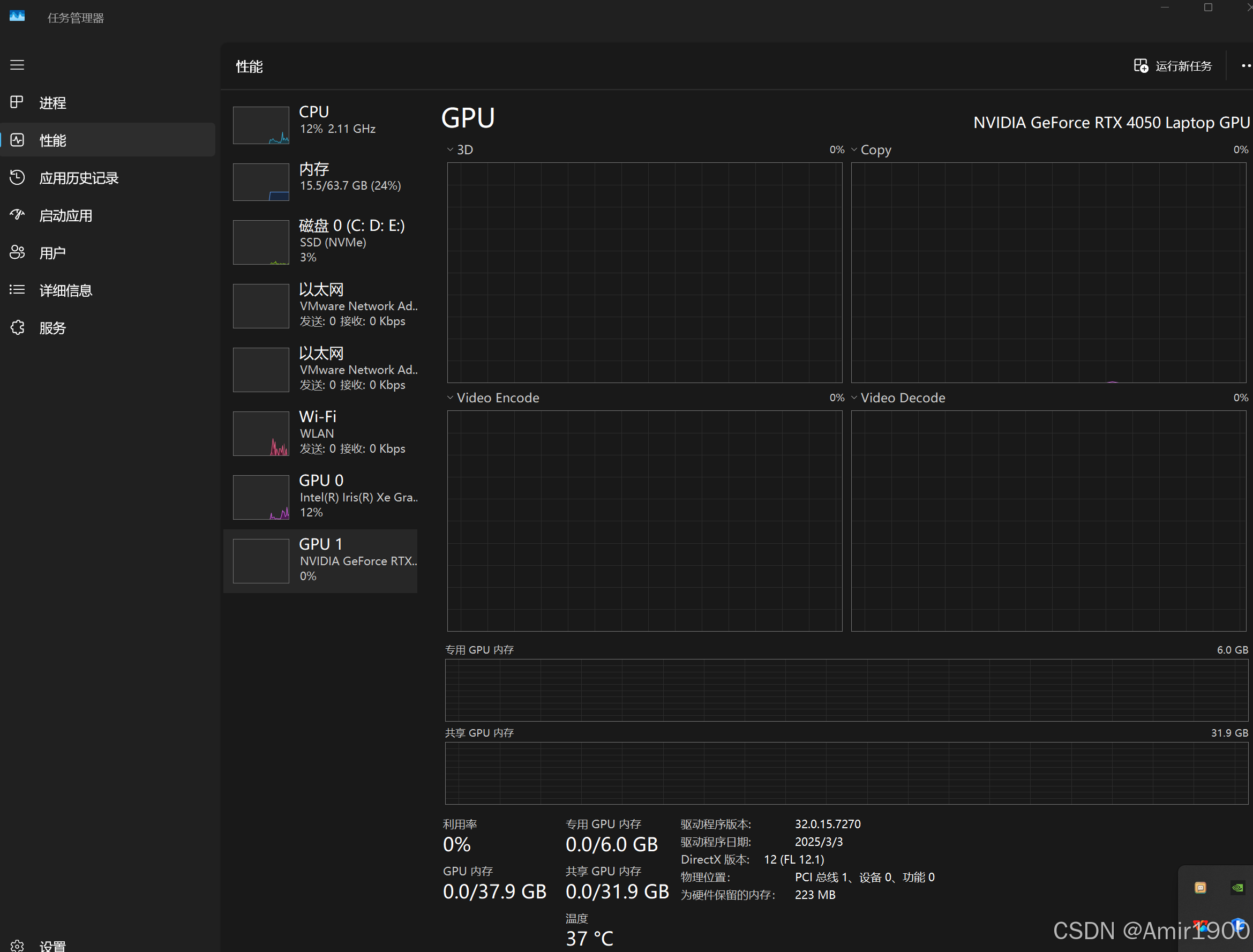
测试:
deepseek r1 1.5B:顺畅运行,思考和输出基本不超过1秒;内存上升不明显,显卡占用不明显;
deepseek r1 8B: 每秒20-30个字(目测),内存占用上升2GB左右,专用显存占用4GB左右,输出速度能接受;
deepseek r1 14B:每秒15-20字左右(目测),内存占用上升6GB左右,显存占用4.5GB,共享内存占用4.8GB左右,写代码能接受;

千问qwq 32B:内存占用上升20GB左右,GPU专用4.3GB,共享GPU占用15GB左右,每秒输出5-10个字(目测),很慢;

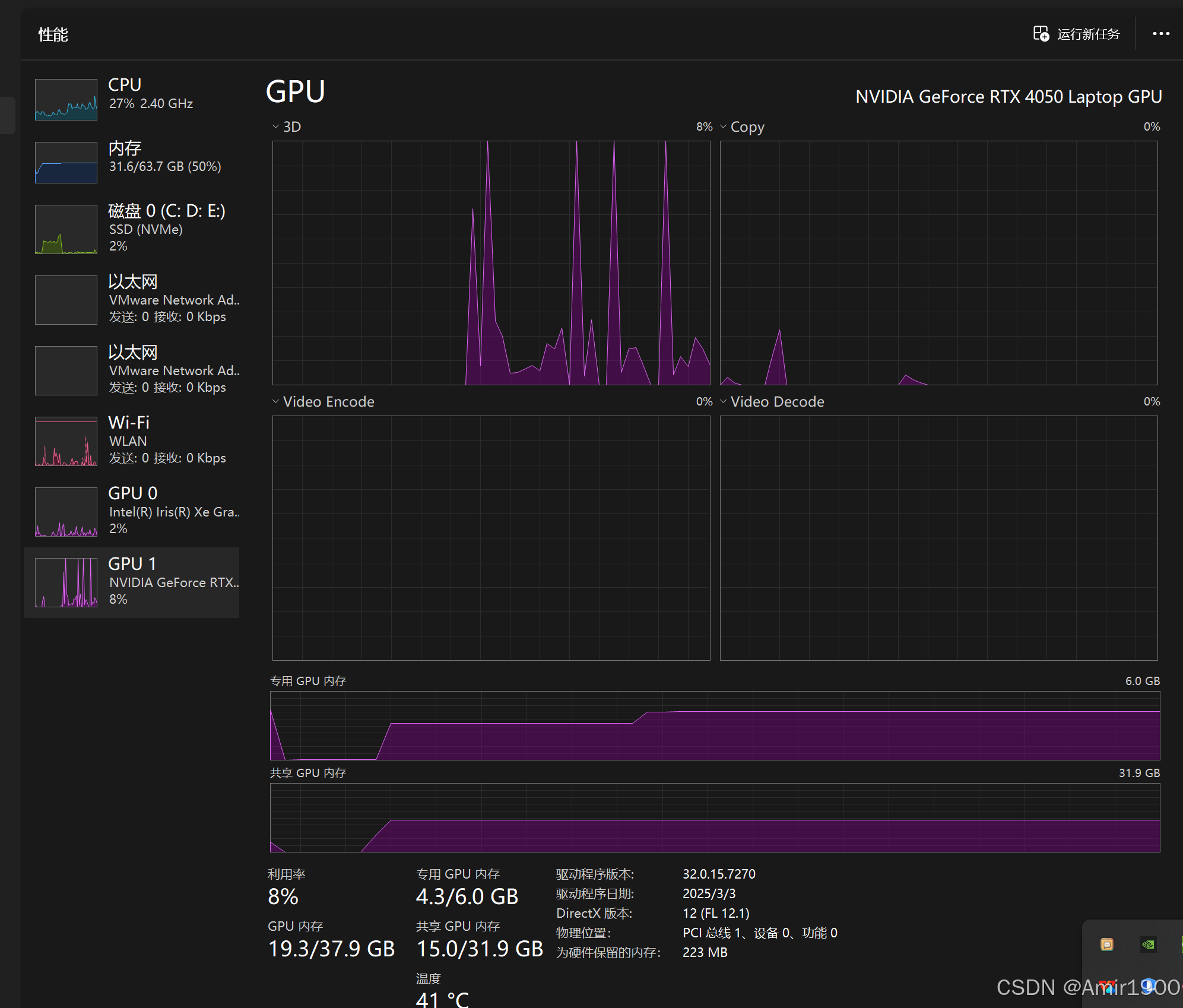
4. 总结
当前电脑配置下,8B及以下可以对话使用,14B可以用来编写代码,更大的模型基本处于不可用状态,耗费时间太长,非必要不可使用;
5. 思考
① 共享内存占用不高,是因为锐炬核显计算能力上限了吗?请教有什么工具可以看到核显的占用程度?
② 如果只用核显(CPU)来运行,最大可以运行多少B的模型?无法测试因为不知道怎么关闭独显的计算,只切换显示模式还是会调用NVIDIA显卡,请教;
③ 当前除了32B的,其余感觉还是有些蠢蠢的,不如主流的一些AI聪明,希望以后还能出现更 高效的模型,在算力更少的硬件上有更好的效果;
日常记录使用过程,防止以后遗忘,不一定正确,如果有用可以给文章点个赞,谢谢!

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









