






目录
2.1 细粒度分布优化(FDR,Fine-grained Distribution Refinement)
D-FINE : 重新定义实时检测目标的边界框回归任务

论文标题:
《D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement》
论文地址:[2410.13842] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
项目地址:
https://github.com/Peterande/D-FINE
一、概述
D-FINE 是中国科学技术大学团队提出的一种基于Transformer架构的实时目标检测模型,其核心创新在于重新定义边界框回归任务。,通过“细粒度分布优化(FDR)”和“全局最优定位自蒸馏(GO-LSD)”两大方法,在不增加额外训练成本的前提下,显著提升了定位精度和检测效率。该模型在COCO数据集上以 78 FPS 的速度达到59.3% 的平均精度(AP),超越了 YOLO 系列和 RT-DETR 系列的最新版本。
研究团队分别使用 D-FINE 和 YOLO11 对 YouTube 上的一段复杂街景视频进行了目标检测。尽管存在逆光、虚化模糊和密集遮挡等不利因素,D-FINE-X 依然成功检测出几乎所有目标,包括背包、自行车和信号灯等难以察觉的小目标,其置信度、以及模糊边缘的定位准确度明显高于 YOLO11x。具体见下图:

1.1 针对目前实时目标检测的问题
① 边界框回归的局限性:现有方法(如DETR)通过固定坐标来预测边界框,将边缘视为确定值(Dirac delta分布),无法建模定位不确定性,导致对小坐标变化敏感,收敛慢。而且原本采用的 L1 和 IoU 损失难以指导边缘独立优化。
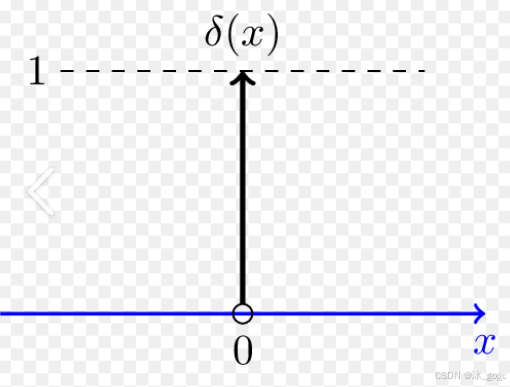
Dirac delta分布,也成为狄克拉函数。
被定义为在除了x=0以外的所有点的值都为0,且在整个定义域上的积分等于1。图像如下
问:为什么固定坐标会导致对小坐标变化敏感❓
固定坐标(确定值)无法建模预测的不确定性,这是因为任何轻微的偏移都会被损失函数(L1损失和IoU损失)视为错误,而概率概率分布(如高斯分布)通过方差量化了不确定性,允许模型区分噪声与真实偏移,从而更鲁棒地优化边界框位置。
② 概率建模与迭代优化的不足:尽管GFocal等方法引入概率分布解决不确定性问题,但仍然依赖锚框、定位粗糙、且缺乏渐进式迭代优化机制,限制了精度的提升。
③ 知识蒸馏的效率和兼容性挑战:有研究表明传统知识蒸馏(KD)方法(如Logit模仿)在检测任务中效率低下。而定位蒸馏(LD)虽然更适配检测,但因为高训练开销和不兼容无锚框模型的问题,难以集成到实时目标检测框架中。
为解决以上问题,研究团队提出D-FINE,一种重新定义了边界框回归并引入一种有效的自蒸馏策略的新颖实时目标检测器。有效解决了固定坐标回归中优化困难、无法建模定位不确定性以及需要低成本有效蒸馏的问题。
1.2 D-FINE的创新点
D-FINE的创新点主要分为四点,具体如下:
① 细粒度分布优化(FDR):D-FINE将边界框回归任务从预测固定坐标转变为迭代细化概率分布,提高了定位精度。
② 全局最优定位自蒸馏(GO-LSD):通过自蒸馏策略,将定位知识从深层细化分布转移到较浅层,简化了深层任务。
③ 轻量级优化:D-FINE在计算密集型模块和操作中采用了轻量级优化,实现了速度和精度之间的更好平衡。
④ 显著性能提升:在COCO数据集上的实验研究表明,D-FINE在精度和效率上超越了现有模型,达到了最先进的性能。此外FDR和GO-LSD这两个方法以可以忽略的额外参数和训练成本将多种DETR模型的性能提升了高达5.3%的AP。
总结:D-FINE在现有DETR的架构上的创新主要是方法的创新,分两点:一是回归任务的方法创新,D-FINE提出细粒度分布优化(FDR),将传统边界框回归任务从预测固定坐标转化为概率分布的逐层优化。二是训练策略的方法创新,D-FINE通过全局最优定位自蒸馏(GO-LSD)实现了训练过程的优化,这是一种无需额外计算成本的知识蒸馏的方法。
二、核心
2.1 细粒度分布优化(FDR,Fine-grained Distribution Refinement)
(1)介绍
FDR 将边界框回归从预测固定坐标转变为建模概率分布,提供了一种更细粒度的中间表示。FDR以残差方式迭代优化这些分布,允许逐步进行更精细的调整,从而提高定位精度。
(2)大致的实现步骤
1、初始框预测:与传统DETR类似,第一层解码器将object queries转换为若干个初始边界框。这些边界框只用于初始化,所以不用特别精确。
2、细粒度的分布优化:和传统方法不同,后续解码层不会再直接预测出新的边界框,而是基于初始边界框生成四组概率分布(对应边界框的四条边),通过FGL损失函数逐层调整优化这些分布,最终通过加权求和得到偏移值。【tips:这些概率分布本质上使检测框的一种「细粒度中间表征」,D-FINE可以通过微调这些表征,不同幅度地独立调整各边缘。】
具体流程如下图:
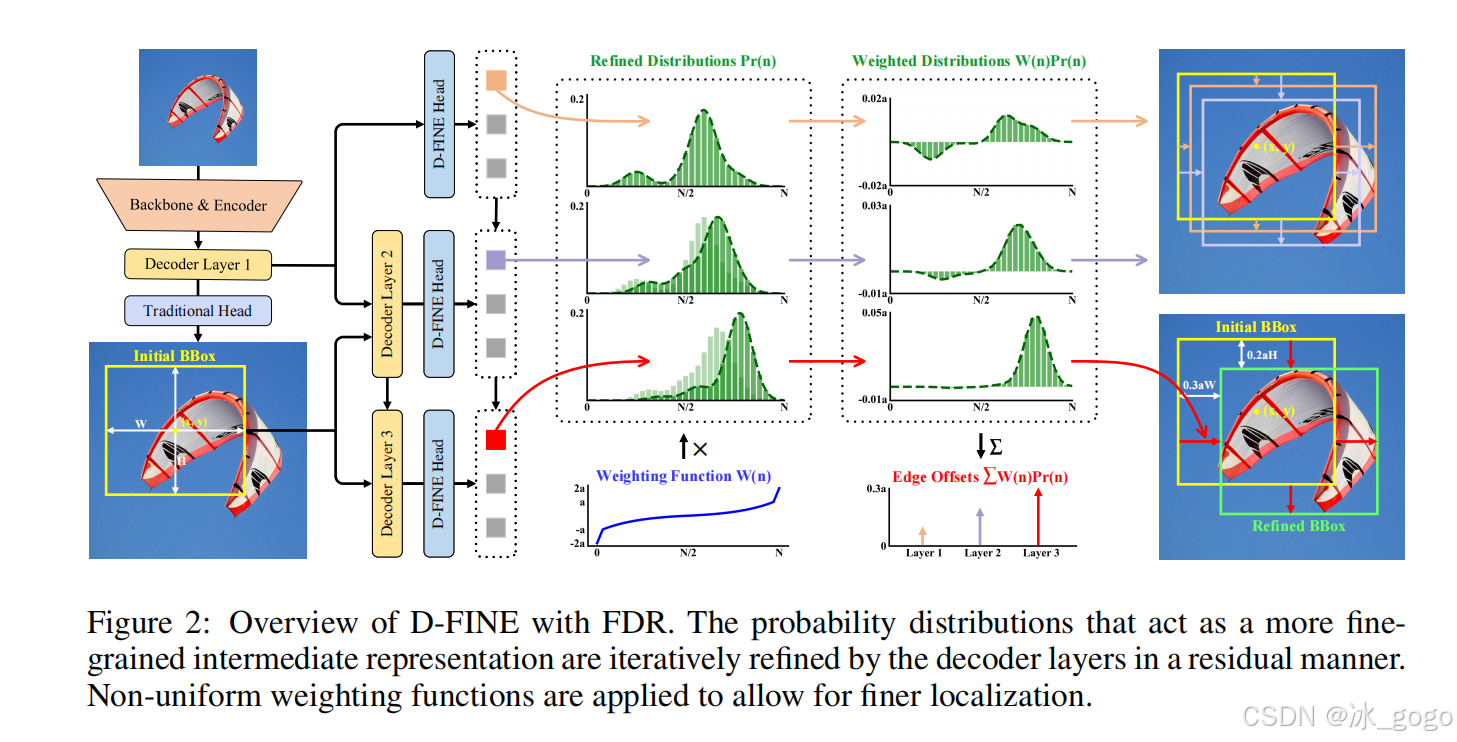
数学上,设 b0={x, y, W, h} 表示初始边界框的预测,其中 {x, y} 表示边界框的中心点坐标,{W, h}表示边界框的宽度和高度。这里将 b0 转换为中心坐标 c0 = {x, y} 和边缘距离 d0 = {t, b, l, r},分别表示中心点到上、下、左、右边缘的距离。
对于第l层,优化后的边缘距离 dl 表示如下:
![]()
dl 的计算公式如下:
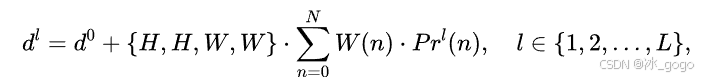
上式中,第l层的 Pr(n)具体表示如下:
![]()
根据Pr(n) 下标的不同,概率 Pr(n) 分别表示四条边的独立概率分布,每个分布预测对应边缘的候选偏移值offset的概率。这些候选值由加权函数 W(n) 决定,n表示离散区间的索引,每个区间对应一个候选的边缘偏移量。分布的加权和生成最终边缘偏移量(即得到上图中的Edge offset图像),这些偏移量最终通过初始边界框的高度H和宽度W进行缩放,确保调整与边界大小成比例。
问:“n表示离散区间的索引” 表示什么意思?
在D-FINE中,每条边界框的边缘(上、下、左、右)的偏移量被划分为多个离散的区间(bin),论文中设为N个,每个区间bin对应一个概率值。简单来说,就是将某条边的偏移范围划分为N个均匀间隔的bin,则每个bin代表一个特定的偏移范围区间。
D-FINE头会为每条边生成一个维度为N的概率分布向量,表示该边落在每个bin内的可能性。每个bin的权重通过非均匀加权函数W(n)动态调整,是模型在不同偏移量下能灵活调整,即小偏移时微调,大偏移时快速矫正。
(3)技术细节部分
① 细节一:概率分布如何逐层调整并优化?
优化后的分布通过「残差」来调整更新,定义如下:

其中,前一层的![]() 反映每个区间偏移值的自信程度。
反映每个区间偏移值的自信程度。
当前层预测的残差![]() 将和前一层的 logits 相加,形成更新后的
将和前一层的 logits 相加,形成更新后的![]() 。这些更新后的 logits通过 softmax函数进行归一化,生成优化后的概率分布
。这些更新后的 logits通过 softmax函数进行归一化,生成优化后的概率分布
② 细节二:加权函数 W(n)
为了支持精确且灵活的调整,加权函数 W(n) 定义如下:
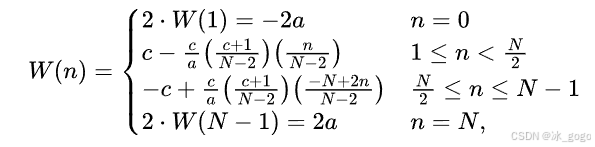
其中, a是控制函数上界的超参数,c是控制函数曲率的超参数。如上面FDR的大致流程图所示, W(n) 的形状确保当边界框预测解决准确时,较小的曲率允许更精细的调整;反之,当预测不准确时,边缘附近较大的曲率和边界处的急剧变化确保足够的灵活性以进行大幅度修正。
③ 细节三:细粒度定位损失(FGL)
为了进一步提高概率分布预测的精度,并与真实值对齐,研究团队基于分布焦点损失(DFL)的启发,提出一种新的损失函数——细粒度定位损失(FGL),具体计算公式如下:
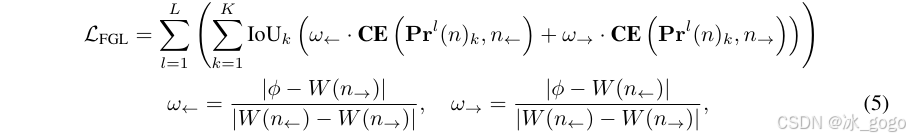
其中,第k个预测对应的概率分布为![]() 。
。
相对偏移表示为![]() ,其计算公式如下:
,其计算公式如下:
![]()
其中,![]() 表示真实边缘距离。
表示真实边缘距离。
![]() 和
和![]() 是
是![]() 相邻的区间索引。
相邻的区间索引。
带权重![]() 和
和![]() 的交叉熵(CE)损失确保区间之间的插值与真实偏移精确对齐。通过引入基于IoU的加权,FGL损失鼓励不确定性角度的分布更加集中,从而实现更精确和可靠的边界框回归。
的交叉熵(CE)损失确保区间之间的插值与真实偏移精确对齐。通过引入基于IoU的加权,FGL损失鼓励不确定性角度的分布更加集中,从而实现更精确和可靠的边界框回归。
(4)优点
将边界框回归任务重新定义为FDR,具有如下优势:
1、优化过程更简单:传统方法直接用L1或IoU损失调整坐标值,而FDR通过逐步优化概率分布来简化任务。每一层解码器只需要关注当前预测与真实值之间的误差(即“残差”),而不是从头开始调整整个边界框。随着层数增加,误差会越来越小,优化目标也更简单直接。
2、对复杂场景的适应性更强:FDR通过概率分布独立调整每条边的位置。例如,当左边缘因遮挡模糊时,模型会降低左边缘分布的置信度,允许更灵活的调整;而其他清晰的边则保持高置信度。这种边缘调整的独立性让模型在遮挡、模糊或光照变化下更稳定。
3. 修正幅度可自动调节:FDR使用动态调整的权重函数。当预测接近真实值时,加权函数曲率小,会小幅度修正边界框位置;当偏差较大时,则允许大幅度调整边界框位置。这种机制既保证了精度,也避免了反复调整的冗余计算。
4. 兼容更多的技术扩展:FDR将边界框预测转化为概率分布预测,与分类任务的形式一致。这使得模型能直接应用知识蒸馏、多任务学习等技术,突破传统回归方式的限制。
2.2 全局最优定位自蒸馏(GO-LSD)
(1)介绍
GO-LSD 是一种基于自蒸馏的双向优化策略,以可忽略的额外训练成本将定位知识从深层传递到浅层。通过将浅层的预测与深层优化后的输出对齐,模型能够生成更好的早期调整,加速收敛并提高整体性能。
(2)主要机制
① 知识传递:深层解码器生成更精确的分布,通过KL散度损失将知识蒸馏到浅层,实现层间定位知识共享。
② 双向优化:深层知识反馈提升浅层预测,浅层优化减少深层残差任务的难度,形成正向循环。
(3)实现步骤
① 深层传递知识:将深层解码器(如最后一层)优化的概率分布知识通过自蒸馏传递给浅层解码器,强制浅层预测和深层精细化分布对齐,加速收敛并提升浅层定位精度。
② 解耦边缘蒸馏:设计解耦蒸馏焦点损失(DDF loss),对边界框的四个边缘独立蒸馏,并基于预测置信度进行动态加权。
③ 残差优化简化:深层仅需要预测浅层输出的残差调整量,降低优化难度。通过双向参数更新策略同步优化各层一致性,以极低计算成本提升定位鲁棒性。
具体流程如下图:
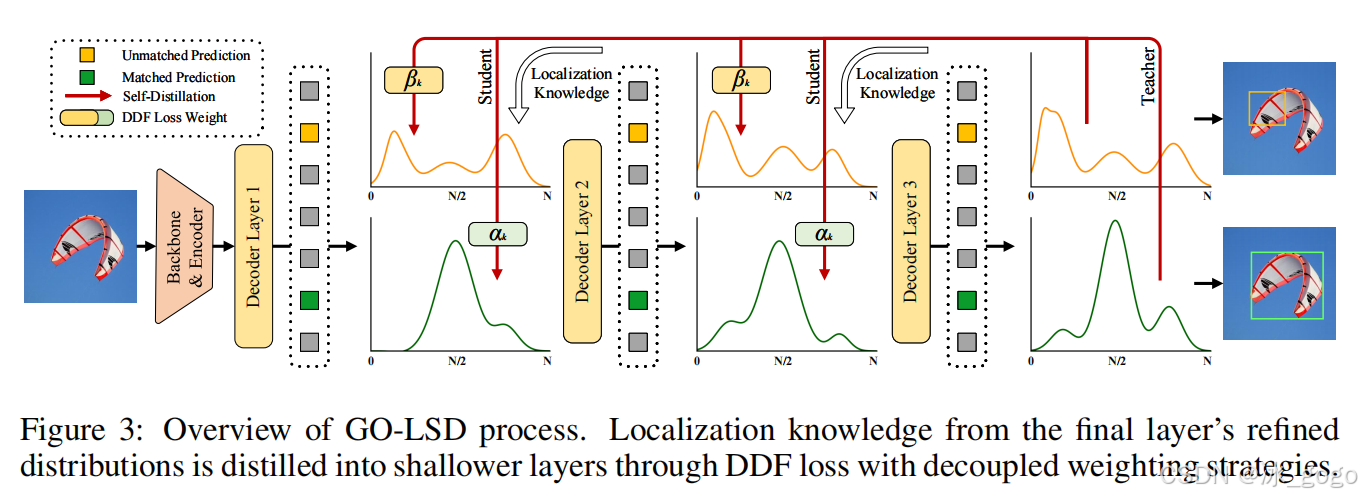
如图3所示,该过程首先对每一层的预测应用匈牙利匹配,在模型的每个阶段识别出局部最优边界框匹配。为了实现全局的优化,GO-LSD将深层网络优化后的精准定位知识传递到浅层网络,并整合所有层中的匹配到真实框的预测框,形成一个(全局)联合集合,实现定位知识的跨层协同优化。除了优化全局匹配之外,GO-LSD突破了传统DETR架构中仅优化匹配预测框的限制,在训练中会同时对未匹配的预测(即背景候选框)同步进行定位监督,以整体性能。
尽管定位任务通过联合集合”广纳“各层最优定位候选框以提升精度,但分类任务仍然遵循一对一的匹配原则(每个ground truth仅保留置信度最高的预测),避免输出冗余的边界框。这种严格的匹配机制意味着在这个联合集合中,部分定位准确但分类置信度较低的预测框可能会被分类任务忽略,造成定位知识的浪费。而且这些低置信度的预测通常代表定位准确的候选框,仍是需要进行有效蒸馏的,不能被忽略。
为了解决问题,研究团队提出解耦蒸馏焦点损失(DDF)。该损失采用解耦加权策略,确保高IoU(即定位准确)但低置信度的预测被赋予适当的权重。DDF损失还会根据匹配和未匹配预测的数量进行加权,平衡它们的整体贡献和个体损失。这种方法使蒸馏过程更加稳定和有效。
解耦蒸馏焦点损失(DDF)定义如下:
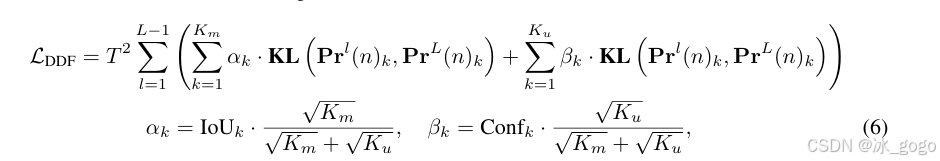
其中,
KL( ),表示KL 散度(Kullback-Leibler divergence),是一种用来比较两个概率分布“像不像”的指标,比如让模型的预测值的分布尽量和真实数据的分布接近,但注意它不对称(调换顺序,结果会不同)。
T表示用于平滑logits的温度参数。logits指模型输出的原始类别预测分数(未经softmax归一化)。温度T通过调整这些分数的分布形态,控制模型输出的“软标签”(即概率分布)的平滑程度。
第k个匹配预测的蒸馏损失由αk加权,其中Km和Ku分别表示匹配和未匹配预测的数量。
第k个未匹配预测,权重为βk,其中![]() 表示分类置信度。
表示分类置信度。
(4)优点
FDR与GO-LSD的结合产生双赢:随着训练的进行,最后一层的预测将变得越来越准确,其生成的软标签也能够更好地帮助前几层提高预测准确性,从而进一步提高整体准确性。
三、局限性与未来工作
轻量级的D-FINE模型和其他紧凑模型之间的性能差距仍然较小。一个可能的原因是较浅的解码器层可能生成不够准确的最终层预测,限制了将定位知识蒸馏到早期层的结果。解决这一挑战需要在不增加推理延迟的情况下,提升轻量级模型的定位能力。
未来的研究可以探索先进的架构设计或者新的训练范式,其中一种思路是继续改进架构设计,尝试在训练期间引入额外的异构解码层(简单理解就是能够包含更多的解码器层去生成更准确的最终层预测),然后在测试时可以通过简单地丢弃这些层来保持轻量级推理。如果训练资源足够,还可以直接用大模型对小模型进行蒸馏,而不是依赖自蒸馏。
参考来源:

















 1318
1318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









